Streaming SFDC Data to BigQuery for Real-Time Customer Analytics
A common challenge organizations face is how to extract, transform, and load (ETL) Salesforce data into a data warehouse so that the business can use the data. Salesforce (SFDC) is a business-critical customer relationship management (CRM) application commonly used by organizations to maintain information about ongoing customer engagements and deals.
Business use cases vary, but commonly include forecasting numbers (annual and quarterly), running sales analytics, and evaluating marketing efforts (e.g., lead scoring and alerts).
Organizations often rely on a third-party ETL tool to periodically load data from SFDC to their data warehouse. These batch tools introduce a lag between when the business events are captured in SFDC, and when they are made available for consumption and processing. This also commonly results in discrepancies between Salesforce reports and internal dashboards, leading to concerns about the veracity and reliability of the data.
At Confluent, we rely heavily on extracted SFDC data in Google BigQuery to power analytics for internal field and marketing teams. Over the past few years, Confluent has invested in building out stream processing capabilities and a vast portfolio of connectors around Apache Kafka®.
This blog post shares how we internally leverage fully managed Confluent Cloud connectors (e.g., SFDC CDC Source and BigQuery Sink), Schema Registry, ksqlDB, and Kafka Streams (KStreams) to build a streaming data pipeline to send SFDC data to BigQuery.
Terms and technology choices
Change data capture (CDC) is a process of identifying changes in the source system, packaging them into events, and writing them to a Kafka topic.
In the context of Salesforce, CDC events are often referred to as “Change Data Events.” The data changes are propagated as the interested Salesforce object gets updated, which can be conceptualized as follows:
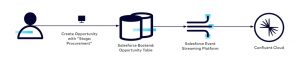
Figure 1: Data flow from Salesforce to Confluent Cloud
Salesforce connect solutions:
Confluent Cloud offers fully managed connector solutions of Salesforce: CDC Source, Bulk API Source, PushTopic Source, Platform Event Source and Sink, and SObjects Sink.
Google Cloud connect solutions:
Confluent Cloud offers fully managed connector solutions to different components on Google Cloud: BigQuery, Cloud Storage, Spanner, Dataproc, PubSub, and Cloud Functions. You can browse the connector catalog to view them all.
Before we dive into streaming SFDC data using our Confluent Cloud connectors, let’s examine what a common batch solution for this problem may look like.
The shortcomings of a batch solution
In this section, we demonstrate how a common batch ETL architecture can create a 4-6 hour delay. There are two main ways to load data in a batch from Salesforce to a data warehouse. The first involves developing and managing your custom scripts to invoke the Salesforce REST API. The second involves leveraging a third-party tool, like Stitch or Fivetran Salesforce integration.
For this example, we'll leverage Stitch, a commonly used third-party ETL tool.
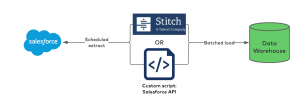
The Salesforce REST API provides programmatic access to the underlying objects, such as the database tables that contain your organization’s information. For example, the central objects such as Opportunity and Account in the Salesforce data model represent the accounts and opportunities of organizations involved with your business.
Multiple field-facing and cross-functional internal teams in the organization leverage the Salesforce CRM application. Every operation on the application could trigger a change event. For example, updating a customer’s status, adding new customer contact information, updating the opportunity value estimate, adding a new opportunity, importing new leads, etc.
Thus Salesforce objects often have a high volume of changes. A full reload integration operation might use a high amount of Salesforce server resources, which could result in degraded performance for other concurrent operations. This can be avoided by incremental processing that involves working with just the data that changed and only updating or retrieving the changed data. Let’s look at the interlinked data integrity and latency issues with a batch process:
- Data integrity: Frequent data changes require frequent API requests to Salesforce to keep the data warehouse up to date. Salesforce API limitations restrict the number of calls in a given period of time to prevent overloading their servers. Soft deletes (an isDeleted field is marked as “True”) can be tracked using this API since the record is not actually deleted. However, hard deletions, where a record is completely removed, cannot be handled in this way. Full replication is needed to ensure that hard-deleted records are correctly propagated to the data warehouse.
