Streaming UEBA Marketing Analytics
Empower data scientists, marketing managers, and IT decision-makers with a User and Entity Behavior Analytics (UEBA) application to facilitate targeted marketing campaigns fueled by real-time user behavior insights.

Unlock Streaming Power with Confluent

Data Reply IT actively participates in the Build with Confluent initiative. By validating our streaming-based use cases with Confluent, we ensure that our Confluent-powered service offerings leverage the capabilities of the leading data streaming platform to their fullest potential. This validation process, conducted by Confluent's experts, guarantees the technical effectiveness of our services.
Data Reply IT leverages a data-driven approach, utilizing advanced unsupervised machine learning techniques like K-means clustering to extract valuable insights from transactional data. By implementing efficient labeling strategies to comprehend user behavior and optimizing development workflows for greater efficiency and flexibility, Data Reply IT significantly improves its real-time reporting and analytics functionalities.
K-means clustering is an unsupervised machine-learning algorithm that groups data into homogeneous clusters. It divides a dataset into K clusters, with each cluster represented by a centroid, the average point of all points in the cluster. This method is widely applicable across various fields for its effectiveness in data grouping and analysis.
Data Reply IT opts for unsupervised machine learning since it does not require a training dataset and can be processed as it flows in.
Streaming starts with the input of transactional data into the "transactions" topic. Leveraging FlinkSQL, you can enrich this data with additional transaction entity information, enabling meaningful user labeling. Following this, FlinkSQL's aggregation functions aggregate the data by user id and forward it to a topic dedicated to aggregated transactions.
A Kafka consumer, operating within a Python script, accesses this aggregated data, processes it, and readies it for application of the K-means clustering algorithm. Post-clustering, the outcomes are dispatched to a topic containing the latest, compacted data, which can be visualized through any data visualization tool.
Build with Confluent
This use case leverages the following building blocks in Confluent Cloud:
Reference Architecture
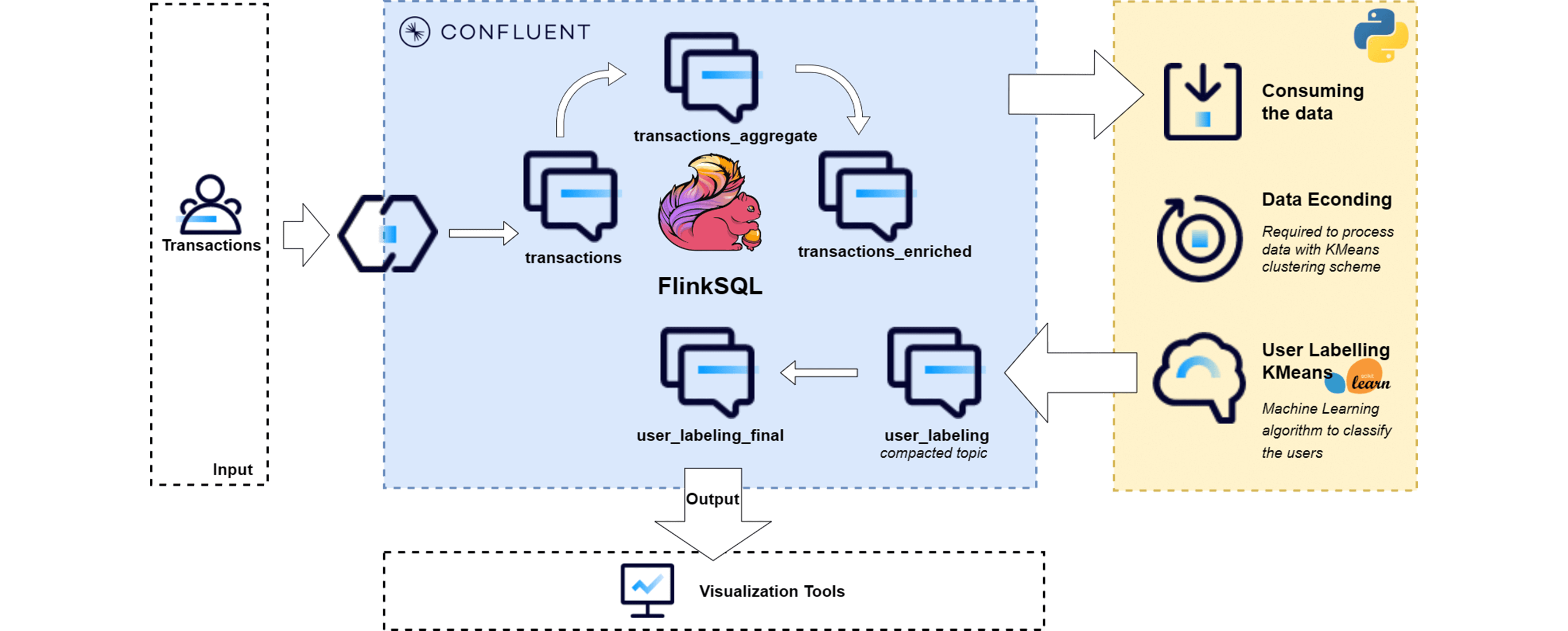
Flink is used to join, window, and aggregate data streams.
Data products for downstream consumption include transactions_aggregate and user_labeling_final.
Resources
Data Reply and Confluent
Streaming UEBA Marketing Analytics
Contact Us
Contact Data Reply IT to learn more about this use case and get started.