Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Integrating Apache Kafka With Python Asyncio Web Applications
Modern Python has very good support for cooperative multitasking. Coroutines were first added to the language in version 2.5 with PEP 342 and their use is becoming mainstream following the inclusion of the asyncio library in version 3.4 and async/await syntax in version 3.5.
Web applications can benefit a lot from this. The traditional approach for handling concurrent requests in web applications has been to dedicate a thread (or process!) to each request. If a blocking IO operation is required to service the request—for example, to update information in a database or produce a message to Apache Kafka®—the thread blocks until it’s complete.
By contrast, async web frameworks use coroutines to service requests. These coroutines suspend their execution and give up control to a central event loop whenever they are blocked on IO. The event loop is capable of managing many outstanding coroutines simultaneously, cooperatively scheduling their continuation as IO operations are completed and interleaving this with accepting new requests. This approach is more efficient than utilizing a dedicated thread per request for typical workloads and enables modern web servers to service many more simultaneous requests.
There are quite a number of async web frameworks available for Python. These include Starlette, FastAPI (which builds on Starlette), aiohttp, Sanic, Vibora, Quart, BlackSheep, and Responder. Since FastAPI is currently attracting quite a following, we’re going to use this for our example, but the approach is the same for other frameworks.
Building an asyncio-enabled Kafka producer
Confluent’s Python client doesn’t yet come with support for asyncio out of the box; however, it’s simple to build a wrapper class yourself for this purpose.
Here’s a minimal producer example (from GitHub):
class AIOProducer: def __init__(self, configs, loop=None): self._loop = loop or asyncio.get_event_loop() self._producer = confluent_kafka.Producer(configs) self._cancelled = False self._poll_thread = Thread(target=self._poll_loop) self._poll_thread.start() def _poll_loop(self): while not self._cancelled: self._producer.poll(:0.1) def close(self): self._cancelled = True self._poll_thread.join() def produce(self, topic, value): result = self._loop.create_future() def ack(err, msg): if err: self._loop.call_soon_threadsafe( result.set_exception, KafkaException(err)) else: self._loop.call_soon_threadsafe( result.set_result, msg) self._producer.produce(topic, value, on_delivery=ack) return result
This class essentially does two things:
- Calls the Producer‘s poll method periodically
- Creates an asyncio Future corresponding to each produce request and arranges for this to be completed when the result of the produce call is known
All communication from the Confluent Producer to your application (e.g., of message delivery, log messages, and statistics) occurs via callbacks. Callbacks are always executed as a side effect of a call to the poll method and on the same thread. An advantage of this approach is that it gives you complete control over how you handle notifications in your program flow—you choose precisely when and on what thread they occur. It’s also very efficient.
This type of API works well with event streaming applications where the poll method has a natural place in the processing loop. Web applications, however, have no such loop—request handlers execute on an ad hoc basis, where timing is determined by random people on the internet. We need to explicitly arrange for poll to be called periodically.
To ensure callbacks are triggered as soon as possible, the above code performs blocking calls to poll in a dedicated thread. It would have been simpler to arrange for non-blocking poll calls to be made on the event loop thread periodically using call_later, but this approach would introduce an additional average latency of (poll period)/2 to each delivery notification. The poll period could be chosen so as to make this delay insignificant, but that would meaningfully add to CPU load, in turn impacting the number of requests that can be handled simultaneously.
On a related note, the timeout used for the blocking poll call cannot be too low because that would result in undesirably high CPU load. It shouldn’t be too high either, because it effectively determines the maximum time close will block. 0.1s is a good compromise.
Asyncio provides the Future class for the purpose of creating a bridge between low-level, callback-based code and high-level async/await code. We use this to implement our async produce method. The callback ack is defined as an inner function that captures the asyncio Future instance we create to return to the user. Each time the ack method is called, it operates on a different Future instance—the one associated with the initiating produce call. The ack method will be called exactly once per produced message.
Since we are using a dedicated thread to call poll, the ack method won’t execute on the event loop thread; it will execute on the poll thread. We therefore need to use the event loop’s call_soon_threadsafe method to schedule the Future‘s completion on the event loop thread, since the Future class isn’t thread safe.