- Data latency: Stitch takes about 25 minutes to load changes across ~80 objects, which means that our tighest polling loop is roughly 30 minutes. Keep in mind that this is subject to change depending on how many objects have changed since the last iteration. A full replication from SFDC using Stitch for eight objects (ex: Opportunity, Lead, User, etc.) takes about 7.5 hours to load ~10GB of data (~5 million records). In both cases, you must contend with latency
Due to the high latency and an inability to make it faster, reports generated from the data warehouse are stale to some degree. In many cases, high latency causes business and analytic users to wait for the next day to extract reports for the previous day, just so they can be sure they have captured all of the necessary data.
Our new streaming data pipeline architecture
To provide a real-time data foundation for our data warehouse, we chose to utilize a fully managed Salesforce CDC Source connector on Confluent Cloud. This connector is a highly scalable data capture solution that provides an event stream of records with at-least-once delivery semantics.
This new architecture relieves the biggest pain points of the batch system, enabling us to generate analytical reports on up-to-date and accurate data.
The captured stream of records can be leveraged by multiple teams in your organization. For example, a billing microservice can ingest account information and sales figures to produce billing results, while another microservice can assign sales follow-ups based on opportunity updates. This pattern creates a single source of truth of SFDC data for consumer use, while simultaneously reducing the amount of API calls made to SFDC.
