The Simplest Useful Kafka Connect Data Pipeline in the World…or Thereabouts – Part 3
We saw in the earlier articles (part 1, part 2) in this series how to use the Kafka Connect API to build out a very simple, but powerful and scalable, streaming data pipeline. The example we built streamed data from a database such as MySQL into Apache Kafka® and then from Apache Kafka downstream to sinks such as flat file and Elasticsearch. Now we will take a look at one of the very awesome features recently added to Kafka Connect — Single Message Transforms.
Single Message Transforms (SMT) is a functionality within Kafka Connect that enables the transformation … of single messages. Clever naming, right?! Anything that’s more complex, such as aggregating or joins streams of data should be done with Kafka Streams — but simple transformations can be done within Kafka Connect itself, without needing a single line of code.
SMTs are applied to messages as they flow through Kafka Connect; inbound it modifies the message before it hits Kafka, outbound and the message in Kafka remains untouched but the data landed downstream is modified.
The full syntax for SMTs can be found here.
Setting the Key for Data from JDBC Source Connector
This is a nice simple, but powerful, example of SMT in action. Where data is coming from the JDBC Source Connector, as in the previous example, it will have a null key by default (regardless of any keys defined in the source database). It can be useful to apply a key, for example to support a designed partitioning scheme in Kafka, or to ensure that downstream the logical key of the data is persisted in the target store (for example, Elasticsearch).
Let’s remind ourselves what the messages look like that are flowing into Kafka from the Kafka Connect JDBC connector:
./bin/kafka-avro-console-consumer \ --bootstrap-server localhost:9092 \ --property schema.registry.url=http://localhost:8081 \ --property print.key=true \ --from-beginning \ --topic mysql-foobarnull {"c1":{"int":1},"c2":{"string":"foo"},"create_ts":1501796305000,"update_ts":1501796305000} null {"c1":{"int":2},"c2":{"string":"foo"},"create_ts":1501796665000,"update_ts":1501796665000}
Those nulls at the beginning of the line are the keys of the messages. We want our keys to contain the integer value of the c1 column, so we will chain two SMTs together. The first will copy the message value’s c1 field into the message key, and the second will extract just the integer portion of that field. SMTs are always set up per connector, so for our connector we amend the config file (or create a new version):
Apply this configuration change:
$ <path/to/CLI>/confluent local config jdbc_source_mysql_foobar_01 -d /tmp/kafka-connect-jdbc-source-with-smt.json
The connector will automagically switch to the new configuration, and if you then insert some new rows in the foobar MySQL table (here using a direct pipe instead of interactive session):
echo "insert into foobar (c1,c2) values (100,'bar');"|mysql --user=rmoff --password=pw demo
you’ll see in the avro console consumer:
100 {"c1":{"int":100},"c2":{"string":"bar"},"create_ts":1501799535000,"update_ts":1501799535000}
Note that the key (the first value on the line) matches the value of c1, which is what we’ve defined in the transforms stanza of the configuration as the column from which to take the message key from.
We can use the fact that we now have a key on the messages in Kafka to maintain a static view of our source table in Elasticsearch. This is because Elasticsearch writes in an idempotent manner based on the key of the row (“document”, in Elasticsearch terminology). All that’s necessary for this is to use the SMT to ensure there’s a key on the Kafka message, and in the Elasticsearch sink connector set "key.ignore": "false" (or simply remove the configuration line, since false is the default).
Note that if you’ve got null-keyed messages on your Kafka topic, which you will have if you’ve followed all of the previous examples, you’ll want to restart the source connector with a different topic as its target. If you try to write to Elasticsearch with a topic that has null-keyed messages in and the connector not set to "key.ignore": "true" then the sink task will fail with the pretty self-explanatory error: ConnectException: Key is used as document id and can not be null.
Add Metadata to the Apache Kafka Message for Data Lineage
Here are two more SMTs that can be useful.
