It’s Here! Confluent’s 2026 Data + AI Predictions Report | Download Now
検索拡張生成 (RAG) とは?
RAG は、大規模言語モ�デル (LLM) によって生成される応答の精度と関連性を高めるために設計された生成 AI のアーキテクチャパターンです。これは、プロンプトが発行された時点でベクターデータベースから外部データを取得することによって機能します。このアプローチは、LLMが十分なコンテキストや情報がない場合に発生する可能性のある不正確さや捏造であるハルシネーションを防ぐのに役立ちます。
取得したデータが常に最新であることを保証するために、ベクターデータベースはリアルタイムの情報で継続的に更新する必要があります。この継続的な更新プロセスにより、RAG は利用可能な最新かつコンテキストに適したデータを確実に取得できます。
LLM は翻訳やテキスト要約などのテキスト生成に優れていますが、リアルタイムデータに基づいて非常に具体的な情報を生成するのは困難です。検索拡張生成 (RAG) は、外部データを取得して LLM にコンテキストを提供することでこの問題に対処し、クエリに対してより正確かつ適切に応答できるようにします。



RAG なしで LLM を使用する AI チャットボットについて考えてみましょう。コンテキスト、信頼性、リアルタイムデータがなければ、LLM はユーザーに有意義な価値を提供できません。
情報の精度を向上させるために、RAG システムはセマンティック検索とベクター検索を活用します。これにより、取得したデータのコンテキストを活用して、応答の関連性と正確性を高めることができます。
入力パラメータをリアルタイムデータと照合することにより、RAG は最新の情報を必要とするクエリに対処できます。例えば、RAG を使用した航空会社のチャットボットは、最も正確かつ最新の選択肢を提供することで、顧客が代替便や座席を見つけられるよう支援できます。高度な検索技術とリアルタイムデータの組み合わせにより、RAG は LLM が顧客の特定の要求に合わせてコンテキストに応じた応答を生成するのを支援します。
RAG を使用する理由



LLM の課題
LLM は生成 AI アプリケーションを構築するための優れた基礎ツールであり、AI をより利用しやすくしました。しかし、これには課題が伴います。
LLM は__本質的に確率的であり__、通常は大規模な__静的データ__のコーパスでトレーニングされます。その結果、最新のドメイン固有の知識が不足しています。知識のギャップがある場合、LLM はもっともらしく聞こえるにもかかわらず、誤りや誤解を招くような幻覚的な回答を提供する場合があります。生成 AI アプリケーションを使用する企業にとって、ハルシネーション は、顧客の信頼やブランドの評判を損ない、さらには法的な問題を引き起こす可能性があります。
LLM は__知識の忠実性と出所が不明確な「ブラックボックス」として機能する可能性があり__、データの品質と信頼性に関する潜在的な問題につながる可能性があります。
