Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?
There is a coming and a going / A parting and often no—meeting again.
—Franz Kafka, 1897
Load balancing and scheduling are at the heart of every distributed system, and Apache Kafka® is no different. Kafka clients—specifically the Kafka consumer, Kafka Connect, and Kafka Streams, which are the focus in this post—have used a sophisticated, paradigmatic way of balancing resources since the very beginning. After reading this blog post, you will walk away with an understanding of how load balancing works in Kafka clients, the challenges of existing load balancing protocols, and how a new approach with Incremental Cooperative Rebalancing allows large-scale deployment of clients.
Following what’s common practice in distributed systems, Kafka clients use a group management API to form groups of cooperating client processes. The ability of these clients to form groups is facilitated by a Kafka broker that acts as coordinator for the clients participating in the group. But that’s where the Kafka broker’s involvement ends. By design, group membership is all the broker/coordinator knows about the group of clients.
The actual distribution of load between the clients happens amongst themselves without burdening the Kafka broker with extra responsibility. Load balancing of the clients depends on the election of a leader client process within the group and the definition of a protocol that only the clients know how to interpret. This protocol is piggybacked within the group management’s protocol and, thus, is called the embedded protocol.
The embedded protocols used so far by the consumer, Connect, and Streams applications are rebalance protocols, and their purpose is to distribute resources (Kafka partitions to consume records from, connector tasks, etc.) efficiently within the group. Defining an embedded protocol within Kafka’s group management API does not restrict its use to load balancing only. Such use of an embedded protocol is a universal way for any type of distributed processes to coordinate with each other and implement their custom logic without requiring the Kafka broker’s code to be aware of their existence.
Embedding the load balancing algorithm within the group management protocol itself offers some clear advantages:
- Autonomy: clients can upgrade or customize their load balancing algorithms independently of Kafka brokers.
- Isolation of concerns: Kafka brokers support a generic group membership API and the details of load balancing are left to the clients. This simplifies the broker’s code and enables clients to enrich their load balancing policies at will.
- Easier multi-tenancy: for Kafka clients such as Kafka Connect, which balance heterogeneous resources among their instances and potentially belong to different users, abstracting and embedding this information to the rebalance protocol makes multi-tenancy easier to handle at the clients level. In this case, multi-tenancy is not yet another feature that the brokers have to worry about being aware of.
To keep things simple, all rebalancing protocols so far have been built around the same straightforward principle: a new round of rebalancing starts whenever a load needs to be distributed among clients, during which all the processes release their resources. By the end of this phase, which reaffirms group membership and elects the group’s leader, every client gets assigned a new set of resources. In short, this is also known as stop-the-world rebalancing, a phrase that can be traced back to garbage collection literature.
Challenges when stopping the world to rebalance
A load balancing algorithm that stops-the-world in every rebalance presents certain limitations, as seen through these increasingly notable cases:
- Scaling up and down: Unsurprisingly, the impact of stopping the world while rebalancing is relative to the number of resources being balanced across participating processes. For example, starting 10 Connect tasks in an empty Connect cluster is different than starting the same number of tasks in a cluster running 100 existing Connect tasks.
- Multi-tenancy under heterogeneous loads: The primary example here is Kafka Connect. When another connector, probably from another user, is added to the cluster, the side effect of stopping a connector’s tasks is not only undesirable but also disruptive at large scale.
- Kubernetes process death: whether in the cloud or on-premises, failures are anything but unusual. When a node fails, another node quickly replaces it, especially when an orchestrator like Kubernetes is used. Ideally, a group of Kafka clients would be able to absorb this temporary loss in resources without performing a complete rebalance. Once a node returns, the previously allocated resources would be assigned to it immediately.
- Rolling bounce: intermittent interruptions don’t only occur incidentally due to environmental factors. They can also be scheduled deliberately as part of planned upgrades. However, a complete redistribution of resources should be avoided because scaling down is only temporary.
Despite workarounds to accommodate these use cases, such as splitting clients into smaller groups or increasing rebalancing-related timeouts, which tend to be less flexible, it became clear that stop-the-world rebalancing needed to be replaced with a less disruptive approach.