- The first (InsertTopic) embeds the topic name into the message itself—very useful if you have complex pipelines and you want to preserve the lineage of a message and its source topic
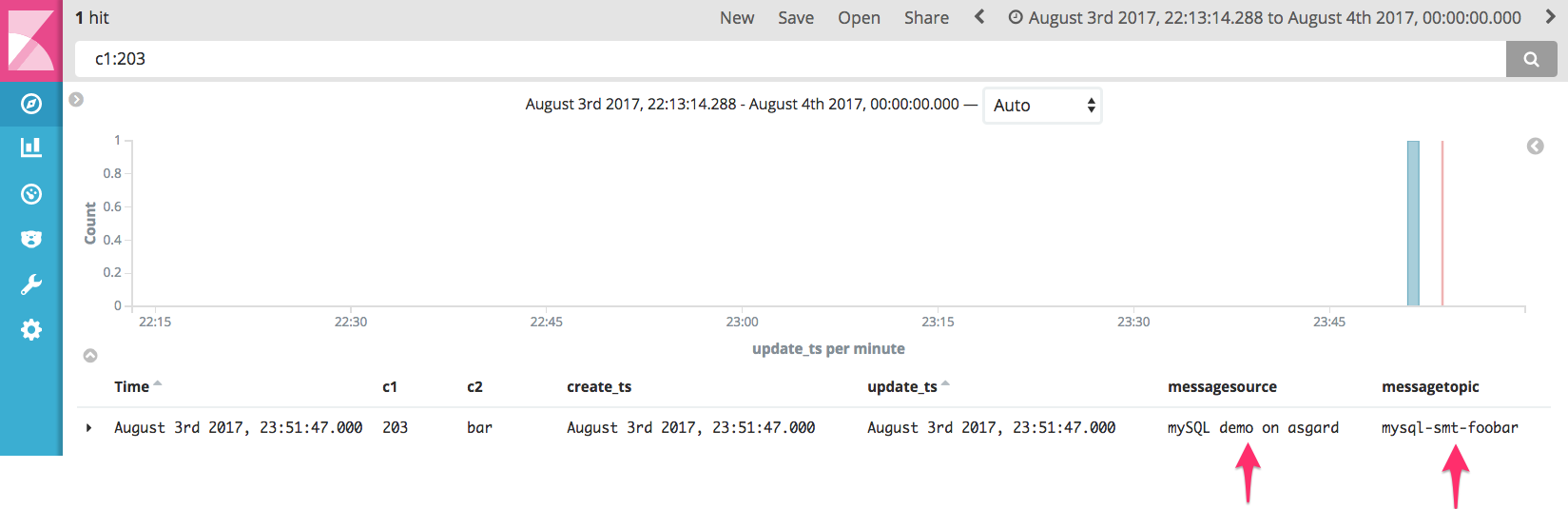
- The second (InsertSourceDetails) adds custom static information as a field into the message. In this example, it’s the name of the source database. Other uses could be environment (dev/test/prod) names, geographies of distributed systems, and so on
"transforms":"InsertTopic,InsertSourceDetails", "transforms.InsertTopic.type":"org.apache.kafka.connect.transforms.InsertField$Value", "transforms.InsertTopic.topic.field":"messagetopic", "transforms.InsertSourceDetails.type":"org.apache.kafka.connect.transforms.InsertField$Value", "transforms.InsertSourceDetails.static.field":"messagesource", "transforms.InsertSourceDetails.static.value":"MySQL demo on asgard"
Note that thanks to the wonders of schema evolution and the Confluent Schema Registry, these new columns are automagically added into the schema, and reflected downstream in Elasticsearch—without a single change having to be made. Literally, the pipeline was running the whole time that I made these changes, and the columns just got added to the Elasticseach mapping. Pretty smart!
Kafka Connect loading Elasticsearch with Schema Evolution
Field Masking and Whitelist/Blacklists
SMTs offer the capability to mask out the value of a field, or drop it entirely.
Here’s an example of a field masking configuration:
"transforms":"maskC2", "transforms.maskC2.type":"org.apache.kafka.connect.transforms.MaskField$Value", "transforms.maskC2.fields":"c2"
This masks field c2, transforming the original message as seen here:
{"c1":{"int":22},"c2":{"string":"foo"}
and removing the contents of c2:
{"c1":{"int":22},"c2":{"string":""}}
We can also drop the field entirely:
"transforms":"dropFieldC2", "transforms.dropFieldC2.type":"org.apache.kafka.connect.transforms.ReplaceField$Value", "transforms.dropFieldC2.blacklist":"c2"
With the result:
{"c1":{"int":22}}
N.B. If you’re using org.apache.kafka.connect.transforms.ReplaceField make sure you include the $Key or $Value suffix, otherwise you’ll get the error:
org.apache.kafka.common.config.ConfigException: Invalid value class org.apache.kafka.connect.transforms.ReplaceField for configuration [...] Error getting config definition from Transformation: null
Message Routing with Kafka Connect SMTs
It’s pretty nifty being able to modify and enrich data inbound through Kafka Connect with a few extra lines of configuration. Here’s some useful examples where SMTs help make the outbound section of the datapipe more flexible, by routing messages to different topics.