RAG アーキテクチャは、モデルの再トレーニングにかかる高いコストをかけずに、LLM 応答をリアルタイムデータで拡張することにより、これらの問題に対処します。LLM の運用にはコストがかかるため、処理されるトークンの数に基づいて、これらのコストが顧客に転嫁されることがよくあります。ベクターデータベースにクエリを行うことで、RAG はプロンプトに最も関連性の高いドメイン固有の情報をコンテキスト化し、正確な回答を提供して LLM への呼び出し回数を減らすことができます。これにより、処理されるトークンの数が減少し、コストが大幅に__削減されます__。LLMは、一度に把握できる情報量に上限があるため、プロンプトが長くなりすぎると、過去の内容がうまく反映されなくなる場合があります。この RAG パターンは、最も関連性の高い情報のみをフィルタリングすることで、他の方法では実現不可能なユースケースを可能にします。
RAG アーキテクチャは、LLM によって生成される機密情報に関連する__プライバシーの懸念__を最小限に抑えることも可能です。LLM の生成機能の速度を活用しながら、機密データをローカルに保存することができます。RAG は、プロンプトを LLM に送信する前に、モデルのナレッジライブラリ内のプライベートデータや機密データをフィルタリングする機会を提供します。



事前トレーニングまたは微調整された LLM に対する RAG の利点
RAG には、事前トレーニング済みまたは微調整済みの LLM に比べて明確な利点があります。
__事前トレーニング__では、大規模なデータセットを使用して LLM を最初からトレーニングします。これにより、広範なカスタマイズが可能になりますが、かなりのリソースと時間の投資が必要です。
__微調整__では、事前にトレーニングされたモデルを、特化したデータセットを用いて新しいタスクやドメインに適応させます。事前トレーニングよりもリソース効率は高いものの、微調整には依然としてかなりの GPU リソースが必要で、困難を伴う可能性があり、LLM が以前に学習した情報を誤って忘れたり、その能力が低下したりすることもあります。
一方、RAG は、LLM からの公開データを企業のドメイン固有データで拡張します。これにより、プロンプト時にコンテキストを使用して解析および推論��を行うことができます。さらに、RAG システムの後処理では生成された応答が検証され、LLM からの不正確な情報や誤った情報のリスクが最小限に抑えられます。
RAG は生成 AI の共通パターンとして登場し、モデルの再トレーニングを必要とせずに LLM の力をドメイン固有のデータセットに拡張しています。
RAG の利点
生成 AI における RAG の主な利点は以下の通りです。
リアルタイム情報へのアクセス
RAG は、リアルタイムデータストリーミングプラットフォームを使用してベクターストアを最新の状態に保つことで、運用データベースや産業データヒストリアンなどのソースからリアルタイムデータを取得します。これにより、LLM は最新かつ正確な応答を確実に生成することができます。
ドメイン固有の独自のコンテキスト
RAG は、独自のデータソースと非公開のデータソースからの情報を統合し、特定の業界、企業ポリシー、ユーザーのニーズに合わせてカスタマイズされた対応を可能にします。
高い費用対効果
RAG は、事前トレーニングや微調整のようなリソース集約型の方法への依存を減らし、よりコスト効率の高いソリューションを提供します。
ハルシネーションの減少