Incremental Cooperative Rebalancing
The proposition that gained traction in the Kafka community and aimed to alleviate the impact of rebalancing that the current Eager Rebalancing protocol exhibits in large clusters of Kafka clients is Incremental Cooperative Rebalancing.
The key ideas to this new rebalancing algorithm are:
- Complete and global load balancing does not need to be completed in a single round of rebalancing. Instead, it’s sufficient if the clients converge shortly to a state of balanced load after just a few consecutive rebalances.
- The world should not be stopped. Resources that don’t need to change hands should not stop being utilized.
Naturally, these principles lend themselves to the name of the proposition behind the improved rebalance protocols in Kafka clients. The new rebalancing is:
- Incremental because the final desired state of rebalancing is reached in stages. A globally balanced final state does not have to be reached at the end of each round of rebalancing. A small number of consecutive rebalancing rounds can be used in order for the group of Kafka clients to converge to the desired state of balanced resources. In addition, you can configure a grace period to allow a departing member to return and regain its previously assigned resources.
- Cooperative because each process in the group is asked to voluntarily release resources that need to be redistributed. These resources are then made available for rescheduling given that the client that was asked to release them does so on time.
Implementation in Kafka Connect – Connect tasks are the new threads
The first Kafka client to provide an Incremental Cooperative Rebalancing protocol is Kafka Connect, added in Apache Kafka 2.3 and Confluent Platform 5.3 through KIP-415. In Kafka Connect, the resources that are balanced between workers are connectors and their tasks. A connector is a special component that mainly performs coordination and bookkeeping with the external data system, and acts either as a source or a sink of Kafka records. Connect tasks are the constructs that perform the actual data transfers.
Even though Connect tasks don’t usually store state locally and can stop and resume execution quickly after they restore their status from Kafka, stopping the world in every rebalance could lead to significant delays. In some cases—also known as rebalance storms—, it could bring the cluster into a state of consecutive rebalances and the Connect cluster could take several minutes to stabilize. Before Incremental Cooperative Rebalancing and due to rebalancing delays, the number of Connect tasks that a cluster could host was often capped below the actual capacity, giving the wrong impression that Connect tasks are out-of-the-box heavy weight entities.
With Incremental Cooperative Rebalancing, a Connect task can be what it was always intended for: a runtime thread of execution that is lightweight and can be quickly scheduled globally, anywhere in the Connect cluster.
Scheduling these lightweight entities (potentially based on information that is specific to Kafka Connect, such as the connector type, owner or task size, etc.) gives Connect a desirable degree of flexibility without overextending its responsibilities. Provisioning and deploying workers, which are the main vehicles of a Connect cluster, is still a responsibility of the orchestrator in use—that being Kubernetes or a similar infrastructure.
Let’s now take a look at what happens when we need to rebalance connectors and tasks in a Kafka Connect cluster of Apache Kafka 2.3 and beyond.
1. A new worker joins (Figure 1). During the first rebalance, a new global assignment is computed by the leader (Worker1) that results in the revocation of one task from each existing worker (Worker1 and Worker2). Because this first rebalance round included task revocations, the first rebalance is followed immediately by a second rebalance, during which the revoked tasks are assigned to the new member of the group (Worker3). During both rebalances, the unaffected tasks continue to run without interruption.
