Apache Kafka®️ 비용 절감 방법 및 최적의 비용 설계 안내 웨비나 | 자세히 알아보려면 지금 등록하세요
3 Ways to Prepare for Disaster Recovery in Multi-Datacenter Apache Kafka Deployments
Imagine:
Disaster strikes—catastrophic hardware failure, software failure, power outage, denial of service attack or some other event causes one datacenter with an Apache Kafka® cluster to completely fail. Yet Kafka continues running in another datacenter, and it already has a copy of the data from the original datacenter, replicated to and from the same topic names. Client applications switch from the failed cluster to the running cluster and automatically resume data consumption in the new datacenter based on where it left off in the original datacenter. The business has minimized downtime and data loss resulting from the disaster, and continues to run its mission critical applications.
Ultimately, enabling the business to continue running is what disaster recovery planning is all about, as datacenter downtime and data loss can result in businesses losing revenue or entirely halting operations. To minimize the downtime and data loss resulting from a disaster, enterprises should create business continuity plans and disaster recovery strategies.
There are three actions you should take today for disaster planning:
1. Design a multi-datacenter solution
A Kafka deployment in a single datacenter provides message durability through intra-cluster data replication. Data replication with producer setting acks=all provides the strongest available guarantees, because it ensures that other brokers in the cluster acknowledge receiving the data before the leader broker responds to the producer.
The single datacenter design provides robust protection against broker failure. If a client application is using a certain broker for connectivity to the cluster, and that broker fails, another bootstrap broker can provide connectivity to the cluster. However, this single Kafka deployment is vulnerable if the entire datacenter fails.
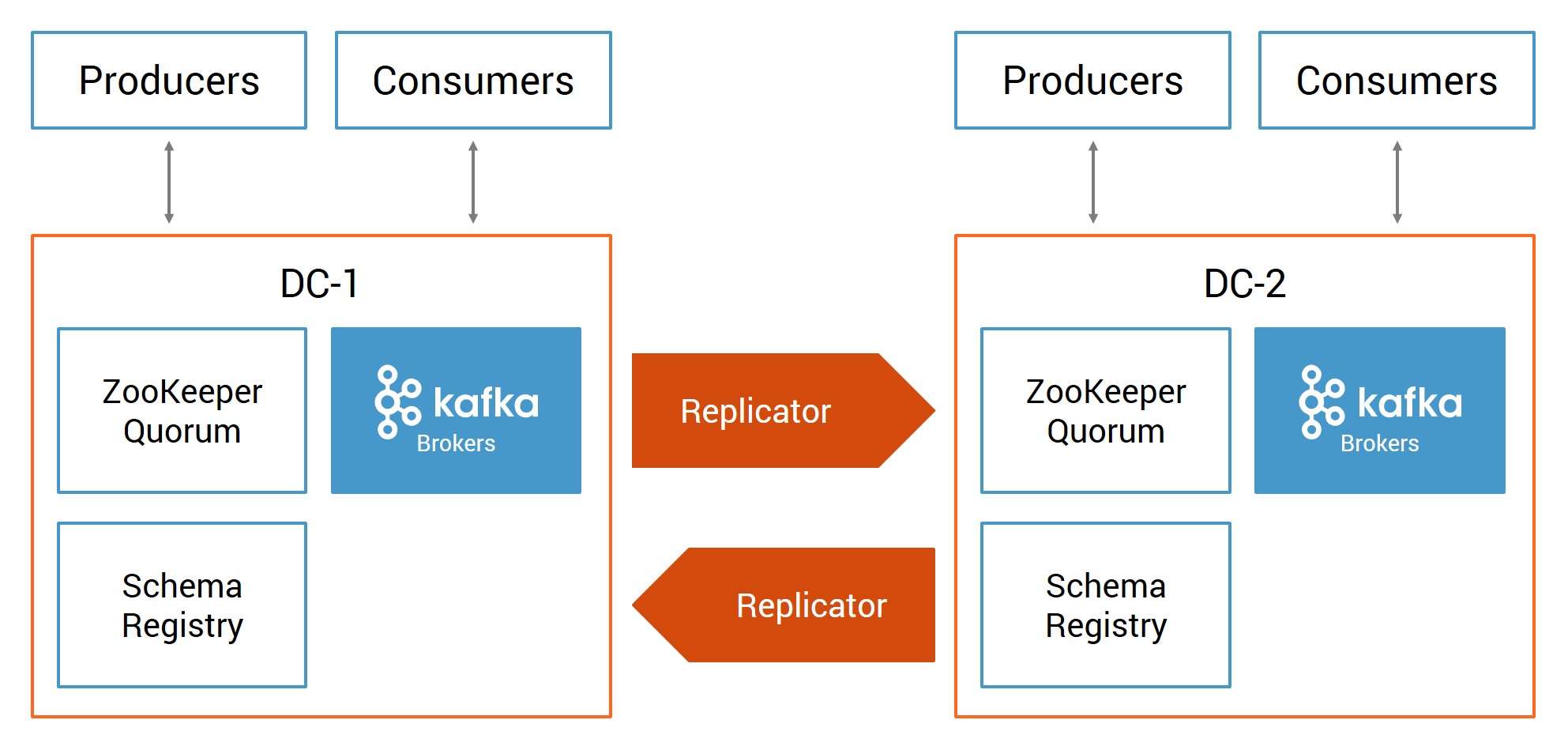
In a multi-datacenter design, instead of a single datacenter with one Apache Kafka deployment, there are two or more datacenters with Kafka deployments geographically dispersed. They can be on prem or in Confluent Cloud. Confluent Replicator synchronizes data between the sites so that in the event of a partial or complete disaster in one datacenter, applications can fail over to the other datacenter.
