Secure Data Exchange for Financial Institutions
In order to deliver the services that the financial sector relies on from day to day, for example, with credit card or trade transactions, there is a choreography of data interactions that takes place under the covers to fulfill those requests. The requests can trigger many other background subprocesses that include transferring funds and settling/clearing trades—transactions that require an additional layer of data orchestration both within the organization and across multiple external parties, including market partners, custodians, DTCC, and regulatory authorities.
To meet the immediate demands of today’s banking environment, this data exchange should be seamless. Financial institutions that excel at this will see transactions accurately processed immediately, trades executed flawlessly, and little friction between data sharing outside the organization. To provide these fundamental capabilities, the financial services industry (FSI) constantly evolves its data architecture, utilizing new technologies and solutions to enhance efficiency, streamline processes, and innovate new services. But this willingness to adopt new technologies comes at a price—it’s created a noisy data landscape of multiple and varied formats, standards, and protocols that present a challenge for IT teams to harmonize and operationalize data sharing across the infrastructure in a secure and timely manner. While commonly adopted data formats and transport methods (such as SFTP, EDI, flat file, FIX, and REST APIs) make this orchestration possible, these traditional methods come with limitations, not the least of which includes batch-level-speed quality of service, lack of scalability and fault tolerance, and end-to-end data governance. For a modern financial system that relies on superior real-time services to remain competitive, this is problematic.
This blog explores how firms can overcome the challenges of data exchange with a highly secure and efficient process using Confluent Cloud clusters at the edge.
FSI services that leverage data exchange
First, let’s begin with a closer look at some of the critical financial services functions that depend on accurate, secure, and timely data exchange mechanisms.
Regulatory reporting and compliance: These are non-negotiable line items for financial institutions. Compliance with various regulations such as Anti-Money Laundering (AML) and Know Your Customer (KYC) not only fulfills their regulatory obligations but also nurtures and develops trust with clients and investors. Failure to do so can result in severe penalties, loss of reputation, and the erosion of client trust. By partnering with experienced providers and leveraging the right technology to do so, financial institutions can achieve greater regulatory reporting and compliance success.
Trading services: Time is money. Financial institutions must exchange trade-related data such as orders, pricing, liquidity, and securities lending with speed and precision to ensure seamless execution. They need to enable access to local and global markets while scrutinizing foreign exchange workflows as the industry and regulators shift to faster settlement cycles. The settlement of securities trades is a multi-step process that involves coordination and communication among a wide variety of parties. The adoption of T+1 (transaction date + 1 business day) clearing and settlement will make data and its flow an even more integral part of the trading lifecycle. The industry acknowledges that there are benefits that T+1 can offer. By removing one day of the settlement cycle, which is currently T+2, there is literally a 50% corresponding reduction in risk. The length of exposure to trading counterparties also declines as a result. This will also lower margin requirements for clearing members, and lower both market and liquidity risk. There is also greater funding efficiency as investors benefit from operational efficiencies and get access to their funds sooner. It will demand nothing short of flawless accuracy and lightning-fast efficiency. Financial institutions can deliver exceptional trading services and drive profitability by optimizing their trading workflows.
Portfolio management: This is the engine that drives asset allocation optimization for clients, risk assessment, and overall efficiency in managing portfolios within the new time frame. Maintaining discipline in these areas of managing a client’s financial assets not only drives the outcomes desired by clients, but also compounds trust, which in turn, powers a flywheel effect to profitability. At the heart of it all lies data sharing.
Investment research: Research is the fuel that powers informed investment decisions and enables institutions to provide unparalleled value to their clients. To deliver this value, investment institutions must seamlessly share research data, market insights, and macroeconomic data with their partners. This helps institutions build resilient client relationships.
Investment servicing: The backbone of financial institutions, providing services such as custody, fund administration, and accurate performance reporting while ensuring regulatory compliance is essential. These are the ingredients to deliver clients a top-notch investment service. But with the settlement cycle getting shorter, investment financial institutions must exchange data more effectively.
Unlocking the power of real-time data exchange
The thread that weaves all the above offerings together for a financial institution is underpinned by the accuracy, security, and timeliness of the data shared not just within its own ecosystem, but also the data interchanged with its partners and other third-party data providers. Inaccurate, delayed, or compromised data can have significant financial and reputational implications for all parties involved and commonly lead to a longer innovation and integration cycle. Exchanging data is one of the pillars of a financial institution’s operations.
Some of the challenges for financial institutions that need to exchange data are:
Security
Onboarding
Scaling
Multi-tenancy
Data privacy
Data formats
Chargebacks
To tackle these complexities, they require a solution that is up to the task of streamlining their processes, preventing failures, and automating end-to-end tasks wherever feasible.