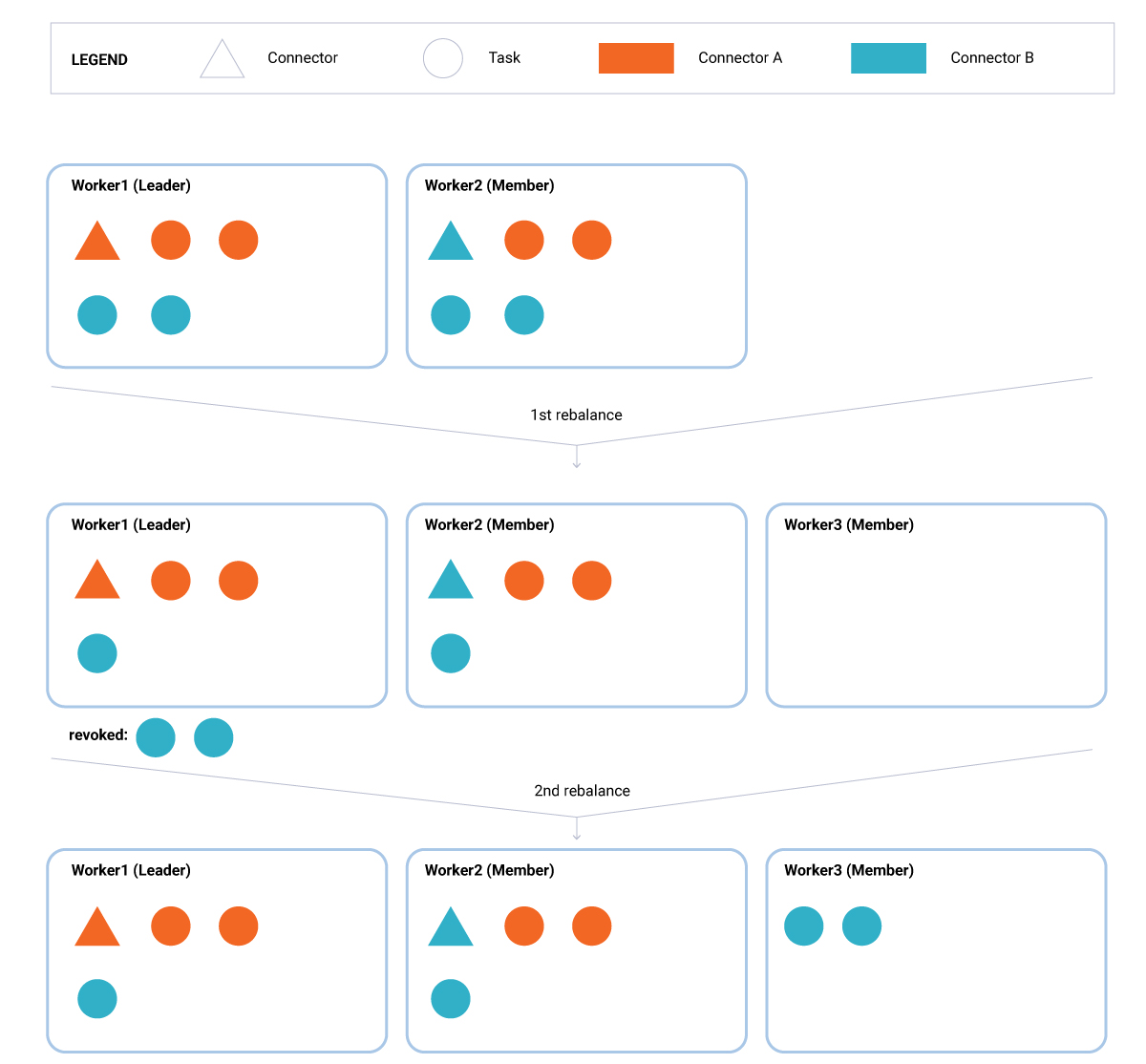
Figure 1. A new worker joins.
2. An existing worker bounces (Figure 2). In this scenario, a worker (Worker2) leaves the group. Its departure triggers a rebalance. During this rebalance round, the leader (Worker1) detects that one connector and three tasks are missing compared to the previous assignment. This enables a scheduled rebalance delay, controlled by the configuration property scheduled.rebalance.max.delay.ms (by default, it is equal to five minutes).
