Multi-Threaded Message Consumption with the Apache Kafka Consumer
Multithreading is “the ability of a central processing unit (CPU) (or a single core in a multi-core processor) to provide multiple threads of execution concurrently, supported by the operating system.” In situations where the work can be divided into smaller units, which can be run in parallel, without negative effects on data consistency, multithreading can be used to improve application performance.
In Kafka topics, records are grouped into smaller units—partitions, which can be processed independently without compromising the correctness of the results and lays the foundations for parallel processing. This is usually achieved by scaling: using multiple consumers within the same group, each processing data from a subset of topic partitions and running in a single thread.
For most use cases, reading and processing messages in a single thread is perfectly fine, so it’s not surprising that thread per consumer threading model is commonly used with the Apache Kafka® consumer. When processing doesn’t involve I/O operations, it’s usually very fast, so the poll loop runs smoothly. While this model has many benefits, especially with regard to the simplicity of client code, it also has limitations that can cause problems in some use cases.
Understanding Kafka consumer internals is important in implementing a successful multi-threaded solution that overcomes these limitations, in which analyzing the thread per consumer model and taking a look under the hood of the Kafka consumer is a good first step.
This blog post assumes the use of Kafka consumers from the Java client library; therefore, some claims made here may not apply to other client libraries. For an alternate approach to parallelism that subdivides the unit of work from a partition down to a key or even a message, check out the blog post on the Confluent Parallel Consumer.
Thread per consumer model
When implementing a multi-threaded consumer architecture, it is important to note that the Kafka consumer is not thread safe. Multi-threaded access must be properly synchronized, which can be tricky. This is why the single-threaded model is commonly used.
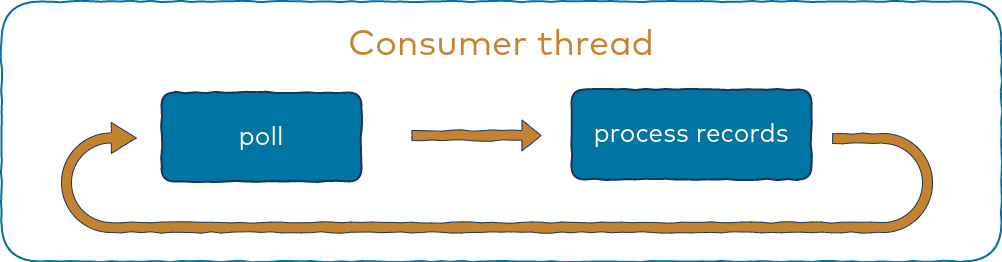
A typical single-threaded implementation is centered around a poll loop. Basically, it’s an infinite loop that repeats two actions:
- Retrieving records using the poll() method
- Processing fetched records
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(10000));
// Handle fetched records
}
With the default configuration, the consumer automatically stores offsets to Kafka. You can use the auto.commit.interval.ms config to tweak the frequency of commits. The following is the official description of this config:
“The frequency in milliseconds that the consumer offsets are auto-committed to Kafka if enable.auto.commit is set to true.”
Based on that description alone, users new to Kafka might assume that offsets are committed in these intervals by a background thread. In reality, offsets are committed during the consumer’s poll method execution, and the auto.commit.interval.ms only defines the minimum delay between commits. Only offsets of records returned in previous poll calls are committed. Since processing happens between poll calls, offsets of unprocessed records will never be committed. This guarantees at-least-once delivery semantics.
Automatic offset committing can be disabled, where the application itself must take care of manually committing offsets of processed records.
Because records are fetched and processed by the same thread, they are processed in the same order as they were written to the partition. This is referred to as processing order guarantees.
Group rebalancing
Consumer group rebalancing is triggered when partitions need to be reassigned among consumers in the consumer group: A new consumer joins the group; an existing consumer leaves the group; an existing consumer changes subscription; or partitions are added to one of the subscribed topics.
Rebalancing is orchestrated by the group coordinator and it involves communication with all consumers in the group. To dive deeper into the consumer group rebalance protocol, see Everything You Always Wanted to Know About Kafka’s Rebalance Protocol But Were Afraid to Ask by Matthias J. Sax from Kafka Summit and The Magical Rebalance Protocol of Apache Kafka by Gwen Shapira.
Regarding consumer client code, some of the partitions assigned to it might be revoked during a rebalance. In the older version of the rebalancing protocol, called eager rebalancing, all partitions assigned to a consumer are revoked, even if they are going to be assigned to the same consumer again. With the newer protocol version, incremental cooperative rebalancing, only partitions that are reassigned to another consumer will be revoked. You can learn more about the new rebalancing protocol in this blog post by Konstantine Karantasis and this blog post by Sophie Blee-Goldman.
