Testing Event-Driven Systems
So you’ve convinced your friends and stakeholders about the benefits of event-driven systems. You have successfully piloted a few services backed by Apache Kafka®, and it is now supporting business-critical dataflow.
Each distinct service has a nice, pure data model with extensive unit tests, but now with new clients (and consequently new requirements) coming thick and fast, the number of these services is rapidly increasing. The testing guardian angel who sometimes visits your thoughts during your morning commute has noticed an increase in the release of bugs that could have been prevented with better integration tests.
Finally after a few incidents in production, and with velocity slowing down due to the deployment pipeline frequently being clogged up by flaky integration tests, you start to think about what you want from your test suite. You set off looking for ideas to make really solid end-to-end tests. You wonder if it’s possible to make them fast. You think about all the things you could do with the time freed up by not having to apply manual data fixes that correct for deploying bad code.
At the end of it all, hopefully you’ll arrive here and learn about the Test Machine.
The Test Machine
Funding Circle is a global lending platform where investors lend directly to small businesses in Germany, the Netherlands, the UK and the U.S. (and soon in Canada). A typical borrower repayment triggers actions in several subsystems and if not done promptly and correctly, can prevent investors from making further investments. The Test Machine is the library that allows us to test that all these systems work together.
We built the Test Machine at Funding Circle because we did not have enough confidence in our unit tests alone. The TopologyTestDriver is great for unit testing a single topology at a time, and the Fluent Kafka Streams Tests wrapper helps reduce repetitive code and captures a common pattern for testing Kafka Streams. But the system we were responsible for was a mish-mash of Ruby on Rails, Apache Samza, Kafka Connect and Kafka Streams, which seems to be a common scenario (for those on the journey to event driven).
The tests we had that exercised the entire stack were “flaky” and slow (both usually due to subtle errors in the test code). After reviewing the fixes to a number of these full stack tests, we realized that many of our tests matched a fairly simple pattern:
- Ensure supporting topics exist
- Start the application under test (“application” here could mean Kafka Streams, Kafka connectors, Samza, etc.)
- Send some input events
- Wait until the application has finished processing the test input
- Assert that it looks right
It was quite easy to make mistakes when implementing this pattern using the Kafka APIs directly. This led us to create a simple, functional, pure data interface, and we hoped this pattern would be a popular utility.
The interface is implemented using Clojure but thanks to the Confluent ecosystem, the system under test can be anything from an unholy assortment of Rails applications, Kafka Connect jobs and “untestable” PL/Perl triggers, to the latest, greatest, highly replicated, fault-tolerant, Kafka-Streams-based self-distributing API. The only requirement is that all the events we care about are seen by Kafka.
This post discusses the main components of the system independent of their implementation, because you can actually implement them on other platforms in whichever ways are most useful for you. (I’m looking forward to seeing what other folks have come up with to solve similar problems!) The figure below illustrates the high-level design of the Test Machine:
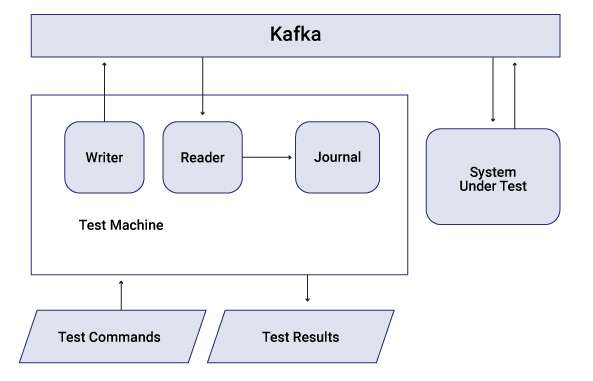
Tests as data
Test authors shouldn’t be concerned with the mechanics of writing test data to Kafka. The examples you see in the docs are great for getting started. However, once your application starts to use even just a handful of inputs, all the code for manipulating a Kafka producer directly for each input can obscure what should be fairly simple data required to make the test pass.
This can be resolved by adopting a data notation for test inputs combined with a pure function designed to determine when the test has completed. In Clojure we can use Extensible Data Notation (EDN) for this purpose. A sample test input intended for the Test Machine is included below, but you could come up with something similar using JSON or YAML.
[[:write :customer {:id 101, :name "andy"}]
[:write :order {:id 1001, :customer-id 101,
:items [{:qty 1, :amount 99}
{:qty 3, :amount 95}]}
[:watch (fn [journal]
(->> (get-in journal [:topics :shipping-instruction])
(filter #(and (= 101 (:customer-id %))
(= 1001 (:order-id %))))
(first)))]]You’ll find that it can be helpful to define an external mapping from identifiers like :customer and :order to conventions about how to serialize and extract keys or partitions from the messages destined for that topic. This allows the creation of generic procedures to handle these functions for all topics even when the system under test uses a variety of conventions.
Journal everything
There are also a few things to get right in order to correctly consume an application’s test output. For example, the consumer should probably be configured to start from the latest recorded offsets so that it is not affected by old test data. In addition, managing the consumer lifecycle for each output topic is another opportunity for error. But the topic mapping described above has utility on the consumer side too.
