New for Confluent Cloud: Stream Designer, Stream Governance Advanced, and More
Our latest set of Confluent Cloud product launches is live and packed full of new features to help businesses innovate faster and more confidently with our real-time data streaming platform. What’s new? Streaming data pipelines are now simpler than ever to build, with an enterprise-grade governance suite to back it all up. We are introducing Stream Designer, a new visual canvas for building pipelines in minutes; Stream Governance Advanced, expanding on the existing suite of enterprise-grade governance tools; and much more!
Here’s an overview of our new features—read on for more details:
- New Confluent Cloud features:
- See the new features in action in the Q4 Launch demo webinar
Streaming data pipelines made simple and governed
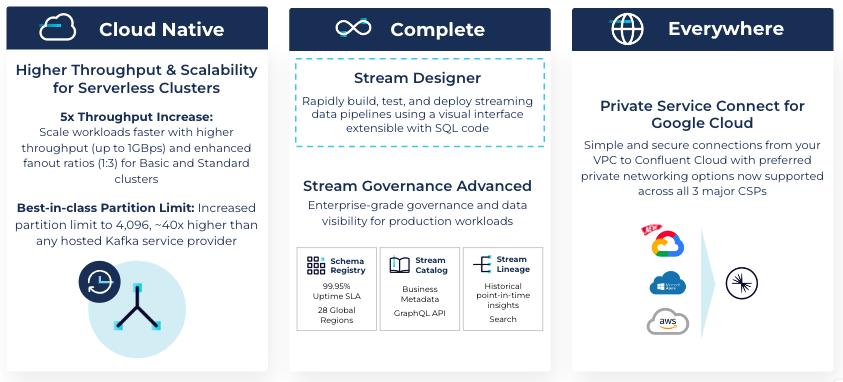
Stream Designer: Rapidly build, test, and deploy streaming data pipelines using a visual interface extensible with SQL code
Stream Designer is a visual interface for rapidly building, testing, and deploying streaming data pipelines on Confluent Cloud. Instead of spending weeks or months setting up individual components with open-source Apache Kafka®, developers can now build pipelines in minutes on Stream Designer, leveraging fully managed Kafka clusters, a portfolio of over 70 pre-built connectors, and ksqlDB for stream processing. After creation, pipelines can be easily updated and extended through a unified, end-to-end view and exported as SQL code for CI/CD or reused as templates across teams.
Unlike other GUI-based interfaces, Stream Designer takes an approach that offers speed and simplicity without sacrificing performance, fitting into existing developer workflows with no runtime layer and allowing users to switch between UI and the full SQL editor as needed. Organizations will be able to accelerate their real-time initiatives and democratize access to data streams by reducing reliance on specialized Kafka expertise.
Now generally available for Confluent Cloud, Stream Designer allows businesses to:
- Boost developer productivity by reducing the need to write boilerplate code. In minutes, developers can start building pipelines that leverage Confluent Cloud integrations.
- Unlock a unified end-to-end view to update and maintain pipelines throughout their lifecycle. There’s inherent flexibility to switch between the visual interface and full built-in SQL editor when modifying pipelines, with changes seamlessly translated from UI to code and vice versa.
- Accelerate real-time initiatives across an organization with shareable and reusable pipelines. Multiple users can edit and work on the same pipeline live, improving collaboration and knowledge sharing.
“Data streaming is quickly becoming the central nervous system of our infrastructure as it powers real-time customer experiences across our 12 countries of operations,” said Enes Hoxha, enterprise architect, Raiffeisen Bank International. “Stream Designer’s low-code visual interface will enable more developers across our entire organization to leverage data in motion. With a unified, end-to-end view of our streaming data pipelines, it will improve our developer productivity by making real-time applications, pipeline development, and troubleshooting much easier.”