Real-time table snapshot in BigQuery
The next step is to create a table snapshot in BigQuery. The BigQuery sink connector can read data from the necessary Kafka topics to a destination dataset. This lets us maintain a snapshot of Salesforce data in BigQuery, so our analytical data is consistent with the Salesforce system.
To understand how to reconstruct and maintain a consistent table snapshot in BigQuery, let’s first review the Salesforce Change Data Event. First, we look at a new Opportunity in Salesforce with a stage name “Procurement”. changeType is an enumeration of CREATE, UPDATE, DELETE, UNDELETE, and other Gap change types, prefixed with GAP_ (GAP events will be discussed in a later section).
The CREATE event is special, as it contains many fields all at once (Note in Figure 3 that changedFields is empty because this is a “CREATE” event, and nothing has yet changed).
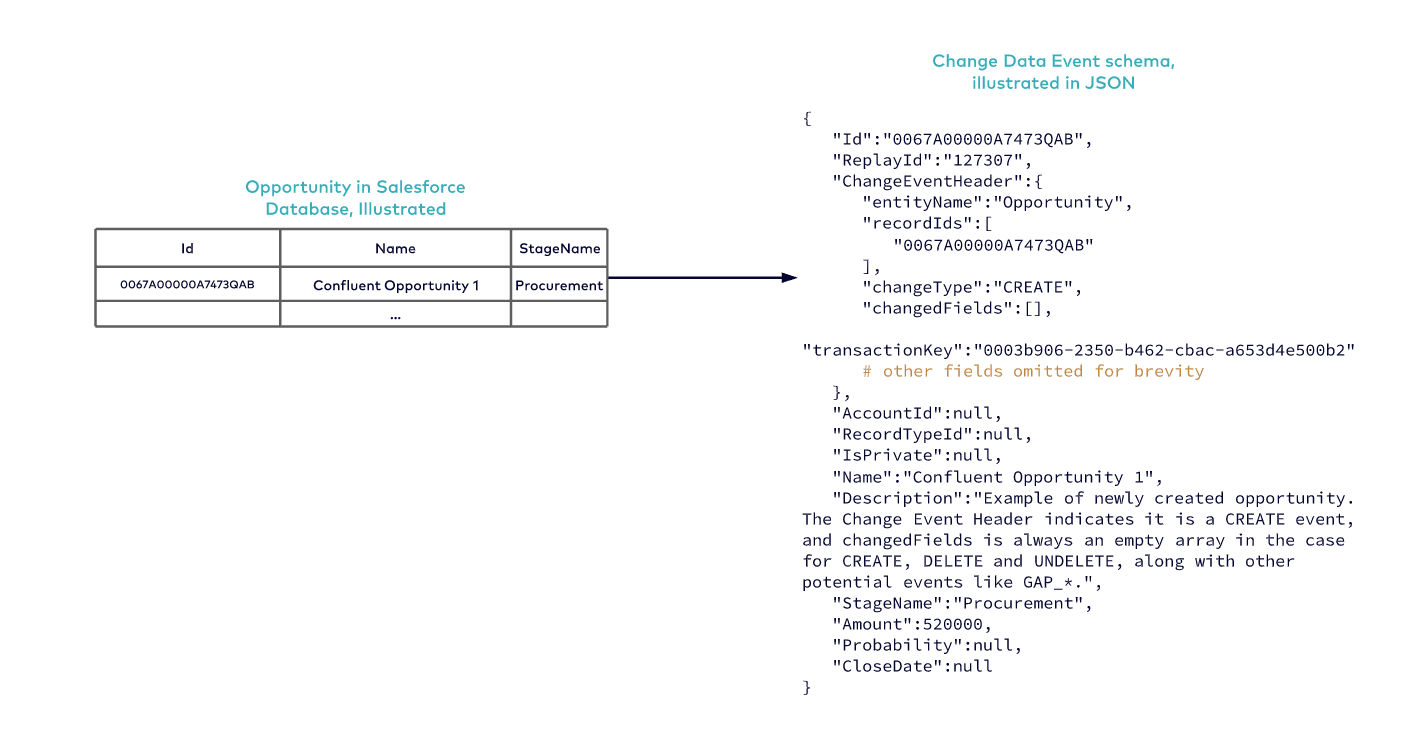
Figure 3: Change Data Event for the newly created Opportunity
Now, we proceed to update the Opportunity by changing the StageName from “Procurement” to “Closed – Won”. Figure 4 highlights the contents of the “UPDATE” event.
Note that the changedFields includes “StageName”, while the other fields such as Amount, Description, and Name are set to null.
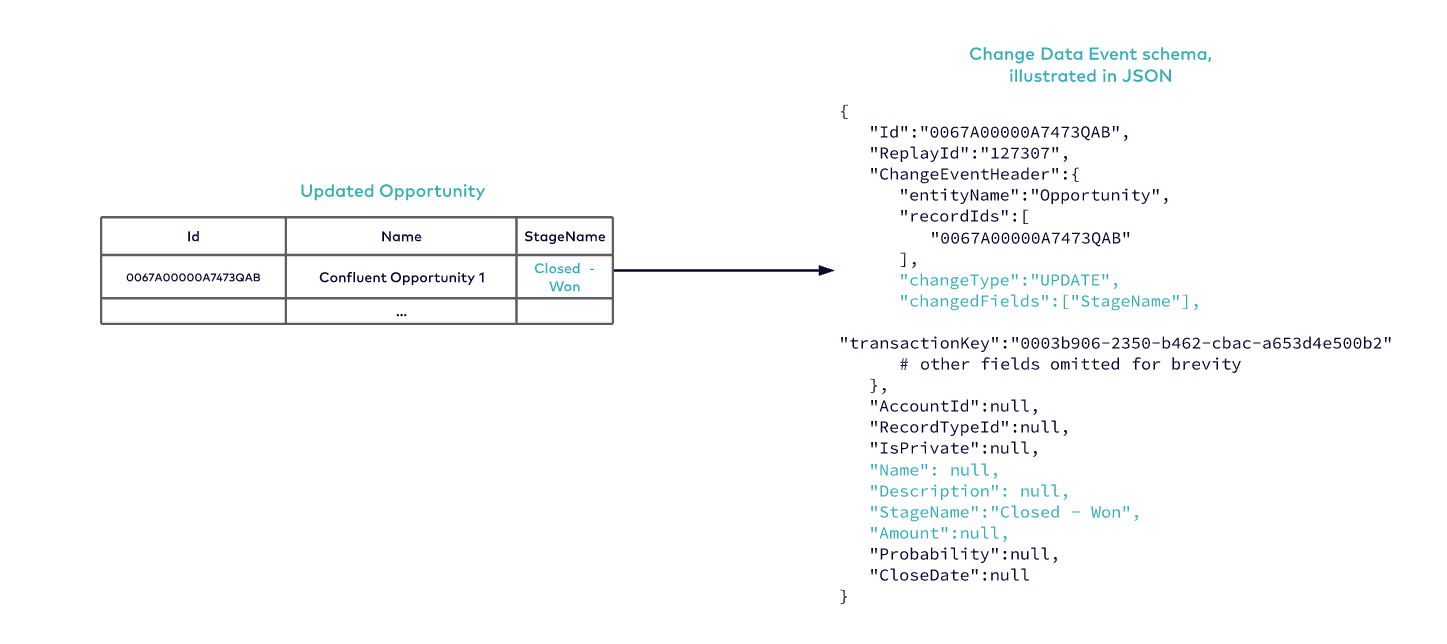
Figure 4: Change Data Event for the Closed Opportunity
The challenge we now face is reconstructing the database view in real time, based on these change events.
Note that:
- A field can be updated to null
- Each Change Data Event could contain one or more records that have been updated; each event maps to one database transaction
