Data Streaming in Healthcare: Achieving the Single Patient View
Healthcare providers have long known the benefits of a single patient view (SPV). A clinician’s ability to securely access and act on patient data which spans disparate medical disciplines, departments, and locations is key to the effective provision of healthcare. It helps to improve patient outcomes by providing medical professionals with a complete, accurate view of a patient’s health, and reduces the time and resources required to manage patient information. This leads to a more cost-effective service which empowers clinicians to deliver better results for their patients.
The reason that many healthcare organizations are unable to provide an effective SPV, however, is because their current data infrastructures prevent it. Reliant on legacy messaging technologies and batch processes, their infrastructures represent complex webs of stale, siloed datastores. Ultimately, this means that an up-to-date, holistic record of a patient’s healthcare is difficult to obtain.
In this blog, we’ll explore some of the technical challenges in creating an SPV, before explaining how they can be addressed with a data streaming platform. As part of this, we’ll take a look at a case study in which a healthcare organization created an SPV in order to power a real-time experimental treatment-matching service for cancer patients.
Creating a single patient view – the challenges
Interoperability
The IT infrastructure of many healthcare organizations is based on a patchwork of individual systems. When a patient is admitted to a healthcare facility, it’s not uncommon for their treatment to be charted across multiple systems of record. In order for data to flow across these systems, however, they must be interoperable; they must share data in a standardized format, such as Fast Healthcare Interoperability Resources (FHIR). Many healthcare systems (especially legacy ones) don’t generate data in this standardized format – their messages need to be transformed. This creates the need for an integration technology that’s either able to transform messages via stream processing or able to connect with a separate FHIR transformer.
Regulatory compliance
The creation of an SPV requires the integration of complex, highly sensitive data across a potentially huge estate. This can increase the risk of noncompliance with regulatory standards such as HIPAA, which are designed to protect the privacy and security of individuals’ medical information. Technologies integrating healthcare data must implement stringent access controls, ensure the encryption of personal healthcare information (PHI), and maintain data integrity across on-premises and private cloud environments.
Scalability, observability, and disaster recovery
“Healthcare systems” generate vast quantities of data, but often at unpredictable throughputs. Data integration pipelines need to be able to scale elastically in order to meet this variable demand. If the pipeline fails, moreover, data engineering teams need to be able to quickly identify the issue; observability over an organization's operational and analytical estates is therefore critical for engineering teams. To ensure that key services remain online, integration pipelines must also have disaster recovery mechanisms (e.g., cluster linking) in place.
Patient-focused outcomes
Patients are the core of healthcare. All other considerations are secondary. It’s imperative that patients and clinicians have access to timely, accurate, and useful information. Patients and providers need access to test results, medication approvals, and timely advice. Patient portals need to reflect the most recent findings, prescriptions, and doctor notes. Timely results for infectious disease testing can mean the difference between beginning effective treatment as quickly as possible and preventing community spread.
The solution – a data streaming platform for healthcare
Responding to these challenges, many organizations have chosen to build an SPV based on data streaming. This is a method of continuously processing data as it is generated and making it available for downstream applications.
Transform Your Data Pipelines, Transform Your Business →
Apache Kafka® is the de facto technology for data streaming and is used by over 70% of Fortune 500 companies. It’s particularly well-suited for data integration as it decouples data producers from consumers, removing single points of failure. It can also handle large volumes of complex data from multiple source systems, and easily connect with a wide range of technologies across the healthcare datasphere.
Confluent, based on Apache Kafka and powered by the Kora engine, is the HIPAA-ready enterprise data streaming platform. It’s used by healthcare organizations to stream, process, and govern sensitive patient data in a secure, compliant way, powering a number of critical use cases.
Let’s take a look at how one company used Confluent to create an SPV as the foundation of a real-time clinical trial matching service.
Matching patients to new treatments
Patients in a given location with certain medical histories may be eligible for customized treatments. Oncology practices offer their patients the chance to take part in trials of new cancer therapies. There’s often a gap, however, between these practices and the research labs delivering new treatments. This gap is caused by patient information not flowing between entities. In order for labs to identify potential candidates for clinical trials, they need access to actionable patient data.
Data Streaming in Real Life: Healthcare →
The organization we work with is aiming to bridge this divide with a solution that securely processes patient medical records, and alerts oncology practices to eligible patients based on very specific biomarker requirements. This solution allows oncology practices to widen accessibility to innovative new cancer therapies while helping research labs increase their efficiency in identifying candidates.
Apache Kafka was a natural fit for the underlying data infrastructure of this solution.
As a self-managed solution, however, the team was running into challenges. Various components of the pipeline needed to be patched, upgraded, and maintained independently, taking a significant amount of data engineering time. Infrastructure and data was duplicated as the system wasn’t designed for multi-tenancy. Scaling the pipeline to handle variable throughput was also difficult—they had to resort to artificially throttling data before it reached a customized transformation pipeline. Added to this was that the solution lacked observability; when there was a failure, they had to check each component within the system.
