Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
What is Kafka Dead Letter Queue?
A Kafka Dead Letter Queue (DLQ) is a special type of Kafka topic where messages that fail to be processed by downstream consumers are routed. These messages might fail for a variety of reasons, such as schema validation errors, malformed data, or application logic failures. The DLQ ensures that failed messages do not block the processing pipeline, allowing the system to continue operating smoothly while giving operators a place to inspect and reprocess erroneous messages.
Overview
A Kafka Dead Letter Queue is an essential part of building robust, fault-tolerant data pipelines. Kafka’s distributed nature makes it highly reliable, but that does not mean every message will be successfully processed. Data errors, consumer failures, or unhandled exceptions can cause a message to fail processing. A DLQ serves as the catch-all for such messages, allowing the system to continue functioning while giving operators the tools needed to diagnose and resolve issues.
While Kafka doesn’t natively have DLQ support, organizations often implement DLQ as part of their consumer application logic. Kafka’s consumer offset management and retries are typically extended to accommodate DLQs. In the case of Confluent Cloud, Kafka-managed services offer enhanced DLQ features with built-in monitoring and scalability.
Key benefits of using a Kafka DLQ:
Prevents message loss
Provides clear error visibility
Supports recovery and reprocessing of failed messages
Kafka DLQ Architecture Overview
In Kafka, a Dead Letter Queue (DLQ) is usually implemented by creating a dedicated Kafka topic where failing messages are sent. A well-architected DLQ system will include several components:
-
Producers: The applications or systems that produce messages to Kafka topics.
-
Consumers: These applications consume the messages from Kafka topics and process them.
-
Error Handler: The mechanism that catches exceptions or failures during message processing and decides whether to route messages to the DLQ.
-
DLQ Topic: A specific Kafka topic designated to store messages that could not be processed.
When a message fails, an error handler is invoked in the consumer application, which can then write the message to the DLQ. Some systems implement retry logic before finally sending a message to the DLQ after a specified number of retries.
Confluent Cloud’s managed Kafka services enhance this architecture by providing seamless integrations, better scaling, and enhanced monitoring tools like cloud native GUI, CLI and the metrics API to monitor DLQ health and troubleshoot issues.
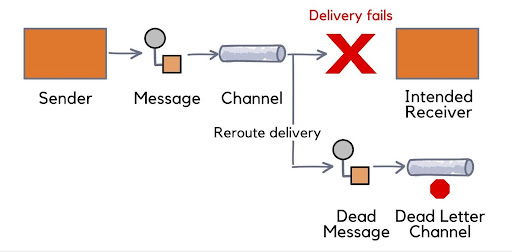
Why Use a Kafka Dead Letter Queue?
There are several reasons why incorporating a Kafka Dead Letter Queue into your system design is essential:
-
Fault Tolerance: Kafka DLQs help ensure that failures in message processing do not impact the overall system.
-
Data Integrity: They provide a safe storage location for messages that cannot be processed, preserving data integrity.
-
Monitoring and Troubleshooting: DLQs allow teams to monitor failed messages and analyze why they failed, making debugging easier.
-
Scalability: By offloading failed messages to a DLQ, the system avoids backlogs and can scale without being overwhelmed by error conditions.
Kafka DLQs provide flexibility by allowing you to set retry policies, timeouts, and other parameters based on the failure type, ensuring more granular control over message flow.
Configuring a Kafka Dead Letter Queue
Configuring a Kafka Dead Letter Queue generally involves a few key steps:
-
Define a DLQ Topic: First, create a separate Kafka topic to store the messages that fail processing.
-
Error Handling Logic: Implement error handling in your consumer application to catch message processing failures. This can include catching deserialization errors, schema validation errors, or exceptions triggered by business logic.
-
Routing Logic: Define the logic that determines when a message should be sent to the DLQ. This often involves setting up retry policies before a message is moved to the DLQ.