As long as this delay is active, the lost tasks remain unassigned. This gives the departing worker (or its replacement) some time to return to the group. Once that happens, a second rebalance is triggered, but the lost tasks remain unassigned until the scheduled rebalance delay expires. Then, all workers rejoin the group, triggering a third rebalance. At this time, the leader (Worker1) detects that there is a set of unassigned tasks, and a new worker keeps the group in a state of balanced load. As a result, the leader decides to assign the previous unaccounted tasks (one connector and three tasks) to the worker that bounced back in the group (Worker2).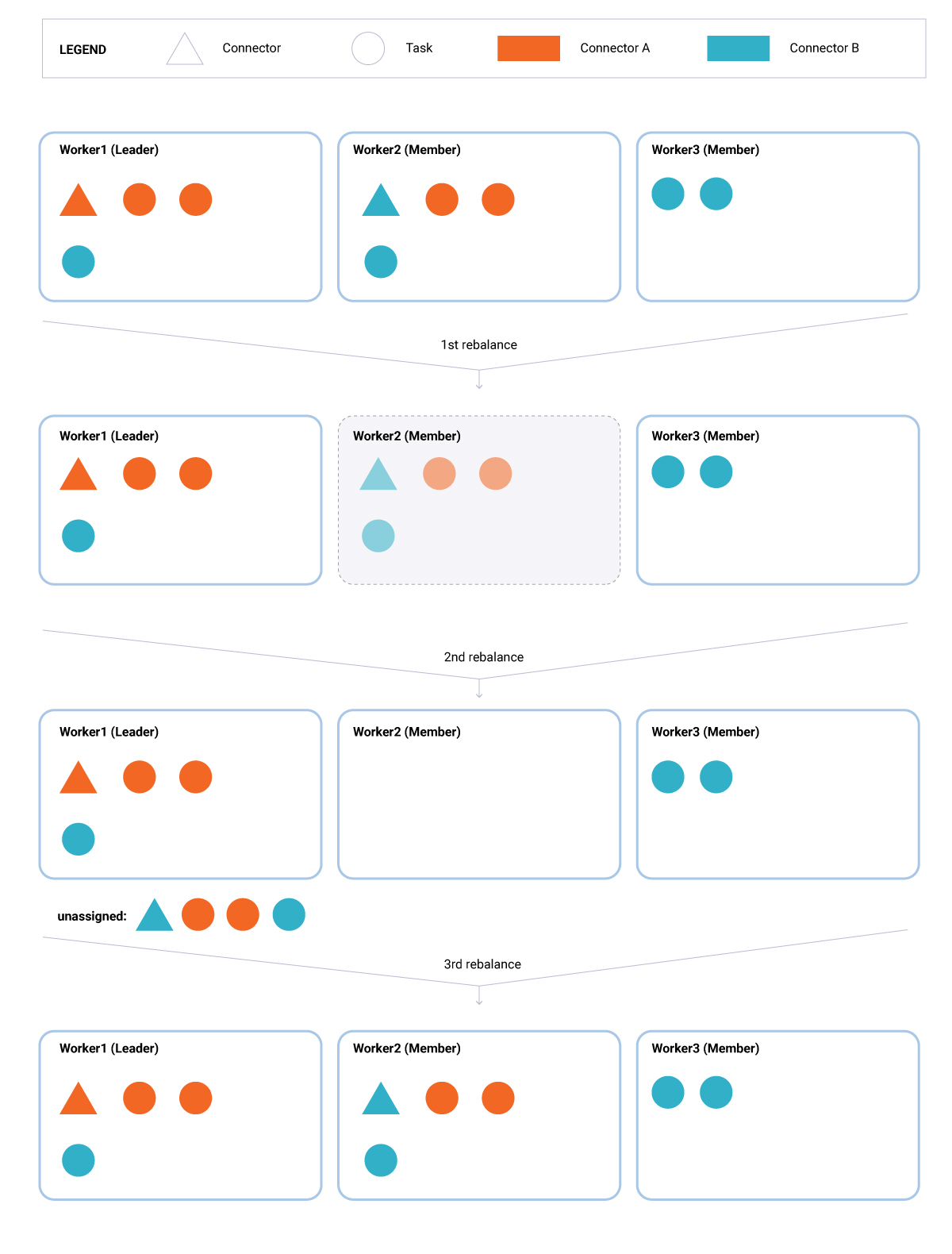
Figure 2. An existing worker bounces.