- Field changedFields is an empty array when it is CREATE, DELETE, UNDELETE, and GAP events (we’ll review GAP events shortly)
We can reconstruct the state by referring to the changedFields of each record and UPSERTing only those changed values into the state store.
Our reconstruction decision
There are two main options for reconstructing the state:
- Option 1: Write first, reconstruct second
Write the raw CDC stream into a BigQuery dataset, and then apply the transformations, e.g., batched scripts or leveraging BigQuery’s powerful engine to perform processing at query time using BigQuery views, to reconstruct complete records. - Option 2: Reconstruct first, write second
We can use stream processing (such as Kafka Streams) to reconstruct the records first, writing the updates to BigQuery as they become available. We would, however, need to leverage an intermediate state store to keep the record state while resolving change events.
We decided to go with option 1 and leverage BigQuery views because we have already selected BigQuery and SQL for downstream reporting use cases. There is a trade-off between idempotency versus query performance.
As most of our transformations happen at query time in BigQuery, you may suffer from slow query performance, depending on the data size, complexity of view query logic, etc. If your use cases require high-performance queries, it would be best to consider option 2 instead.
Our real-time Salesforce streaming data pipeline architecture is illustrated in Figure 5. Using Salesforce CDC Source connectors, change events for objects (e.g., Opportunity and User) stream into raw topics, noted as sfdc.cdc.<object>_raw.
