Improved Robustness and Usability of Exactly-Once Semantics in Apache Kafka
This blog post talks about the recent improvements on exactly-once semantics (EOS) to make it simpler to use and more resilient. EOS was first released in Apache Kafka® 0.11 and experienced enormous adoption; however, due to its complex nature, various production use cases within the community have shown operational and development challenges. The Kafka 2.5 release delivered two important EOS improvements, specifically, KIP-360 and KIP-447.
Background
EOS is a framework that allows stream processing applications such as Kafka Streams to process data through Kafka without loss or duplication. This ensures that computed results are always accurate. This blog post primarily focuses on the resiliency related to the transactional guarantee between producers and brokers, instead of every detail of EOS. For the full background on the architecture and semantics of EOS, see the blog post Transactions in Apache Kafka or the comprehensive design KIP, which dives deep into the EOS framework step by step.
Enhanced error handling
When using EOS, the producer and broker both have logic to determine whether it is safe for a producer to continue to send data without violating the exactly-once guarantees. Prior to Kafka 2.5, if either the producer or broker was ever not able to make this determination, the producer would enter a fatal error state. The only way to continue processing was to close the producer and create a new one. This process is generally very disruptive to client applications. For example, if a producer fails in Kafka Streams, then the associated task needs to be migrated, which causes a rebalance of the full workload. This results in throughput drop until the rebalance is complete.
To address this issue, KIP-360 added a mechanism for producers to automatically recover when they encounter these cases and continue processing. To better understand how it works, the following describes some of the situations that can cause fatal errors.
Each producer is configured with a transactional ID, which is a descriptive string provided by the user that uniquely identifies the producer instance across process restarts. For each transactional ID, there can be only one active producer at a time. Any other producers attempting to produce using the same transactional ID need to be fenced to block writes. The transactional ID therefore provides a single-writer guarantee.
To understand why this is important, imagine that an application creates a producer and begins producing messages in a transaction. For some reason, the application determines that the producer has failed, so it creates a new one, which restarts the transaction and begins producing from the start. If the first producer is still sending messages and the broker accepts them, the transaction will now contain duplicate records, which violates the exactly-once guarantees.
The restriction of one active producer per transactional ID is enforced by the transaction coordinator, which is a module running inside every Kafka broker that maintains the state for each transaction. In order to identify the active producer for each transactional ID, the transaction coordinator tracks two values that are associated with that ID: a producer ID and a producer epoch.
The producer ID is generated by the broker and returned to the producer when the producer calls InitProducerId to initialize its state on the broker before beginning to produce. The producer ID is an integral value, which is efficient to store in individual records (as opposed to the transactional ID, which is a descriptive string provided by the user and can be verbose). Only one producer ID at a time is allowed for any given transactional ID: If a producer calls InitProducerId with a transactional ID that has already been initialized on the broker, the existing producer ID will be returned.
The producer epoch is associated with the producer ID and is incremented every time a new producer instance is initialized. The broker only allows a producer with a recognized producer ID and the current epoch for that producer ID to write or commit data. A producer that tries to use an older epoch will receive an error indicating that it has been fenced, at which point it needs to be closed.
Fencing is possible because each record in the log contains the ID and epoch of the producer that produced it. When the broker starts, it reads each partition log and materializes a cache mapping each producer ID to that ID’s current epoch. When processing a produce request, the cache is used to validate that the request’s producer ID is present in the cache and that the request’s producer epoch is equal to or greater than the epoch in the cache. If this is not the case, the producer is fenced. Prior to Kafka 2.5, the broker removed each producer ID from the cache once no more records from the producer ID were present in the log. This could happen if an application produces infrequently enough that the retention time for all its records passes in between transactions, for example.
Once this happens, the broker responds to all producer operations with an UNKNOWN_PRODUCER_ID error, and the producer enters a fatal error state. Because the InitProducerId API can only be called once at the start of a producer’s lifetime, the only way to continue is to create a new producer and initialize a new producer ID.
Another fatal error occurs when the producer cannot assign sequence numbers to the records that it produces. In order to maintain the correct order, records produced by an idempotent or transactional producer each have a sequence number, and the broker only accepts writes in sequential order, with no gaps or out-of-order records allowed. In order to assign the correct sequence number, the producer needs to know which requests have been successfully written to the log, which requires a successful response from the broker.
