Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Streaming ETL with Confluent: Routing and Fan-Out of Apache Kafka Messages with ksqlDB
In the world of data engineering, data routing decisions are crucial to successful distributed system design. Some organizations choose to route data from within application code. Other teams hand off the routing of data to a different process after application code has transmitted messages to a central store, like an Apache Kafka® cluster.
Several Confluent customers have requested assistance in routing data internally using ksqlDB. Specifically, they have engaged with Confluent Professional Services to review two patterns:
- Filter out messages so that downstream applications don’t have to, and process them right away
- Make copies of the messages and send them to multiple target topics (fan-out)
Both of these patterns are easily implemented using the event streaming database ksqlDB, which is available as a fully managed service in Confluent Cloud. If you prefer to self-manage your infrastructure, you can deploy ksqlDB yourself in your own datacenter or private/public cloud through Confluent Platform. So, I’ll walk through how both patterns could be achieved using ksqlDB.
Prerequisites to follow along:
- Basic knowledge of Apache Kafka
- Basic knowledge of persistent, pull, and push queries in ksqlDB
- A running Confluent Cloud cluster or a self-managed Confluent Platform cluster
- A single-node ksqlDB cluster
- A source topic
- One or more target topics
To quickly set up a sample cluster, use one of the two methods below:
- Try out Confluent Cloud for free. When you sign up, you’ll receive $400 to spend within Confluent Cloud during your first 60 days. If you use the promo code CL60BLOG, you can get an additional $60 of free usage.*
- Use docker-compose by following the official guide.
Now let’s get started.
Routing messages
Some companies might have a giant topic with messages from a single source. But not all their downstream applications need all the messages from this topic. To help downstream applications efficiently get only the messages they need, they have a few choices:
- Customize producers and let them produce to different topics given the condition
- Customize consumers to filter out the messages that they don’t need
- Utilize ksqlDB to quickly set up a few streams in order to perform that for you
There are three pieces of information that we need to route from a source topic to a target topic:
- Source topic name: the stream initially created pulls messages from this source topic
- Target topic identifier (not necessarily a name): when this gets matched, the data will go to the target topic
- All target topics: to set up streams, which flow data into each one of them
Here’s a sample JSON message:
{
"targetTopic": "topic-1",
"content": "foo"
}
If you would like, you can also put the target topic information inside the message produced to Kafka. However, that will require you to use regular expressions later on to extract the information that you need. Beware that introducing the use of regular expressions in an event streaming application can have severe performance implications.
Step 1: Create a stream in ksqlDB for the source topic
This is needed to get all the messages from the source topic.
If you are using the sample message from earlier, it will look like this:
CREATE STREAM source_stream ( targetTopic varchar, content varchar ) with ( kafka_topic='source-topic', value_format='JSON' );
source_stream is simply any name that you desire for this stream, and source-topic is the topic that you are getting your messages from.
value_format='JSON' means that we are reading the messages as JSON. Thus, we can pick up the field directly inside CREATE STREAM. If your message has no particular format and includes your target topic information, you should use 'KAFKA'.