Out-of-band error handling
In some scenarios, you might not wish the result of an API endpoint to depend on the outcome of a particular produce call. For example, you probably shouldn’t return an error result simply because an endpoint was unable to write some analytics data to Kafka. Also, the response probably shouldn’t be delayed for this reason either. You will often still care about whether your call to produce was successful or not though. For example, you might want to write a log message or trigger an alert if too many errors occur.
There are a number of ways to accommodate this. First, we could modify our AIOProducer.produce method to accept an optional on_delivery parameter. When the delivery result is available, we could dispatch a call to the on_delivery handler on the event loop in addition to completing the future (the caller need not await the future). This API is Pythonic, abstracts the use of threads away from the user, and neatly allows the same producer instance to be used for both await and out-of-band use cases within the same application. This approach is implemented by the AIOProducer.produce2 method in the accompanying GitHub example.
Alternatively, we could simply let the delivery notification handler run on the poll thread, avoiding the overhead of call_soon_threadsafe unless the application explicitly requires it. Since you will typically only want to perform IO in your handler in the case of errors (which you may wish to rate-limit), this approach may be measurably more efficient. Here’s an implementation:
def produce(self, topic, value, on_delivery=None): self._producer.produce(topic, value, on_delivery=on_delivery)
Note: in the companion code, we’ve created a new class Producer for this method since it would be out of place on a class named AIOProducer.
Fire and forget
Finally, it’s possible to completely ignore delivery notifications by simply calling the out-of-band produce method without specifying a callback. People are often tempted to take this approach in order to optimize for efficiency, but it’s an anti-pattern. If your event handler only performs an action in response to error results, the improvement in efficiency won’t be measurable in the context of a web application. Also, by silently dropping errors, you are foregoing an opportunity to be notified of problems and an avenue for debugging them.
Integration with FastAPI
Let’s use our AIOProducer in a FastAPI web application (available on GitHub):
import asyncio import uvicorn from confluent_kafka import KafkaException from fastapi import FastAPI, HTTPException from pydantic import BaseModel from aio_producer import AIOProducer app = FastAPI() class Item(BaseModel): name: str producer = None @app.on_event("startup") async def startup_event(): global producer producer = AIOProducer({"bootstrap.servers": "localhost:9092"}) @app.on_event("shutdown") def shutdown_event(): producer.close() @app.post("/items") async def create_item(item: Item): try: result = await producer.produce("items", item.name) return { "timestamp": result.timestamp() } except KafkaException as ex: raise HTTPException(status_code=500, detail=ex.args[0].str()) if __name__ == '__main__': uvicorn.run(app, host='0.0.0.0', port=8000)
FastAPI is an ASGI (Asynchronous Server Gateway Interface) framework, which means our application requires an ASGI server in order to run. Uvicorn is a popular and easy-to-use option. It can be used programmatically as we’ve done above, or in other more powerful ways from the command line.
The first thing to note about our application is that we create the AIOProducer instance in the startup event handler. This is because the event loop used to service web requests is certain to exist at this point. Depending on how you run your application, it may or may not exist in the global scope.
In the snippet above, we’ve defined just one endpoint /items that demonstrates usage of the awaitable produce method. The endpoint accepts POST requests with an item object specified in a JSON payload. FastAPI makes use of pydantic to automatically transform this into an Item object, coercing fields as required and performing type validation using the Python type hints. To enable this, the Item class derives from the pydantic type BaseModel.
Finally, the business logic defined by the /items endpoint is very simple: produce a message to Kafka with the message value set to the item name, wait for the result, and return the Kafka message timestamp to the user upon success or a 500 HTTP response upon failure.
A more comprehensive example that also includes endpoints corresponding to the fire-and-forget, out-of-band methods and a no-op endpoint that doesn’t produce anything to Kafka as a point of comparison is available on GitHub. We’ll compare each of these endpoints in a load test below.
Load testing with Siege
Our example is simple but also representative of how you might go about building a real-world application, so it’s useful to perform some load testing to get an idea of how it performs.
To do this, we’ll use Siege, a multi-threaded HTTP load tester written in C. By default, Siege operates in verbose mode, which outputs a line to the console corresponding to each request. This may negatively impact results, so we disable it by setting verbose=false in the ~/.siege/siege.conf file. Likewise, uvicorn outputs log messages at a high verbosity level, and we reduce this to warning in our tests.
