Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Announcing ksqlDB 0.7.0
We are pleased to announce the release of ksqlDB 0.7.0. This release features highly available state, security enhancements for queries, a broadened range of language/data expressions, performance improvements, bug fixes, and more! I’ll discuss a few of these, but be sure to check out the changelog for the full update!
When we launched ksqlDB, one of the big shortcomings it had was an inability to serve queries against its tables of state during a cluster rebalance. In each ksqlDB cluster, one server is designated the active for a particular partition of a state store whereas its replicas are the standbys. Queries are routed to the active server based on the key targeted in the query. Previously, if the active server was down, queries routed to that server would fail until rebalancing completed and a new server was elected as the active. This created a window of unavailability.
Now in ksqlDB 0.7.0, queries will not fail even when the active is down, but rather will get routed to a standby server. One caveat is that query results can be stale since replicas asynchronously materialize their state through intermediate Apache Kafka® topics. You can cap how much staleness, sometimes called lag, your application can tolerate by setting the flag ksql.query.pull.max.allowed.offset.lag per pull query. By default, high availability is not enabled. If you want to make your state highly available, you should enable the ksql.query.pull.enable.standby.reads and ksql.query.pull.max.allowed.offset.lag configuration parameters.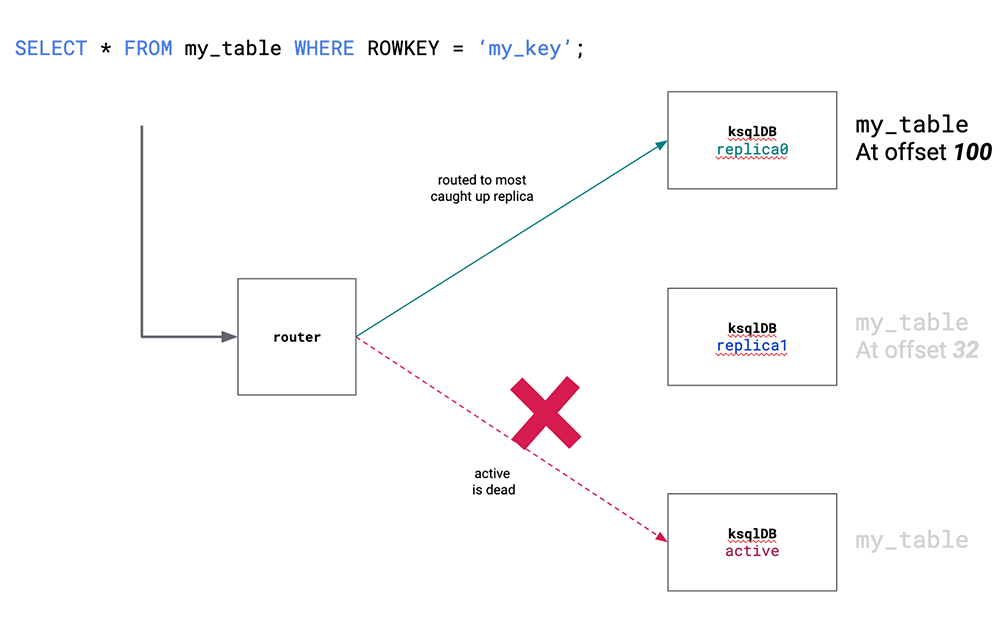 We’ve also added two heavily requested functions: count_distinct and cube. count_distinct is an aggregation function that counts the distinct occurrences of a value within a window (or one that is boundless), which is a notoriously hard problem to hand-roll a solution for. cube is a table function that takes as argument a list of columns and then outputs a new row for each possible combination of them. It is commonly used for modeling multi-dimensional data and when combined with a group by allows you to compute subtotals and a grand total for every combination of columns.
We’ve also added two heavily requested functions: count_distinct and cube. count_distinct is an aggregation function that counts the distinct occurrences of a value within a window (or one that is boundless), which is a notoriously hard problem to hand-roll a solution for. cube is a table function that takes as argument a list of columns and then outputs a new row for each possible combination of them. It is commonly used for modeling multi-dimensional data and when combined with a group by allows you to compute subtotals and a grand total for every combination of columns.
We’ve also enhanced the range of data that ksqlDB can work with. In the past, ksqlDB was only able to work with record keys that were of type string. We’ve happily removed this archaic limitation. Keys can now be of other primitive types, including INT, BIGINT, and DOUBLE. We have a lot more work to do to complete the range of data that ksqlDB tolerates in the key position, but this is a good start.
Finally, we’ve made the ergonomics of working with compound data just a bit easier. Native arrays, maps, and structs now have first class constructors. You can create them using syntax like ARRAY[val1, val2...], MAP(key:=val, ...), and STRUCT(field:=val). You can use this in queries as well as INSERT INTO ... VALUES. Here are some examples that showcase this:
SELECT STRUCT(name := col0, ageInDogYears := col1*7) AS dogs FROM animals creates a schema dogs STRUCT, assuming col0 is a string and col1 is an integer.
The following two statements create an array and map, respectively:
CREATE STREAM OUTPUT AS SELECT ARRAY[a, b, 3] as L FROM TEST CREATE STREAM OUTPUT AS SELECT MAP(k1:=v1, k2:=v1*2) as M FROM TEST
Stay tuned for the next release of ksqlDB! In the 0.8.0 release, we plan to continue improving the ergonomics of developing apps with ksqlDB, including making it easier to install connectors and increasing performance of the query layer. As always, feel free to message us at @ksqlDB on Twitter or in our #ksqldb Confluent Community Slack channel.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.