Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
How Tencent PCG Uses Apache Kafka to Handle 10 Trillion+ Messages Per Day
As one of the world’s biggest internet-based platform companies, Tencent uses technology to enrich the lives of users and assist the digital upgrade of enterprises. An example product is the popular WeChat application, which has over one billion active users worldwide. The Platform and Content Group (PCG) is responsible for integrating Tencent’s internet, social, and content platforms. PCG promotes the cross-platform and multi-modal development of IP, with the overall goal of creating more diversified premium digital content experiences. Since its inception, many major products—from the well-known QQ, QZone, video, App Store, news, and browser, to relatively new members of the ecosystem such as live broadcast, anime, and movies—have been evolving on top of consolidated infrastructure and a set of foundational technology components.
Apache Kafka® at Tencent PCG
At our center stands the real-time messaging system that connects data and computing. We have proudly built many essential data pipelines and messaging queues around Apache Kafka. Our application of Kafka is similar to other organizations: We build pipelines for cross-region log ingestion, machine learning platforms, and asynchronous communication among microservices. The unique challenges come from stretching our architecture along multiple dimensions, namely scalability, customization, and SLA. Here are some of the notable requirements:
- Workload. It takes close and continuous observation to fully grasp the dynamics of data in complex apps. In a highly seasonal and eventful environment of consumer internet with over a billion monthly active users, product promotion and large-scale experimentations often cause volume to burst up 20x from one day to another. At the peak, our pipeline needs to transfer 4 million messages per second (or 64 gigabytes/second) for a single product. Our ops team, therefore, is challenged with managing and optimizing clusters with more than a thousand physical nodes in total.
- Low latency and high SLA. As the organization moves quickly toward leveraging real-time analytics for driving business decisions, the requirements of data accuracy and timeliness become more rigid than before. Imagine when a video-consuming event is fed to the recommendation algorithm or when discovering hot trends that guide the incentivisation of content supply—it is desirable that the data can be used within a few seconds since its emission and with an end-to-end loss rate as low as 0.01%.
- Flexibility. Nowadays real-time data processing architectures are componentized and configurable. Consequently, the messaging system needs to handle frequent changes in the number of consumers, access pattern, and topic distribution without impacting performance. We cannot simply optimize the system for a static topology as a traditional ingestion pipeline.
Ideally, we need a multi-tenant, gigantic pub/sub system to satisfy all these requirements. At peak time, it should reliably support data transfer at hundreds of gigabits per second. It should be provisioned almost instantly without disrupting existing workload; it also needs to tolerate single-node and cluster failure. Considering interface concerns, we want it to be compatible with the Kafka SDK as much as possible. After exploring the limitations of a single Kafka cluster, we’ve moved forward with a series of developments.
Federated Kafka design
We chose to develop in the Kafka ecosystem for its maturity, rich set of clients and connectors, as well as superb performance among alternatives. On the other hand, there are a few gaps in using Apache Kafka to meet the requirements above. For instance, more than expected, we found during heavy usage that multiple disk failures caused insufficient replica or even cluster-level reliability problems. Moreover, expanding the capacity of a cluster (i.e., adding brokers) requires significant data rebalancing, often imposing hours of operational latency. Without fully automated capacity management, this greatly limits how we can support a large business.