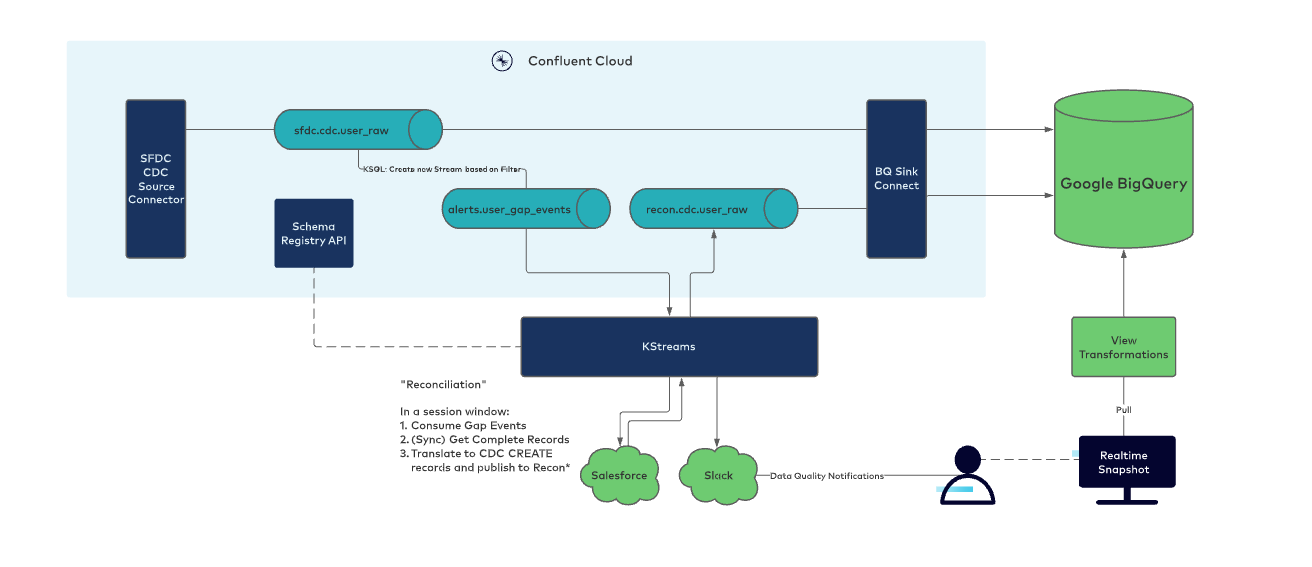
Figure 5: Real-time streaming data pipeline architecture using Salesforce CDC
Walk the talk
Now let’s look into some of the details of the components we need to deploy on Confluent Cloud, starting with the SFDC CDC Source connector.
The Salesforce Source CDC connector requires one connector instance for each Salesforce object definition. To deploy a connector, follow these four steps:
- Set up Confluent Cloud (ccloud)
- Set an API key
- Create the configuration file
- Deploy the connector
Set up ccloud
The easiest way is through the CLI, though you can also do this through the UI.
$ confluent login --save $ confluent environment use <env-id> $ confluent kafka cluster use <cluster-id>
Set an API key
You’ll need an API key. You can use an existing key with the necessary permissions, or you can opt to use a new key.
# Create a new API key $ confluent api-key create --resource<env-id> --service-account <cluster-id
Alternatively, use an existing key
$ confluent api-key use <API-Key> --resource <cluster-id>
Create the configuration file
Deploy the connector
A sample configuration for sourcing Opportunity Salesforce data looks something like the following:
{
"connector.class": "SalesforceCdcSource",
"name": "SFDCSourceConnectOpportunity",
"kafka.api.key": "<API-Key>",
"kafka.api.secret": "<API-Secret",
"kafka.topic": "sfdc.cdc.opportunity_raw",
"salesforce.instance": "https://login.salesforce.com",
"salesforce.username": "<Username>",
"salesforce.password": "<Password>",
"salesforce.password.token": "<Security-Token>",
"salesforce.consumer.key": "<Consumer-Key>",
"salesforce.consumer.secret": "<Consumer-Secret>",
"salesforce.cdc.name": "OpportunityChangeEvent",
"salesforce.initial.start": "latest",
"output.data.format": "AVRO",
"tasks.max": "1",
"connection.max.message.size": "52428800"
}
Some configs we found very useful to set include init.start=all, which polls the last three days of change events from SFDC when the connector initially starts. This is helpful in cases where you need to restart the connector and want to avoid any data loss. We also adjusted connection.max.message.size to a larger value (Salesforce CDC source connector documentation), as this helps with bandwidth utilization when polling large quantities of change events. Here, 52428800(50 MB) works well for our data volume.
$ confluent connect create --config PATH-TO-CONFIG-FILE # Check Connector Status via CLI, $ confluent connect list
BigQuery Sink connector
We used the BigQuery Sink connector to sink the Salesforce data, append-only, into a table per topic. We used AVRO schema with auto schema updates for the BigQuery sink, which automatically keeps the BigQuery tables updated with the latest schema even as new fields get added to the SFDC objects.