After the stream is successfully created, it will receive all the messages being sent to the source topic. You can validate it by using this query:
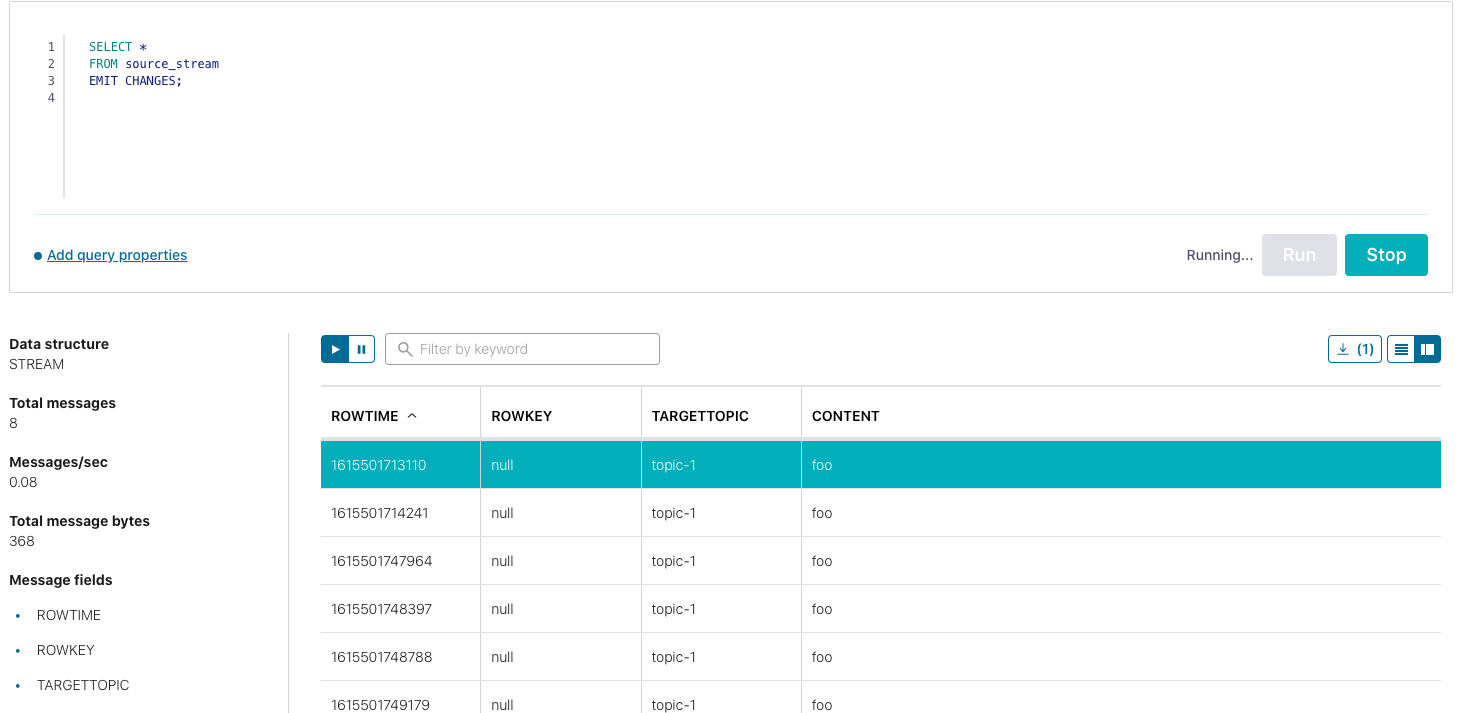
SELECT * FROM source_stream EMIT CHANGES;
The result will look like this on the cloud:
Step 2: Create a stream for each target topic
Once you have validated that the source stream is working properly, create a stream for each target topic that needs to receive the routed message. It will look like this if you are using the sample JSON message:
CREATE STREAM target_stream_1 with
(kafka_topic='topic-1', VALUE_FORMAT='KAFKA') AS # KAFKA is the part to get rid of the wraps;
SELECT content
FROM source_stream
WHERE targetTopic = 'topic-1'; # The filtering part;
Where target_stream_1 is any target stream name that you desire, topic-1 is the topic you want the message to go to, source_stream is the stream that you created in step 1, and topic-1 is an arbitrary string that you want the field to match in order for the message to be routed.
VALUE_FORMAT='KAFKA' will output your message in its raw form. For example, if your content has an XML format, then the new message passed down will be this:
<xml>sample xml</xml>
If you want it to be wrapped around JSON like it was before, then use JSON:
{
"content": "<xml>sample xml</xml>"
}
That’s it! Your incoming messages will be routed by these stream applications, respectively.