If a produce request fails with a retriable error, the producer will retry it until it either succeeds or hits the configured delivery timeout (delivery.timeout.ms), at which point the records are expired by the producer. If the records expire, the producer can’t be sure if the records were written or not. When this happens, the producer can’t continue because it doesn’t know what sequence number to assign to the next record. Like the UNKNOWN_PRODUCER_ID, the only way to recover prior to Kafka 2.5 is to create a new producer.
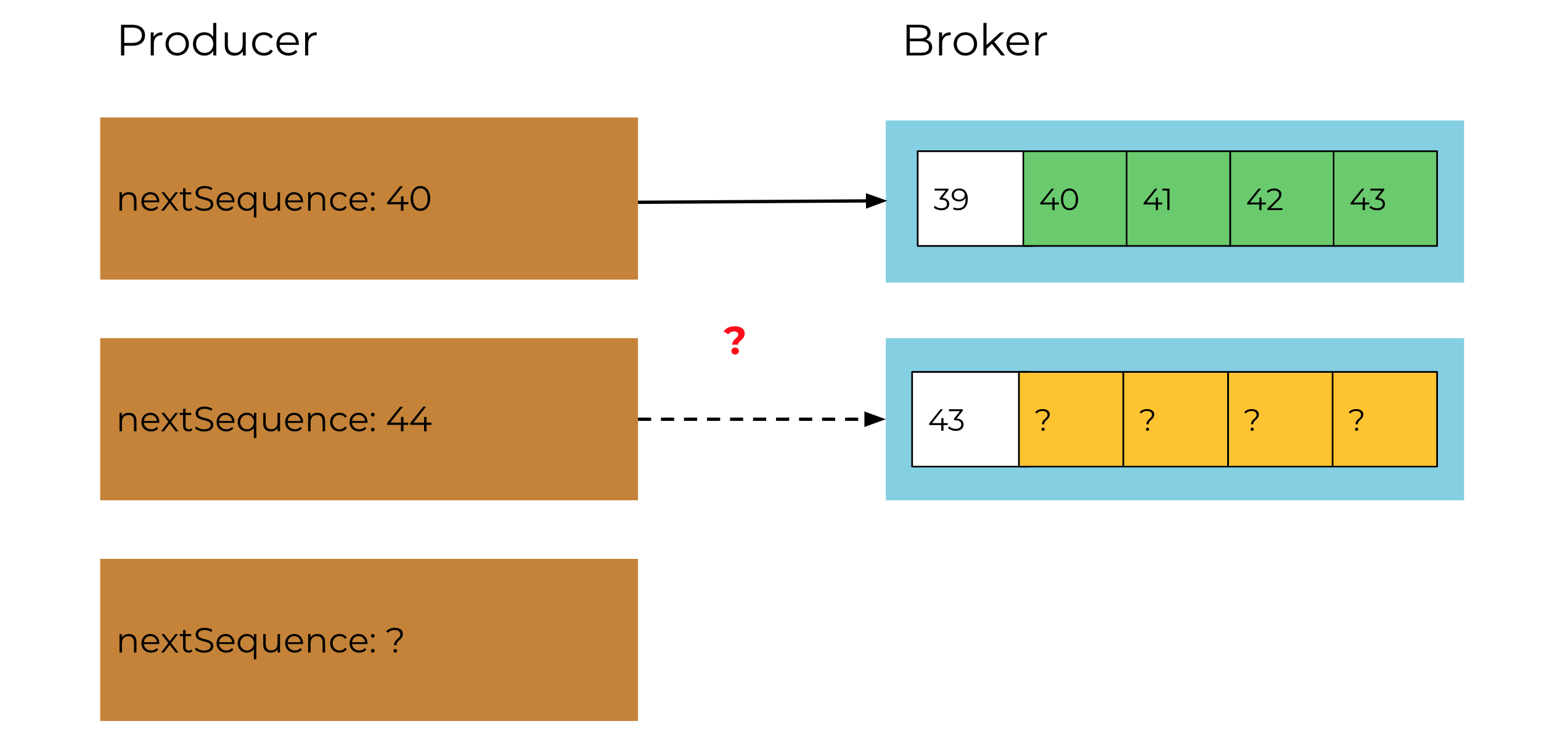 On a successful exactly-once produce call, records are written into the log in sequential order. This sequence is tracked by both the producer and the broker. If a record batch repeatedly fails until it is expired by the producer, the producer can’t be certain that records were written to the log. This means that the producer doesn’t know what sequence number to assign to the next record, and the producer cannot continue processing.
