Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Migrating Kafka to the Cloud: How Skai Went From 90K to 1.8K Topics
Imagine managing an online advertising campaign using an interactive tool that lets you pivot, analyze, filter, and display your campaign’s performance across all online channels. The tool surfaces interesting insights, and lets you react using automated actions. But as you begin to fire up additional features and accrue more data, you start to notice that each action is taking longer than it should, and that your UI is updating more and more slowly.
As a client, we bet you would be very frustrated—we know we would. We bet that you would also be frustrated as a developer of such a tool, when you know that there are many more useful features and improvements to come, and that the systems won’t be able to handle them.
We are the team behind Skai’s omnichannel advertising platform, and we were confronted with this situation a few years ago. So we started to look for solutions. Essentially, we knew that our relational databases couldn’t scale enough to support the requirements of flexible slice-and-dice capabilities over ever-growing datasets.
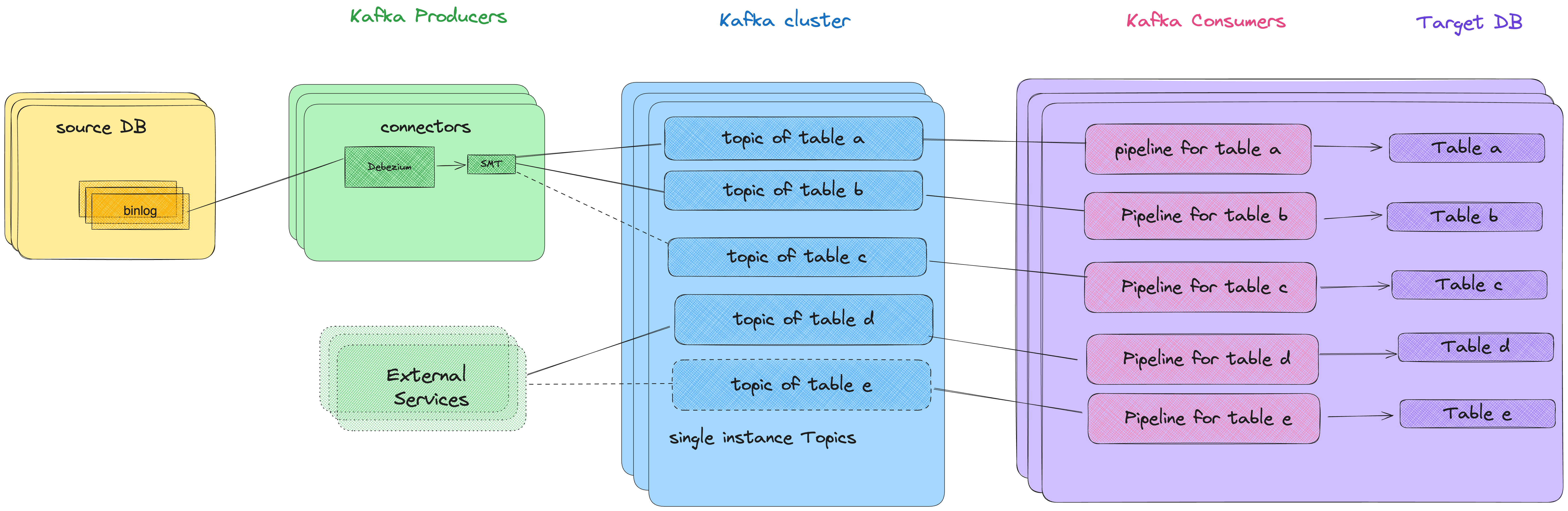
After investigating the problem further, and creating a few POCs, we decided to try change-data-capture (CDC) replication to a fast in-memory database, using Apache Kafka® with a Debezium connector. We implemented this with a few of our big clients first, knowingly starting with a simple and naive approach to ensure single-tenant isolation—by creating a dedicated topic for each tenant table. Performance improved dramatically.
Below is a diagram of our initial end-to-end (E2E) architecture, where you can see that each table has its own dedicated topic and “pipeline.” A pipeline is a database component that continuously loads data as it arrives from external sources (Kafka in our case), into a table. It’s robust and scalable, and supports fully distributed workloads.