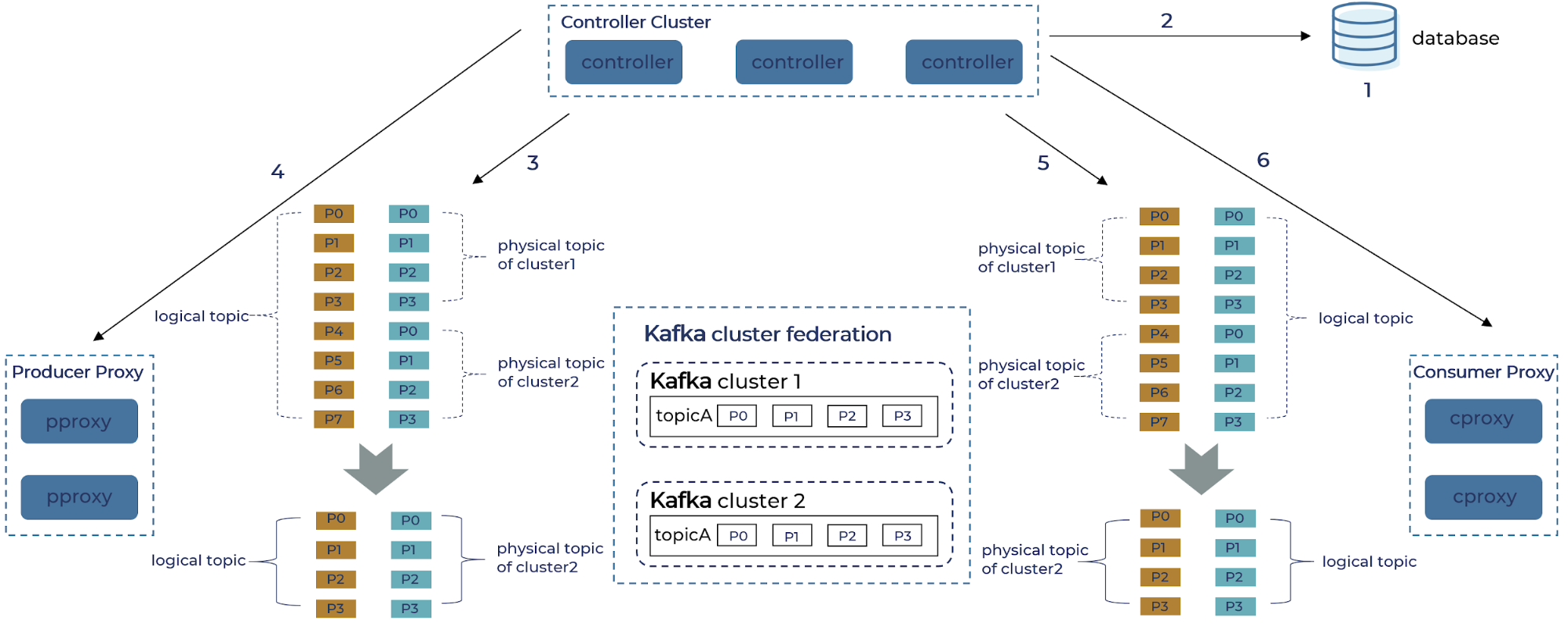
Given that we decided to focus our initial enhancement on scalability and failure tolerance, we started off building a proxy layer that federates multiple Kafka clusters and provides compatible interfaces to both providers and consumers. The proxy layer presents logical topics to Kafka clients and internally maps them to distinct physical topics in each Kafka cluster. In the figure below, a logical topic with eight partitions (P0–P7) is distributed to two physical clusters each with four partitions (P0–P3).