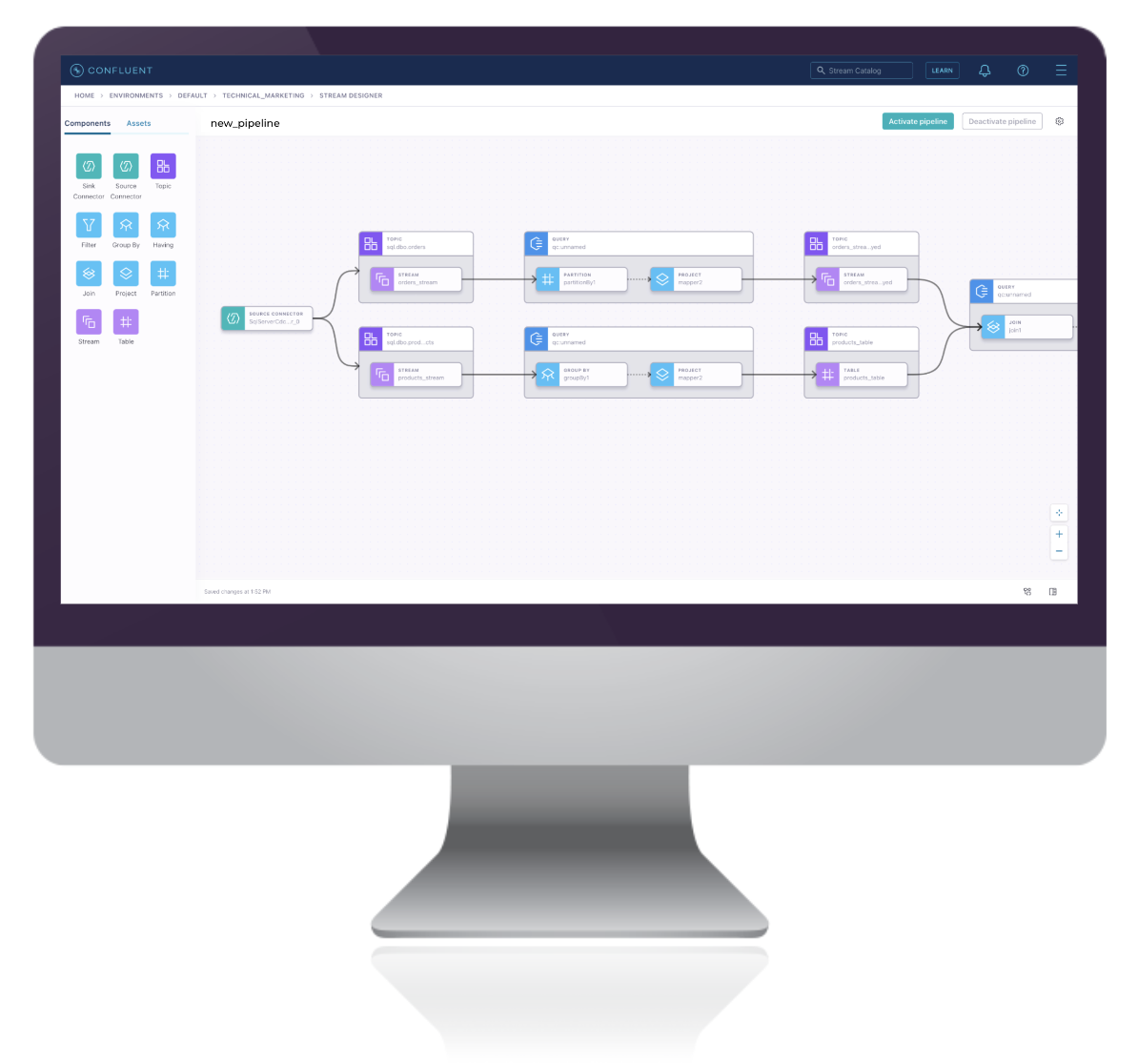
Build streaming data pipelines in minutes using a visual canvas
Check out our latest Stream Designer blog to learn more.