Alongside this effort, we also started to investigate managed cloud solutions for Kafka, so that we could get rid of maintenance overhead and operate everything easily.
The problem
After a while, we realized that all of our clients would eventually need this significant improvement, since they all wanted more and more features—meaning more tables. With around 600 tenant instances, each with 150 tables replicated through Kafka, we’d need around 90K application topics (600*150), before replication factor(!)—and more than 60 brokers in the cluster to support them.
Our average Kafka write rate was 13 MB/sec, with some peaks up to 20-22 MB/sec, and our daily traffic was around 2 TB. Considering those numbers, obviously the cost of 60 brokers and the overhead of managing 90K topics wasn’t justified.
The main challenges we faced were:
High maintenance costs: A huge number of topics and brokers makes a cluster very hard to rebalance and monitor, and makes quickly fixing failures difficult in a production environment.
Inefficient utilization: Our daily 2 TB traffic didn't justify such a robust cluster with 90K topics and 60 brokers.
Slow metadata operations: Adding a new table across all tenants required creating hundreds of topics and could take up to an hour, piling up the connector requests queue.
As mentioned, we were simultaneously considering migrating Kafka to the cloud, since we preferred a SaaS solution with a positive ROI. We looked for a solution that would let us focus on reaching our business goals—while leaving infrastructure management and upgrades to others.
We evaluated a few streaming options, but we liked the professional service we received from Confluent, and we found that its solution suited our needs the most. However, during a successful POC, we noticed two issues that we needed to address before migrating Kafka to the cloud:
Confluent has a hard limit on topics per cluster, thus our setup would require multiple clusters, along with a topics and connectors distribution manager.
Our architecture wasn't cost-effective. Each CKU (Confluent’s virtual hardware unit) supports 4.5K topics, 50MB/sec writes, and 150 MB/sec reads. With those limits, we would need a bloated cluster with 1 GB/sec writes (much more than necessary), merely to support our topic count.
In summary, in order to adhere to Confluent’s guidelines, and to improve our ability to manage and support our cluster, we had to find an architecture that would drastically reduce our number of topics.
Initial solution
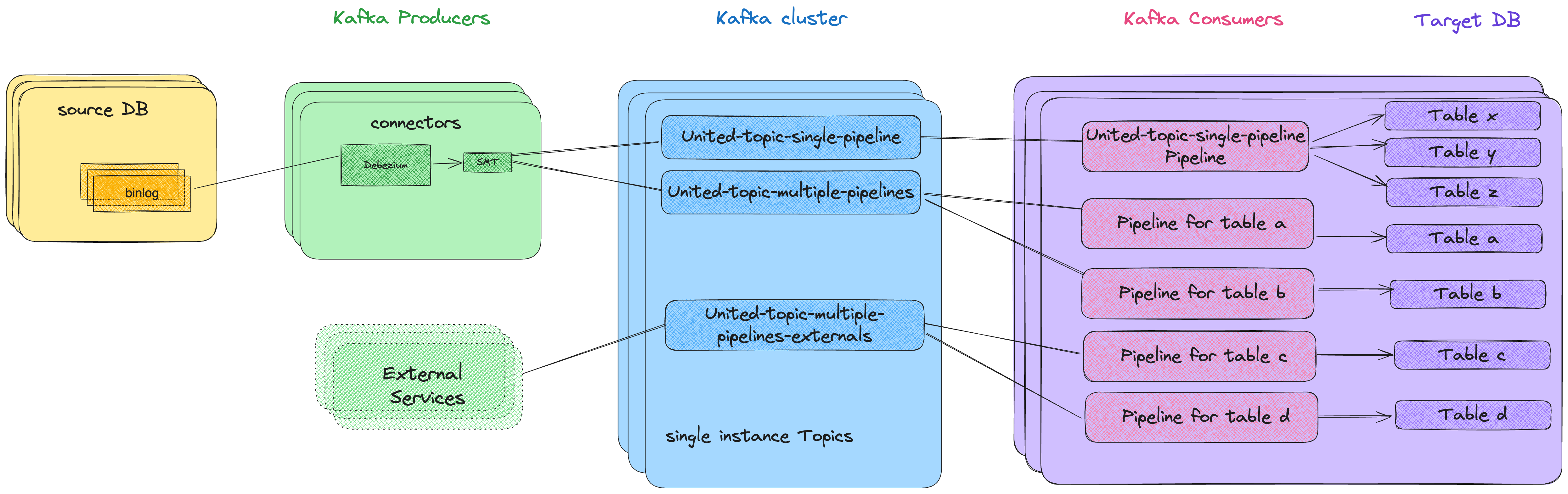
The first solution we tried was dubbed united-topic-single-pipeline. With this solution, we consolidated and published multiple tables’ events to a shared topic that was connected to a single consumer pipeline, which distributed the events to multiple tables. This worked well, but only for tables with low traffic, roughly up to 10K daily events. When a high-traffic table was added to the topic, all tables suffered from lag.