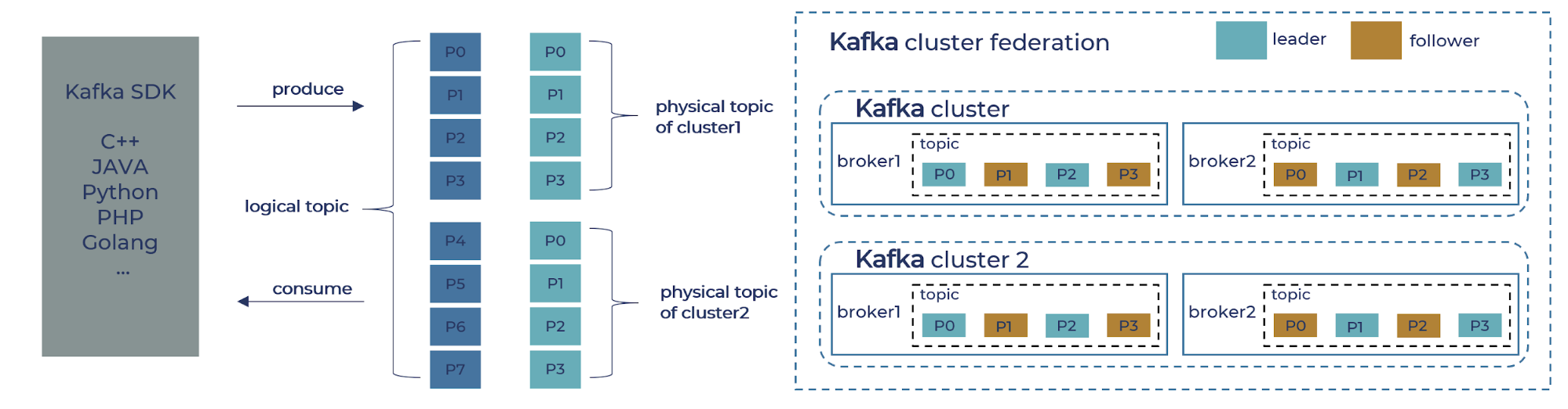
The extra layer of abstraction of logical topics allows us to achieve the following, desirable behavior. First, we can expand the capacity of the data pipeline with little (re)synchronization overhead. In case two clusters at their maximum size cannot handle the predicted peak volume, we can easily deploy two additional clusters without shuffling any existing data. Second, fault tolerance is easier to manage with smaller clusters, as we can provision extra capacity at fine granularity and redirect traffic at a low cost. Lastly, in the (not-so-rare) event of physical cluster migration, the transparent proxy eliminates the need for any code and configuration change on the application side. We would only need to set the old clusters in read-only mode before it is completely drained, while associating the proxy with the new clusters. Such maintenance is not visible from the perspective of logic topics.
Key components and workflows
In this section, we get into more details of the new components we built and how they interact in essential scenarios, as shown in the figure below. Two proxy services, one for the producer (pproxy) and another for the consumer (cproxy), implement the core protocols of the Kafka broker. They are also responsible for mapping logical topics to their physical incarnation. The application uses the same Kafka SDK to connect directly to the proxy, which acts as a broker.
In order to address the set of proxy brokers, we built a lightweight name service that maintains this relationship between client ID and the collection of proxy servers. The SDK will request the list of proxy brokers using client ID once at the beginning of the communication. Internally, the most complicated and bulky part of our implementation involves managing the metadata of the federated cluster, including both the state of the topics as well as the lifecycle of the proxy nodes. We extract the logic of the Kafka controller node (such as topic metadata) into a separate service, which is also called “the controller,” but it is different from Kafka’s own controller functionality. This service is responsible for collecting the metadata of physical clusters, composing the partition information logical topics, and then publishing it to the proxy brokers.