On a successful exactly-once produce call, records are written into the log in sequential order. This sequence is tracked by both the producer and the broker. If a record batch repeatedly fails until it is expired by the producer, the producer can’t be certain that records were written to the log. This means that the producer doesn’t know what sequence number to assign to the next record, and the producer cannot continue processing.
KIP-360 solves these problems by providing a way to re-initialize a producer ID without having to create a new producer. In addition to the producer’s transactional ID, InitProducerId now optionally takes a producer ID and producer epoch as well. When these are present in the request, the broker compares them to the existing producer ID and epoch for that transactional ID. If they match, then no other producer has been initialized for that transactional ID, and it is safe for the producer to continue processing. The broker will increment the producer epoch and return it to the producer. When the epoch is bumped, the sequence number is also reset to zero, allowing the producer to continue through both unknown producer and out of sequence errors.
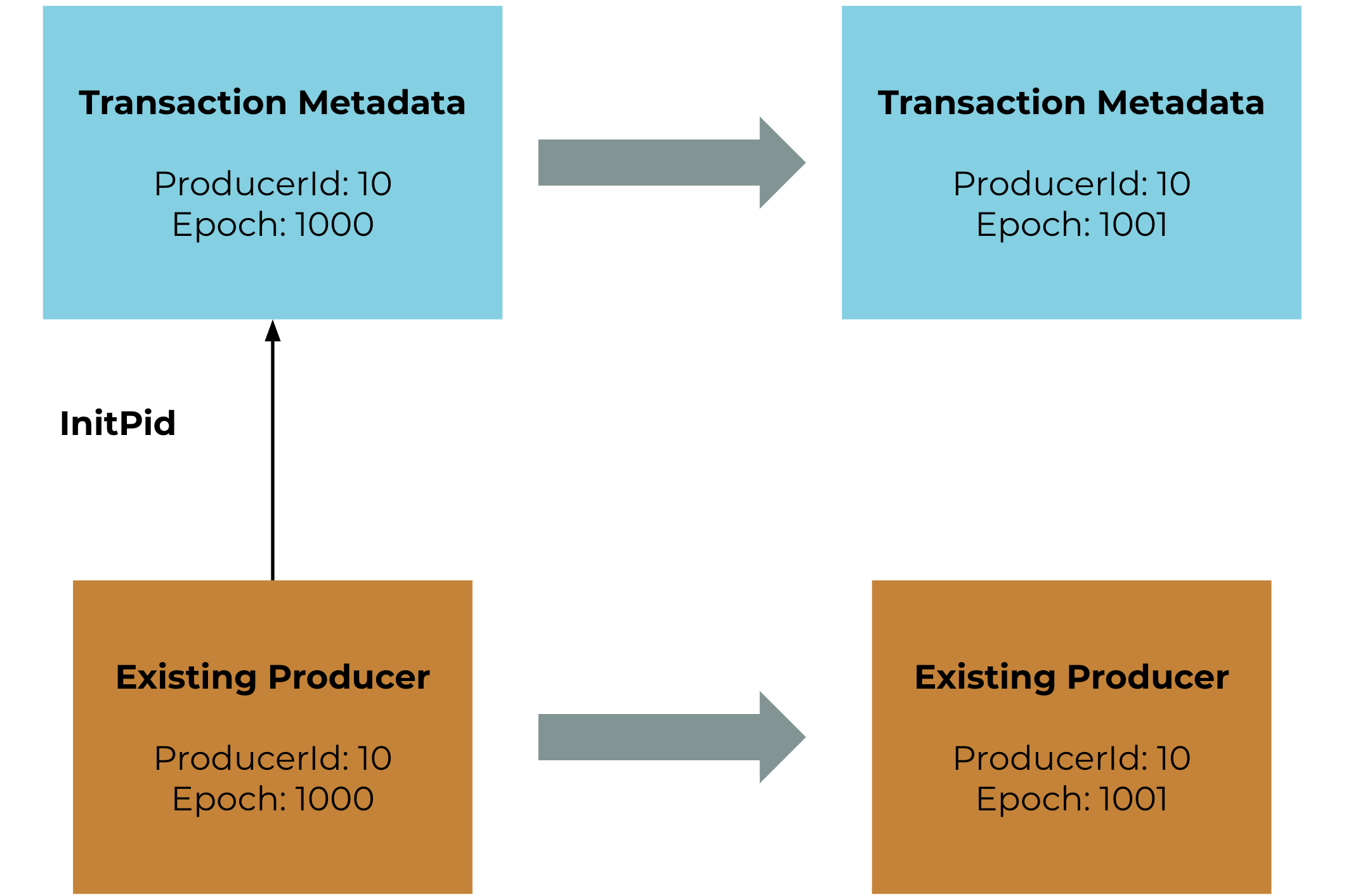 If the existing producer’s ID and epoch match the transaction metadata, the transaction coordinator bumps the epoch and the producer continues processing.