Stream Governance Advanced: Globally available quality controls, rich-context cataloging, and point-in-time lineage insights
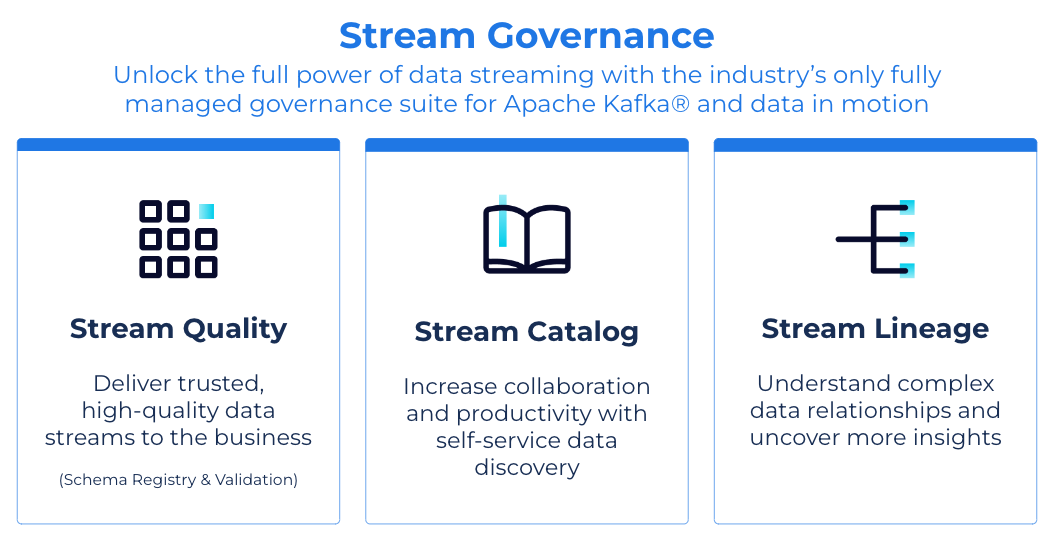
As organizations seek to scale their use of data streaming and deliver against an expectation for “real-time everything”, it becomes increasingly important that engineering teams have the tools necessary to efficiently and safely leverage the technology. Stream Governance establishes trust in the data streams moving throughout a business and delivers an easy, self-service means for more teams to discover, understand, and put data streaming to work. The industry’s only fully managed governance suite for Apache Kafka and data in motion is organized across three feature pillars: Stream Quality, Stream Catalog, and Stream Lineage.
Originally launched in 2021, Stream Governance gives Confluent customers the ability to accelerate projects dependent upon Apache Kafka. However, the wide adoption of these features coupled with more customer feedback gave clear signals that even heavier investment was needed in this area (see more from Ventana on Confluent’s governance capabilities). In this launch, we present Stream Governance Advanced and significantly expand the suite of governance capabilities on Confluent Cloud.
Stream Governance Advanced delivers enterprise-grade governance and data visibility for production workloads. Organizations can now:
- Confidently govern mission-critical workloads at any scale with a new 99.95% uptime SLA for Schema Registry available across 28 global regions (Stream Quality)
- Enhance data discovery within your streaming catalog with user-generated business context and easy, declarative search via GraphQL API (Stream Catalog)
- Simplify comprehension and troubleshooting of complex data streams with lineage search and historical point-in-time insights (Stream Lineage)
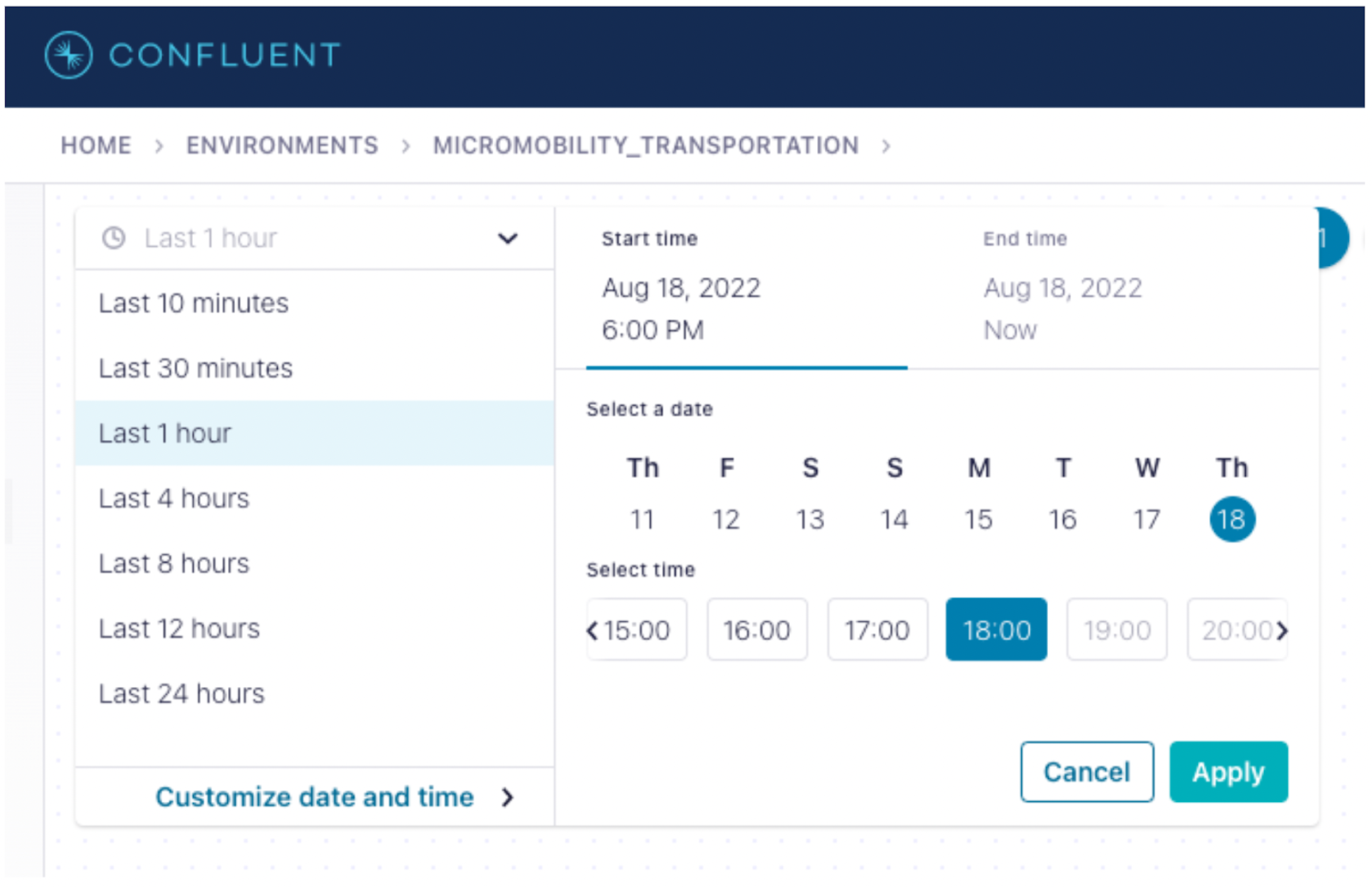
