Reliable, Fast Access to On-Chain Data Insights
At TokenAnalyst, we are building the core infrastructure to integrate, clean, and analyze blockchain data. Data on a blockchain is also known as on-chain data. We offer both historical and low-latency data streams of on-chain data across multiple blockchains.
How we use Apache Kafka and the Confluent Platform
Apache Kafka® is the central data hub of our company. At TokenAnalyst, we’re using Kafka for ingestion of blockchain data—which is directly pushed from our cluster of Bitcoin and Ethereum nodes—to different streams of transformation and loading processes.
Loading involves batching and storing data in Avro for replay and schema evolution, as well as in Parquet for optimized batch processing in AWS Athena. A big challenge is to support and manage multiple semantically enriched data models for the same underlying data, e.g., into a graph data model to trace value flow or into a MapReduce-compatible data model of the UTXO-based Bitcoin blockchain.
One can easily imagine that the Confluent Schema Registry is extremely helpful for typeability and systematic evolution of our models. Access to the data lake and raw data streams is self-provisioned which allows us to work in parallel, and to scale to support multiple protocols (e.g., the decentralized exchange protocol 0x) that are built on top of different chains.
On the event streaming side, we offer reliable low-latency data streams for financial applications based on Kafka Streams. Kafka Streams allows us to focus on our business logic leveraging its out-of-the-box high availability and fault tolerance. A very central and custom component of our data pipeline, the block confirmer, is built on top of the Processor API, as we will discuss later in the Block confirmer based on Kafka Streams section.
The confirmer is maintaining a fork tree (stored in the state store) to process incoming new blocks from a cluster of blockchain nodes effectively once. The fork-tree is very similar to how blockchain clients resolve competing blocks. Our data science team uses KSQL to experiment with raw or lifted streams to ultimately deploy new machine learning models (using custom user-defined functions) without writing a single line of Java code. Use cases range from stateless transformation, such as ERC-20 transactions, to anomaly detection and classification.
As a startup, we try to maximize the impact of our work effort by focusing on providing value instead of reinventing the wheel. The Confluent Platform is an amazing toolbox, which every architect and data engineer should know of and utilize.
Why does on-chain data matter?
A public ledger could potentially serve not only as a publicly accessible ledger for money or asset transactions but also as a ledger of interactions on a shared decentralized data infrastructure. Any event, from IoT-supported delivery, trade, real estate transfer, to a bet in a prediction market is timestamped, censorship-resistant, and provable.
The blockchain as a data structure is, in essence, a giant, shared immutable log, lending itself perfectly for event sourcing and (replayed) stream processing. Interestingly, blockchain technology is reducing the need for trust, but doesn’t make it obsolete. The required trust comes from transparency. And transparency is realized by surfacing and decoding the data that is stored on the blockchain.
Without looking too far into the future—blockchain companies, public entities, and governments rely on analytics of blockchain data for different motives, ranging from simple runtime monitoring of a smart contract to live trades made on a decentralized exchange, or revenue reports of potentially decentralized autonomous organisations or companies.
The importance of on-chain data will become ubiquitous, prompting potential on- and off-chain data joins, such as on-chain value transactions or token holdings with traditional user or customer profiles. For example, we recently examined data on Ethereum smart contract interactions and clearly identified patterns of usage that could inform future development in what is essentially a machine dominated ecosystem.
Accessing on-chain data requires setting up nodes, which turns out to be not as easy as we thought, due to overcoming different quirks we encountered or data discrepancies between versions. Furthermore, another challenge is keeping them in sync with the network. For zero downtime, and to ensure the highest standards in data quality and reliability, we decided to use Kafka and the Confluent Platform.
Cluster of Ethereum nodes, Ethereum-to-Kafka bridge
Right now, our focus lies on Ethereum. To interface with the peer-to-peer network, we have node templates written in Terraform, which allow us to easily deploy and bootstrap nodes across the planet in different AWS regions. We use the Geth and Parity clients. Both provide a JSON-RPC interface that enables us to subscribe to recent block updates (recently mined blocks). A new block is mined on average every 15 seconds. Complementary data types such as transaction receipts, event logs, and state diffs are also extracted.
To bridge the gap between different Ethereum clients and Kafka, we developed an in-house solution named Ethsync, written in Scala, which allows us to propagate the data in a reliable at-least-once manner. Each node plus Ethsync is pushing the data to its corresponding Kafka topic. It’s important to note that we need to run multiple nodes for redundancy because nodes can run out of sync or simply crash. The block updates pushed to the topics are the blocks that the client accepts as a new valid block. However, due to the nature of the blockchain, forks of the blockchain might happen (an alternative chain becomes longer and causes the other chain to be invalidated). Therefore, previously valid blocks can become invalid.