If the existing producer’s ID and epoch match the transaction metadata, the transaction coordinator bumps the epoch and the producer continues processing.
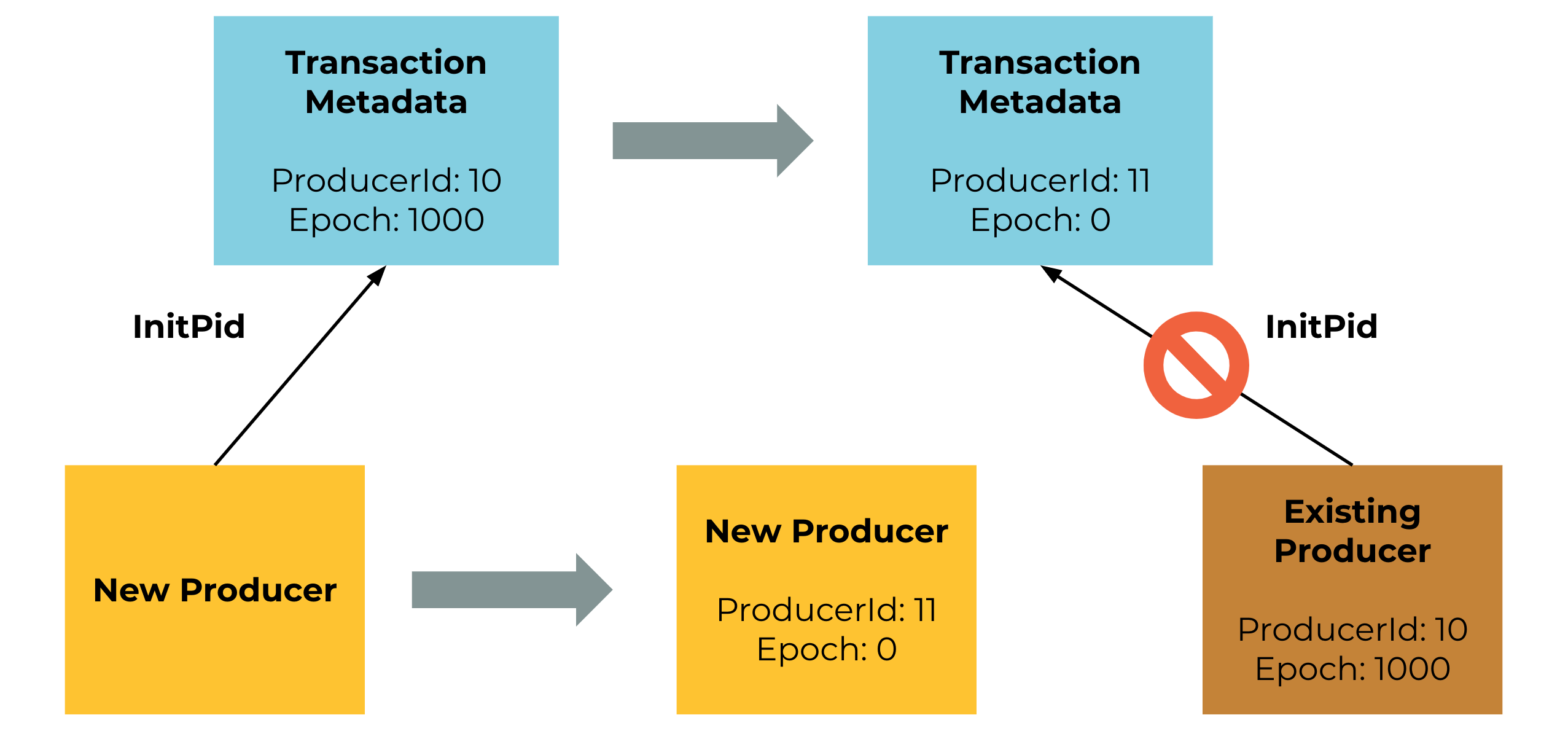 On the other hand, if a new producer has been initialized before the existing producer can re-initialize, the existing one will be fenced.