One particular config we had to use in this setup was the Allow Schema Unionization. We ran a scenario where sometimes the schema of the topic and BigQuery table had a mismatch.
In that case, this option results in a union of the two schemas and updates BigQuery accordingly, preventing the writes to BigQuery from failing. This is primarily used in cases where a column may have been deleted from the source data, as BigQuery doesn’t allow columns to be dropped from tables, nor does it allow column types to be modified.
Sample config
{
"name": "SFDCBigQuerySinkConnector",
"config": {
"topics": "sfdc.cdc.user_raw, sfdc.cdc.opportunity_raw, sfdc.cdc.account_raw, alerts.sfdc.user_gap_events, ….",
"input.data.format": "AVRO",
"connector.class": "BigQuerySink",
"name": "SFDCBigQuerySinkConnector",
"project": "GCP_PROJECT_ID",
"datasets": "GCP_DATASET_ID",
"auto.create.tables": "true",
"auto.update.schemas": "true",
"sanitize.topics": "true",
"sanitize.field.names": "false",
"allow.schema.unionization": "true",
"tasks.max": "6"
}
}
Gap events handling
In addition to the happy path, Salesforce may send a Gap event instead of a change event to inform subscribers about internal system errors, or if it’s not possible to generate a change event. Gap events contain the record IDs of any impacted records, but they do not contain the current values of the records themselves. These events require a dedicated path for reconciliation by calling the SFDC API. A failure to do so can result in the BigQuery dataset deviating indefinitely from the source in SFDC.
The general approach
This section describes a general approach to Gap event handling, applicable to readers who have different setups and/or use cases than real-time snapshots in a data warehouse.
- On receiving a Gap event, first mark the corresponding impacted record(s) as dirty, e.g., using the record ID.
- If you receive newer change events for the same record, don’t process them—either save it for later processing or pause your current process, if applicable.
- Reconcile the data for the record (See the next section on event-driven reconciliation).
- Remove the dirty flag after reconciliation.
- Accept new change events for the record again.
Our solution: Event-driven reconciliation
We opted to use Confluent solutions, e.g., ksqlDB and Kafka Streams application, for event-driven Gap events identification and reconciliation. The idea is to filter the Change event, if it is a Gap event, a dedicated Kafka Streams application will issue an API call to Salesforce to retrieve the complete record. The stream process then emits a stream of complete records—“reconciliation stream,” which will then be combined into the same BigQuery dataset to form a complete snapshot.
A plain synchronous API call (singular) is a good place to start because it blocks the messages within the same process. Alternatively, if API limits and/or any client/server-side error is a concern, we can build more features such as complex retry backoff logic, rate limiters, and/or micro batching for records that come in during the same window. In our implementation, we decided to go with micro batching plus alerts on failures, based on our internal Salesforce API usage.
And finally, we delegate the effort of managing the dirty flag in the BigQuery views, as we are reconstructing records there.
Step one: Filter out Gap events on ksqlDB
We used ksqlDB to first filter Gap events and direct that traffic to a dedicated Kafka topic: alerts.sfdc<object>_gap_events.
