[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
T+1 and Beyond: Transforming Trade Settlement for Modern Markets With Confluent
Effective May 2024, the US and Canadian securities markets will migrate to an accelerated T+1 trade settlement cycle. Discover how Confluent’s data streaming platform can help your firm meet the faster workflow requirements of this new industry regulation.
Create Faster Trade Settlement Pipelines
T+1 is driving an increased need for real-time systems, more efficient trade operations, and improved risk management for financial institutions worldwide. As the world’s largest securities market, settling U.S. trades 24 hours faster will have a significant impact on international investors and other global markets who remain on a two business day cycle (T+2).
As the settlement time continues to shrink, dropping from hours today to potentially near real time, trading systems driven by batch processes will struggle to meet future requirements. Confluent’s data streaming platform enables financial institutions to evolve their settlement systems, with highly accurate data orchestration across real-time settlement pipelines that future proofs for ever-decreasing regulatory processing times.
Enable real-time data processing for automated trade enrichment and integration demands.
Stream accurate and enriched data points to multiple systems in the multi-step settlement process in real time.
Collect and store securities and counterparty information as an immutable replayable log to recapture point-in-time views.
Build with Confluent
This use case leverages the following building blocks in Confluent Cloud.
Reference Architecture
Below is a reference architecture showing where Confluent sits as the stream processing engine for settlements:
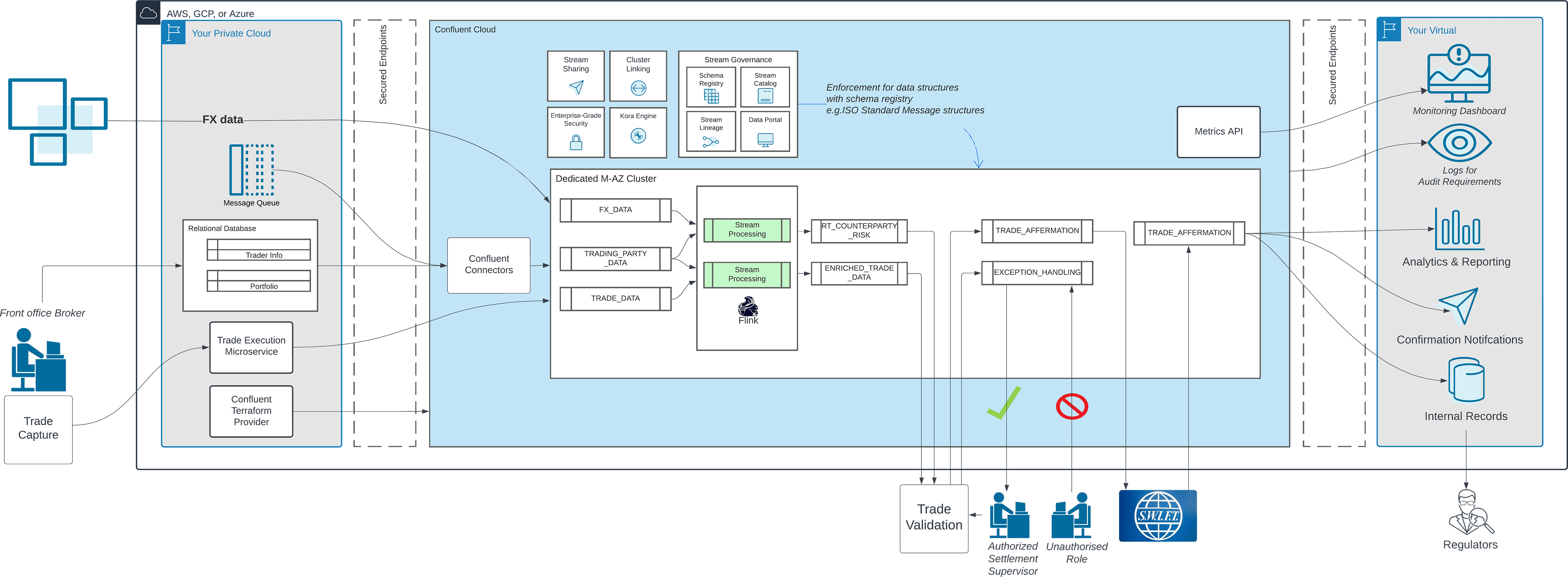
From trade capture and trade confirmation to clearing and reconciliation to final settlement, data and events must move across each of these often siloed processes. To help connect the disparate systems, Confluent offers over 120 pre-built connectors available in the Confluent connector hub.
Scaling for market volatility: Confluent Cloud allows Kafka clusters to dynamically expand and shrink as needed. Confluent Cloud's self-balancing clusters optimize data placement to ensure that newly provisioned capacity is immediately used and that skewed load profiles are smoothly leveled.
Allows data to be elevated from simply being events and messages to curated data products:
- Simplify server-side payload filtering by consuming subsets of topics
- Leverage windowed sorting to help with out-of-sequence message processing
- Use KTables for data quality and data validation
- Leverage Point-in-time joins to determine FX pricing
- Use Kafka Streams’ broadcast pattern to ensure all consumers receive "Done for Day" messaging
Enforce entitlements and standards throughout the settlement life cycle.