Want to migrate to AWS Cloud? Use Apache Kafka.
Amazon’s AWS cloud is doing really well. Doing well to the tune of making $2.57 Billion in Q1 2016. That’s 64% up from Q1 last year. Clearly a lot of people are interested in what AWS has to offer – anything from reducing capital expenses to hiring fewer IT experts. AWS is doing so well that I’d be hard pressed to think of a single company I’ve talked with in the last year that isn’t already running, at least partially, in a public cloud.
One thing we noticed when talking to all those companies is that no one moves to the cloud all at once. They start with a new use-case or a new application. Sometimes it can just run independently in the cloud, but far more often it needs some data from the on-premise datacenter. Maybe it is mostly independent but just needs an update whenever a user modifies their account. Or perhaps the new application is collecting important usage information that you want to send to the on-prem data warehouse for BI analytics.
If this is successful, they will start additional new use-cases in the cloud. Each with its own event pipeline. After few of those, you decide to migrate an existing application. Maybe you have a legacy app that uses an old database that you want to migrate to the cloud and to a modern data store, or perhaps you have a monolith that you are planning to modernize by migrating to cloud microservices, or perhaps you are deploying a new mobile application. Large application changes are often an important driver for migrating an existing app to the cloud.
If the first migration is successful – more applications will follow: Brand new applications will start in the cloud and will need some data from existing applications that are still running on-prem. Existing applications will slowly migrate but will need a strategy for migrating the data, often moving to a whole new database (or several) in the process.
It is important to acknowledge that this process of slowly moving to the cloud can take years in a mature organization. Netflix continued running some services in their own datacenters for many years after they were the world’s foremost expert in running on AWS. When Dropbox did the reverse journey to move off the cloud, it took them 2.5 years – and that is probably a record.
The most important lesson you can learn from these stories is that you must plan for this gradual process from the get go. Maybe do one experimental cloud app without deep organization-wide planning, but if this experiment is successful (and it always is), you will need to plan for few years of slowly transitioning to the cloud – application by application.
If you don’t plan holistically and instead let each team and department execute their own cloud migration, it is very likely that you will end up with something like this:
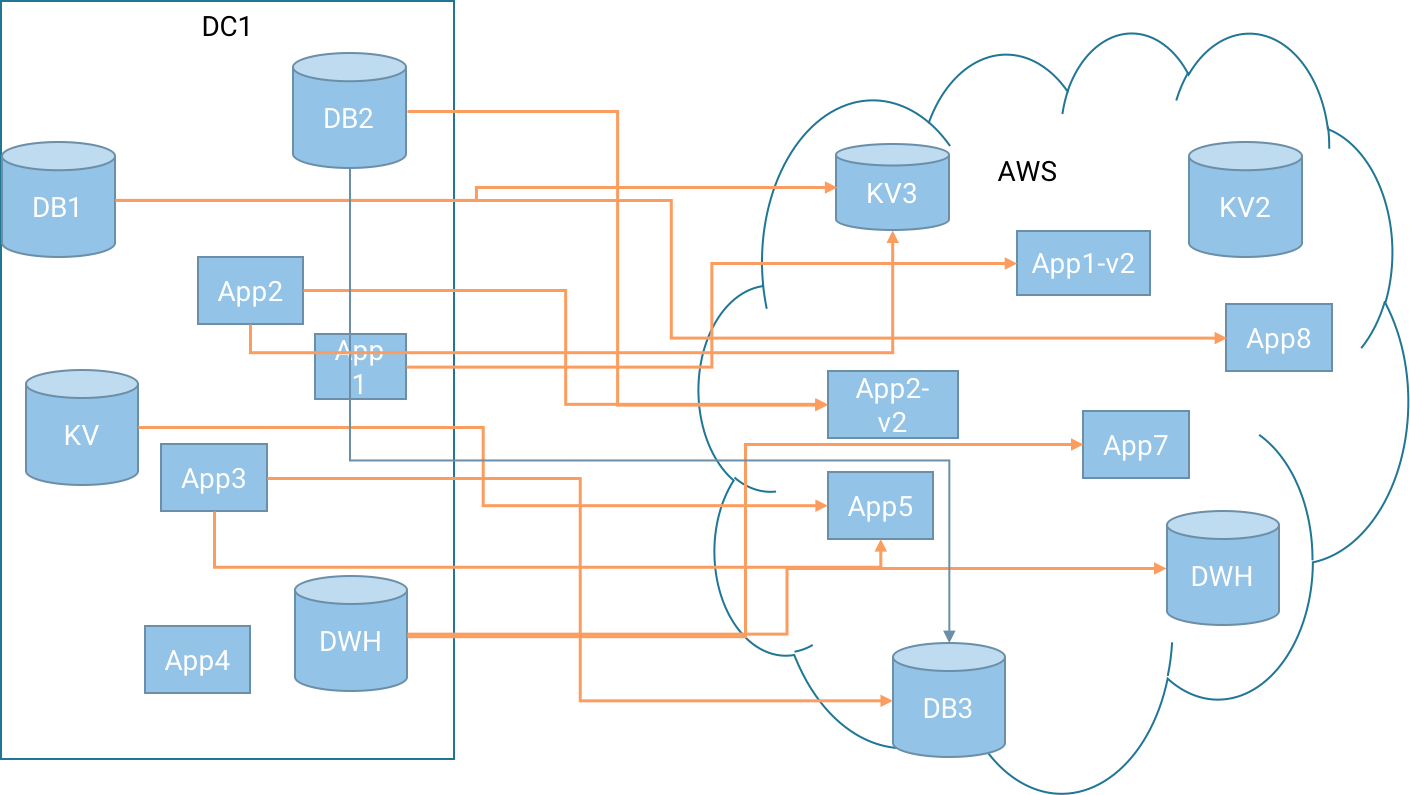