Here’s a high-level overview of what’s happening:
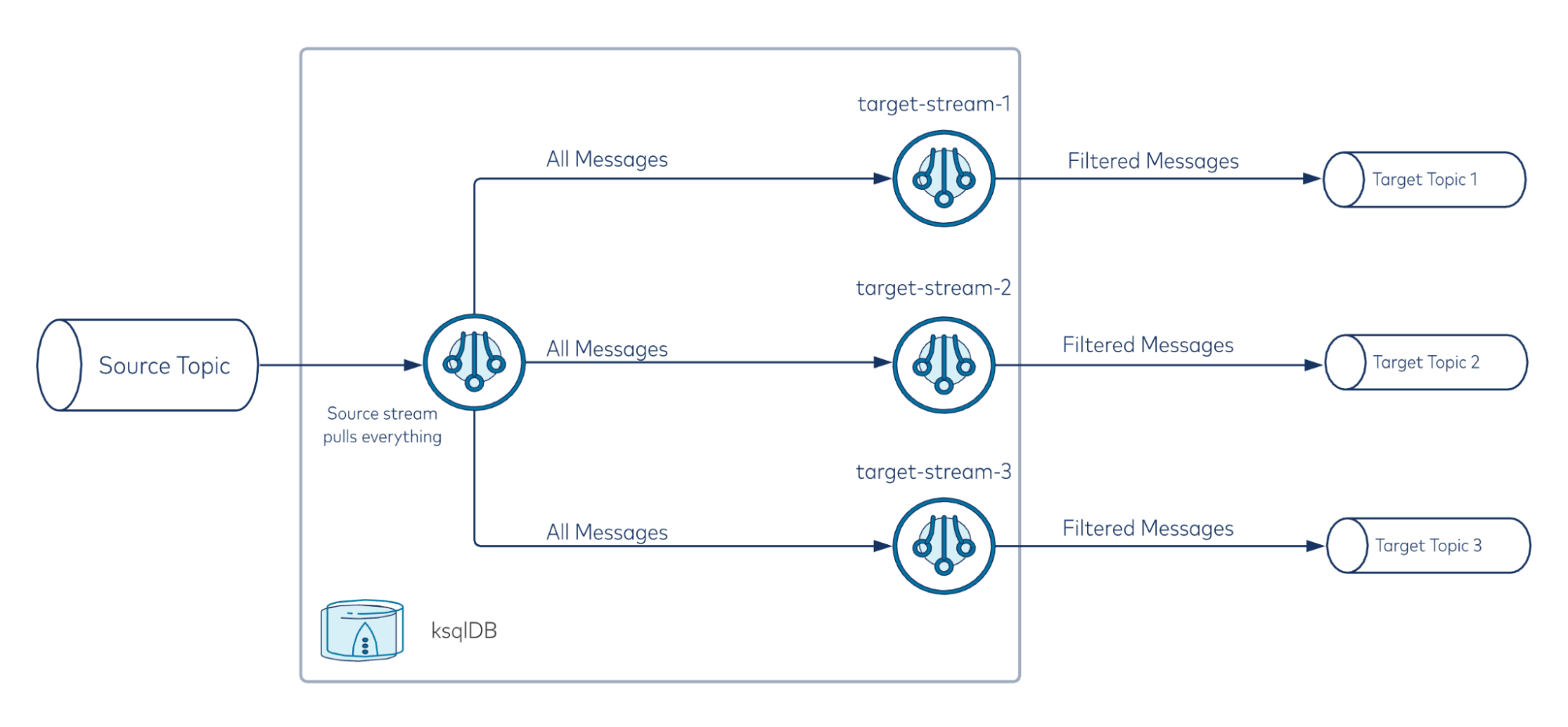
Regex option
If you feel strongly about removing the field "targetTopic": "topic-1" and don’t mind the performance impact, you can put the target topic information within the content field. Then the sample message will look something like this:
{
"content": "target-topic,foo"
}
You can change the target stream creation above into something along these lines:
CREATE STREAM target_stream_1 with
(kafka_topic='target-topic', VALUE_FORMAT='KAFKA') AS
SELECT content
FROM source_stream
WHERE REGEXP_EXTRACT('target-topic', content) = 'target-topic';
If you take this approach, confirm what your performance requirements are and test out the performance impact that this will have on your use case.