How Confluent data streaming platform helps overcome these challenges
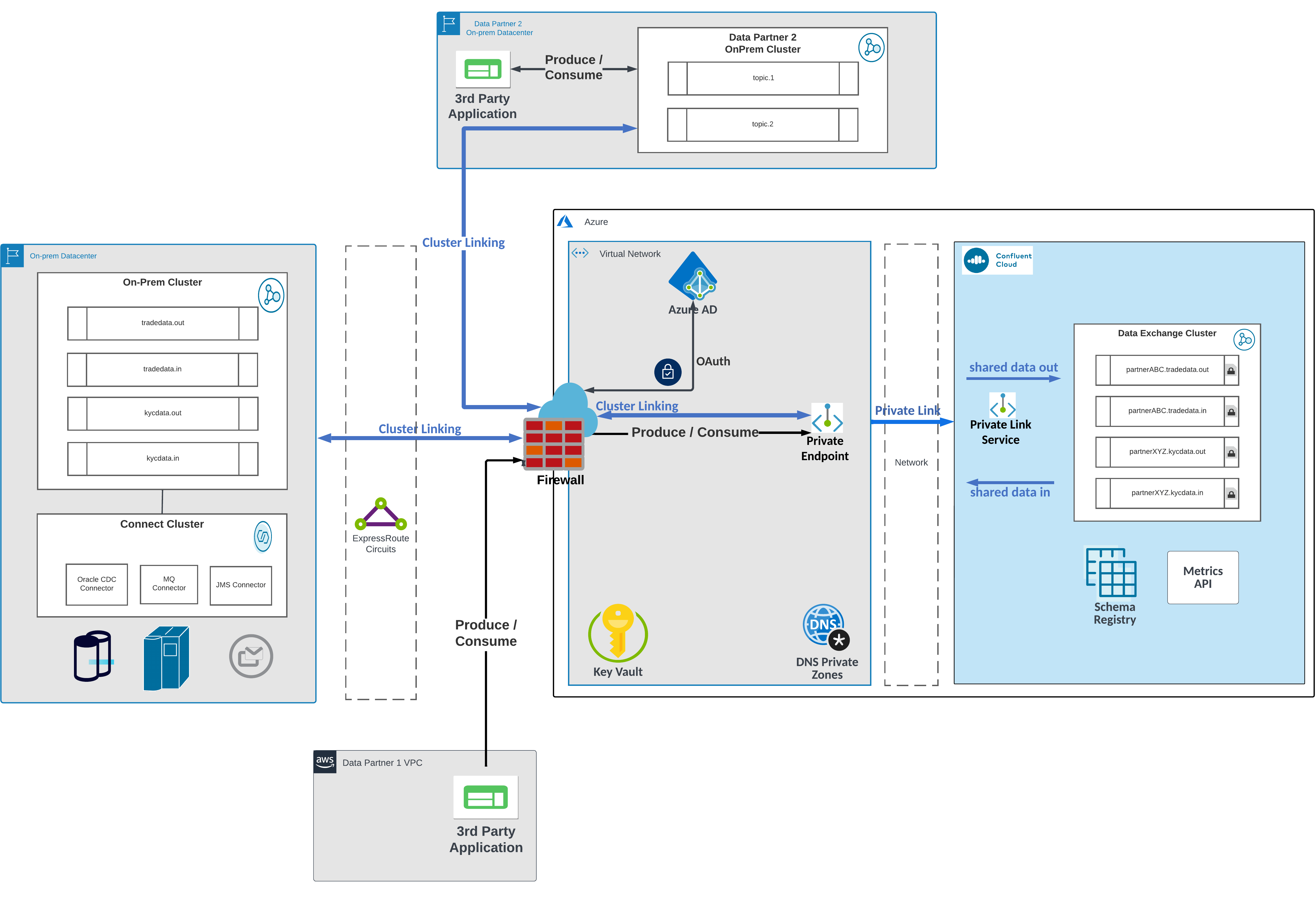
Confluent Cloud enables companies to quickly and securely share data within and across organizations more efficiently. It can integrate traditional external methods of flat file transmissions, legacy messaging, API calls, or webhooks via a comprehensive array of source and sink connectors.
Provisioning a Confluent Cloud cluster at the edge for data interchange, companies can offload the workload of administering another cluster for sharing data. The goal is to isolate internal operations, data, and systems from external access to protect the sovereignty of internal data while enabling the secure external exchange of enriched information. Another benefit is that the burden of processing and exchanging data can be removed from your internal infrastructure. This improves performance and scalability by preventing data congestion and minimizing the risk of errors and system failures.