Every one of those orange lines between your datacenter and AWS is its own special pipeline – catering to the needs of one team and one application. They may be carrying the exact same data (many apps in retail organization need to know when a user returns a product), but more important – they each require development, testing, deployment, monitoring and maintenance. And the more apps you move, the more of those things your organization will need to support and maintain. As you’ve seen in the examples earlier, cloud migration doesn’t happen in batches, you need a continuous pipeline feeding incremental updates to the applications deployed in the cloud.
In addition to the development and operational costs, there is also data quality concerns. If you are copying the same data 3 times, will the three applications have the same view of the world? What if one loses data? Are you sure all pipelines provide the same level of reliability? Does your organization really have a source of truth in this scenario?
All those are serious concerns. And when we started talking to our customers about them, they also seemed eerily familiar. We’ve been in the business of sorting out complicated data pipelines for a long time now. After all, we are the Apache Kafka company and Kafka’s claim to fame is taking LinkedIn from:
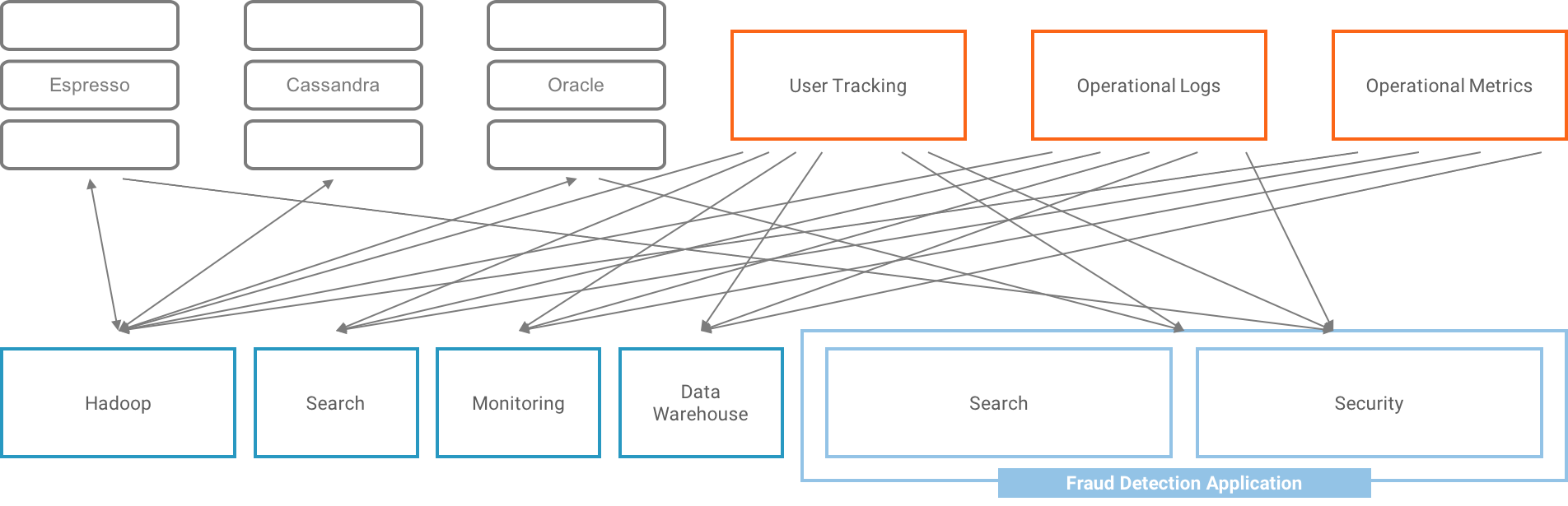
To
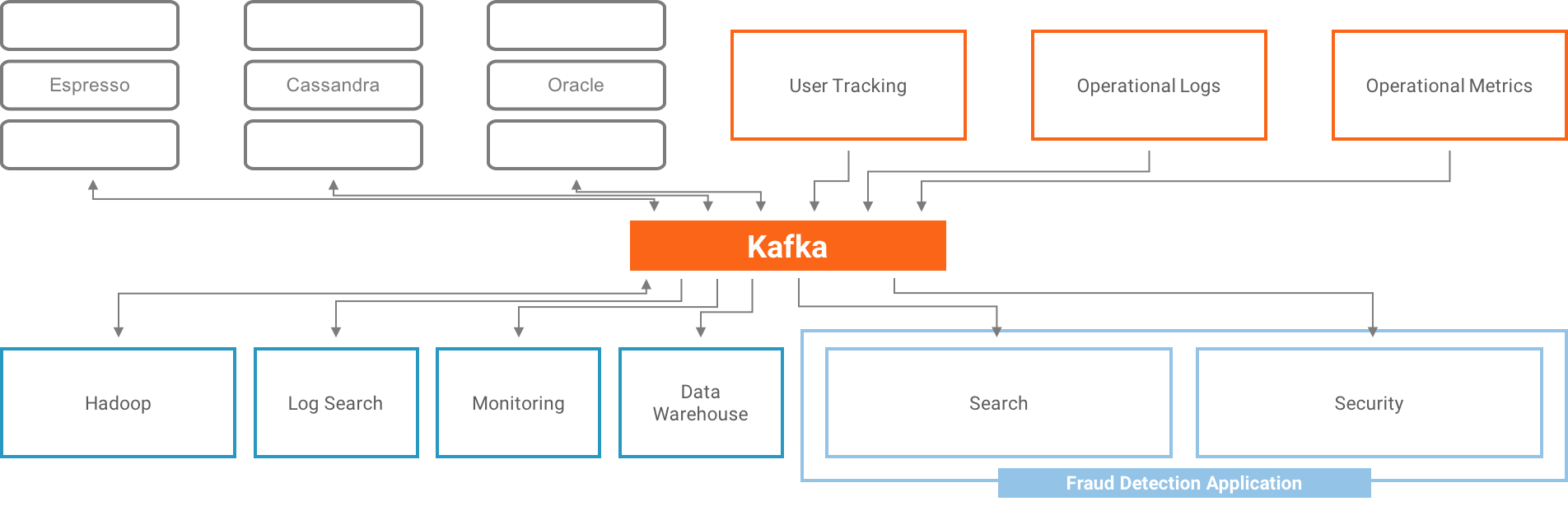
A large number of companies worldwide have been using Kafka to integrate data pipelines, bridge data centers in a streaming fashion for many years now. While the cloud certainly presents new challenges, centralizing organizational pipelines is not one of them. It is an old and familiar pattern.