RAG は、信頼できるデータソースからの正確で最新の情報を LLM に提供することで、ハルシネーションのリスクを軽減します。例えば、ベクターストアに Kafka Topic から提供された最新情報があれば、チャットボットがクエリに応答するときに、正確で関連性の高いインベントリレベルにアクセスできるようになります。
セマンティック検索とベクトル検索



__セマンティック検索__は、AI システムがクエリの意味と意図を理解するのに役立つデータ検索手法です。自然言語処理 (NLP) を使用して、キーワード検索よりも深いところまで到達します。セマンティック検索は、クエリ内の単語を一致させるのではなく、単語やフレーズの意味を分析して、最も関連性の高い結果を取得します。
単語間の意味的類似性を分析する際に正確な結果を得るために、セマンティック検索はベクター検索を利用します。__ベクター検索__は、個々の単語、フレーズ、ドキュメントを、多次元空間の点としてのベクター (データの数値表現) に変換します。意味が密接に関連しているもの (バックパック、ナップザックなど) は、空間内でベクターがより近接に配置されます。このように、ベクター検索では、多次元空間で近くのベクターを検索するために、クエリがベクターに変換されます。両者の位置が近ければ近いほど、互いの関連性が高まります。
RAG はベクター検索とセマンティック検索の両方を活用します。例えば、MongoDB の Atlas Search Index は、非構造化データを検索するための両方の方法をサポートしています。Atlas Vector Search を使用すると、ベクターにキャプチャされた意味に基づいてデータを検索することができます。RAG は、ユーザーのクエリに対して最も正確でコンテキストに適した回答を見つける可能性を最大化します。
RAG のユースケース
RAG の汎用性と適応性は、さまざまな業界やリアルタイムシナリオでのワークフローを強化します。その例をいくつかご紹介します。
航空会社が使用するような独自のカスタマーサポート用チャットボットでは、RAG はフライトの再予約や座席変更などのタスクを容易にします。これにより、顧客の質問に即座に回答できるため、カスタマーサービスに電話する必要性と待ち時間が削減されます。
小売業において、RAG は顧客の360度データ、リアルタイムのモバイルアプリのインサイト、購入パターンを活用して、製品推奨システムをサポートしています。顧客が店内で閲覧したり、販売時点で取引を完了したりするときに、パーソナライズされた製品やアドオンを提案できます。
RAG は、生成 AI アプリケーションがリアルタイムの顧客とのやり取りや通話から簡潔で説得力のあるセールススニペットを生成するのを支援し、営業担当者がターゲットを絞った売り込みを効果的に行えるようにします。
RAG は、リアルタイムの物流情報にアクセスするために非常に有効です。�最も効率的なルートを自動的に生成することにより、正確な在庫レベルを維持し、配送を最適化するのに役立ちます。これには多額の投資が行われているものの、この種の制約充足問題に対する成果は、多くの分野において限られたものにとどまっており、特に十分な学習データが存在しない分野ではそれが顕著です。