-
Offset Management: Ensure that consumer offsets are managed correctly to prevent message duplication when retrying messages from the DLQ.
Example:
To configure a DLQ in Confluent Cloud:
-
Use Kafka Connect for connecting source systems to your Kafka topic, and configure a custom error handler to push failed records to a dedicated DLQ topic.
Use Kafka Streams or other frameworks to build custom retry and failure handling mechanisms.
Best Practices for Implementing Kafka DLQ
Here are some best practices for successfully implementing a Kafka Dead Letter Queue:
Set Retrying Limits
Always implement retry logic with a defined limit before sending messages to the DLQ. This prevents infinite loops and ensures that only irrecoverable messages end up in the DLQ.
Use Schema Validation
Incorporate schema validation using Confluent Schema Registry to ensure that messages adhere to the expected format.
Monitor DLQ Health
Continuously monitor the health of the DLQ topic, including message volume, processing times, and consumer health.
Leverage Confluent Cloud Features
If using Confluent Cloud, take advantage of built-in tools like Control Center to manage and monitor your DLQ seamlessly.
Monitoring and Troubleshooting Kafka DLQ
Monitoring the Kafka DLQ is vital to ensure that it is functioning properly. Some monitoring tips include:
-
Message Count and Size: Keep track of the number of messages and their size in the DLQ to avoid overflow.
-
Error Patterns: Use tools like Confluent Cloud UI to identify patterns in failed messages and correlate them with upstream issues.
-
Alerting Systems: Set up alerting for sudden spikes in DLQ message volume to catch errors early.
-
Retry Logic Performance: Monitor the effectiveness of retry mechanisms to ensure that messages in the DLQ are eventually processed or handled.
Troubleshooting DLQ issues typically involves:
-
Identifying the failure source (e.g., deserialization errors, network issues).
-
Investigating failed messages to determine why they could not be processed.
-
Debugging the consumer or processing pipeline.
Handling DLQ Messages
Once a message enters the Kafka DLQ, it is essential to handle it correctly:
-
Investigate the Error: Examine why the message failed by analyzing the error logs and the message content.
-
Reprocess or Fix the Message: Depending on the failure type, messages in the DLQ can either be reprocessed after fixing the error or discarded if deemed unnecessary.
-
Manual Intervention or Automation: In some cases, messages may require manual intervention to fix, while in other cases, automated scripts can be used to reprocess messages in the DLQ.
Using tools like Confluent Cloud’s Schema Registry and Kafka Streams, you can automate the processing and error resolution for DLQ messages.
Use Cases
Kafka Dead Letter Queues are used in various scenarios, including:
Schema Evolution
When messages do not adhere to the new schema, they are sent to the DLQ.
Data Validation Errors
If business rules or validation checks fail during message processing.
Consumer Failures
When a consumer application experiences errors such as resource limits, timeouts, or bugs, the message is sent to the DLQ.
Message Transformation Failures
If transformations or aggregations on a message fail, it is routed to the DLQ.
Alternatives to Kafka DLQ
While Kafka Dead Letter Queues are a common solution for error handling, there are other alternatives:
Retry Queues
Some systems use retry queues where failed messages are placed temporarily for retries before reaching a DLQ.
Event Sourcing
Instead of using DLQs, some systems use event sourcing, where the state of an event is always stored, allowing for later reprocessing.
Other Messaging Systems
Some organizations may use other message queuing technologies such as RabbitMQ or AWS SQS for error handling.
Conclusion
Kafka Dead Letter Queues are a powerful and necessary tool for managing message processing failures in Kafka-based systems. By isolating problematic messages and allowing for retry and debugging, DLQs help maintain the integrity and reliability of the entire data pipeline. Configuring and managing DLQs effectively ensures that Kafka systems remain robust, scalable, and fault-tolerant. Whether you are using Apache Kafka on-premises or through a managed service like Confluent Cloud, implementing a Kafka DLQ is a critical step in building resilient data streaming applications.