Let’s see how we apply this central-pipeline pattern to the long-term cloud migration plan and then we’ll discuss the benefits and drawbacks of using this architecture:
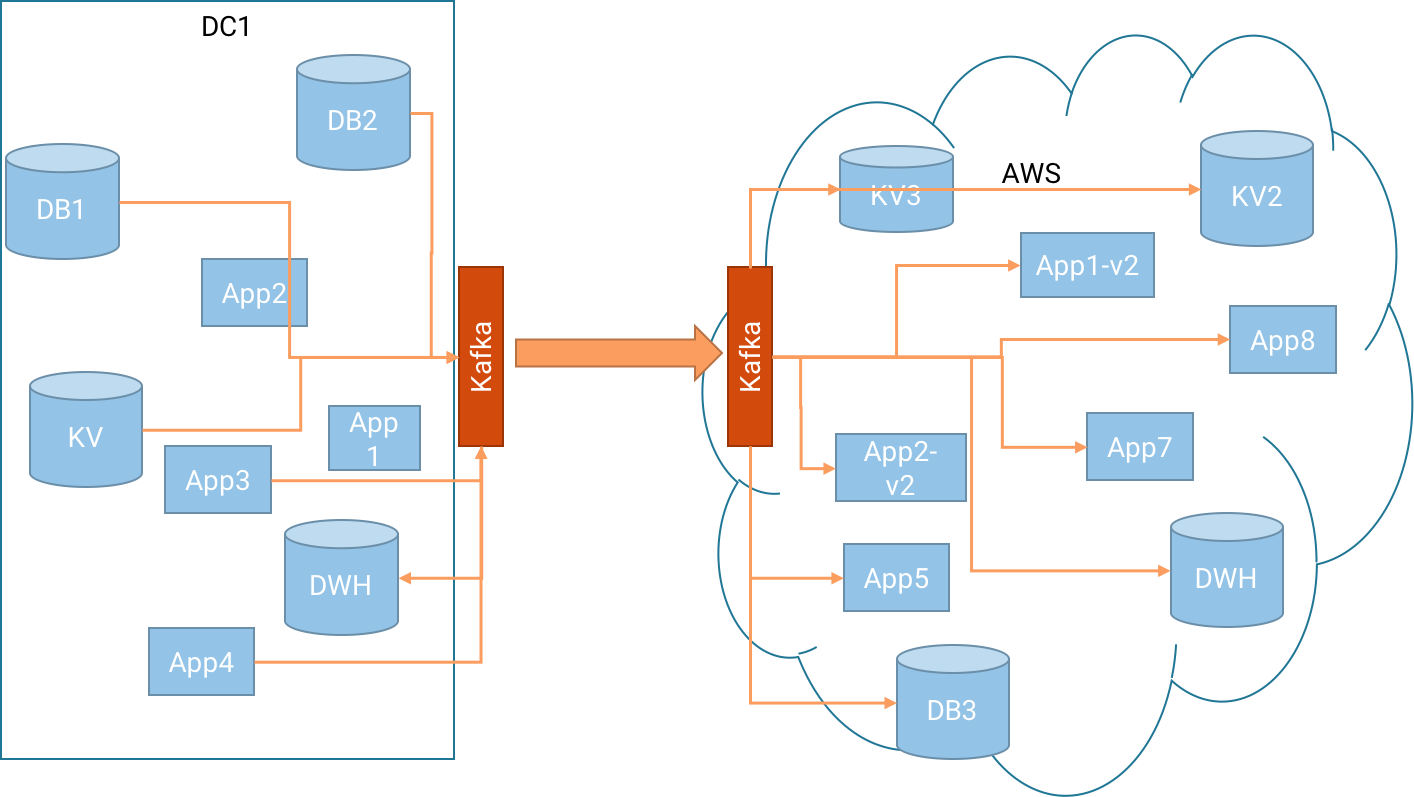
The core idea here is that instead of building a single pipeline for each application and use-case that comes up, we make sure all the necessary data is available in a Kafka cluster in our on-prem datacenter. Then we use Kafka’s replication tool – MirrorMaker, to stream all the data from the on-prem Kafka to a second Kafka cluster in AWS. From there, it is available for each application and datastore that needs it.