3. An existing worker leaves permanently (Figure 3). This scenario is identical to the previous one except that, here, the departing worker (Worker2) does not rejoin the group in time. In this case, its tasks (one connector and three tasks) remain unassigned for the time equal to scheduled.rebalance.max.delay.ms. After that, the two remaining workers (Worker1 and Worker3) rejoin the group, and the leader redistributes the tasks that were unaccounted for during the scheduled rebalance delay to the existing set of active workers (Worker1 and Worker3).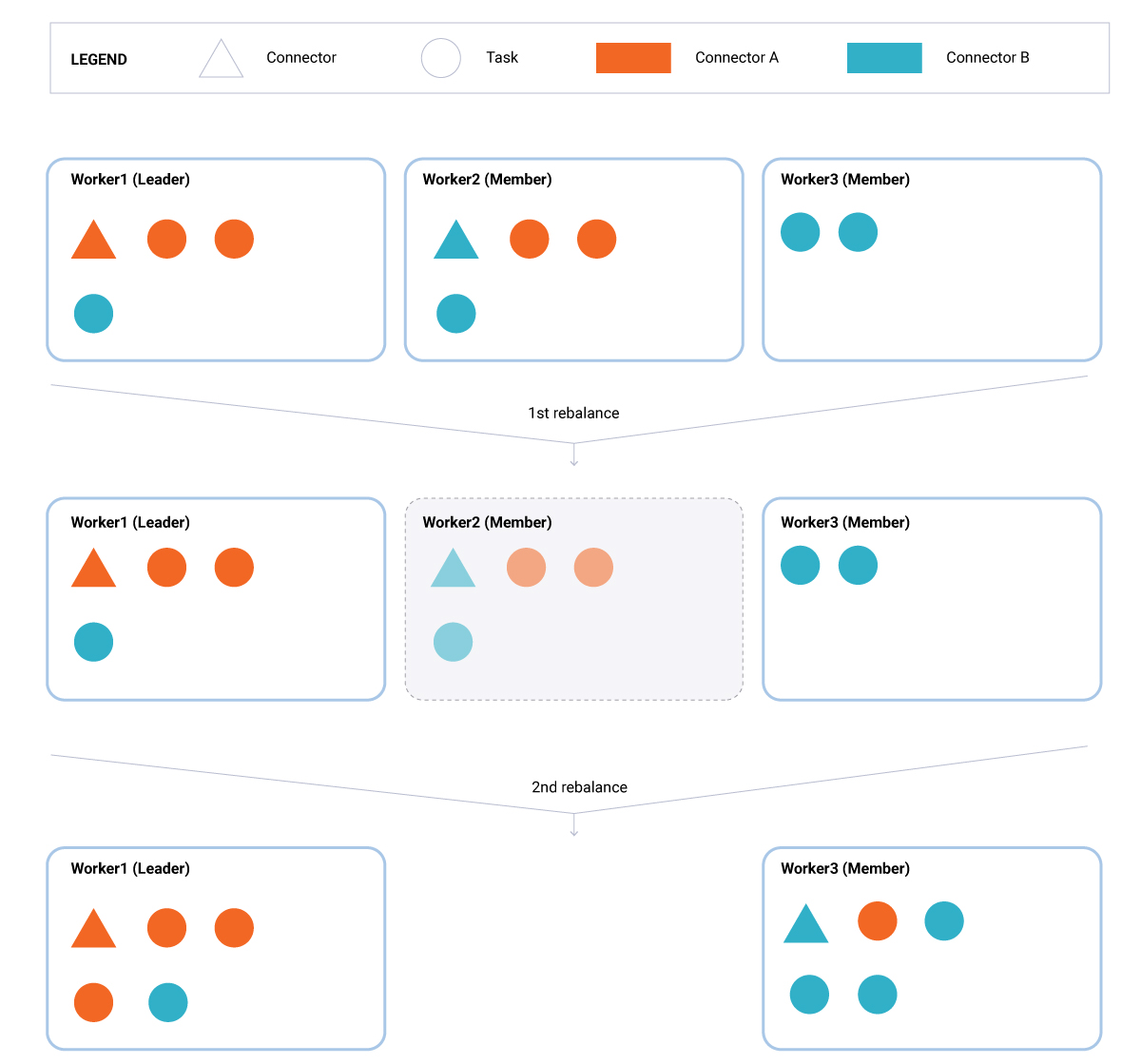
Figure 3. An existing worker leaves permanently.