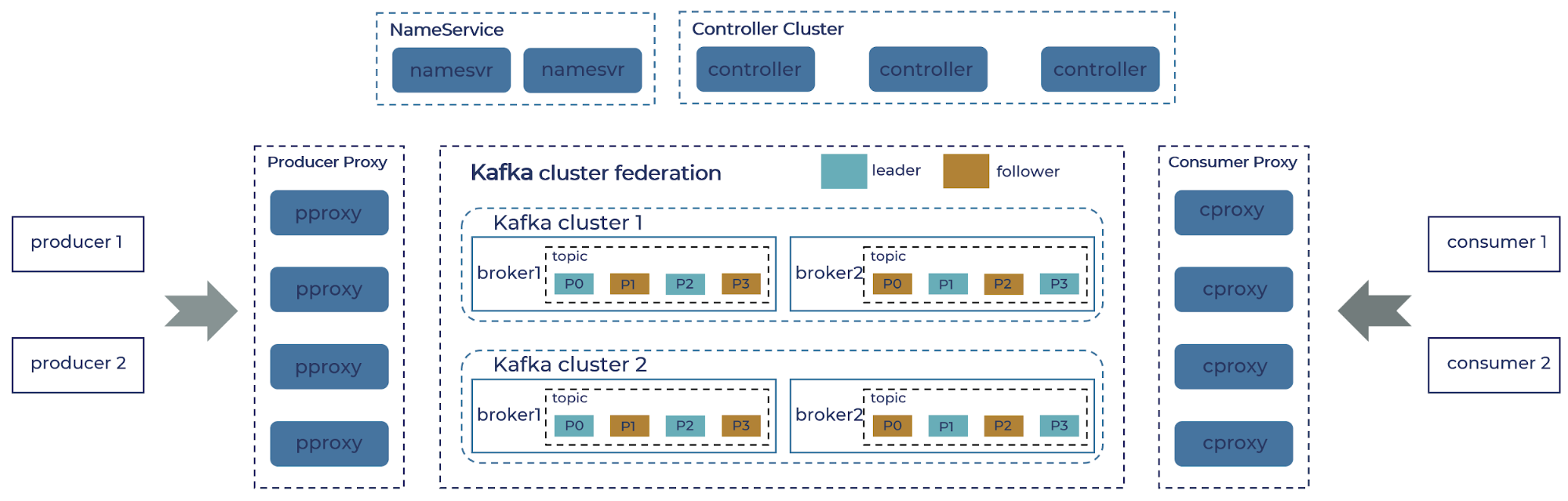
We see some examples of interactions among these components and the Kafka clusters underneath during the most common operations:
- Logical topic metadata retrieval
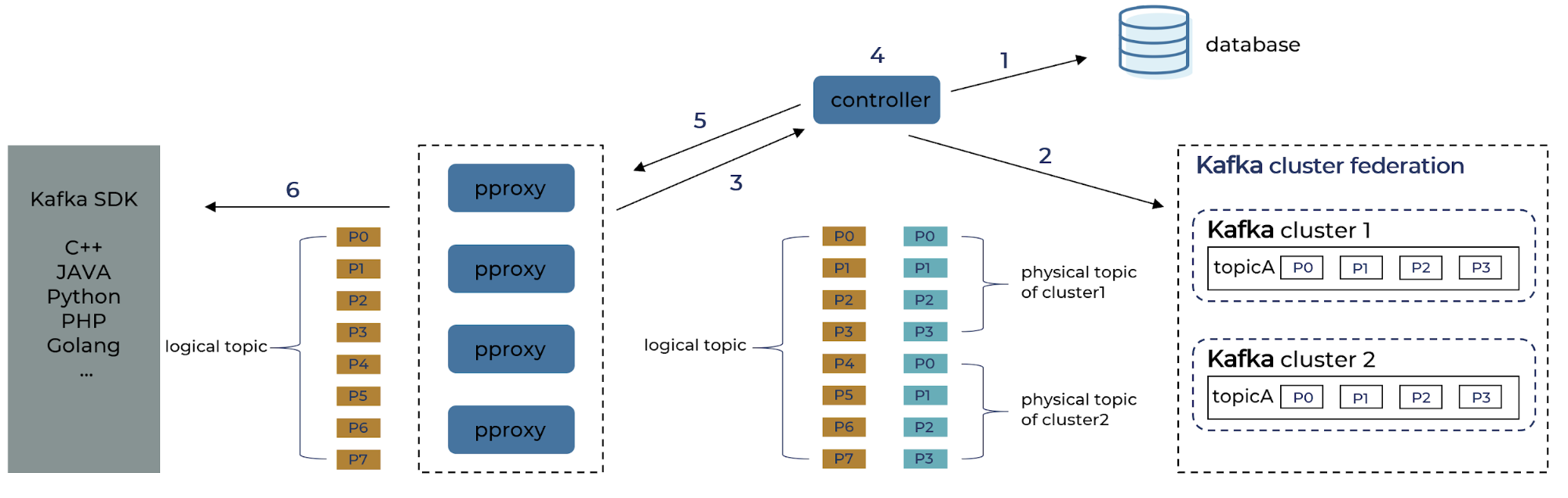
1. Controller reads the mapping between logical topic and physical topic from the config database.
2. Controller scans metadata of all physical topics from each Kafka cluster.
3. Controller finds the list of available pproxy from heartbeat message.
4. Controller composes the metadata for the logical topics.
5. Controller pushes both the topic mapping and topic metadata to proxy brokers.
6. The metadata is sent to the Kafka SDK.
- Cluster provisioning workflow
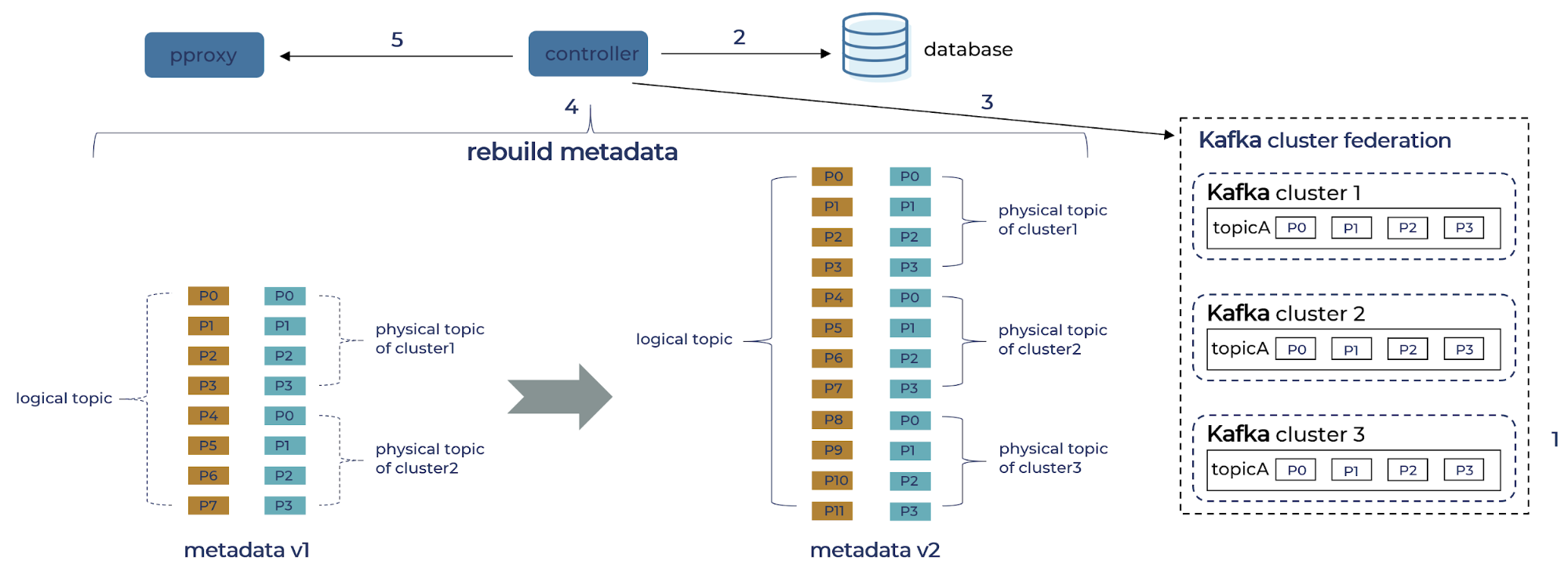
1. An empty cluster (cluster 3) is provisioned and added to the existing federation of cluster 1 and cluster 2.
2. Controller loads the mapping from logical topics to physical topics from the config database.
3. Controller loads metadata from physical topics from cluster 3.
4. Controller reconstructs metadata by merging the result of 2, incrementing the version.
5. Controller publishes the new version to proxy brokers, which will be visible to the SDK after the client refreshes. - Cluster decommission workflow
1. Controller marks the cluster (cluster 1) to be decommissioned in read-only mode in the config database.
2. Controller picks up this state change when it fetches the metadata from the database.
3. Controller reconstructs metadata for producers, removing cluster 1 from the physical clusters.
4. Controller pushes a new version of producer metadata to the proxy. At this moment, data stops being written to cluster 1, while the consuming side is not impacted.