Regardless of protocol version, when a partition is about to be revoked, the consumer has to make sure that record processing is finished and the offset is committed for that partition before informing the group coordinator that the partition can be safely reassigned.
With automatic offset commit enabled in the thread per consumer model, you don’t have to worry about group rebalancing. Everything is done by the poll method automatically. However, if you disable automatic offset commit and commit manually, it’s your responsibility to commit offsets before the join group request is sent. You can do this in two ways:
- Always call commitSync() after fetched records are processed and before the next poll method call
- Implement ConsumerRebalanceListener to get notified when partitions are about to be revoked, and commit corresponding offsets at that point
The first way is easier, but cases where processing is very fast may cause offset commits to occur too frequently. The second approach is more efficient and is necessary with fully decoupled consumption and processing.
Motivation for a multi-threaded consumer architecture
If you are familiar with basic Kafka concepts, you know that you can parallelize message consumption by simply adding more consumers in the same group. However, that approach is more suitable for horizontal scaling where you add new consumers by adding new application nodes (containers, VMs, and even bare metal instances).
A multi-consumer approach can also be used for vertical scaling, but this requires additional management of consumer instances and accompanying consuming threads in the application code. Using multiple consumer instances introduces additional network traffic as well as more work for the consumer group coordinator since it has to manage more consumers.
While these concerns may not be strong enough reasons for switching from a thread per consumer to a multi-threaded model, there are use cases in which a multi-threaded model has compelling advantages.
The problem of slow processing
The maximum delay allowed between poll method calls is defined by the max.poll.interval.ms config, which is five minutes by default. If a consumer fails to call the poll method within that interval, it is considered dead, and group rebalancing is triggered. This can happen often with the thread per consumer and default configuration for use cases where each record takes a long time to be processed.
When using the thread per consumer model, you can deal with this problem by tuning the following config values:
- Set max.poll.records to a smaller value
- Set max.poll.interval.ms to a higher value
- Perform a combination of both
When the record processing time varies, it might be hard to tweak these configs perfectly, so it is recommended to use separate threads for processing.
Handling record processing exceptions
Record processing logic, including error handling, is application specific. In the case of processing errors, you can perform one of the following options:
- Stop processing and close the consumer (optionally, retry a few times beforehand)
- Send records to the dead letter queue and continue to the next record (optionally, retry a few times beforehand)
- Retry until the record is processed successfully (this might take forever)
The third option, retry indefinitely, could be desirable in some use cases. For example, if processing involves writing to an external system that is currently offline, you might want to keep trying until it becomes available, no matter how long it takes.
With the thread per consumer model, single record processing must be done within a time limit, otherwise total processing time could exceed max.poll.interval.ms and cause the consumer to be kicked out of the group. For this reason, you would have to implement fairly complex logic for retries.
The multi-threaded solution outlined below allows you to take as much time as needed to process a record, so you can simply retry processing in a loop until it succeeds.
Multi-threaded Kafka consumer
There are many ways to design multi-threaded models for a Kafka consumer. A naive approach might be to process each message in a separate thread taken from a thread pool, while using automatic offset commits (default config). Unfortunately, this may cause some undesirable effects:
- Offset might be committed before a record is processed
- Message processing order can’t be guaranteed since messages from the same partition could be processed in parallel
While the goal is to achieve record processing parallelization, you also want your multi-threaded solution to maintain the features that a common, single-threaded approach has: processing order guarantees per partition and at-least-once delivery semantics.
The solution described in this blog post uses runnable tasks executed by a thread pool for processing records. The rest of this blog post describes how it works.
Note: This implementation might not be optimal for all use cases. Its goal is to demonstrate key aspects that need to be considered when implementing a multi-threaded consumer model.
Decoupling consumption and processing
In a multi-threaded implementation, the main consumer thread delegates records processing to other threads.
