Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Bring Real Time to Your Data Lakehouse
Stream from any legacy or modern data system into a cloud data lakehouse. Empower downstream data consumers to use their compute engine of choice while taking advantage of up-to-the-minute data freshness at a fraction of the effort and costs.
Harness the full value of all your downstream compute engines with the real-time data lakehouse
The real-time data lakehouse replaces the antiquated world of batch data warehousing so you can dramatically accelerate your pipelines at a fraction of the cost. Work with batch data just like you work with streaming events, all from a single, central platform.
Ensure downstream access for BI and reporting, analytics, AI/ML and any other use case you need to support with the freshest data.
Eliminate data silos. Do away with outdated, inefficient workflows that silo data from low throughput and high throughput sources, eliminating costly and difficult-to-manage replication of data.
Free your data. Ensure interoperability across clouds, warehouses, query engines and open-source data processing frameworks.
Scale performance, not cost. Cut your data infrastructure costs by 50% or more compared to traditional data platforms by running workloads incrementally on highly optimized compute.
Build with Confluent
This use case leverages the following building blocks in Confluent Cloud:
Reference Architecture
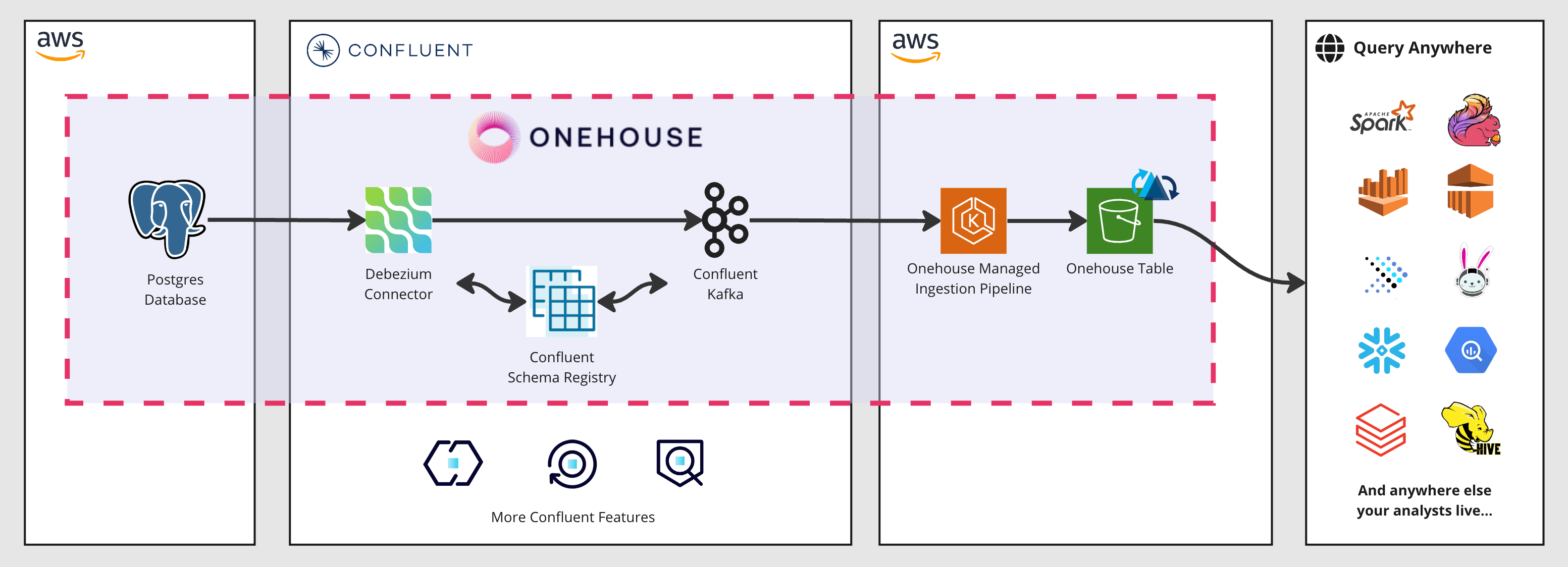
In this example, we are replicating a PostgreSQL database on AWS to the Onehouse Universal Data lake with a Debezium Connector and Confluent Kafka with up-to-the-minute data freshness.
Debezium is an open-source distributed platform for change data capture (CDC).
Onehouse automatically creates a new schema with Confluent’s Schema Registry (Stream Governance). Onehouse manages the Debezium connector, Confluent, and the schema to optimize cost and reduce engineering overhead.
Onehouse will ping PostgreSQL for any inserts, updates, and deletes at the interval you’ve set for up-to-the minute data. You can perform transformations such as masking and deduplication as part of your pipelines, and Onehouse enables you to create validations and quarantine suspicious data, so you can ensure data quality at the point of ingestion.
Onehouse integrates with a number of data catalogs so you can query and process your data downstream with the best tool for the job.