- It can be used to create a single consumer subscribed to all output topics before producing any of the input test data (even if each topic uses a different SerDes)
- It can identify conventions implemented elsewhere about how to deserialize messages and add them to the journal
In the Test Machine, we use a dedicated thread to consume from all listed topics and automatically deserialize them before adding them to the journal. This makes them available for final validation as simple maps representing the data contained in the consumer records. Thus, not only can test assertions be super simple but when they fail, we can also inspect the journal to see why.
Portable tests
Applying the patterns described above enables an interesting method of reusing tests to further increase confidence in the correctness of the system under test by running the test against a variety of targets. The key to unlocking this feature is to define tests as a sequence of commands consisting of writes and watches. Each command is executed in order and blocks until it is complete. A write command simply writes an event to Kafka, while a watch command watches the output journal until a user-specified condition is met.
The small size of this “test grammar” means that the implementation of an interpreter for the commands can easily be taught how to run against a variety of targets. So for example, the Test Machine contains implementations that run against the following targets:
- A local Kafka cluster (requiring direct access to ZooKeeper and Kafka brokers)
- A remote Kafka cluster (requiring only HTTP access to Confluent REST Proxy)
- A mock topology processor
This means that during development, you can quickly try out changes using the mock topology processor (which uses the standard TopologyTestDriver under the hood). Then, before pushing, you can run the entire test suite against a local Kafka cluster (provided by Docker Compose or Confluent tools). When you’re about to merge, you can run the exact same test suite against your staging environment after deploying your code there.
Test performance
We are talking about full stack testing here so that means I/O. If your brokers are writing to spinning metal, you’re not going to get the blazing performance of in-memory tests. However getting a few thousand tests to run within a couple of minutes should be achievable.
Here are a few things to consider if your test suite is slower than you’d like:
- We can reduce some unnecessary overhead by using a single consumer and single producer for each test as described above.
- If each test defines its expectations based on its own input data, tests can be highly parallelizable. To support this, the tests should not care what has gone on before. All data required to set up the system for a test should be included in the test itself.
- Starting/stopping the system under test is often the slowest operation. Try to leverage whatever facilities your test framework has to arrange for this to occur only once during the entire test run (or at least once per high-level domain).
Show me the code
The Test Machine is included as part of Jackdaw, which is the Clojure library that Funding Circle uses to develop event streaming applications on the Confluent Platform. Jackdaw comes bundled with a few examples, and the word count example includes a test (also included below) that uses the Test Machine to check that the resulting output stream correctly counts the words given in the input.
(defn input-writer
[line]
[:write! :input line {:key-fn identity}])
(defn word-watcher
[word]
[:watch (fn [journal]
(some #(= word (:key %))
(get-in journal [:topics :output]))) 2000])
(deftest test-word-count-demo
(fix/with-fixtures [(fix/integration-fixture wc/word-count test-config)]
(fix/with-test-machine (test-transport wc/word-count-topics)
(fn [machine]
(let [lines ["As Gregor Samsa awoke one morning from uneasy dreams"
"he found himself transformed in his bed into an enormous insect"
"What a fate: to be condemned to work for a firm where the"
"slightest negligence at once gave rise to the gravest suspicion"
"How about if I sleep a little bit longer and forget all this nonsense"
"I cannot make you understand"]
commands (->> (concat
(map input-writer lines)
[(word-watcher "understand")]))
{:keys [results journal]} (jd.test/run-test machine commands)]
(is (every? #(= :ok (:status %)) results))
(is (= 1 (wc journal "understand")))
(is (= 2 (wc journal "i")))
(is (= 3 (wc journal "to"))))))))
As you can see, the test builds a list of commands consisting of a write for each input line, and a watch for the word “understand” since that’s the last word to be seen by the word counter. It then submits this sequence of commands to the Test Machine and asserts that the expected counts are observed for a selection of words.
You can try it out yourself!
-
- Setup:
$ brew install clojure $ git clone https://github.com/FundingCircle/jackdaw.git $ cd jackdaw/examples/word-count
- Run the tests against the TopologyTestDriver:
$ clj -A:test --namespace word-count-test
- Run the tests against a local Kafka cluster:
$ docker-compose up -d zookeeper broker $ export BOOTSTRAP_SERVERS=localhost:9092 $ clj -A:test --namespace word-count-e2e-test
- Run the tests against a remote Kafka cluster (via the REST Proxy):
$ docker-compose up -d rest-proxy $ export REST_PROXY_URL=http://localhost:8082 $ clj -A:test --namespace word-count-e2e-test
- Setup:
Now, you’re ready to go write tests for your own application! However it is implemented, as long as its input and output are represented in Kafka, you can use the Test Machine to test it, and in doing so, keep the focus of the test where it belongs—on the data and the program logic.
Interested in more?
If you’d like to know more, you can download the Confluent Platform to get started with the leading distribution of Apache Kafka.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



3 Strategies for Achieving Data Efficiency in Modern Organizations
The efficient management of exponentially growing data is achieved with a multipronged approach based around left-shifted (early-in-the-pipeline) governance and stream processing.



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.