Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
What is Shift Left?
Shift Left in data integration is derived from the software engineering principles of Shift Left Testing where tests are performed earlier in the software development lifecycle to improve quality of software, accelerate time to market, and identify issues earlier. Similarly, Shift Left in data integration is an approach where data processing and governance is performed closer to the source of data generation. By cleaning and processing the data earlier in the data lifecycle, all downstream consumers including cloud data warehouses, data lakes and lakehouses can share a single source of well-defined and well-formatted data. Shift Left provides consistent, reliable, and timely access to important business data where it is needed.
Shift left is an approach to process and govern data near the source and ingest fresh trustworthy data into any downstream consumers including data warehouses, data lakes and lakehouses.
Why is Shift Left Important?
Data has become the single most valuable asset in today's modern business. In the fast-moving world of highly-competitive businesses today, enabling enriched, trustworthy, and contextualized data in real-time, where needed, at any scale, is the difference between growth and stagnation (or worse, failure).
Yet, despite the explosion of tools, data teams struggle to unlock the value of data stored in cloud data warehouses and data lakes which serve as centralized hubs for data storage, data processing and analytics. Over the decades, data management has gotten increasingly complex and organizations are drowning in data complexity; duplication of data is rampant affecting its quality, accuracy and reliability reducing the efficacy of analysis and increasing the overall costs of data storage and processing.
Data lakes have turned into data swamps. Most processes today attempt to clean the vast swamp — an expensive, time-consuming, and error-prone task. Instead, it would be far more effective and efficient to Shift Left and clean the smaller inflow into the lake — producing a faster, less expensive, and higher-quality output.
Old Paradigm: The Challenges with Shifting Right
Historically data engineering teams have relied on Extract-Transform-Load (ETL) pipelines with finite storage and limited compute to take raw datasets from on-premises databases, transform it into the most relevant and load it into expensive data warehouses. An exponential growth in the number of systems (both on-prem and on the cloud) brought about multiple point-to-point ETL processes across the organization creating a giant mess — complicated, expensive, and risky.
In an attempt to alleviate the mess, the next generation of cloud-enabled tools tried to “Shift Right” and centralize all their data into one place before processing for further consumption, often in a multi-hop medallion architecture. Cloud-based data tools enabled plentiful, on-demand, and cheap storage while computers became powerful and supposedly cheaper. The pendulum swung to Extract-Load-Transform (ELT) workloads that ingest a variety of data as-is into a cloud data warehouse or data lakehouse for in-place transformation.
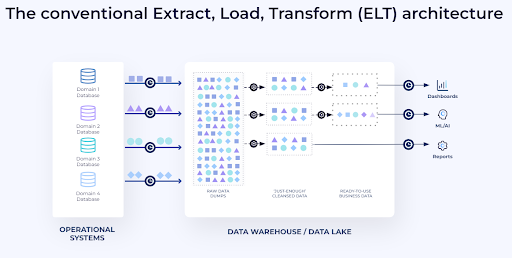
Fig 2. Shifting right to centralize storage and compute in one place
Data continued to explode in volume, variety, and velocity with more and more applications, systems, and teams across the organization requiring access to data for reporting or analytics. The ostensibly cheaper and faster alternative using cloud data warehouses, lakehouses, and ELT pipelines, that enabled accessibility and usage by multiple data teams, ironically turned these systems into data swamps: massive and ungoverned messes with high latency and numerous lower-value workloads dramatically increasing costs. Worse yet, organizations see the need for their data in multiple places by multiple systems and stakeholders, and trip all over themselves rebuilding the same cleaning logic in multiple places using “reverse ETL” pipelines to feed data from lakehouses and data warehouses back to operational systems.
So-called ‘modern’ data stacks of today continue to be built on complex, time-intensive, expensive ELT and batch-based multi-hop data architectures that shift processing downstream to the right, dramatically increasing costs, and limiting innovation and growth.
-
Stale and inconsistent data: Batch processing increases latency and creates low fidelity snapshots leading to poor business decisions made on outdated inputs
-
Redundant processing: Most organizations have multiple downstream systems, including different warehouses, applications or AI platforms. Teams often do the same processing in multiple places or create copies of data to apply processing logic to to meet various use case demands. In addition, when data arrives in micro-batches, additional processing is required to stitch together the incremental changes.
-
Bad data and manual break-fix: The rapid pace of development, frequent changes upstream, and distributed teams often means that data producers and consumers are not communicating effectively, increasing the chances of bad data being generated and proliferated. In a traditional setup, data producers are not involved in what happens downstream and data consumers have very few or no ways to influence the data being produced upstream.
-
Pipeline sprawl: Lack of good documentation on lineage leads to teams adding new “similar-yet-different” pipelines for new use cases, further worsening pipeline sprawl and increasing operational overheads, where expensive resources are spent on managing ETL jobs instead of focusing on innovation.