New rebalancing in action
What’s the quantifiable improvement when using the new load balancing? What is the actual effect on individual connectors running on the Connect cluster, and what are its scaling characteristics? The new rebalancing algorithm raises these questions and more.
To provide answers to these important questions, I conducted a number of tests. These results can help quantify the improvements that Incremental Cooperative Rebalancing is bringing to Kafka Connect and highlight what these improvements mean for Kafka Connect deployments.
The first set of tests evaluated rebalancing itself as a procedure in terms of cost and scaling. Figure 4 shows how Eager Rebalancing compares side by side with Incremental Cooperative Rebalancing when a large number of connectors and tasks is running on a Kafka Connect cluster consisting of three workers. All connectors are Kafka Connect S3 connectors. There are a total of 90 connectors, each running 10 tasks, with a total of 900 tasks. The test ran on AWS using m4.2xlarge instance types to run the workers. To reflect a more realistic scenario, data records were consumed from a Kafka cluster in Confluent Cloud, which was located in the same region as the Kafka Connect cluster.
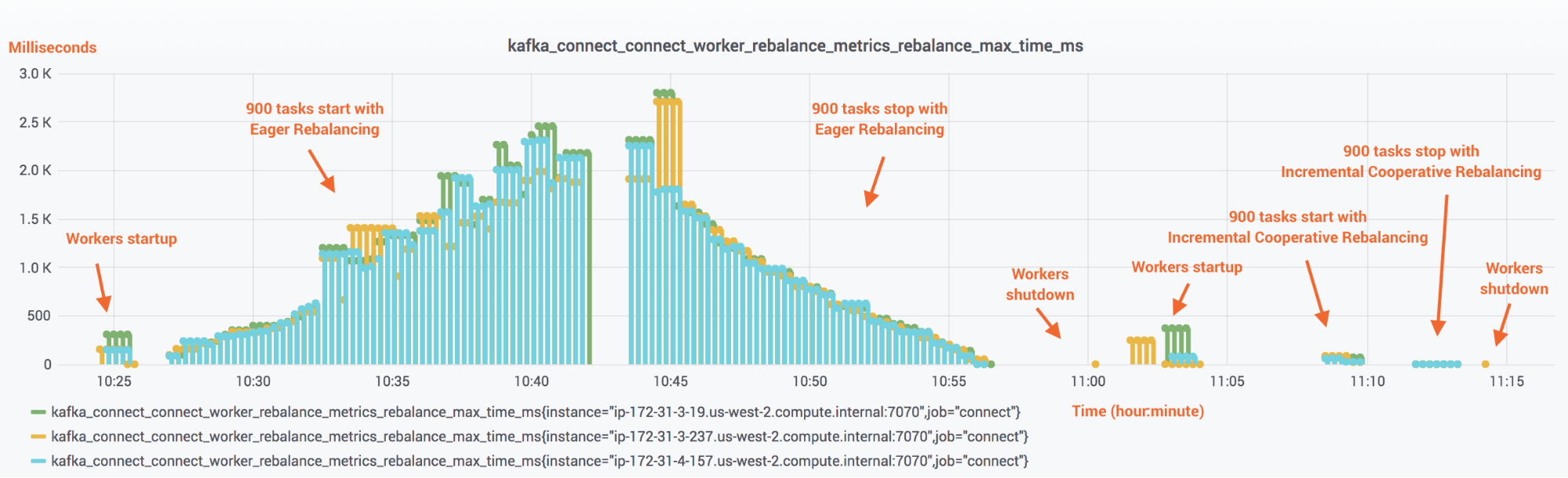
Figure 4. The cost (y-axis) and timeline (x-axis) of startup and shutdown for 900 S3 sink connector tasks with Eager Rebalancing and Incremental Cooperative Rebalancing
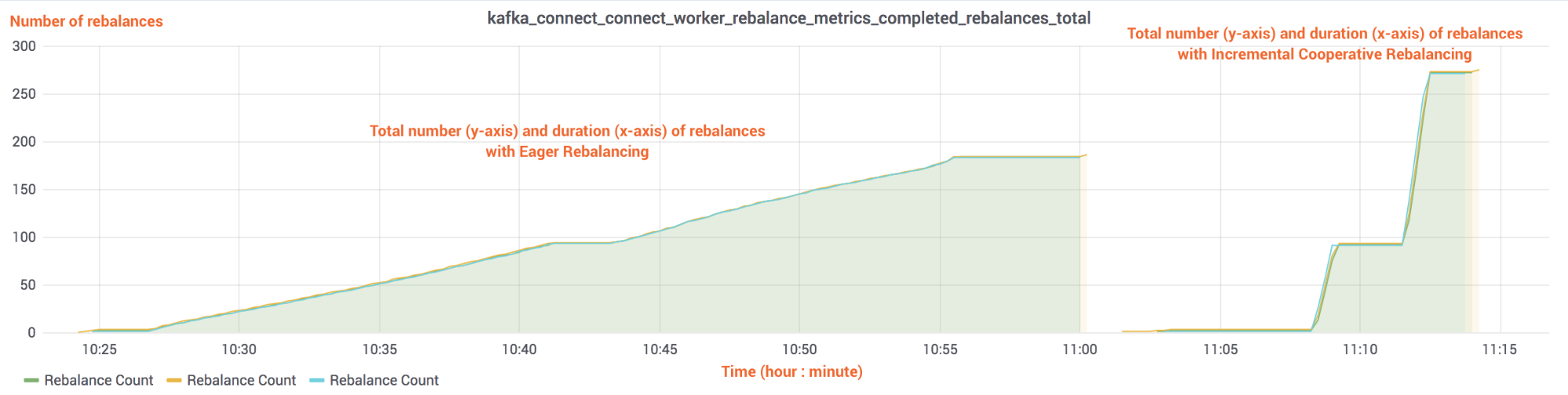
Figure 5. The total number of rebalances (y-axis) and timeline of startup and shutdown (x-axis) for 900 S3 sink connector tasks with Eager Rebalancing and Incremental Cooperative Rebalancing