Time spent administering infrastructure is time that can be spent improving patient outcomes. Software failures shouldn’t take valuable time away from teams that are building next-generation treatments. Oncology experts shouldn’t also have to take time to patch, upgrade, and scale.
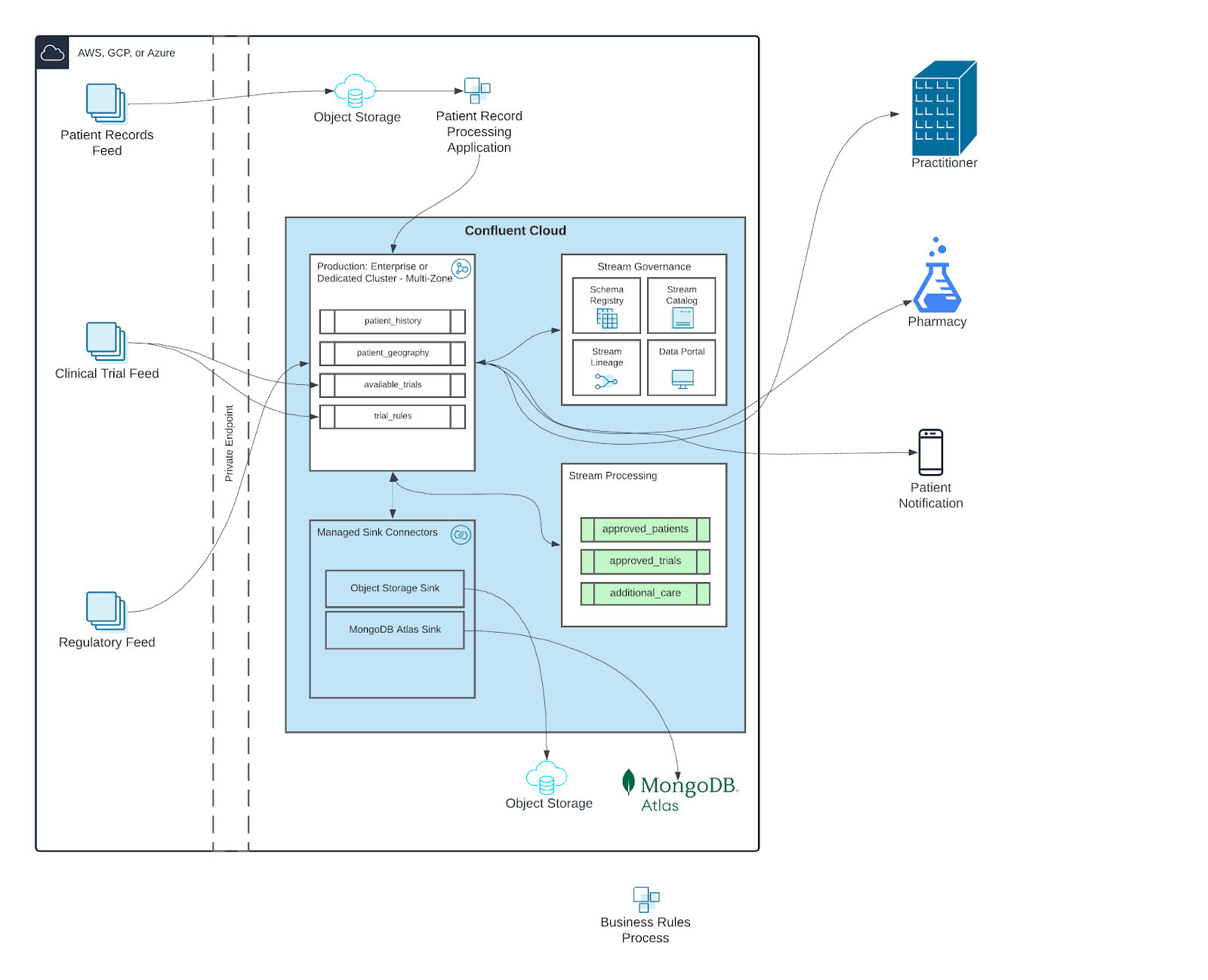
It’s for these reasons why this organization came to Confluent, looking for a fully managed, serverless data streaming platform. Here’s a high-level overview of the solution.