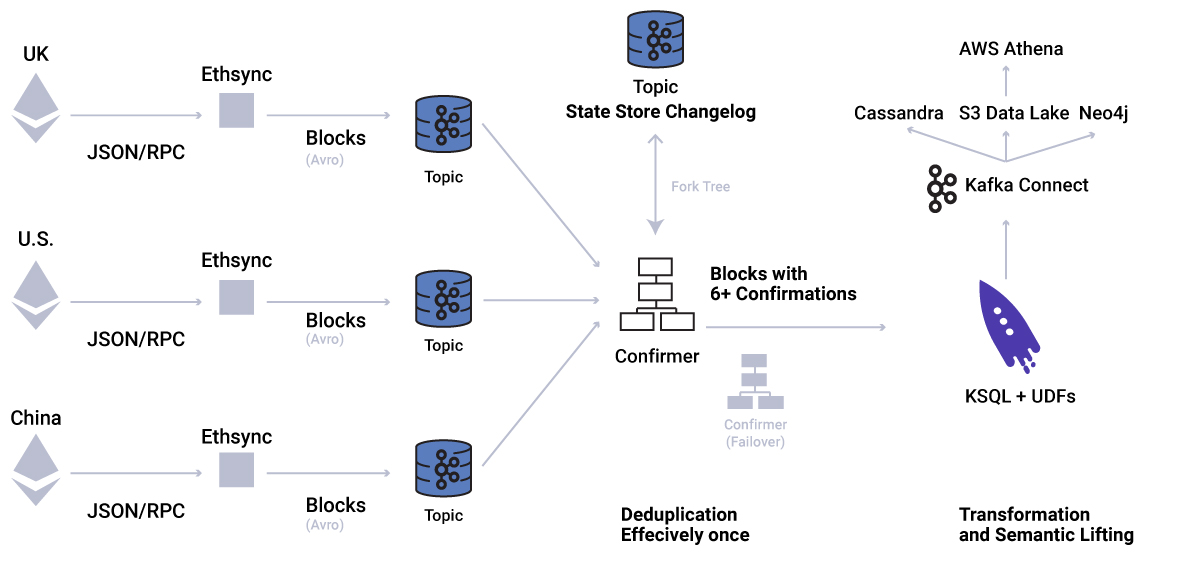
Figure 1. Dataflow in architecture
Block confirmer based on Kafka Streams
To prevent using invalid blocks in downstream aggregate calculations, for example, we developed a block confirmer component that is based on Kafka Streams in Scala. It resolves reorganisation scenarios by temporarily keeping blocks, and only propagates them when a threshold of a number of confirmations (children to that block are mined) is reached.
For this, we keep a tree of parents and children blocks (with forks), as well as the original data, in a Kafka Streams state store as seen in Figure 1. We’re storing the state as updates to the same key. In production, each new block produces a state record update of 150 KB on average. When forks happen, we usually see two forks, but sometimes up to four forks in a six-confirmation time window.
The confirmer not only solves the challenge of verifying the canonical chain but also outputs every confirmed block with effectively once semantics by discarding already registered and already confirmed blocks. Building that component on Kafka Streams allowed us to leverage on fault tolerance recovery mechanisms, such as failover instances and state recovery. This is great for rolling deploys for zero-downtime environments.
Our API and software development kit (SDK)
In the big picture, our API and SDK allow customers to retrieve both historical data and reports, and to subscribe to low-latency data streams of raw and contextualized on-chain data. The API backend and SDK are both written in TypeScript. To access the result records of Kafka Streams processors and KSQL processing queries like filtering, aggregates, and anomaly detection, we use the kafka-node and avro-schema-registry JavaScript libraries. The latter enables us to verify the correct output types to prevent schema inconsistencies, inconsistencies with the SDK, and implicitly with external customer infrastructure.
On our API instances, we use Socket.IO to provide a WebSocket-based access to subscribe to JSON and binary-compressed Avro data. Another interesting way of exposing data we’re looking into is the queryable state of Kafka Streams applications to expose the current state of forks happening and more.
Conclusion
The hype is currently omnipresent, and it’s not going away soon. We foresee a demand for on-chain data, or trusted data, going forward. It doesn’t just come from the perspective of financial transactions and regulations but, more importantly, from the use cases that smart contracts will enable in the near future. As a startup, we try to maximize the impact of our work effort in the right direction under very limited resources. The latter requires leveraging proven components such as the Confluent Platform to build resilient data pipelines.
If you’d like to know more, you can download the Confluent Platform and learn about ksqlDB, the successor to KSQL.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.



Predictive Analytics: How Generative AI and Data Streaming Work Together to Forecast the Future
Discover how predictive analytics, powered by generative AI and data streaming, transforms business decisions with real-time insights, accurate forecasts, and innovation.