Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
Event Sourcing Using Apache Kafka
Adam Warski is one of the co-founders of SoftwareMill, where he codes mainly using Scala and other interesting technologies. He is involved in open-source projects, such as sttp, MacWire, Quicklens, ElasticMQ and others. He has been a speaker at major conferences, such as JavaOne, LambdaConf, Devoxx and ScalaDays.

A Western Jackdaw. In Polish, it is called a Kawka—pronounced /ˈkaf.ka/.
When building an event sourced system, there’s a couple of options available when it comes to persistence. You could use a traditional event-sourcing system like EventStore, a scalable tabular database like Cassandra, or even a good old-fashioned relational database. But it’s also straightforward to do event sourcing on top of Apache Kafka. Let’s see how.
What is event sourcing?
There’s a number of great introductory articles, so this is going to be a very brief introduction. With event sourcing, instead of storing the “current” state of the entities that are used in our system, we store a stream of events that relate to these entities. Each event is a fact, it describes a state change that occurred to the entity (past tense!). As we all know, facts are indisputable and immutable. For example, suppose we had an application that saved a customer’s details. If we took an event sourcing approach, we would store every change made to that customer’s information as a stream, with the current state derived from a composition of the changes, much like a version control system does. Each individual change record in that stream would be an immutable, indisputable fact.
Having a stream of such events, it’s possible to find out what’s the current state of an entity by folding all events relating to that entity; note, however, that it’s not possible the other way round — when storing the current state only, we discard a lot of valuable historical information.
Event sourcing can peacefully co-exist with more traditional ways of storing state. A system typically handles a number of entity types (e.g. users, orders, products, …), and it’s quite possible that event sourcing is beneficial for only some of them. It’s important to remember that it’s not an all-or-nothing choice, but an additional possibility when it comes to choosing how state is managed in our application.
Storing events in Kafka
The first problem to solve is how we store events in Kafka. There are three possible strategies:
- Store all events for all entity types in a single topic (which is, of course, partitioned)
- Topic-per-entity-type, where we create a separate topic for all events related to a particular entity (e.g., a topic for all user-related events, one for product-related events, etc).
- Topic-per-entity, where we create separate topics for each user, each product, and so on.
Apart from low-cardinality entities, the third strategy (topic-per-entity) is not feasible. If each new user in the system would require the creation of a topic, we would end up with an unbounded number of topics. Any aggregations would also be very hard, such as indexing all users in a search engine, as it would require consuming a large amount of topics, which in addition wouldn’t all be known upfront.
Hence, we can choose between options one and two. Both have their pros and cons: with a single topic, it’s easier to get a global view of all events. On the other hand, with topic-per-entity-type, it’s possible to partition and scale each entity type stream separately. The choice between the two depends on the use case.
It is also possible to have both, at the cost of additional storage: derive entity type topics from the all-events topic.
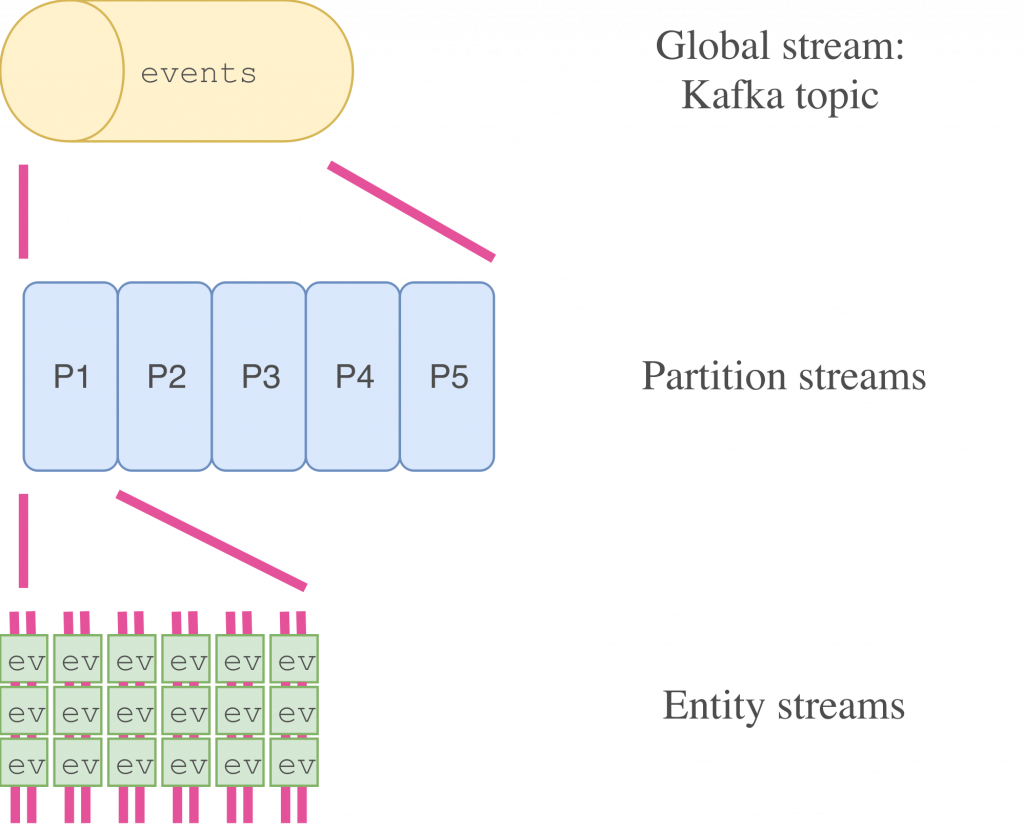
In the remainder of the article we’ll assume we’re working with a single entity type and a single topic; however, it’s easy to generalise to multiple topics or entity types. For more on this, check out Martin Kleppmann’s recent blog post on the topic.