Comparing Figure 4 and Figure 5 is telling. On the left-hand side of each of these graphs, Eager Rebalancing (which stops the world whenever a connector along with its tasks starts or stops) has a cost that is proportional to the number of tasks that currently run in the cluster. The cost is similar both when the connectors are started or stopped, resulting in periods of around 14 and 12 minutes, respectively, for the cluster to stabilize. In contrast, on the right-hand side, Incremental Cooperative Rebalancing balances 900 tasks within a minute and the cost for each individual rebalance remains evidently independent of the current number of tasks in the cluster. The bar charts in Figure 6 show this clearly by comparing how long it took to start and stop 90 connectors and 900 tasks.
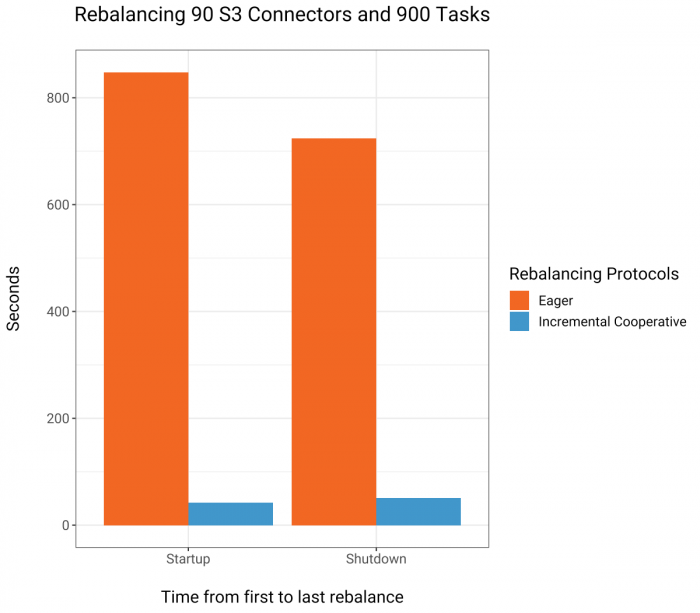
Figure 6. Comparison of the time it takes to sequentially startup and shutdown 900 S3 sink connectors through Connect’s REST interface
The second round of tests revealed the impact of rebalancing on the overall throughput of tasks in a specific Connect cluster. Since rebalancing can happen at any time, measuring just the bytes that a connector transfers to the sink alone is not enough. In order to capture the real-world impact of rebalancing on a set of active connectors, throughput should be examined as the overall end-to-end process that includes record transfer and commission of consumed offsets back to Kafka. It’s the final step of committing offsets that tells us that the S3 sink connector has made actual progress under the presence of rebalances.