On the other hand, if a new producer has been initialized before the existing producer can re-initialize, the existing one will be fenced.
With a safe way to bump its epoch, the producer can now recover from a number of previously fatal errors. When the producer encounters one of these errors, and the broker supports the new InitProducerId version, it will transition to an abortable error state, rather than a fatal one. When the application aborts the transaction, the producer will internally call InitProducerId after aborting, which bumps the epoch and allows it to continue. Because this epoch bump happens transparently as part of the call to KafkaProducer#abortTransaction, existing applications can benefit from this new error handling as soon as both brokers and clients are upgraded to Kafka 2.5.
Client API simplification
In the Kafka 0.11 world, Confluent introduced the transactional API for Kafka producer, as shown in the following simple count example:
producer.initTransactions();
int counter = 0;
while (true) {
try {
producer.beginTransaction();
producer.send(producerRecord(“outputTopic”, counter++));
producer.commitTransaction();
} catch(ProducerFencedException e) {
producer.close();
} catch(KafkaException e) {
producer.abortTransaction();
counter--;
}
}
This code snippet demonstrates how to do transactional writes to Kafka topics. The first thing a producer does is call initTransactions, where InitProducerId is sent to the broker to fence off other instances with the same transactional ID, as discussed in the error handling section above. For each transaction, the producer goes through three steps:
- Begin the transaction
- Write some data
- Commit the transaction
At the time, the logic was fairly straightforward. However, stream processing applications normally need a more complex flow in the real world to process data in and out of Kafka:
- Consumer fetches some data
- Application process the data
- Producer writes data to Kafka
The example can be extended by including the consumer as follows:
producer.initTransactions();
consumer.assign(inputTopicPartitions(“inputTopic”));
while (true) {
ConsumerRecords consumed = consumer.poll(Duration.ofMillis(5000));
Map<TopicPartition, OffsetAndMetadata> consumedOffsets = offsets(consumed);
List processed = process(consumed);
try {
// Write the records and commit offsets under a single transaction
producer.beginTransaction();
for (ProducerRecord record : processed)
producer.send(record);
producer.sendOffsetsToTransaction(consumedOffsets, groupId);
producer.commitTransaction();
} catch(ProducerFencedException e) {
producer.close();
} catch(KafkaException e) {
producer.abortTransaction();
resetToLastCommittedPositions(consumer);
}
}
In the above example, input topic partitions are manually assigned to the consumer. The transactional producer is responsible for not only writing the data in the transaction but also for committing the consumed offsets via sendOffsetsToTransaction. The transactional guarantee means that either both of these writes complete successfully or neither of them do.
Unfortunately, the revised example only works for consumers that have a static assignment of input partitions, while Kafka consumers need to collaborate as a dynamic group for easy scaling and liveness. The requirement that each producer only writes the committed offsets for a consumer with a static set of input partitions is fundamentally at odds with how consumer groups work. In a consumer group, partitions are shifted around dynamically as membership grows and shrinks in order to balance the load.
The only way the static assignment requirement could be met is if each input partition uses a separate producer instance, which is in fact what Kafka Streams previously relied on. However, this made running EOS applications much more costly in terms of the client resources and load on the brokers. A large number of client connections could heavily impact the stability of brokers and become a waste of resources as well.
To explain this in more detail, consider the following scenario:
Two Kafka consumers C1 and C2 each integrate with transactional producers P1 and P2,
each identified by transactional ID T1 and T2, respectively.
They process data from two input topic partitions tp-0 and tp-1.
At the beginning, the consumer group has the following assignments:
(C1, P1 [T1]): tp-0
(C2, P2 [T2]): tp-1
P2 commits one transaction that pushes the current offset of tp-1 to 5.
Next, P2 opens another transaction on tp-1, processes data up to offset 10, and begins committing.
Before the transaction completes, it crashes, and the group rebalances the partition assignment:
(C1, P1 [T1]): tp-0, tp-1
(C2, P2 [T2]): None
Since there is no such static mapping of T1 to partition tp-0 and T2 to partition tp-1,
P1 proceeds to start its transaction against tp-1 (using its own transactional ID T1)
without waiting for the pending transaction to complete.
It reads from last committed offset 5 instead of 10 on tp-1 while the previous transaction
associated with T0 is still ongoing completion and causes duplicate processing.
