Getting Started with the KRaft Protocol
What is KRaft, and how does it work?
Apache Kafka® Raft (KRaft) is the consensus protocol that was introduced to remove Apache Kafka’s dependency on ZooKeeper™ for metadata management. This greatly simplifies Kafka’s architecture by consolidating responsibility for metadata into Kafka itself, rather than splitting it between two different systems: ZooKeeper and Kafka. KRaft mode is available in the Apache Kafka 3.1 release, though it is not yet ready for use in production environments. Refer to KIP-833 to learn more about when KRaft will be marked as production ready.
Below are several key resources to help you learn everything you need to know about the ins and outs of KRaft, its role in the Kafka architecture, and how you can get started in trying it out. These resources are followed by two others that let you “do stuff” with Kraft, i.e., run a KRaft mode cluster and observe how it works when various cluster controller related operations take place.
Learn more about KRaft
Why ZooKeeper Was Replaced with KRaft – The Log of All Logs
This blog post by Guozhang Wang explores the rationale behind the replacement of ZooKeeper. With the current Kafka architecture that uses ZooKeeper as its source of truth for cluster metadata, read and write traffic on ZooKeeper can become a bottleneck as the cluster grows. This problem is exacerbated by Kafka relying upon a single controller for the majority of ZooKeeper access. The effects of this bottleneck significantly impact how the cluster deals with broker shutdown and controller failover. This blog post describes how the KRaft quorum-based consensus protocol solves each of these problems.
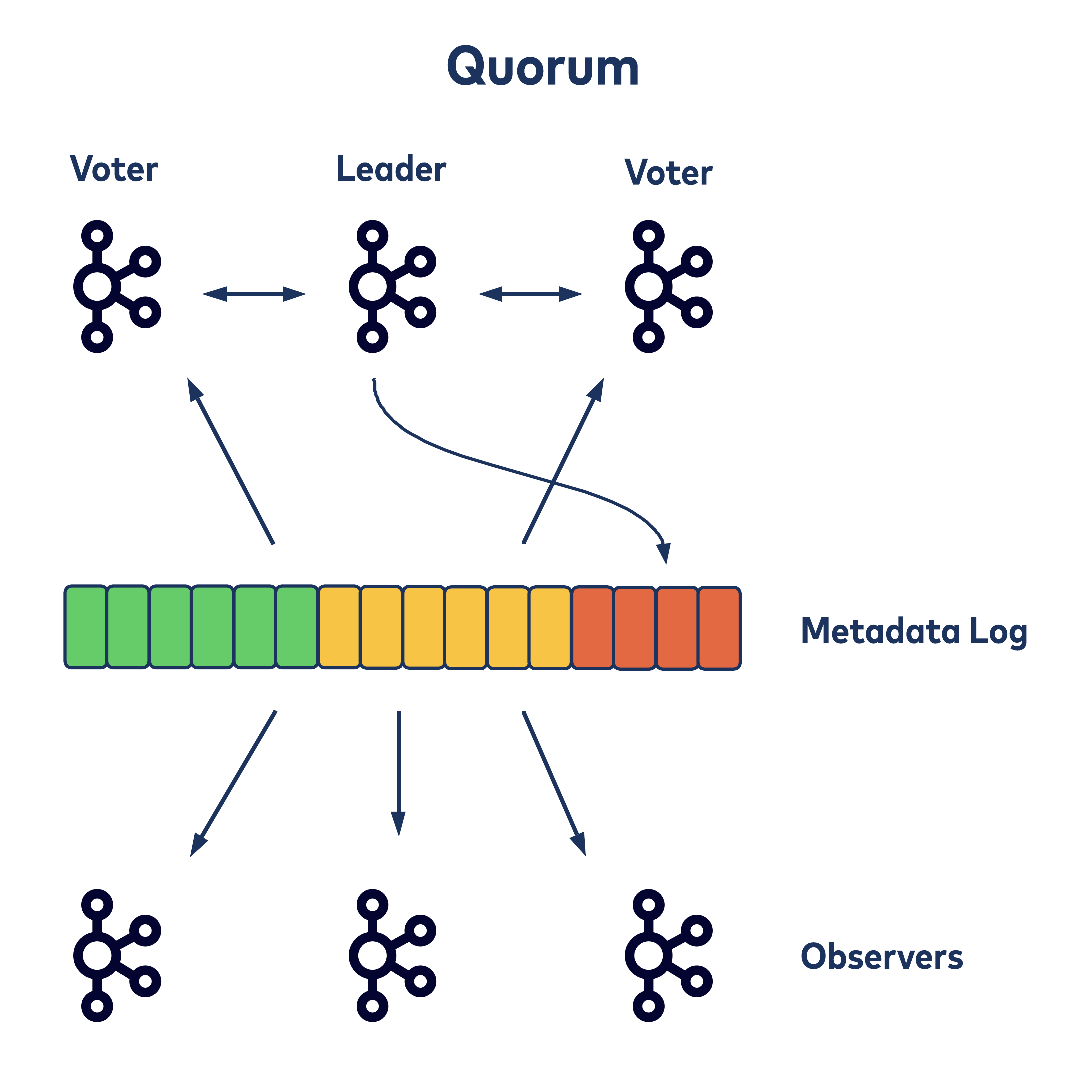
Apache Kafka Internal Architecture Course
There are several resources on the Confluent Developer site to help you learn more about KRaft, but one particular recommendation is a module in the recently released Apache Kafka Internal Architecture course. In this course Jun Rao, one of the original co-creators of Apache Kafka, describes in detail how many key components of the Kafka architecture operate. In addition to a module that covers the Kafka KRaft consensus protocol, it includes modules that cover the Kafka broker request processing loop, the Kafka replication protocol, the Kafka consumer group protocol, Kafka transactions, and Kafka topic compaction.