To help you design your multi-datacenter solution, we’ve released an updated version of the white paper Disaster Recovery for Multi-Datacenter Apache Kafka Deployments. The latest version of the paper walks through the design and configuration of a multi-datacenter deployment, covering designs, centralized schema management and client application development for multi-datacenter.
It also discusses in detail the new Confluent Replicator features in version 5.0, including:
- Prevention of cyclic replication of topics: In the context of active-active datacenters with Replicator running in both directions, Replicator can prevent infinite loops. Otherwise, if you don’t use special topic naming patterns, copying topics could result in an infinite loop copying data from cluster-1 to cluster-2, and then copying that same data in cluster-2 back to cluster-1 and then again from cluster-1 to cluster-2.
- Timestamp preservation: The time that is recorded at initial message production in the origin cluster propagates to the destination cluster. This enables streaming applications to act on the original timestamps.
- Consumer offset translation: The committed consumer offsets are replicated to the destination cluster and translated in such a manner that the offset values make sense in that cluster. This allows consumers to switch to the destination cluster and automatically resume consuming messages where they left off.
Your architecture will vary depending on your business requirements, but you can apply the building blocks from this white paper to strengthen your disaster recovery plan.
2. Build a runbook for failover and failback
When disaster strikes, you have to be prepared with a runbook of specific actions to take. How do you fail over client applications to the new datacenter? How do you enable Confluent Schema Registry to register new schemas? What do you have to do to enable consumers to start resuming data consumption in the new cluster? Most importantly, after the original datacenter recovers, how do you failback?
Disaster Recovery for Multi-Datacenter Apache Kafka Deployments walks through the basic multi-datacenter principles, explaining what to do if one datacenter fails and how to failback when it recovers. You should adapt those principles to your specific deployments.
How manual or automated the failover workflow is depends on the recovery time objective (RTO), which is the point in time after the disaster event when the failover completes. Ideally, it is as soon as possible after the disaster to minimize downtime. The more aggressive the RTO is, the more you want an automated workflow, which depends on the service discovery mechanism and failover logic developed into the applications.
The recovery point objective (RPO) is the last point in time before the disaster event that the application can recover to with known good data. Usually it is as close before the disaster as possible to minimize data loss. Especially if you leverage the features provided in Replicator 5.0, it will immensely simplify the workflow for failover and failback, as well as improve these recovery times.
3. Test! Test! Test!
Use the building blocks in the updated white paper to configure an environment that is representative of your production environment, then simulate the disaster. Follow the entire workflow: Take down a cluster, fail over applications, make sure they are successfully processing data and then fail back.
Stepping through the entire workflow is important primarily because it ensures that the multi-datacenter design is robust and working for your specific business needs. Every deployment is slightly different, and client applications are written slightly differently to meet their business needs, so you need to make sure that everything is functional. The second reason to do this simulation is it inherently tests your runbook to ensure that the steps are well documented.
To help you with the testing, Confluent provides a Docker setup in a GitHub repository that you can clone. Disclaimer: This is just for testing—do not take this Docker setup into production!
The Docker brings up an active-active multi-datacenter environment leveraging the new Replicator features, such as provenance headers to prevent cyclic replication of topics, timestamp preservation and consumer offset translation.
For testing, adapt the configurations to be more representative of your deployment and run your client applications against it. You may also use the provided sample client application to see how data consumption can resume in the new datacenter based on where it left off in the original datacenter. Then, simulate the failover and failback, test its behavior, test your runbook and verify that it all works.
In summary, a disaster recovery plan often requires multi-datacenter Kafka deployments where datacenters are geographically dispersed. Take these three steps to ensure you are prepared:
- Design a multi-datacenter solution
- Build a runbook for failover and failback
- Test! Test! Test!
You may be considering an active-passive design (one-way data replication between Kafka clusters); active-active design (two-way data replication between Kafka clusters); client applications that read from just their local cluster or both local and remote clusters; service discovery mechanisms to enable automated failovers; geo locality offerings; etc.
The latest version of the white paper Disaster Recovery for Multi-Datacenter Apache Kafka Deployments provides building blocks that you can apply to any of the above.
이 블로그 게시물이 마음에 드셨나요? 지금 공유해 주세요.
Confluent 블로그 구독



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...