As explained in the above example, two transactional producers P1 and P2 could not transfer the ownership of tp-1 safely at runtime. In the old EOS design, the topic partition was statically bonded with the transaction ID, which was not flexible and very hard to scale up. To address the described usability and scalability issues, KIP-447 was proposed as a fundamental improvement to the transactional semantics.
The first goal of KIP-447 is to find another authority to monitor the partition reassignment between transactional producers in order to efficiently avoid any violation of EOS. The group coordinator was selected for this responsibility. Recall that the group coordinator is a designated broker that is responsible for maintaining the committed offsets and mediating the rebalances of a consumer group. As such, it is already aware of the processing of the consumer group since transactional offset commits flow through it. When some offsets get committed to the group coordinator while the transaction itself has not finished, these offsets are treated as pending offsets, which could be used as an indication of some associated open transactions.
When the partition assignment is finalized after a consumer group rebalance, the first step for the consumer is to always get the next offset to begin fetching data. With this observation, the OffsetFetch protocol protection is enhanced, such that when a consumer group has pending transactional offsets associated with one partition, the OffsetFetch call can be blocked until the associated transaction completes. Previously, the “outdated” offset data would be returned and the application allowed to continue immediately. The scenario now becomes:
P2 commits one transaction, which pushes the current offset of tp-1 to 5.
Next, P2 opens another transaction on tp-1 and begins committing a transaction,
which advances the offset to 10. Before the transaction completes, it crashes,
and the group rebalances the partition assignment:
(C1, P1): tp-0, tp-1
(C2, P2): None
After the rebalance completes, the consumer C2 will send an OffsetFetch request to the
consumer group coordinator for the two partitions.
Since there are pending offsets on tp-1, C2 would back off and retry until the ongoing
transaction completes either through the regular commit phase or through a timeout by