5. While all topics in the cluster are expired, the controller reconstructs the consumer metadata again and removes the physical topics no longer valid.
6. Consumer proxy loads the new metadata and now when the new consumer arrives, it will no longer pick up cluster 1. This completes the decommission operation.
Federated Kafka in practice
Over the past year, we have gradually onboard many products in Tencent PCG to use the federated Kafka solution. Alongside the cluster, we have also been developing better monitoring and automated management tools. Our design principles have been quickly validated by many critical business use cases such as real-time analytics, feature engineering, and more. Up to now, we have deployed a few hundreds of clusters of various sizes, which collectively handle more than 10 trillion messages every day. The following table summarizes our typical setup and operational benchmarks.
| Average time to initialize a federated cluster | 10 minutes |
| Average time to scaling up a federated cluster (add one physical cluster) |
2 minutes |
| Metadata refresh latency | ~1 second |
| Maximum physical clusters per logical cluster | 60 |
| Brokers per physical cluster | 10 |
| Total number of brokers provisioned | ~500 |
| Max cluster bandwidth (CPU ~40%) | 240 Gb/s |
| Proxy overhead | Same as Kafka broker |
There are two notable limitations of the first design composed of cluster federation with a proxy layer. First, the distribution of logical partitions is not transparent to clients who use a hash key to specify the partition when producing a message. Consequently, when we add a new cluster, messages with identical keys might be delivered to different partitions and hence get out of order. This did not turn out to be a blocker for our current use cases for two reasons. First, we surveyed the product teams and found that they only use keyed messages occasionally. Furthermore, when they face the trade-off between application-level fault tolerance and scalability, they typically prefer the latter and sometimes settle with a mechanism to briefly halt production when cluster membership is updated.
A more fundamental limitation is that we have to frequently evolve the interface of the proxy broker as more functionalities need to be exposed and as native Kafka evolves. This leads to unnecessary code duplication and makes the whole system harder to manage. In the future, we will explore implementing similar semantics inside Kafka, as described in the next section.
Next steps
As we explained above, Tencent is one of the largest Kafka users in the world, processing trillions of messages every day. This also means that to power our many use cases, we have successfully pushed some of Kafka’s boundaries. We are aware of the ongoing development and proposals within the Kafka community, and we further find that some of our ideas, such as abstracting out the controller and shard in traffic across multiple controllers, are along the same lines as what the community is moving toward. We may see significant benefits if our federation solution integrates with new features like Tiered Storage (KIP-405) and ZooKeeper removal (KIP-500), and we look forward to contributing what has been proven to help Tencent back into the community.
Conclusion
In this article, we introduce our journey of building federated Kafka clusters for business use cases that require high scalability and fault tolerance. Through a strong engineering solution and investment in the operation, we are bridging the gap and supporting the continued growth of Tencent PCG. Our experience has reassured our confidence in the Kafka ecosystem and shed light on how we can further extend its capabilities. We will continue our development along this direction.
Start building with Apache Kafka
If you want more on Kafka and event streaming, you can check out Confluent Developer to find the largest collection of resources for getting started, including end-to-end Kafka tutorials, videos, demos, meetups, podcasts, and more.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.



Predictive Analytics: How Generative AI and Data Streaming Work Together to Forecast the Future
Discover how predictive analytics, powered by generative AI and data streaming, transforms business decisions with real-time insights, accurate forecasts, and innovation.