Of course, many organizations don’t already have Kafka as a central bus connecting all their applications. This is fine and definitely not mandatory (although it doesn’t hurt). We realize that modifying every single application to report its events to Kafka is not a realistic requirement. This is why Connect API in Kafka exists, so you can use connectors to get data directly from the various data stores into Kafka. The same is true in AWS: you don’t need to modify all your apps to read from Kafka; you can use Connect API to push data directly into the data stores that your apps are using.
We usually see organizations use both strategies: some apps are modified to work directly with Kafka. Especially apps that fit the streaming data models — apps that already use a message bus or monoliths that are converted into microservices. In other cases, connectors are used to integrate with data stores directly, most often when database migration is one of the goals. It is also very common to see a mixture – you use Connect to get events from, let’s say, Oracle to on-prem Kafka, use MirrorMaker to replicate to Kafka in AWS, and then have several applications consume the events from Kafka.
I think you already have a sense of the potential of this architecture pattern, but let’s look at the benefits more closely:
- Proven long term multi-datacenter architecture: This architecture acknowledges the reality of cloud-migration projects – they are not a one-time project that finishes in few weeks and they are not limited to one application. Organizations need an architecture that allows them to run in cloud and on-prem (or in multiple clouds) for many years. After all, we’ve seen organizations take anything between 2 to 8 years just to migrate to a new data warehouse. We shouldn’t expect the entire organization to move to the cloud in a matter of weeks. You need an architecture that is built with a long term multi-datacenter vision in mind. This architecture provides a path forward: You can data to Kafka once, and it allows you to add more applications in the future that might need the same data in order to operate in the cloud.
- Continuous low-latency synchronization: Data is continuously synchronized between on-prem services and cloud services at relatively low latencies. The synchronization latency can be as low as 100s of milliseconds with a fast network and a properly configured MirrorMaker. No need to worry that one is ahead and the other is behind – both are equal citizens in the architecture.
- Centralized manageability and monitoring: Having one central pipe means you have only one cross-datacenter link to monitor and manage. This simplifies operations a lot, and simpler operations is usually higher availability and fewer headaches. We put all the eggs in one basket and then manage and monitor the heck out of that basket. In addition to system level monitoring, we also suggest using end-to-end monitoring available in Confluent Control Center. This will allow you to track events produced in each data center and see who is consuming them, what is the latency and make 100% sure that all events safely arrived to their destination.
- Security and governance: A central pipe also means that it is simpler to implement your security requirements. When LinkedIn discovered that all data going to Europe needs to be encrypted, they just needed to apply SSL encryption to the link between the two Kafka clusters – a simple configuration change. Imagine the amount of work involved if there were 20 different replication solutions for all kinds of different databases and applications. What if some of them don’t even have a secured replication solution? More than that, a big part of security is governance – this architecture helps you track and control where data comes from and who is accessing it.
- Cost savings: By making sure you have a single pipeline and every piece of source data is streamed to the cloud just once (and not multiple times for multiple applications), this architecture cuts down cross data-center traffic and thereby cuts down on costs. Especially if you take advantage of Kafka’s built-in compression. You also cut down significantly on development time, allowing you to accelerate the migration to the cloud of any application – after setting up the initial pipe, the data will be available immediately to any app that needs to migrate.
To summarize a long discussion – every organization is planning (or already implementing) a migration to the cloud. We are seeing evidence that this migration isn’t a one-time 2-month project, but rather an ongoing process that can last multiple years. We propose implementing a central-pipeline architecture using Apache Kafka to sync on-prem and cloud deployments – this architecture reduces costs, accelerates migration times and makes the migration process more manageable and therefore safer.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...