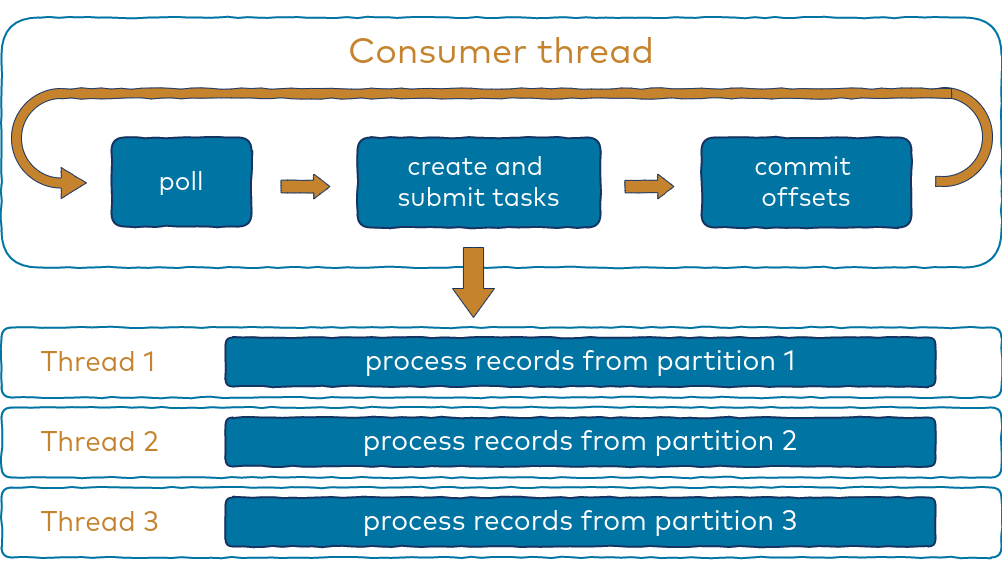
Records are retrieved using the poll method, the same as with a single-threaded implementation. Then, the records are grouped by partition, which results in multiple collections where each holds records from only a single partition. In order to process those collections, runnable tasks are created for each and submitted to an instance of Java’s built-in thread pool implementation.
The task implementation is quite simple, and the following represents a basic version that will be improved upon and discussed later in this blog post:
public class Task implements Runnable {
private final List records;
public Task(List records) {
this.records = records;
}
public void run() {
for (ConsumerRecord record : records) {
// do something with record
}
}
}
Note that the number of collections resulting from grouping by partition varies depending on the number of partitions assigned to a consumer, throughput, and some consumer configuration settings such as max.poll.records and max.partition.fetch.bytes.
Since records from each partition are processed sequentially, a low number of partitions can lead to underutilized CPU. If the number of partitions is very high, you don’t want to process all of them in parallel, since this would require a high number of threads.
In order to utilize the CPU efficiently, a thread pool with a fixed number of threads is used. That number is based on the number of available CPU cores as well as the nature of processing—is it CPU intensive or does it wait for I/O, etc.? For simplicity, assume eight core CPUs are used; therefore, a fixed thread pool with eight threads is configured:
private ExecutorService executor = Executors.newFixedThreadPool(8);
Tasks are submitted using the ExecutorService.submit() method, which returns immediately even if all the threads of the thread pool are currently in use. It simply adds a task to the thread pool’s internal queue where it waits to be processed.
After all of the tasks are submitted to the ExecutorService, the main consumer thread continues to poll for new records. The poll method is called frequently since there is not much to do between calls.
This means that there are no longer problems with excessive delays between poll method calls, and as a result, group rebalancing is very fast. Sounds great, right? But in order to maintain processing order and at-least-once delivery guarantees, some additional steps have to be taken.
Ensuring processing order guarantees
Since the main thread doesn’t wait for record processing threads to finish and continues with fetching, the probability of ending up with more than one task processing records from the same partition in parallel is high. This would obviously break processing order guarantees. To prevent it, pause the specific partition using the KafkaConsumer.pause() method after submitting the task holding records from it.
Note: When the partition is paused, subsequent calls to the poll method will not return any records from that partition—no matter how many times it is called—until that partition is resumed using the KafkaConsumer.resume() method.
It’s clear when to pause a partition, but when should it be resumed? The answer is: not until the task currently handling records from that partition is finished. The approach taken in this blog post is to call the consumer’s methods solely from the main thread, avoiding multi-threaded access synchronization. In each iteration of the poll loop, the main thread checks which tasks are finished and resumes corresponding partitions.
Committing offsets
Using automatic offset commit, which happens during poll method calls, is no longer an option. Offsets have to be committed manually at appropriate times. The first step is to disable auto commit in the consumer configuration:
config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
Offsets are committed manually from the main thread loop, but only Task instances know which record from the corresponding partition was last processed and, consequently, which offsets can be committed. In order to provide that information to the main consumer thread, the getCurrentOffset() method is added to the Task class. It returns an offset of the last processed record incremented by one (when committing the offset, it should always be the offset of the next message that should be processed, not the last processed record offset).