ヘルスケア分野では、RAG は患者ごとに推奨される治療と事実に基づく医療報告書を取得して生成します。また、薬物相互作用の分析にも役立ち、患者ケアと AI 意思決定支援システムを強化します。
もっと詳しく
RAG 対応 AI チャットボットのデモを紹介するウェビナーをご覧ください。
RAG の仕組み
RAG は、LLM に関連性のある最新のコンテキストを提供し、最も正確な応答を生成します。エンドツーエンドのフローは、次のように要約できます。
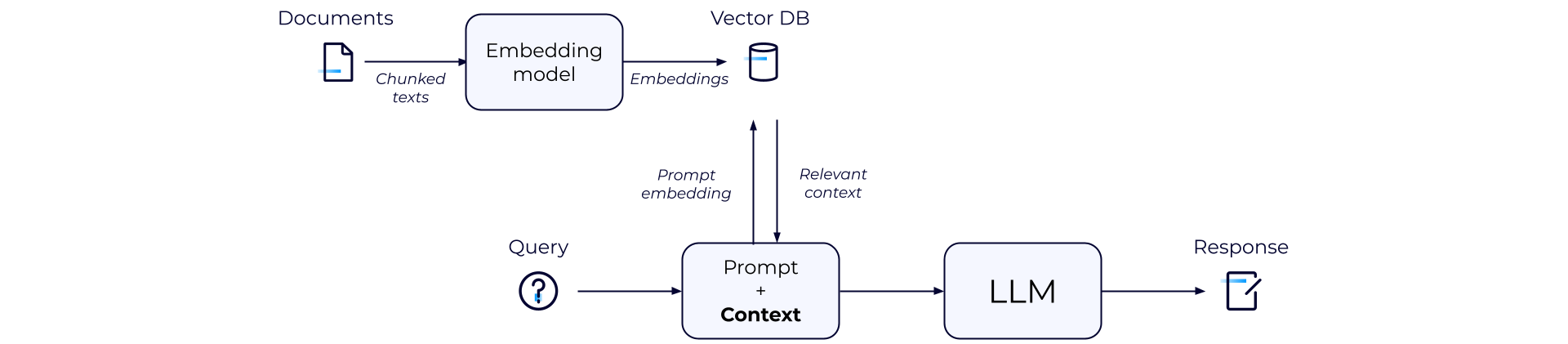
-
ドキュメントリポジトリや API などの外部データソースが収集されます。ドキュメントはチャンク化され、埋め込みモデルに渡されて埋め込みに変換されます。これらの埋め込みは、ベクターデ��ータベースに格納されます。2. ユーザーまたはマシンがクエリを送信すると、それが LLM のプロンプトとなり、生成 AI アプリケーションに送信されます。生成 AI アプリケーションは、RAG を使用して、LLM では利用できない関連データでクエリを強化します。
-
RAG システムはクエリをベクター埋め込みに変換します。セマンティック検索を活用して、RAG はプロンプトの埋め込みを最も関連性の高い情報と照合し、そのベクター埋め込みを取得します。
-
RAG システムは埋め込みを元のクエリと組み合わせ、追加のコンテキストで拡張した上で、それを LLM に渡し、ユーザーに対して自然言語で応答を生成します。
-
最後に、LLM の応答は、信頼性があり、ハルシネーションがないことを確認するために、後処理中に検証される必要があります。
RAG 構築における一般的なツール
コンテキスト固有のリアルタイム RAG アーキテクチャの構築には、いくつかのツールが頻繁に使用されます。
LangChain や LlamaIndex などの__フレームワーク__は、LLM を使用する生成 AI アプリケーションの構築をサポートしています。これらは、データの統合、取得、ワークフローのオーケストレーション、LLM のパフォーマンス向上に役立ちます。
GPT、Gemini、Claude、Olympus、LlaMA、Falcon、PaLM などの__LLM__は、高品質な応答を生成するためのバックボーンとして機能します。
Pinecone、Weaviate、Zilliz、MongoDB などの__ベクトルデータベース__は、データを数値ベクトルとして保存します。これにより、RAG システムはプロンプト時に最も関連性の高いデータを取得できるようになります。
__埋め込みモデル__�はデータを埋め込み、意味を保持する数値ベクターに変換します。これらには、OpenAI、Cohere、HuggingFace などのプラットフォームや、Word2Vec などのツールが含まれます。
データストリーミングのデファクトスタンダードである Apache Kafka は、あらゆるソースからリアルタイムデータを取り込み、下流のコンシューマーが即座に利用できるようにします。分離されたイベントドリブン型アーキテクチャにより、一貫性とスケーラビリティが実現します。
Apache Flink は、実行中のデータを充実化、変換、集約するために使用されるオープンソースの分散ストリーム処理フレームワークです。低レイテンシのステートレスおよびステートフル計算を実行し、処理済みのデータを取得用に提供できます。