the transaction coordinator.
As shown below, the group coordinator is a must-reach spot for the consumers to complete the offset fetch. The ownership of tp-1 is clearly transferred through this synchronization barrier.
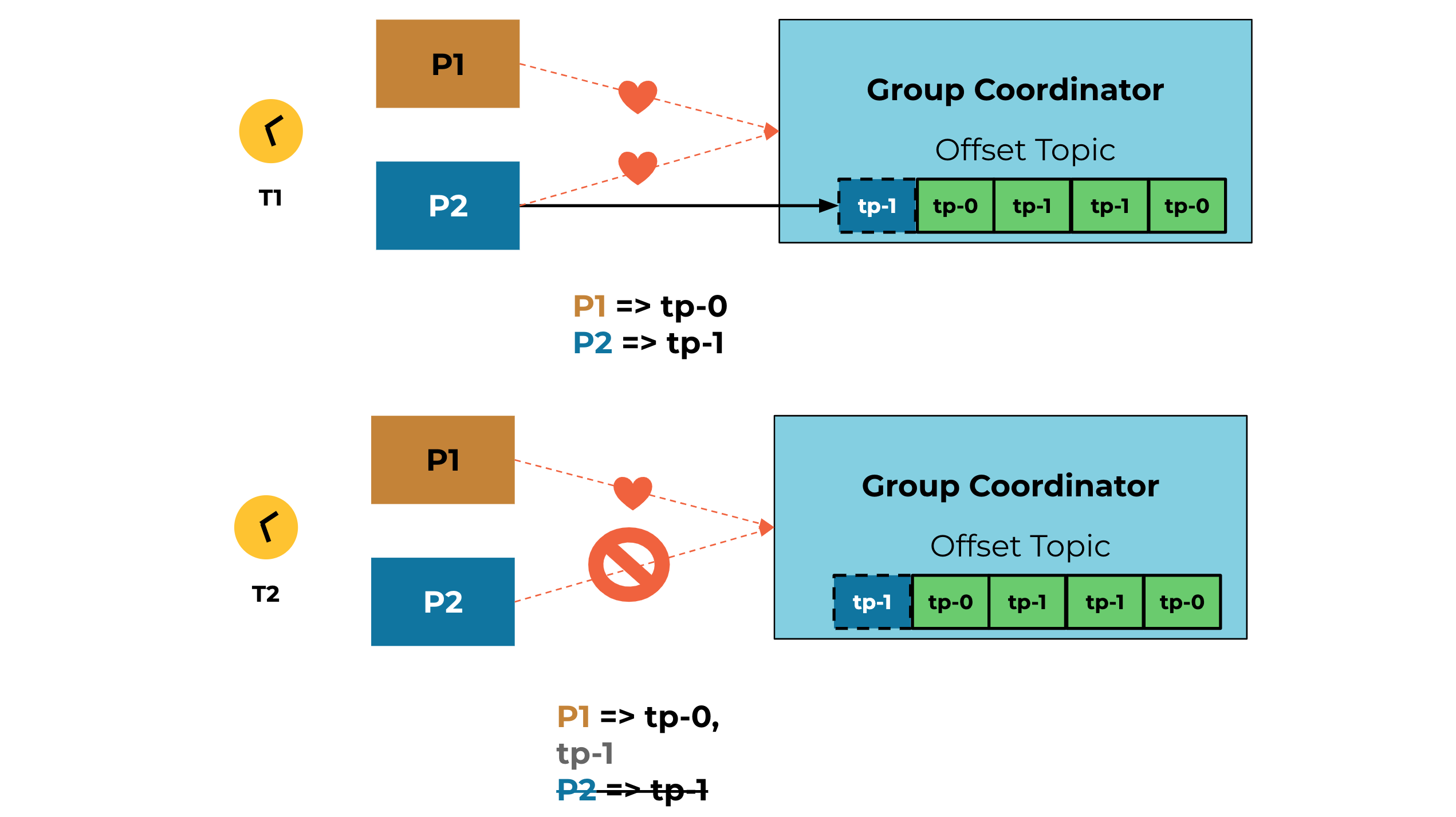 For example, at time T1, producer P2 starts a transaction and has some pending offsets on the partition. When P2 gets disconnected and the coordinator marks it dead, the rebalance shall trigger and assign P2 owned partitions (tp-1) to producer P1 at time T2.
For example, at time T1, producer P2 starts a transaction and has some pending offsets on the partition. When P2 gets disconnected and the coordinator marks it dead, the rebalance shall trigger and assign P2 owned partitions (tp-1) to producer P1 at time T2.
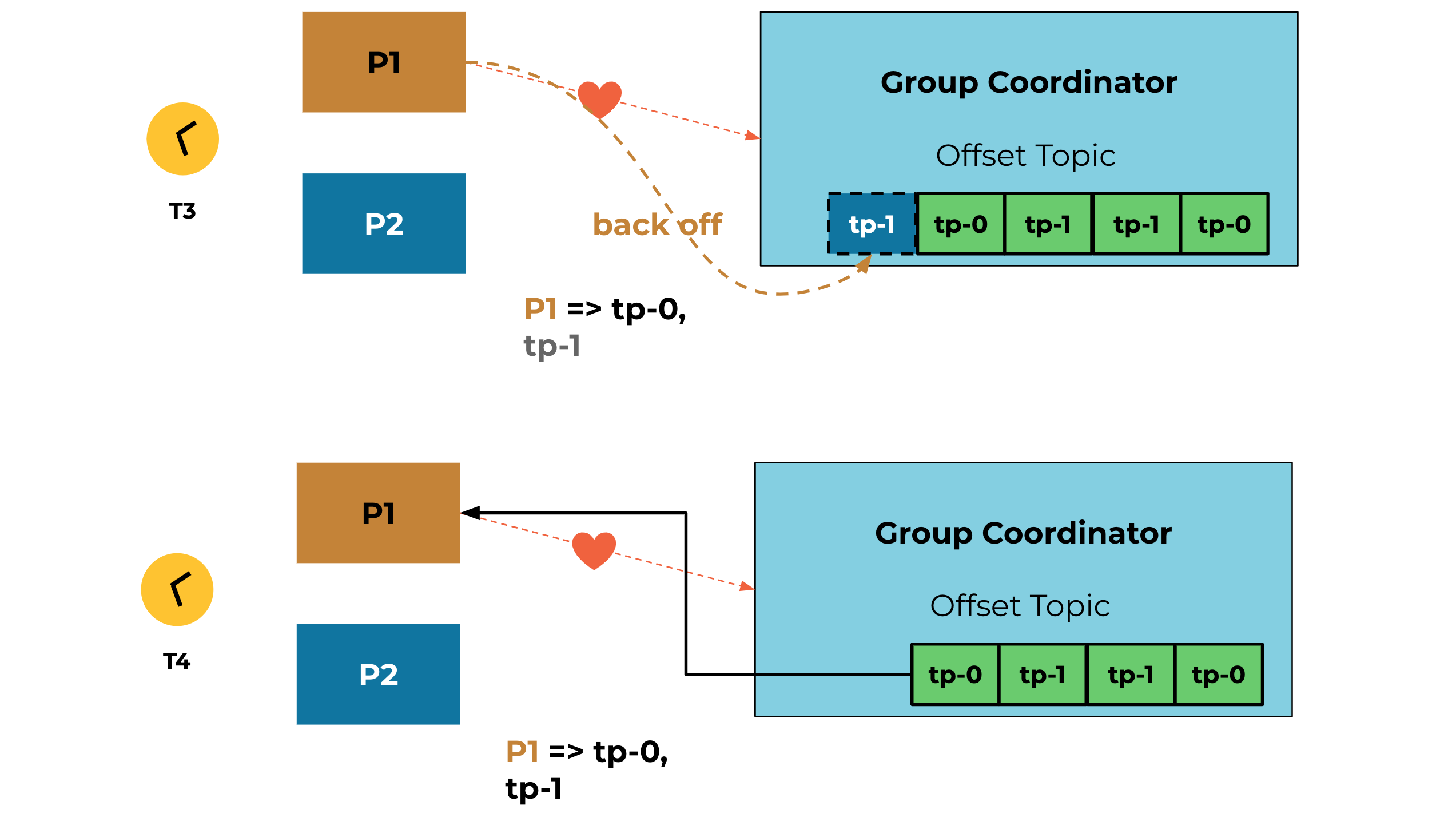 At time T3, P1 will retry and back off for the first offset fetch until the pending offsets are made by the broker due to timeout. At T4, P1 is finally able to get back the latest committed offsets.
At time T3, P1 will retry and back off for the first offset fetch until the pending offsets are made by the broker due to timeout. At T4, P1 is finally able to get back the latest committed offsets.
Additionally, KIP-447 carefully handles edge cases such as fencing against zombie producers. In consumer semantics, there is a concept called group generation, which gets bumped after every successful rebalance so that any out-of-sync member gets fenced off. With the integration of the consumer group and transactional semantics, it is possible for any zombie producer to commit with a valid producer epoch although its generation is outdated. To address this gap, these new APIs have been added:
- A new consumer API, groupMetadata, which reflects the consumer group metadata such as member ID and group generations
- A new producer API, sendOffsetsToTransaction (offset, GroupMetadata), to include the group metadata exposed from the consumer to fence against group generation if necessary
The revised EOS example now supports consumer group semantics:
producer.initTransactions();
consumer.subscribe(singletonList(“inputTopic”));
while (true) {
// Block for the first offset fetch call to get returned.
ConsumerRecords consumed = consumer.poll(Duration.ofMillis(5000));