Putting it together
The following describes how the main consumer thread handles the operations discussed above:
public void run() {
try {
consumer.subscribe(Collections.singleton("topic-name"), this);
while (!stopped.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
handleFetchedRecords(records);
checkActiveTasks();
commitOffsets();
}
} catch (WakeupException we) {
if (!stopped.get())
throw we;
} finally {
consumer.close();
}
}
The poll loop operation is divided into three methods, so it’s easy to follow what’s happening.
The first step retrieves records from the consumer.
The next step creates and submits the record processing tasks. This is done by the handleFetchedRecords() method. It also pauses appropriate partitions and stores task references to a map instance named activeTasks, so their status can be checked on later.
private void handleFetchedRecords(ConsumerRecords<String, String> records) {
if (records.count() > 0) {
records.partitions().forEach(partition -> {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
Task task = new Task(partitionRecords);
executor.submit(task);
activeTasks.put(partition, task);
});
consumer.pause(records.partitions());
}
}
The next step of the poll loop iteration uses the checkActiveTasks() method, where it asks for the current progress of tasks and checks to see if they are finished:
private void checkActiveTasks() {
List finishedTasksPartitions = new ArrayList<>();
activeTasks.forEach((partition, task) -> {
if (task.isFinished())
finishedTasksPartitions.add(partition);
long offset = task.getCurrentOffset();
if (offset > 0)
offsetsToCommit.put(partition, new OffsetAndMetadata(offset));
});
finishedTasksPartitions.forEach(partition -> activeTasks.remove(partition));
consumer.resume(finishedTasksPartitions);
}
The offsetsToCommit map (declared on class level) is used to store the current offset of individual tasks. Those offsets are committed in the next step using the commitOffsets() method.
The checkActiveTasks() method also checks to see if an individual task has finished, and if so, the corresponding partition is resumed and the task is removed from the activeTasks map.
Committing offsets on every iteration of the poll loop is not recommended. Since it runs very fast, doing so would generate a lot of (unnecessary) commit requests. Instead, commit offsets only if the preconfigured amount of time has passed from the previous commit. In this case, it’s hard coded to five seconds.
private void commitOffsets() {
try {
long currentTimeMillis = System.currentTimeMillis();
if (currentTimeMillis - lastCommitTime > 5000) {
if(!offsetsToCommit.isEmpty()) {
consumer.commitAsync(offsetsToCommit);
offsetsToCommit.clear();
}
lastCommitTime = currentTimeMillis;
}
} catch (Exception e) {
log.error("Failed to commit offsets!", e);
}
}
Handling group rebalances
Since the poll method is now called in parallel with processing, the consumer could rebalance and some partitions might be reassigned to another consumer while there are still tasks processing records from those partitions. As a result, some records could be processed by both consumers.
Duplicate processing due to a group rebalance can be minimized by ensuring that the processing of records from revoked partitions is finished and corresponding offsets are committed before partitions get reassigned.
Passing an instance of ConsumerRebalanceListener as an argument to the KafkaConsumer.subscribe() method is a way to plug into the rebalance process and intercept partition revocation by implementing the ConsumerRebalanceListener‘s onPartitionsRevoke() method.
It is called from the consumer’s poll method, which means that this happens on the main consumer thread, so consumer.commitSync() can be called here without fear of running into the ConcurrentModificationException.
If there are tasks currently processing records from partitions that are being revoked, there are two options to handle this situation:
- Wait for the task to finish
- Stop the task, waiting only for the record currently being processed to finish
After that, offsets for those partitions can be committed.
Waiting results in the onPartitionsRevoked() method blocking the main consumer thread, so be aware that waiting too long might exceed the max.poll.interval.ms, causing the consumer to leave the group. Given this, the second option is better, since it takes less time.
Even with this option, the consumer may be kicked out of the group if processing a single record takes too long. This is most likely to happen when processing involves communication with an external system. To prevent that from happening, timeout on the external request should be smaller than max.poll.interval.ms.
If a timeout happens, the corresponding offset should not be committed, since the request won’t be considered successful. This means that the record will be processed again after the partition gets reassigned, which could produce duplicates in the external system, unless writes are idempotent.