Basic event-sourcing storage operations
The most basic operation that we would expect from a data store that supports event sourcing is reading the “current” (folded) state of a particular entity. Typically, each entity has some kind of an ID. Given that ID, our storage system should return its current state.
The event log is the primary source of truth: the current state can always be derived from the stream of events for a particular entity. In order to do that, the storage engine needs a pure (side-effect free) function, taking the event and current state and returning the modified state: Event => State => State. Given such a function and an initial state value, the current state is a fold over the stream of events. (The state-modification function needs to be pure so that it can be freely applied multiple times to the same events.)
A naive implementation of the “read current state” operation in Kafka would stream all of the events from the topic, filter them to include only the events for the given id and fold them using the given function. If there’s a large number of events (and over time, the number of events only grows), this can be a slow and resource-consuming operation. Even if the result would be cached in-memory in a service node, it would still need to be periodically re-created, for example due to node failures or cache eviction.
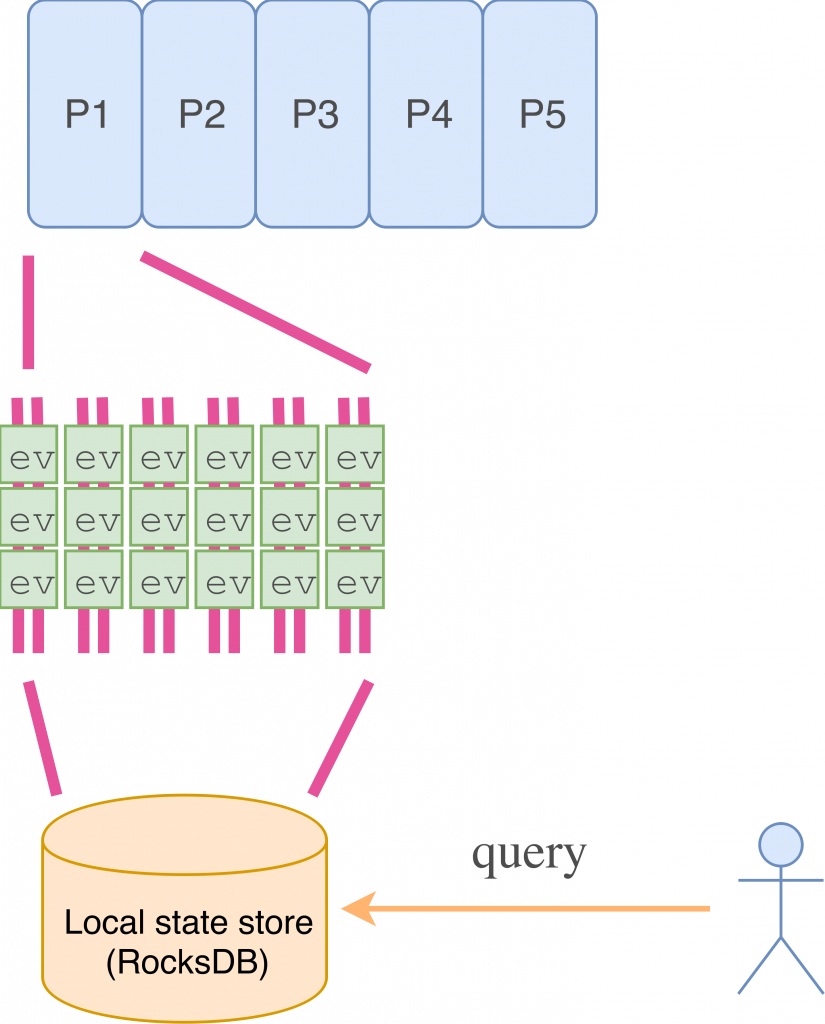
Hence, we need a better way. That’s where Kafka Streams and state stores come into play. Kafka Streams applications run across a cluster of nodes, which jointly consume some topics. Each node is assigned a number of partitions of the consumed topics, just as with a regular Kafka consumer. However, Kafka Streams provides higher-level operations on the data, allowing much easier creation of derivative streams.