Point-in-time lineage provides users with a look into the past—allowing them to see data stream evolutions over a 24-hour period or within any 1-hour window over a 7-day range
Within Stream Governance Advanced, we’ve made Schema Registry even more resilient, scalable, and globally available. Production workloads can be run with high confidence atop an increased 99.95% Uptime SLA. Quality controls can be enforced across every unique pipeline and workload with an increased schema limit of 20,000 per environment. And with 28 global regions supported, teams have more flexibility to run Schema Registry directly alongside their Kafka clusters and maintain strict compliance requirements.
Within Stream Catalog, we’re giving teams the ability to build more contextual, detail-rich catalogs of their data streams to improve self-service search and discovery across their organizations. The Advanced package introduces business metadata, giving individual users the ability to add custom, open-form details represented as key-value pairs to entities that will be critical to enabling effective self-service access to data. For example, while tagging has allowed users to flag a topic as “PCI” or “Sensitive,” business metadata allows that user to add more context such as which team owns the topic, how it is being used, who to contact with questions about the data, or any other details necessary.
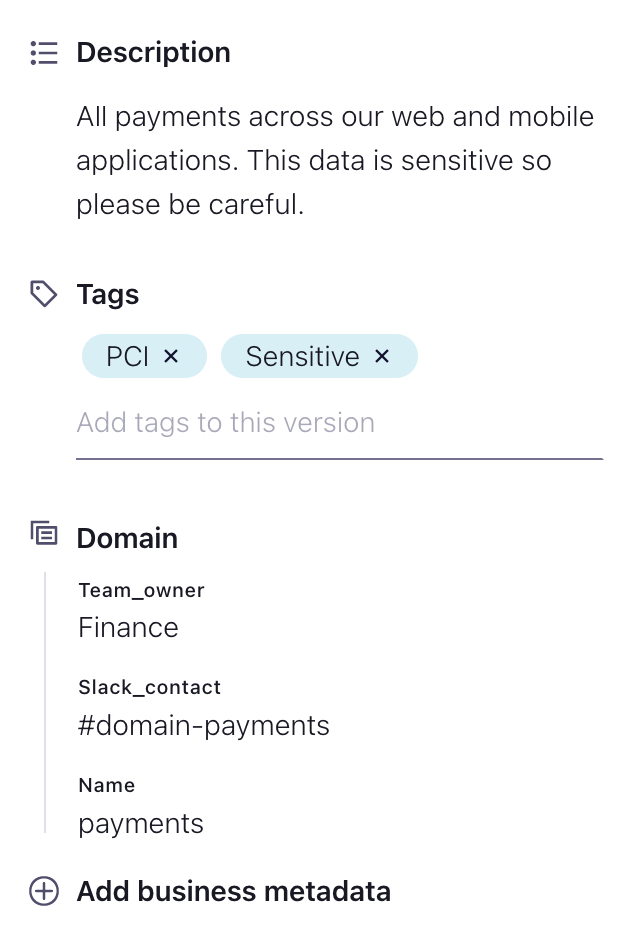
Descriptions, tagging, and business metadata improve the discoverability of objects on the data streaming platform and enable effective self-service access to data
Alongside an existing REST API, Stream Governance Advanced also introduces support for GraphQL API—the same API on which the Stream Catalog UI is built—providing a simple, declarative method of programmatically exploring the catalog and better understanding data relationships on Confluent Cloud.