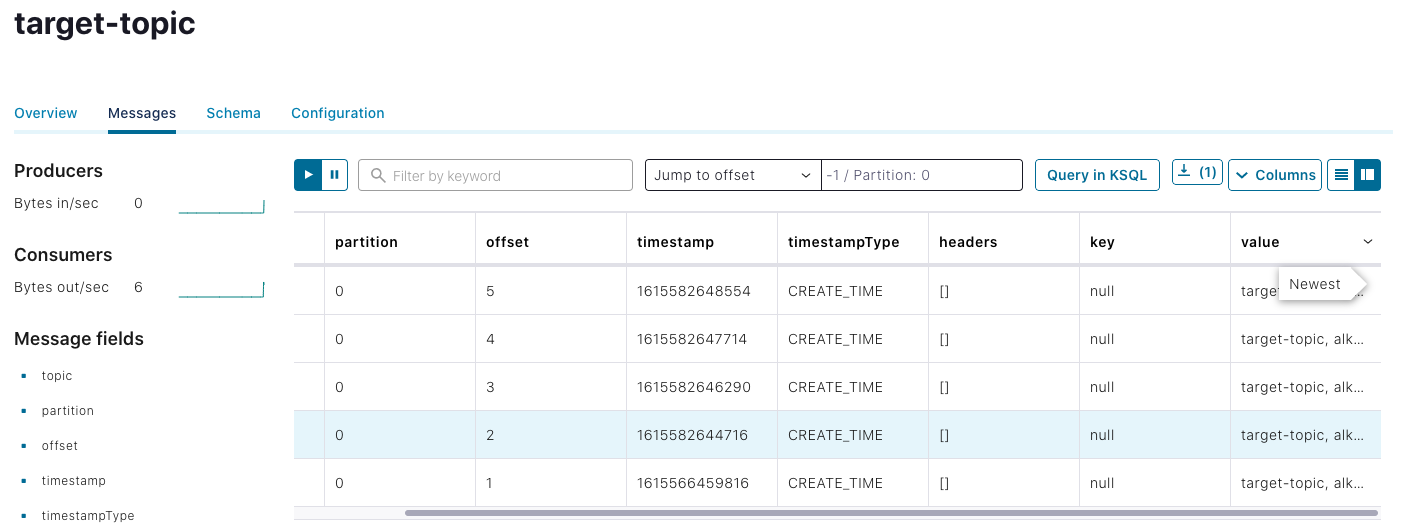
To test if the topics are receiving the correct messages, simply go to the Confluent UI’s topic section to read the messages. Remember to set offset to -1 so that all messages will be shown. The output will resemble this:
Fan-out messages
At times, companies need exact copies of topics within a single cluster and to constantly sync them. To achieve this, either (1) same messages are produced to multiple topics from the producer side or (2) you can utilize ksqlDB to create them and keep them constantly in sync.
Now that we know how to route the message, it’s clear that it is easier to fan out the message because we don’t need a logic condition on where the messages are going. They will be going to all target topics. Therefore, we only need two details:
- Source topic name
- All target topics
Follow the steps below to fan out the message.
Step 1: Create a stream in ksqlDB for the source topic
As before, we have to create a stream for the source topic to get the messages out:
CREATE STREAM source_stream ( content varchar ) with ( kafka_topic='source-topic', value_format='JSON' );
Note that we no longer need the target topic information here. Also, bear in mind that the stream creation content is based on your message. You can learn more about how to properly create a stream in the documentation.
Step 2: Create a stream in ksqlDB for each target topic
You’ve probably already guessed what comes next. Because fan-out requires no additional logic, we can create a stream for each of the target topics with this query:
CREATE STREAM target_stream_1 with
(kafka_topic='topic-1', VALUE_FORMAT='KAFKA') AS
SELECT content
FROM source_stream;
Make sure all of your stream names are unique and replace topic-1 to your desired topic names.
Final considerations
Although routing and fan-out is possible using ksqlDB, there are a few pros and cons to consider before you take this approach.
The good
- Can be set up in minutes by writing a few SQL-like queries
- Easily scalable by writing ksqlDB scripts and/or standard scripts utilizing ksqlDB REST APIs
- No development work required given that ksqlDB is already part of Confluent Platform and Confluent Cloud
- Less maintenance work because ksqlDB is being managed as part of Confluent Cloud
The bad
- Each stream is an application, which makes it less memory efficient due to application memory overhead. It is advised to monitor ksqlDB as your streams grow.
- There are limits to how many streams you can create on Confluent Cloud. To avoid this, you can set up your own ksqlDB cluster to connect Confluent Cloud.
This is just the tip of the iceberg of what ksqlDB can do. Ready to check it out for yourself? Head over to ksqlDB.io to get started!
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.