One such operation in Kafka Streams is folding a stream into a local store. Each local store contains data only from the partitions that are consumed by a given node. There are two local store implementations available out of the box: a persistent storage engine (RocksDB, used by default) and an in-memory store. Both implementations are fault-tolerant, so even if you decide to configure your applications to use the in-memory store, you will not lose data.
Coming back to event sourcing, we can fold the stream of events into the state store, keeping locally the “current state” of each entity from the partitions assigned to the node. If we are using the RocksDB implementation of the state store, we are only limited by disk space as to how many entities can be tracked on a single node—and of course we can always mitigate that scale problem by further partitioning the source topic.
Here’s how folding events into a local store looks like using the Java API (serde stands for serializer/deserializer):
StreamsBuilder builder = new StreamsBuilder();
builder.table("my_entity_events", Consumed.with(keySerde, valueSerde))
.toStream(); // yields a stream of intermediate states
return builder;
For a full example, check out the orders microservices example in GitHub. In an event-sourcing system, you may want to retain data forever, rather than the default retention period of seven days. To get this done, set log.retention.bytes = -1 on the applicable topics.
Looking up the current state
We have created a state store containing the current states of all entities coming from partitions assigned to the node, but how to query it? If the query is local (same node), then it’s quite straightforward:
streams.store("my_entity_store", QueryableStoreTypes.keyValueStore()).get(entityId);
But what if we want to query for data which is present on another node? And how do we find out which node it is? Here, another feature recently introduced to Kafka comes in: interactive queries. Using them, it’s possible to query Kafka’s metadata and find out which node processes the topic partition for a given ID (this uses the topic partitioner behind the scenes):
metadataService.streamsMetadataForStoreAndKey("my_entity_store", entityId, keySerde);
Then it’s a matter of forwarding the request to the appropriate node. Note that how the inter-node communication is handled and implemented — is it REST, akka-remoting or any other way — is outside the scope of Kafka Streams. Kafka just allows accessing the state store, and gives information on which host a state store for a given ID is present.
Fail-over
State stores look nice, but what happens if a node fails? Re-creating the local state store for a partition might also be an expensive operation. It can cause increased latencies or failed requests for a long period of time due to Kafka Streams re-balancing (after a node is added or removed).
That’s why by default persistent state stores are logged: that is, all changes to the store are additionally written to a changelog-topic. This topic is compacted (we only need the latest entry for each ID, without the history of changes, as the history is kept in the events) and hence is as small as possible. Thanks to that, re-creating the store on another node can be much faster.
But that still might cause latencies on re-balancing. To reduce them even further, Kafka Streams has an option to keep a number of standby replicas (num.standby.replicas) for each storage. These replicas apply all the updates from the changelog topics as they come in, so if the primary fails Kafka Streams will fail over to the standby replica instantaneously.
Consistency
Using the default settings, Kafka provides at-least-once delivery. That is, in case of node failures, some messages might be delivered multiple times. It is possible, for example, that an event is applied to a state store twice, if the system failed after the state store changelog was written, but before the offset for that particular event was committed. That might not be a problem: our state-updating function (Event => State => State) might cope well with such situations. But it doesn’t have to; in that case, we can leverage Kafka’s exactly-once guarantees. These exactly-once guarantees only apply when reading and writing to Kafka topics, but that’s all that we are doing here: the action of updating the state store’s changelog and committing offsets are both writes to Kafka topics behind the scenes, and these can be done transactionally.
Hence, if our state-update function requires that, we can turn on exactly-once stream processing using a single configuration option: processing.guarantee. This introduces a performance penalty, but because the cost of a single commit is aggregated over a batch of messages the cost is comparatively small.