Organizations that continue to run data processing and governance processes including large, complex, and inefficient batch-based transformations downstream in a data life cycle face:
-
Increased costs from redundant and intensive processing, time spent on low-value tasks, data downtime, and data proliferation
-
Long time-to-value for data engineering teams running business initiatives from complicated batch-processing and redundant efforts
-
Insufficient data adoption due to data integrity challenges and mistrust
-
Sub-optimal innovation and growth: Resources are wasted on low-value activities like data cleaning, and pipeline maintenance instead of building better customer experiences
New Paradigm to Shift Left
Shift Left is a new paradigm for processing and governing data at any scale, complexity, and latency. Shift Left moves the processing and governance of data closer to the source enabling organizations to build their data once, build it right and reuse it anywhere within moments of its creation.
Tools and technologies of the past did not have sufficient capabilities to make most of the data as it is being generated. Organizations have had to make do with a hodgepodge of multiple technologies and tools for each of their needs – be it real-time vs historical, operational vs analytical, governed vs accessible.
The advent of the cloud-native Data Streaming Platform that not only connects and streams data from and to a plethora of systems, but also enables processing and governing of that data continuously in-stream, and creates a world where Shift Left is possible. Shift Left is not just a technology rethink but also breaks down the silos between data producer teams (app developers), data platform teams (who handle the data infrastructure), data engineering teams (who build pipelines to warehouse and lakehouses) and data consumers (data analysts and data scientists)
Shift Left shifts the bronze and silver datasets which require data cleansing, processing and governance to the Data Streaming Platform. Data teams can still use their warehouse and lakehouses to process and prepare the gold level datasets.
Here’s how Shift Left works:
-
Connect and stream data continuously as events are created
-
Use explicit data contracts to promote downstream compatibility and share trusted, high-quality data
-
Data producers clean and apply quality checks upstream with data contracts and data quality rules
-
Data engineers curate, enrich, and transform streams on-the-fly creating reusable data products
-
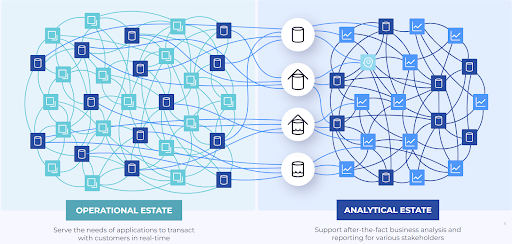
Data consumers use data products as either a stream or as a table unifying operational and analytical data estates
-
Enable self-serve data discovery of data products across multiple teams to maximize data adoption
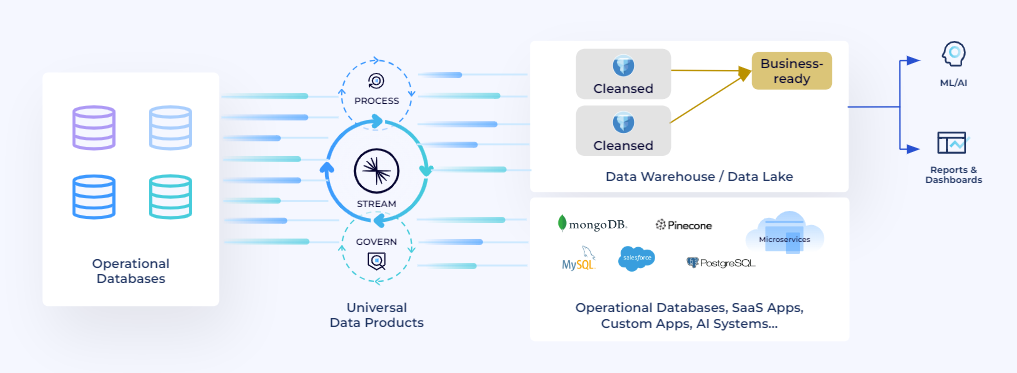
Fig 3. Shift Left to build data once, built it right, and use it anywhere in real-time
Benefits of Shifting Left
Shift Left ensures that data downstream is always fresh and up-to-date; that it’s trustworthy, reliable, discoverable and instantly usable so teams across the organizations can get data insights or build new applications more easily.
Shifting Left eliminates data inconsistency challenges, reduces the duplication of processing and associated costs, prevents data quality issues before they become problematic downstream, and maximizes the ROI of the data warehouse and data lakes.
Shift Left delivers the benefits from batch based legacy approaches without the drawbacks that come with these previous approaches by enabling:
-
A single source of truth upstream, eliminating waste and reducing TCO
-
Governed / bottled-at-the-source data with data contracts
-
Re-usable, high-quality data products that unifies operational and analytical estates
-
Real-time decision making with fresh, trustworthy data
With Shift Left, organizations can free up valuable time and resources and accelerate self-service data access and discovery to decrease costs of existing data infrastructure while enabling faster business decisions and fueling innovation and growth.
Shift Left Use Cases
Reduce cloud data warehouse costs
Move bronze and silver medallion data processing to the stream and deliver cleaned, refined, ready to use data products directly into downstream cloud data warehouses and data lakes.