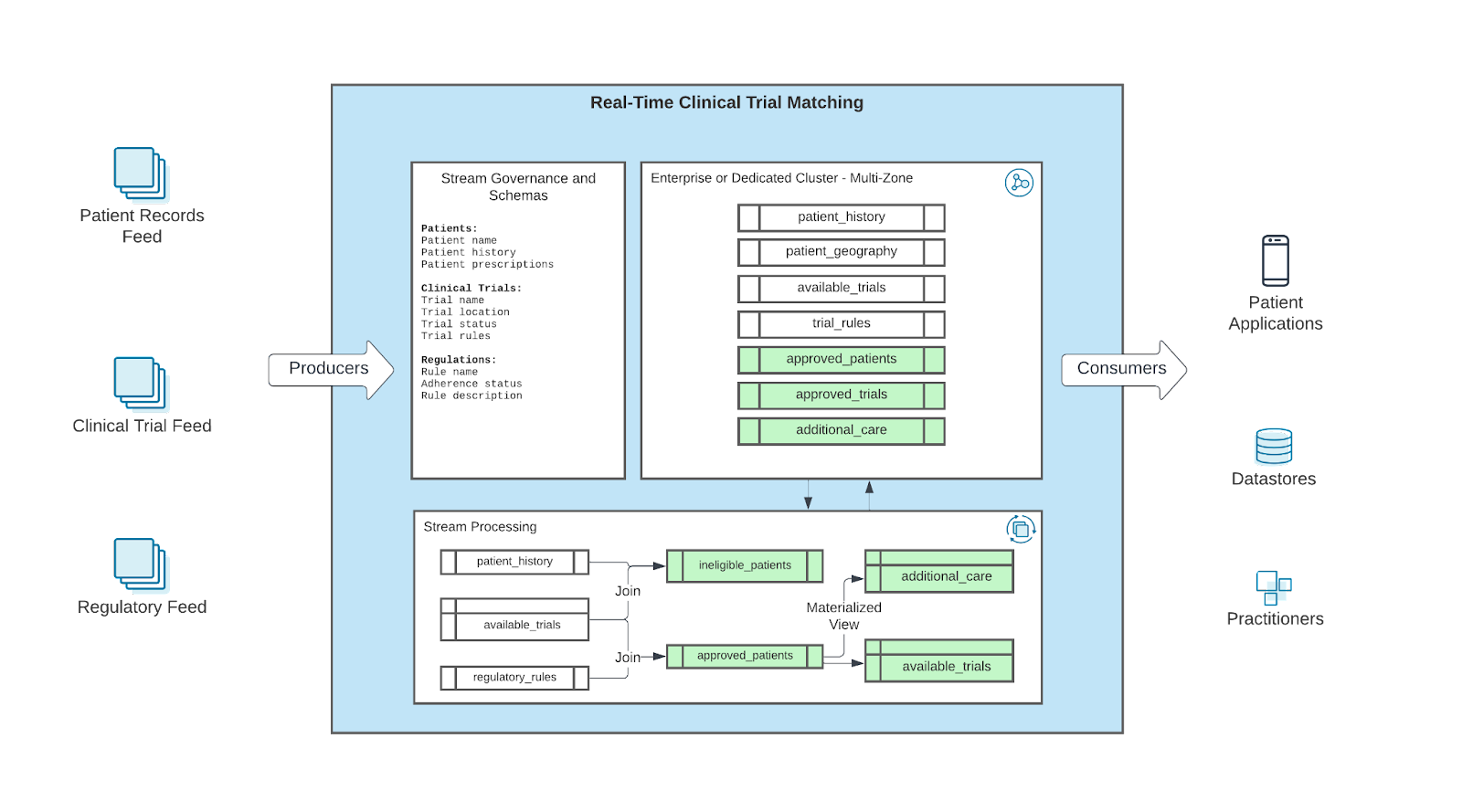
In this scenario, bundled EMR files are received via clinical care feeds containing encrypted payloads. These files are stored in object storage before an ingest process retrieves, decrypts, and decompresses the bundled data (i.e., a “coat check architecture”). This data is then sent to Confluent Cloud, where it is processed with data from clinical trial and regulatory feeds via Apache Flink. Consuming applications subscribe to processed topics (i.e., “approved_patients”), triggering notifications to oncology practices and/or eligible patients. Data is also synced to MongoDB Atlas via a fully managed connector for historical analysis.
Benefits
Less intervention, more flexibility – The organization’s previous solution required significant resources to maintain. Time was spent on manually provisioning clusters as well as upgrading and patching individual components across the pipeline. Now, with a fully managed data streaming platform, the data team is free to innovate. Confluent Cloud scales elastically to 100MBps and beyond, responding to demand automatically while providing full visibility over the health of the pipeline with Stream Governance Advanced.
HIPAA-ready – Confluent is certified according to the HITRUST Common Security Framework (CSF) and is used in HIPAA environments. This reassured the organization that they could fully comply with regulatory requirements while harnessing the benefits of a fully managed, serverless data streaming platform.
Simplified architecture – With this architecture, the organization can replace custom transformations with stream processing via Apache Flink on Confluent Cloud. This avoids the need for complex custom transformations and gives applications the benefit of native observability and alerting.
Streaming a single patient view
Effective healthcare is dependent on the timely sharing of high-quality information between different entities. Confluent’s data streaming platform enables healthcare organizations to stream, process, and govern sensitive medical information securely and at scale in order to build an SPV and improve healthcare outcomes.
If you’d like to learn more about how data streaming can be harnessed by healthcare, check out the following resources:
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.


{kind=link}
{kind=link}

Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.