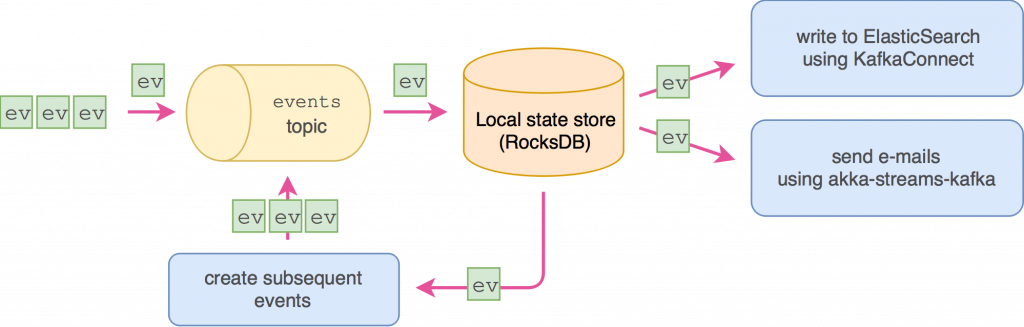
Listening for events
Now that we have the basics covered — querying and updating the “current state” of each entity — what about running side-effects? At some point, this will be necessary, for example to:
- send notification e-mails
- index entities in a search engine
- call external services via REST (or SOAP, CORBA, etc. 😉 )
All of these tasks are in some way blocking and involve I/O (as is the nature of side-effects), so it’s probably not a good idea to execute them as part of the state-updating logic: that could cause an increased rate of failures in the “main” event loop and create a performance bottleneck.
Moreover, the state-updating logic function (Event => State => State) can be run multiple times (in case of failures or restarts), and most often we want to minimise the number of cases where side-effects for a given event are run multiple times.
Luckily, as we are working with Kafka topics, we have quite a lot of flexibility. It is possible to consume messages either before or after the stage where we update the state store, and these messages—before or after—can be consumed in an arbitrary way. Finally, we also have control if we want to run the side-effects at-least-once or at-most-once. At-least-once can be achieved by committing the offset of the consumed event-topic only after the side-effects complete successfully. Conversely, at-most-once, by committing the offsets before running the side-effects.
As to how the side-effects are run, there’s a number of options, depending on the use-case. First of all, we can define a Kafka Streams stage, which runs the side-effects for each event as part of the stream processing function. That’s quite easy to setup, however it isn’t a very flexible solution when it comes to retries, offset management and executing side-effects for many events concurrently. In more advanced cases like these, it might be more suitable simply to define the processing using a Kafka topic consumer.
There’s also a possibility that one event triggers other events — for example an “order” event might trigger “prepare for shipment” and “notify customer” events. This can also be implemented using a Kafka Streams stage.
Finally, if we’d like to store the events, or some data extracted from the events, in a database or search engine, such as ElasticSearch or PostgreSQL, we might use a Kafka Connect connector which will handle all of the topic-consuming details for us.
Creating views and projections
Usually the requirements of a system go beyond querying and handling only individual entity streams. Aggregations, combining a number of event streams, also need to be supported. Such aggregated streams are often called projections and when folded, can be used to create data views. Is it possible to implement this using Kafka?
Again, yes! Remember that at the basic level we are just dealing with a Kafka topic storing our events: and hence, we have all the power of “raw” Kafka consumers/producers, Kafka Streams combinator and even KSQL to define the projections. For example, with Kafka Streams we can write Java or Scala code to filter the stream, or do operations like map, groupByKey, or aggregate in time or session windows. Alternatively, we can opt to use KSQL, where you use a SQL-like language to express the same processing logic instead of having to write code.
Such streams can be persistently stored and made available for querying using state stores and interactive queries, just like we did with individual entity streams.
Going further
As the system evolves, to prevent the event stream from growing indefinitely, some form of compaction or storing “current state” snapshots might come in handy. That way, we could store only a number of the recent snapshots and the events that occured after them. It is straightforward to build this kind of functionality in Kafka using the mechanisms we’ve already covered, like consumers, state stores, and so on.
Summing up
While Kafka wasn’t originally designed with event sourcing in mind, its design as a data streaming engine with replicated topics, partitioning, state stores and streaming APIs is very flexible and lends itself perfectly to the task. Moreover, since there’s always a Kafka topic behind the scenes, we get the additional flexibility of being able to work either with high-level streaming APIs or low-level consumers for maximum development convenience and velocity.
About Apache Kafka’s Streams API
If you have enjoyed this article, you might want to continue with the following resources to learn more about Apache Kafka’s Streams API:
- Get started with the Kafka Streams API to build your own real-time applications and microservices.
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications.
- Check out the latest release of KSQL to process and analyze your company’s data in real time. (Check out tag v0.5 to get the most recent KSQL release as of this writing.)
Watch our 3-part online talk series for the ins and outs behind how KSQL works, and learn how to use it effectively to perform monitoring, security and anomaly detection, online data integration, application development, streaming ETL, and more.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