Real-time analytics
Analyze real-time data streams on-the-fly for real-time reporting or analytics use cases: for example to generate important insights faster such as monitoring campaign performance, identifying patterns for better engagement, or quality alerting.
Data warehouse modernization
Migrating on-prem data warehouse—or connecting data warehouses across clouds (AWS, Azure and GCP)—to unlock analytics and machine learning innovation doesn’t need to be a multi-year lift and shift. Shift Left creates a bridge across your cloud and on-prem environments.
Headless data architectures
By using data contracts, schema registry, and data quality rules on data in flight, Shift Left enables well-defined, well-formatted, and immediately usable data products that can be consumed as streams or tables across multiple downstream systems.
Shifting Left with Confluent
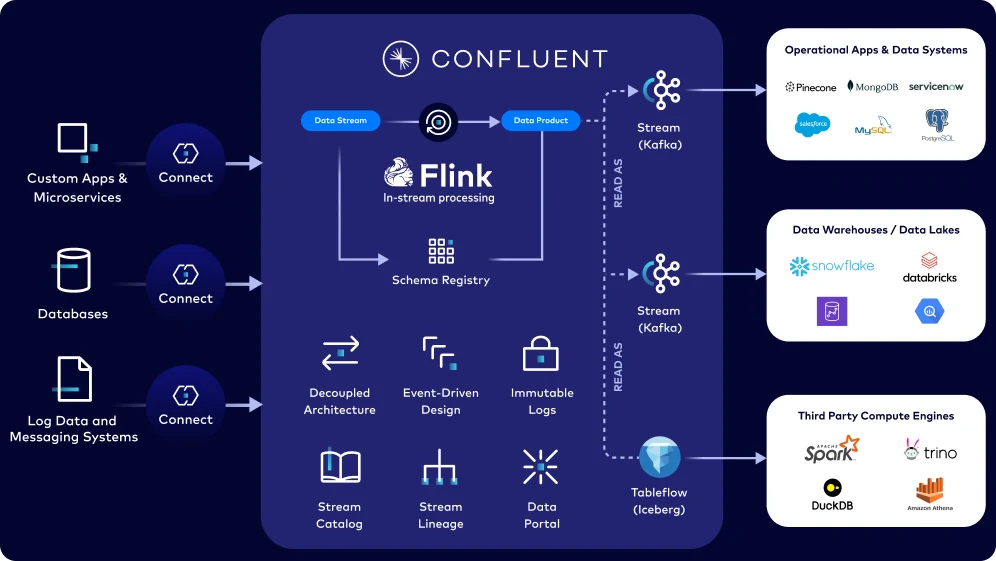
Confluent’s cloud-native, all-in-one Data Streaming Platform supports streaming, connecting, processing and governing all of an organization’s data in real-time and at scale.
Confluent provides the best ecosystem of zero code connectors for data streaming including various CDC connectors to synchronize changes data downstream. Once that data is in Confluent, the schema registry enables quality control, Flink stream processing enables data enrichment and transformation on in-flight data to create ready-to-use reusable data products that can be simultaneously consumed by your operational and analytical systems and applications. And with the simplification of operational data access in the analytical estate with Tableflow, Confluent brings a truly unified view of the data, as a stream or as a table — bringing about a true convergence of the operational and analytical data estates.
-
Connect & Stream real-time data anywhere: Continuously capture and share real-time data everywhere — to your data warehouse, data lake, operational systems and applications.
-
Deliver well-curated, reusable data products: Continuously process data in-stream with Flink the moment it’s created, to shape data into multiple contexts on-the-fly
-
Build trusted, high-quality data products at source: Reduce faulty data downstream by enforcing quality checks and controls in the pipeline with data contracts, schema registry, and data quality rules.
-
Self-service data discovery with Data Portal: Enable anyone with the right access controls to effortlessly explore and use real-time data products for greater data autonomy
-
View Stream Lineage: Understand data relationships and the data journey in visual graphs to ensure trustworthiness
-
Read data products as stream or tables with Tableflow: Simplify representing your operational data as a ready-to-use Iceberg table for analytical systems in just one-click
How Confluent’s definition is different from the “traditional one”
Shift Left in data integration is derived from the software engineering principles of Shift Left Testing where tests are performed earlier in the software development lifecycle to improve the quality of software, accelerate time to market, improve customer experience, and reduce costs. Shift Left Testing became prominent with the advent of agile and DevOps technologies and methodology that aims to produce high-quality software rapidly. In the old scenario, developers code first, and testers test and spot bugs only after the code update is passed on. However, Shift Left initiates testing earlier and more frequently in the development process by integrating testing components to the build and code processes to identify and resolve errors earlier. This not only prevents errors in the end product but also avoids the redesign of a fully developed codebase which can be time-consuming and expensive.
Similarly, Shift Left in data integration is an approach where data processing and governance is performed closer to the source of data generation helping reduce time-to-value, save costs on downstream processing, and drive data adoption and growth. By performing data processing and governance earlier in the stream, Shift Left in data integration reduces bad data proliferation, storage and compute needs in downstream systems.