Map<TopicPartition, OffsetAndMetadata> consumedOffsets = offsets(consumed);
List processed = process(consumed);
try {
// Write the records and commit offsets under a single transaction
producer.beginTransaction();
for (ProducerRecord record : processed)
producer.send(record);
// Pass the entire consumer group metadata for proper fencing
producer.sendOffsetsToTransaction(consumedOffsets, consumer.groupMetadata());
producer.commitTransaction();
} catch(ProducerFencedException e) {
producer.close();
} catch(KafkaException e) {
producer.abortTransaction();
resetToLastCommittedPositions(consumer);
}
}
A demo of the new EOS model is available in this Kafka example. You can run the simulation tests to get a sense of how it works.
Summary
This blog post shared some of the learnings along the EOS improvement path by diving deep into key design points. The enhanced producer error handling makes the EOS application easier to operate and more resilient, while the simplified transactional API encourages the integration of EOS and Kafka consumer semantics to derive more powerful production use cases.
What’s coming next
In the upcoming Kafka 2.6 release, Kafka Streams is expected to adopt this newly introduced transaction model to achieve much better scalability, which will be covered in more detail in a follow-up blog post.
There continue to be ongoing projects to make the transaction model even more efficient, such as:
- KIP-588, which is a follow-up to KIP-360, designed to make the transaction expiration retriable
- KAFKA-9878 aims to reduce end-to-end transaction model latency through delayed processing and batching
If you want to get started using Kafka EOS or have any cool features to contribute, please reach out through dev@kafka.apache.org or user@kafka.apache.org, or join the Confluent Community Slack to discuss your use case with other community friends!
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Guide to Consumer Offsets: Manual Control, Challenges, and the Innovations of KIP-1094
The guide covers Kafka consumer offsets, the challenges with manual control, and the improvements introduced by KIP-1094. Key enhancements include tracking the next offset and leader epoch accurately. This ensures consistent data processing, better reliability, and performance.



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…