The implementation of onPartitionsRevoked()method might look like this:
public void onPartitionsRevoked(Collection partitions) {
// 1. Stop all tasks handling records from revoked partitions
Map<TopicPartition, Task> stoppedTasks = new HashMap<>();
for (TopicPartition partition : partitions) {
Task task = activeTasks.remove(partition);
if (task != null) {
task.stop();
stoppedTasks.put(partition, task);
}
}
// 2. Wait for stopped tasks to complete processing of current record
stoppedTasks.forEach((partition, task) -> {
long offset = task.waitForCompletion();
if (offset > 0)
offsetsToCommit.put(partition, new OffsetAndMetadata(offset));
});
// 3. collect offsets for revoked partitions
Map<TopicPartition, OffsetAndMetadata> revokedPartitionOffsets = new HashMap<>();
partitions.forEach( partition -> {
OffsetAndMetadata offset = offsetsToCommit.remove(partition);
if (offset != null)
revokedPartitionOffsets.put(partition, offset);
});
// 4. commit offsets for revoked partitions
try {
consumer.commitSync(revokedPartitionOffsets);
} catch (Exception e) {
log.warn("Failed to commit offsets for revoked partitions!");
}
}
For a complete picture, revisit the Task class below to see how stopping the task works:
public class Task implements Runnable {
private final List<ConsumerRecord<String, String>> records;
private volatile boolean stopped = false;
private volatile boolean started = false;
private final CompletableFuture completion = new CompletableFuture<>();
private volatile boolean finished = false;
private final ReentrantLock startStopLock = new ReentrantLock();
private final AtomicLong currentOffset = new AtomicLong(-1);
public Task(List<ConsumerRecord<String, String>> records) {
this.records = records;
}
public void run() {
startStopLock.lock();
if (stopped){
return;
}
started = true;
startStopLock.unlock();
for (ConsumerRecord<String, String> record : records) {
if (stopped)
break;
// process record here and make sure you catch all exceptions;
currentOffset.set(record.offset() + 1);
}
finished = true;
completion.complete(currentOffset.get());
}
public long getCurrentOffset() {
return currentOffset.get();
}
public void stop() {
startStopLock.lock();
this.stopped = true;
if (!started) {
finished = true;
completion.complete(-1L);
}
startStopLock.unlock();
}
public long waitForCompletion() {
try {
return completion.get();
} catch (InterruptedException | ExecutionException e) {
return -1;
}
}
public boolean isFinished() {
return finished;
}
}
As a result of group rebalancing, some tasks might be stopped even before the thread pool starts to process it, i.e., while they are still in the queue. That’s why start-stop synchronization is needed at the beginning of the run() method as well as at the end of the stop() method.
The stop() method sets the stopped flag to true, causing the processing loop to break on the next iteration (if the task processing is in progress). If the task is still in the queue, the stop()method immediately marks the task as completed.
The waitForCompletion() method waits for task completion by calling the get() method on the CompletableFuture instance. It can be completed in two ways:
- From the run() method after the processing loop has finished
- From the stop() method if it is called before the ExecutorService starts to process this task
Now, let’s focus again on the main consumer thread. In the onPartitionsRevoked() method, all tasks currently handling records from revoked partitions are informed to stop processing. The stop() method returns immediately, so it can be invoked on all tasks without blocking and they can finish current record processing in parallel. Next, wait for all stopped tasks to finish processing by calling the waitForCompletion() method on all of them. It returns an offset that should be committed for the corresponding partition, based on the last processed record. Those offsets are stored to a map so they can be committed in a single commitSync() method call.
If stopping is omitted, tasks would be completed after all of the remaining records they hold are processed (option 1), but as we’ve already pointed out, that would slow down the rebalance process.
Conclusion
Implementing a multi-threaded consumer model offers significant advantages over the thread per consumer model for certain use cases. Although there are many ways to do this, the key considerations are always the same:
- Ensure that records from the same partitions are processed only by one thread at a time
- Commit offsets only after records are processed
- Handle group rebalancing properly
You can find the complete example code for the multi-threaded model described in this blog post via the GitHub repository. You can also watch my Kafka Summit talk for more details and read about the Confluent Parallel Consumer for an alternative approach.
If you don’t want to deep dive into details of the Kafka consumer client and just want to write cool apps against Kafka that someone else configures, maintains, and optimizes for you—check out Confluent Cloud with ksqlDB and use the promo code CL60BLOG to get $60 of additional free usage.*
ksqlDB is a database that is purpose-built for creating applications that respond immediately to events. Fully managed by us, ksqlDB is perfect for getting started with stream processing and streaming analytics. Craft materialized views over streams. Receive real-time push updates, and pull current state from tables on demand.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Powering AI Agents With Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