Topic Routing with Regular Expressions
Often Kafka Topics are (a) used to define the target object name in a data store (such as Elasticsearch), and (b) have various prefixes and suffixes to denote things like data centers, environments, and so on. This means that unless you want your Elasticsearch index (or whatever else) to have a name DC1-TEST-FOO instead of FOO, you have to manually remap it in the configuration. And why do things manually, if they can be done automagically?
"transforms":"dropPrefix", "transforms.dropPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter", "transforms.dropPrefix.regex":"DC1-TEST-(.*)", "transforms.dropPrefix.replacement":"$1"
So using the example from before, our topic is called mysql-foobar, and let’s say we want to drop the mysql- prefix. With the Elasticsearch connector, we could use the topic.index.map configuration, but this requires us to manually specify every before/after topic permutation, which is going to be pretty tedious (and error prone).
Use this updated configuration for the Elasticsearch connector, with the SMT appended:
From here we can verify that in Elasticsearch the data is now routing to the foobar index:
curl -s "http://localhost:9200/foobar/_search" | jq '.hits.hits[]'
{
"_index": "foobar",
"_type": "type.name=kafka-connect",
"_id": "100",
"_score": 1,
"_source": {
"c1": 100,
"c2": "bar",
"create_ts": 1501799535000,
"update_ts": 1501799535000,
"messagetopic": "mysql-smt-foobar",
"messagesource": "MySQL demo on asgard"
}
}
Note that with the Elasticsearch sink you may hit ConnectException: Cannot create mapping – see this GitHub issue for details. If you hit this then as a workaround you can prime Elasticsearch by explicitly creating the index first:
curl -XPUT 'http://localhost:9200/foobar'
Timestamp Topic Routing
As well as remapping a topic based on a regex pattern, SMT can be used to route messages to topics (and thus downstream objects such as Elasticsearch indices) based on a timestamp.
"transforms": "ts-to-topic", "transforms.ts-to-topic.type": "org.apache.kafka.connect.transforms.TimestampRouter"
There are two optional configuration options – topic.format and timestamp.format, letting you specify the topic pattern and timestamp format to use. For example:
"transforms":"routeTS", "transforms.routeTS.type":"org.apache.kafka.connect.transforms.TimestampRouter", "transforms.routeTS.topic.format":"kafka-${topic}-${timestamp}", "transforms.routeTS.timestamp.format":"YYYYMM"
Both routing transforms can be combined, giving:
"transforms":"dropPrefix,routeTS", "transforms.dropPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter", "transforms.dropPrefix.regex":"mysql-(.*)", "transforms.dropPrefix.replacement":"$1", "transforms.routeTS.type":"org.apache.kafka.connect.transforms.TimestampRouter", "transforms.routeTS.topic.format":"kafka-${topic}-${timestamp}", "transforms.routeTS.timestamp.format":"YYYYMM"
Summary
In this series so far we’ve seen how to build realtime, scalable, fault-tolerant, distributed data pipelines with Kafka and Kafka Connect. The first post looked at streaming data from a database into Kafka. Streaming data out to Elasticsearch from Kafka was then covered next.
In this post we dug a little deeper into Kafka Connect, seeing how Single Message Transforms provide a powerful way to manipulate messages as they flow through Kafka Connect. Masking data, adding lineage, and routing topics are all possible with SMTs. Something we didn’t even cover here is that it’s an open API and so they’re completely extensible too! For more detail on when SMTs are appropriate, have a look at this excellent presentation from Kafka Summit in New York earlier this year.
Other Posts in this Series:
Part 1: The Simplest Useful Kafka Connect Data Pipeline in the World…or Thereabouts – Part 1
Part 2: The Simplest Useful Kafka Connect Data Pipeline in the World…or Thereabouts – Part 2
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