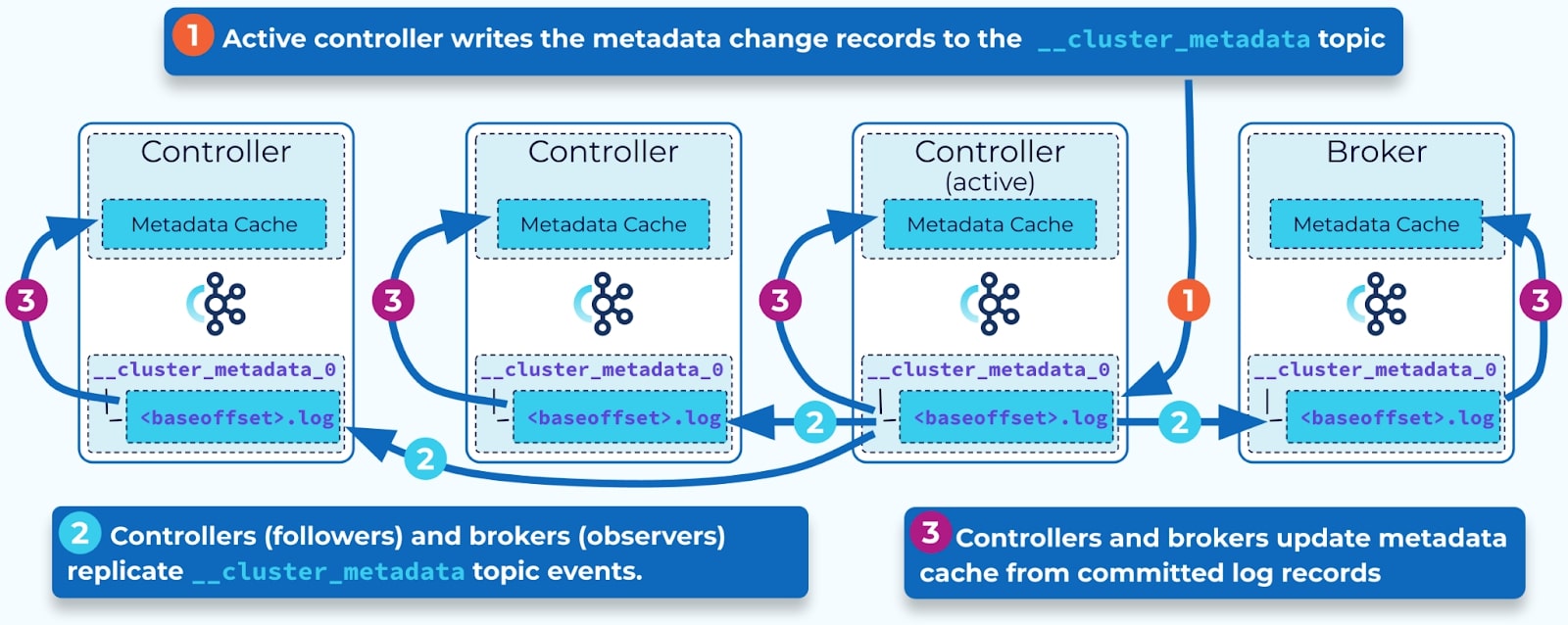
In The Apache Kafka Control Plane module Jun explains how the KRaft consensus protocol is used to elect the active cluster controller, how cluster metadata is propagated to follower controllers and brokers, and how cluster metadata is reconciled when a new active controller is elected.
Preparing Your Clients and Tools for KIP-500: ZooKeeper Removal from Apache Kafka
This blog post identifies configuration changes that may need to be made related to the removal of ZooKeeper from Kafka. It specifically covers changes related to Kafka clients and services, Confluent Schema Registry, Kafka administrative tools, the REST Proxy API, and the Kafka cluster ID.
| With ZooKeeper | Without ZooKeeper | |
| Configuring clients and services | zookeeper.connect=zookeeper:2181 | bootstrap.servers=broker:9092 |
| Configuring Schema Registry | kafkastore.connection.url=zookeeper:2181 | kafkastore.bootstrap.servers=broker:9092 |
| Kafka administrative tools | kafka-topics --zookeeper zookeeper:2181 ... | kafka-topics --bootstrap-server broker:9092 … --command-config |
| REST Proxy API | v1 | v2 or v3 |
| Getting the Kafka cluster ID | zookeeper-shell zookeeper:2181 get /cluster/id | kafka-metadata-quorum or view metadata.properties or confluent cluster describe --url http://broker:8090 --output json |
Get started with KRaft
Apache Kafka Quick Start
This resource includes a guide that demonstrates how to quickly get started with Apache Kafka. First you start up a Kafka cluster in KRaft mode, connect to a broker, create a topic, produce some messages, and consume them. Be sure to also check out the client code examples it provides at the end of the guide to learn more.
./bin/kafka-storage format \
--config ./etc/kafka/kraft/server.properties \
--cluster-id $(./bin/kafka-storage random-uuid)
Apache Kafka KRaft Mode Playground
This GitHub repo includes a Gitpod workspace definition that is set up to run an Apache Kafka KRaft mode cluster. It includes an exercise guide that walks through starting up the cluster and observing things like a cluster metadata snapshot being written, compares the cluster metadata structure contained in two point-in-time snapshots, examines the contents of the __cluster_metadata log, identifies records in the log associated with a broker failure and a resulting partition leader election, and observes the first snapshot and log segments being deleted by the log cleaner.
Summary
Apache Kafka KRaft mode will soon be production-ready for new clusters. To follow the current status of this milestone, check out KIP-833. And for those that are ready to leave ZooKeeper for KRaft, check out the 42 ways that doing so will make you happier.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