Confluent を使用した RAG の構築
Confluent データストリーミングプラットフォームは、リアルタイムでコンテキスト化された信頼できるナレッジベースを提供し、推論時にプロンプトと組み合わせてより良い LLM 応答を生成できるよう、RAG の実装をサポートします。Confluent は、生成 AI アプリケーションチームの参入障壁を低減し、市場投入までの時間を短縮するとともに、データのセキュリティとコンプライアンスのガードレールを提供します。
データストリーミングプラットフォームを使用して RAG 対応の生成 AI アプリケーションを構築するには、次の4つの重要なステップがあります。
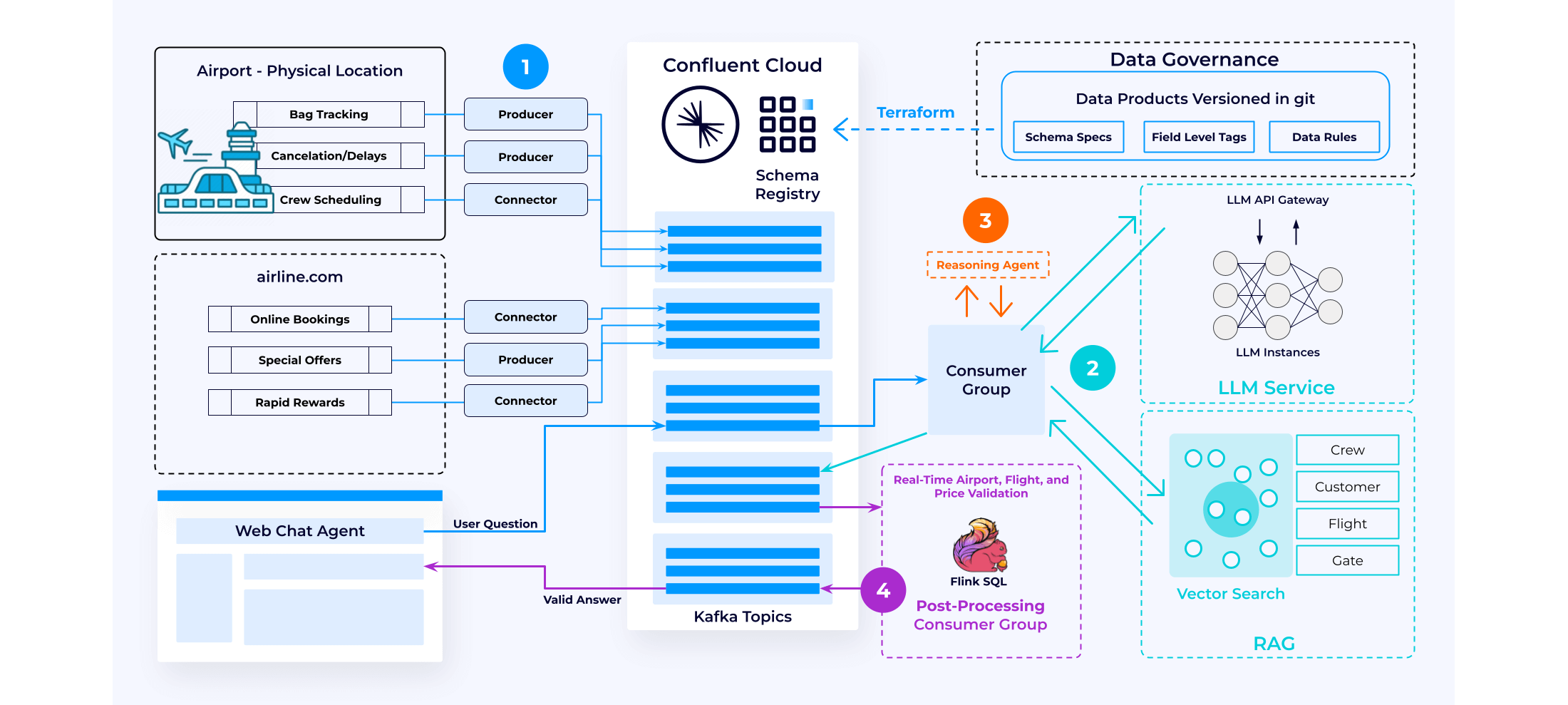
データ拡張
Confluent は、さまざまなデータソースからデータストリームを継続的に取り込み、処理して、リアルタイムのナレッジベースを作成します。このフェーズでは、Flink SQL のようなツールがベクター埋め込みサービスを呼び出し、データをベクターで拡張することができます。処理されたデータは、シンクコネクタを使用してベクターデータベースに格納されます。この設定により、継続的に更新される情報を含むベクターデータベースに対する RAG が可能になります。
推論
コンシューマーグループが Kafka Topic からユーザーの質問とプロンプトを取得し、ベクターストアデータベースのプライベートデータでそれを充実化します。このプロセスでは、ユーザーのクエリを調べ、それを使用してベクターデータベース内でベクター検索を実行し、関連する結果を追加のプロンプトとして追加します。たとえば、フライトが欠航となった場合、KNN (k 近傍法) 検索により、次に利用可能な最適なフライトオプションを特定できます。このように充実化され、コンテキストに関連したデータは LLM サービスに送信され、包括的な応答が生成されます。
ワークフロー
生成 AI アプリケーションが単一の自然言語クエリを構成可能な複数の論理クエリに分割し、リアルタイムで情報を利用可能にするために、推論エージェントがよく使用されます。このアプローチは、クエリ全体を一度に処理するよりも効果的です。
このようなワークフローでは、一連の LLM 呼び出しが使用され、推論エージェントがプロンプトの出力に基づいて次のアクションを決定し、シームレスな対話とデータ取得を可能にします。
後処理
多くの組織は、LLM の出力にそのまま依拠することにまだ不安を感じています。自動化されたワークフローでは、すべてのアプリケーションにビジネスロジックとコンプライアンス要件を適用するステップが含まれています。
イベントドリブン型パターンを使用すると、生成 AI ワークフローを後処理から切り離すことができ、独立した開発と進化が可能になります。Confluent は、LLM の出力を検証し、ビジネスロジックとコンプライアンス要件を強制して、信頼できる回答を保証します。これにより、AI ドリブン型ワークフローの信頼性と精度が向上します。
その他のリソース
利用の開始
Confluent Cloud の利用を無料で開始し、生成 AI ユースケースのためのリアルタイムでコンテキスト化された信頼できるナレッジベースを構築し始めましょう。