So while we did manage to reduce the number of topics in the cluster, it was only a partial solution, and only worked with some tables. We wanted more. So we leveraged our initial idea and eventually used it as part of the end solution, along with some enhanced monitoring assistance that will be described later on.
End solution
We needed a robust solution that would work for all tables. So we configured three “topic types” for each instance:
united-topic-single-pipeline as described above, for low traffic tables.
united-topic-multiple-pipelines for higher traffic tables. All originating tables’ events are published to the same topic, but each destination table gets its own consuming pipeline. Thus each pipeline efficiently skips other tables’ events, and ingests only the events relevant to it. The performance is much better here, since a load on one table impacts other tables much less.
united-topic-multiple-pipelines-externals for other Kafka producers, like microservices or AWS Lambda, which publish directly to Kafka and don’t use Debezium connectors, and needed a separate flow (which will be described later).
So at this point, each type used one topic with one partition, which reduced the number of topics dramatically. For our same 150 tables over 600 instances, we reduced the topic count from 90K to only 1.8K application topics (3*600). This made the cluster much more stable, more easily managed, and most importantly—came without performance degradation.
Testing and improving
To be sure that the massive topic reduction would work, we provisioned both the initial E2E architecture and the end-solution E2E architecture for a few dozen of our clients, of all sizes. We did it in a side-by-side manner, meaning we duplicated all Kafka producers, consumers, topics, and target databases.
Thus while our clients were utilizing the old architecture, we were able to test their production load in real time on the new architecture, and compare performance and lags. And lags certainly came. In fact, they came fast.
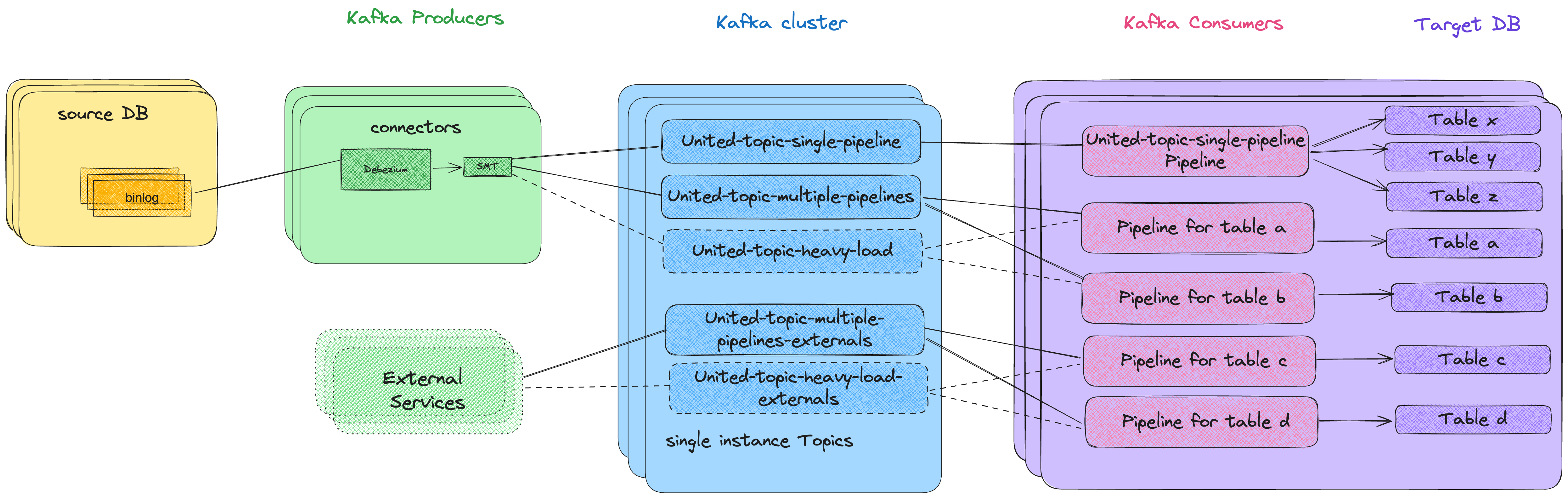
As a result, we improved the solution even more. We implemented a new type of topic to be created on demand: united-topic-heavy-load. This topic type has six partitions to start. It hosts tables with a high volume of changes, segregating them from other topics, and ingests their data loads faster, with higher concurrency on the consumer side (this also helps decrease lag for the remaining tables). Similarly, we added a new type for heavy changes from external Kafka clients: united-topic-heavy-load-externals.