Because consumer offsets are not exposed for reset by the hosted Kafka service, this next test instead used a self-managed Kafka deployment with five Kafka brokers running on m4.2xlarge instance types in the same region as the Connect cluster. The Kafka Connect cluster consists of three workers here too. Throughput is measured based on the timestamp of the consumer offsets with millisecond granularity. The results of running 900 S3 sink connector tasks with Eager Rebalancing and Incremental Cooperative Rebalancing, respectively, are presented in Table 1:
| 90 S3 Connectors/900 Tasks Against a Self-Managed Kafka Cluster | Eager Rebalancing | Incremental Cooperative Rebalancing | Improvement with Incremental Cooperative Rebalancing |
| Aggregate throughput (MB/s) | 252.68 | 537.81 | 113% |
| Minimum throughput (MB/s) | 0.23 | 0.42 | 83% |
| Maximum throughput (MB/s) | 0.41 | 3.82 | 833% |
| Median throughput (MB/s) | 0.27 | 0.54 | 101% |
Table 1. Comparison of rebalancing protocols in terms of measured throughput when running 900 tasks on three Connect workers for (a) all tasks, (b) tasks that achieved the minimum throughput, (c) tasks that achieved the maximum throughput, and (d) tasks that achieved the median throughput
The rows in Table 1 show the aggregate throughput achieved by all 900 tasks, as well as what the throughputs of the slowest, fastest, and median tasks were. Throughput is improved in all cases with Incremental Cooperative Rebalancing. In most cases, throughput is at least doubled when Incremental Cooperative Rebalancing is used.
What these results show is that Incremental Cooperative Rebalancing allows workers to run tasks without disruptions, and this can dramatically increase their throughput compared with Eager Rebalancing. The ability to sustain performance across multiple rebalances is particularly evident when comparing the tasks that achieved maximum throughput with either of the two protocols. For Incremental Cooperative Rebalancing, the highest performing task is more than nine times faster than the task that achieved maximum throughput under Eager Rebalancing.
Finally, although it’s expected for throughput to converge in both cases after the Connect cluster stabilizes, it’s worth noting that long periods without a rebalance taking place are not guaranteed, especially at large scale. Therefore, this difference in overall throughput could be considered rather typical between the two protocols.
Conclusion
Kafka Connect has been used in production for many years as the platform of choice for businesses that want to integrate their data systems with Apache Kafka and create streams. With Incremental Cooperative Rebalancing, connectors are able to scale beyond current limits. Enabling Connect to run at large scale allows for more centralized and manageable connector deployments that are otherwise fragmented into smaller clusters that are difficult to operate. In Kafka consumers and Kafka Streams, Incremental Cooperative Rebalancing is coming soon with the changes proposed by KIP-429 and KIP-441, which will also allow consumer and Streams applications to scale out without stopping the world.
To learn and hear more about how Incremental Cooperative Rebalancing redefines resource load balancing in Kafka clients, watch my session from Kafka Summit San Francisco titled Why Stop the World When You Can Change It? Design and Implementation of Incremental Cooperative Rebalancing.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