Below is a chart of the number of requests per second achieved by a single uvicorn worker process on my i7-8850H 2.60GHz laptop. It shows our five different API endpoints over a range of different numbers of concurrent users:
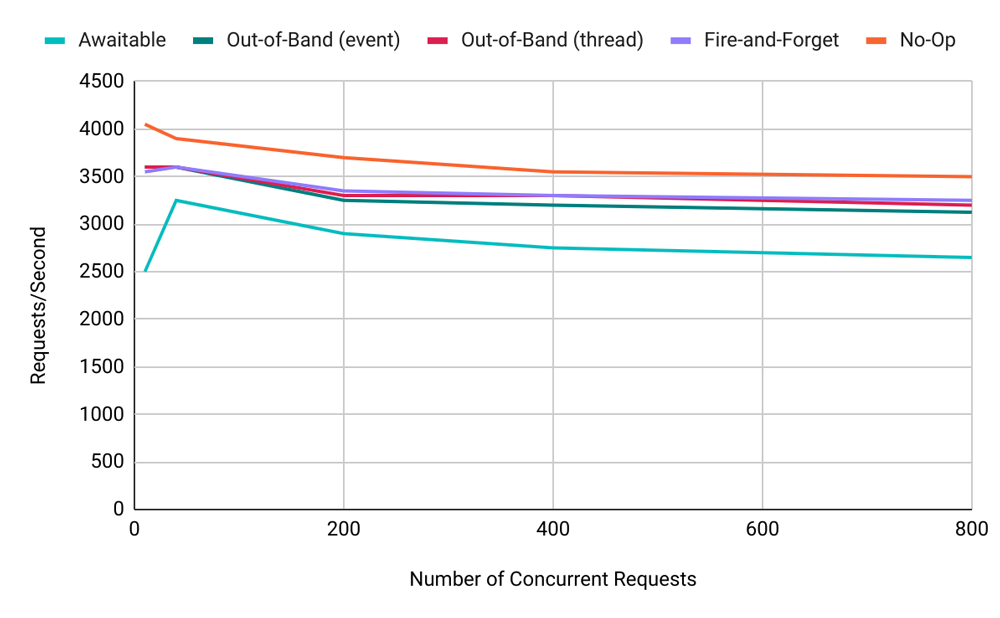
The first thing to note is that writing to Kafka (unsurprisingly) does have an impact on the number of requests per second. The out-of-band (no dispatch to event loop) and fire-and-forget endpoints perform very similarly, about 7% less than the no-op case at 400 concurrent users.
The out-of-band (with dispatch to event loop) endpoint performs about 3% less again and the awaitable case is an additional 12% worse, demonstrating that the async continuation has a relatively high performance impact compared with simply dispatching a function call on the event loop.
You can also see that as the number of concurrent requests increases, the number of requests per second declines, reflecting a higher burden on the event loop relative to throughput. The one aberration is the awaitable case, where enough latency is introduced by the produce calls that at low numbers of concurrent users, the event loop thread is idle some of the time.
As a comparison to the above, remember that each worker process in a traditional WSGI (Web Server Gateway Interface) web application deployment is often configured to service just one request at a time. The above results are good!
AdminClient and Consumer
It’s very common to produce messages to Kafka from web applications. Less often, you may wish to consume messages or perform admin operations.
Unlike the Producer, the Python AdminClient uses futures to communicate the outcome of requests back to the application (though a poll loop is still required to handle log, error, and statistics events). These are not asyncio Futures though. Rather, they are of type concurrent.futures.Future. In order to await them in your asyncio application, you’ll need to convert them using the asyncio.wrap_future method.
The Consumer is probably most often used in web applications to drive notifications to users via WebSockets. There are other use cases too, such as keeping an in-process cache fresh. There’s quite a lot to discuss here, because at scale, you need to think about the architectural implications of how to partition your workload across servers (not a bad topic for a future blog post!). For small scale web applications though, incorporating a Consumer is relatively straightforward.
Summary
By this point, we’ve taken a close look at how to create a simple asyncio-ready producer class by wrapping the callback-based Kafka producer. We also demonstrated how to use this in a simple FastAPI web application and measured how it performs.
Thanks to librdkafka’s backwards and forwards compatibility guarantees, our producer class is compatible with all Kafka brokers version 0.8 and above, as well as with all versions of Confluent Platform. Naturally, it’s also compatible with Confluent Cloud, a fully managed event streaming service based on Apache Kafka, which you can try for free with up to $50 USD off your bill each calendar month for a limited time.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