Confluent Cloud Dedicated Clusters are fully managed, promising up to a 99.99% SLA, and can be provisioned in any of the multi-AZ regions supported by the three major cloud service providers (CSPs) using private networking options. And, with the ability to seamlessly move data across these cloud service providers, financial institutions can achieve unparalleled access to data wherever it resides with resilience and scalability. This can open up new partnerships, product development, and growth opportunities.
Key features
Streaming Governance (data formats): Provides and enforces a unified and standardized way of exchanging data that offers a consistent communication protocol and data format across various systems, eliminating the need for individual legacy methods. This standardization allows financial institutions to deliver trusted, high-quality data streams and maintain real-time data integrity with explicitly defined data contracts. By leveraging these capabilities, financial institutions can improve their systems' interoperability and reliability, making integrating with existing systems and communicating with external partners easier.
Data encryption (data privacy): Protect sensitive and confidential financial data during the exchange, ensuring it remains secure from payload through to transmission, storage, and access. Confluent Cloud supports clients that bring and control their own encryption key (BYOK). Confluent Cloud only exposes TLS endpoints ensuring that in-flight data is always encrypted. To add another layer of security, Confluent announced the release of Client-Side Field Level Encryption (CSFLE). This feature allows producer applications to encrypt fields that need to be protected or that contain sensitive data before publishing the data. Consumers with proper permissions to the key and topic can access the data in unencrypted format while consumers without proper access will only see the data in encrypted form. Customers retain full control over their master/key encryption keys (KEKs) and manage them using their key management service (KMS). Robust end-to-end encryption mechanisms are crucial for achieving this goal, enabling financial institutions to maintain regulatory compliance and safeguard assets. But beyond regulatory compliance, data security provides significant business value regarding reputation and trust.
OAuth and RBAC (security and onboarding): Confluent Cloud enables you to manage identities with any third-party OAuth/OpenID Connect (OIDC) compliant identity provider such as Azure AD, Okta, PingFederate, and Keycloak for authentication of applications and users (i.e., single sign-on). Data exchange partners can authenticate with Confluent Cloud resources using short-lived credentials (i.e., JSON Web Tokens). Once authenticated and access token issued, Confluent Cloud uses identity pools to map groups and other attributes to predefined policies to authorize access to resources such as topics.
Client quotas (multi-tenancy): Customers can use Client Quotas to limit the amount of throughput that applications can obtain from a cluster. Customers can implement a t-shirt sizing capacity planning strategy to determine how much capacity will be required on a cluster. With Client Quotas, in conjunction with service principals and per-principal tagging in the Metrics API, customers have a robust set of foundational capabilities to build a secure and shared cluster. You can learn more here. Cluster operators can precisely allocate, track, and manage their cluster resources, enabling them to efficiently support many third-party workloads on the same cluster.
Observability (chargebacks): Collect metrics, logs, and traces for each data exchange, which can be used to monitor the performance and usage of the end-to-end system and identify potential issues. These metrics can then be used to optimize and trace the lineage and efficacy of the data exchange process audit and overall performance. You can read more about setting up a chargeback strategy here.
Scaling: A side effect of implementing a successful solution is that it attracts many more use cases. To be clear, it’s a good problem to have and when this time arrives a cluster will need to expand to handle the increased throughput. More brokers need to be installed and partitions need to be redistributed so that each broker handles their share of the workload. Manually tackling these tasks is tedious and taxes human resources that should be addressing other pressing issues. With Confluent Cloud scaling is as easy as an API call, CLI call, or a UI slider bar. Everything is handled for you. One of the best parts is that your third-party partners and their applications will dynamically adjust to the scale as well. Producers and consumers will be notified where the new leaders of their partitions are being served from and it’s business as usual.
Terraform (CI/CD and onboarding): To allow you to script all the necessary resources in a declarative manner and automate onboarding of crucial third-party data producers and consumers, Confluent has a Terraform Provider. Use Terraform to securely automate the deployment of new partners with their credentials, topics, RBAC rules, and client quotas. Use Terraform when you need to scale the cluster as well.
Summary
Today’s financial services companies are expected to use data to do it all—minimize friction in the customer experience, maximize business efficiency, and innovate. In siloed organizations, these competing goals result in disjointed data strategies and incompatible data sets that make seamless data exchange seem impossible. However, financial institutions can’t afford to stagnate when it comes to improving their operational efficiency and client experiences. That's why adopting Confluent has become mission-critical.
Using Confluent Cloud at the edge allows firms to implement the automation, security, cloud-native, and governance capabilities their data exchange processes need to work at scale, across environments. As a result, financial institutions can quickly and securely exchange data with their market partners, custodians, and regulatory authorities. Enabling the secure exchange of enriched data will bolster the speed of business and relationships with clients, ultimately driving profitability and defensibility in an increasingly competitive industry.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.


{kind=link}

Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.