Monitoring
We now had mixed events from many tables in the same topic, and identifying lag was on the one hand very important, since it impacts so many tables, but on the other hand, it was quite hard to find which particular table was causing the lag. The regular end-to-end lag monitor showed combined lag for all of the tables in the united topic, whereas only one table was actually causing the lag.
After realizing this, we added an important Datadog metric to visualize the number of events per table in the destination databases, using a dedicated stored procedure for counting and processing the events, called by the pipeline itself. This helped us to easily find the root cause of a lag, and then deal with the problem table separately.
Lag handling
Now that we had managed to find the heavy table causing the lag, we needed a way to easily increase its resources.
For that we created an API for our network operations center (NOC) team that handles lag using the following logic for a given table:
If the table is included in a united-topic-single-pipeline topic, move it to a united-topic-multiple-pipelines topic (where it will have a dedicated pipeline).
If the table is included in a united-topic-multiple-pipelines topic, move it to a united-topic-heavy-load topic (where it will have at least six partitions).
If the table is already included in a united-topic-heavy-load topic, then increase the topic’s partition count by two.
The same handling logic is applied to external tables.
A natural next step (that we haven’t implemented yet), will be doing all of this automatically without even using an API. How are we going to do that? We'll keep you curious about this one.
Additional Kafka clients
So far so good, but there was still a big problem with external services. Our external Kafka clients relied on the old architecture’s strict naming conventions, an approach that wouldn’t work with a dynamic shared-topic architecture, where tables can move between topics. We needed something more dynamic, so we created a dedicated API that always returns the current topic for a given table.
This was a good start, but it wasn’t enough, since calling this API before publishing each and every message could cause millions of requests each minute, and eventually the API wouldn’t be able to respond fast enough.
To solve this, we replaced API access with a shared, dedicated Java library that all services can easily use. This library manages a local cache of the table-->topic mapping results from the API, with some configurable TTL. This caching reduced the number of calls to the API dramatically. We also added a step in the migration of topics that waits for the entire cache’s TTL before switching to a new topic. This ensures that all clients get the changes, thus avoiding data loss.
Below you can see a diagram of the E2E after the re-architecture:
Conclusion
As a result of our re-architecture, we reduced the number of topics we manage by more than 90%—without sacrificing performance. We freed up dozens of brokers and also reduced maintenance time and our Kafka cloud budget dramatically.
After such a successful POC and collaboration, we have great confidence that migrating Kafka to the cloud is the right fit for us. We proved that it is clear and simple to manage our cluster, topics, partitions, and Schema Registry from the intuitive Confluent UI, using built-in integrations and monitoring. Securing our data is also a lot easier. Overall, the change in architecture brought us to a much better starting point for our migration process, which will now be faster, safer, and more cost-effective.
Learn more about migrating Kafka to the cloud in this ebook.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.


{kind=link}
{kind=link}
{kind=link}

Predictive Analytics: How Generative AI and Data Streaming Work Together to Forecast the Future
Discover how predictive analytics, powered by generative AI and data streaming, transforms business decisions with real-time insights, accurate forecasts, and innovation.