CREATE STREAM STREAM_SFDC_CDC_OPPORTUNITY_GAP_EVENT WITH (KAFKA_TOPIC='alerts.sfdc.opportunity_pipeline_gap_events',
PARTITIONS=6,
REPLICAS=3,
VALUE_FORMAT='AVRO',
VALUE_AVRO_SCHEMA_FULL_NAME=’YOUR_SCHEMA_NAME’) -- we recommend always setting the schema name explicitly
AS SELECT
STREAM_SFDC_CDC_OPPORTUNITY_PIPELINE_RAW.REPLAYID REPLAYID,
STREAM_SFDC_CDC_OPPORTUNITY_PIPELINE_RAW.CHANGEEVENTHEADER CHANGEEVENTHEADER
FROM STREAM_SFDC_CDC_OPPORTUNITY_PIPELINE_RAW STREAM_SFDC_CDC_OPPORTUNITY_PIPELINE_RAW
WHERE (UCASE(STREAM_SFDC_CDC_OPPORTUNITY_PIPELINE_RAW.CHANGEEVENTHEADER->CHANGETYPE) LIKE 'GAP%')
EMIT CHANGES;
Step two: Kafka Streams topology for reconciliation
Next, we need to process the Gap events by making a call to the SFDC API. A Kafka Streams Java application is a good fit here, as it can easily consume the event stream and make calls to the REST API on a per-event basis. We invoke the Salesforce API for a window of records to fetch the latest state for them. Below is an example of how we utilize `KeyValueMapper` to reconcile records in a windowed stream `KStream<Windowed, AVROSCHEMA>`:
/**
* Java code snippet: how to apply keyValueMapper to the windowed stream - see next snippet for definition of the keyValueMapper.
*/
// Grouping logic omitted, choose based on your use case. KStream<Windowed, AVROSCHEMA> windowedStream;
windowedStream .flatMap(this.keyValueMapper, Named.as("reconcile_via_api_call")) .filter((k, v) -> v != null) .to(destinationTopic, Produced.with(Serdes.String(), specificAvroValueSerde));
/**
- Java code snippet, lambda expression of key value mapper to construct reconciled records based on Salesforce response.
*/ this.keyValueMapper = (key, value) -> { try { return getSfdcClient().reconcileRecords(value, AccountChangeEvent.class) .stream() .map(returnValue -> new KeyValue<>(returnValue.getId(), returnValue)) .collect(Collectors.toList()); } catch (Exception e) { String errorMessage = String.format("[RECON-FAILED] Failed to reconcile [%s] %s ", getEntity(), // entity is Salesforce objects, e.g. Account, in this case. value.getCHANGEEVENTHEADER().getRECORDIDS()); // logging and alert omitted } return Collections.singletonList(new KeyValue<String, AccountChangeEvent>(null, null)); };
/**
- Java code snippet, sample HTTP client code to perform a Salesforce SOQL query for the reconciliation.
- Example requestQuery = "SELECT FIELDS(ALL) FROM ACCOUNT WHERE Id IN …. ";
*/
final URIBuilder builder = new URIBuilder(instanceUrl); builder.setPath("/services/data/v52.0/query/").setParameter("q", requestQuery); HttpGet get = new HttpGet(builder.build()); get.setHeader("Authorization", "Bearer " + accessToken); try (CloseableHttpResponse httpResponse = httpClient.execute(get)) { JsonNode result; try { result = MAPPER.readValue(httpResponse.getEntity().getContent(), JsonNode.class); } catch (Exception parseError) { LOG.error("Failed to parse response for groupedRecords {}", requestQuery, parseError); throw parseError; } return result; } catch (Exception httpError) { LOG.error("Failed to get Http Response for request {}", requestQuery, httpError); }
Step three: Restruct in BigQuery
In BigQuery, we will combine the reconciliation stream emitted by step two, with raw CDC data, to form a complete snapshot. The query view logics are omitted as they vary from each use case; follow your reconstruction choice.
Building Your Streaming SFDC and ETL Pipelines
In this post, we introduced a reference architecture with technical details that can help you get a quick start to building streaming data pipelines to your data warehouse for analytics related to Salesforce data. While this post focuses on the problem of landing data in real-time, we did not dive too deep into the intricacies of using this data after landing, as most of that computation happens in BigQuery.
Our next initiative entails building upon the current reconstruction design and exploring how the query latency would compare when keeping the compute in BigQuery versus going up the stack and leveraging ksqlDB more.
To build your own streaming data pipelines using fully managed connectors, try Confluent Cloud for free and receive $400 credits at sign-up.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...