Expanding upon Confluent Cloud’s interactive lineage mapping, point-in-time lineage provides users with a look into the past—allowing them to see data stream evolutions over a 24-hour period, or within any 1-hour window over a 7-day range, to understand where, when, and how data streams have changed over time. Paired with the new ability to search across lineage graphs for specific objects such as client IDs or topics, point-in-time lineage provides teams with an easy means of identifying and resolving issues buried within complex data streams in order to keep mission-critical services up for customers and new projects on track for deployment.
Ready for Stream Governance Advanced? Upgrading and configuring your environment with all of these new features is available on-demand from directly within your Confluent Cloud account. For more information, compare the Stream Governance packages.
Simple and secure VPC connection with preferred private networking options across all three major CSPs
We’re also announcing the general availability of Private Service Connect for Google Cloud. This completes our offering of preferred private networking options across AWS, Microsoft Azure, and Google Cloud.
Private Service Connectivity (PSC) allows for one-way secure connection access from your VPC to Confluent Cloud with added protection against data exfiltration. Confluent exposes a Private Service Connect endpoint for each new cluster, for which customers can create corresponding endpoints in their own VPCs on Google Cloud. Making dozens or hundreds of PSC connections to a single Confluent Cloud cluster doesn’t require any extra coordination, either with Confluent or within your organization. This networking option combines the highest level of data security with ease of setup and use.
The benefits of using Private Service Connect include:
- Simplified and highly secure private networking setup minimizing the complexity of connecting virtual networks in the public cloud
- Reduced networking burden for IT teams from having to coordinate on IP address challenges while keeping all details about a customer’s network private
- Improved developer productivity through integration of private service connect resources into Confluent Terraform provider
Get started with Google Cloud Private Service Connect today.
Other features in the Confluent Cloud launch
Higher throughput and scalability with serverless clusters: We increased our throughput for basic and standard clusters from up to 100 MBps for ingress and egress to 250 MBps for ingress and 750MBps for egress (up to 1GBps combined), a 5x increase and improved fanout ratios (1:3). We also increased partition limits to 4,096, which is ~40x higher than any hosted Kafka service provider, making it easier to scale workloads than ever before.
Terraform exposure and other stream processing updates: To simplify stream processing and help you generate even more value from your Apache Kafka data, we’ve launched more stream processing updates on ksqlDB. Provision and manage ksqlDB clusters with Confluent Terraform Provider, allowing you to use ksqlDB as part of your infrastructure-as-code pipelines. For more details, check out the new ksqlDB CRUD API Quickstart and reference guide.
You can also write stream processing queries faster and with less effort by automatically converting existing topics into streams within ksqlDB. Plus, we’ve increased our CSU offering to 28, so now you can process up to 1,000,000 messages per second.
Start building with new Confluent Cloud features
Ready to get started? Remember to register for the Q4 ‘22 Launch demo webinar on November 10th where you’ll learn firsthand how to put these new features to use from our product managers.
And if you haven’t done so already, sign up for a free trial of Confluent Cloud. New sign-ups receive $400 to spend within Confluent Cloud during their first 60 days. Use the code CL60BLOG for an additional $60 of free usage.*
The preceding outlines our general product direction and is not a commitment to deliver any material, code, or functionality. The development, release, timing, and pricing of any features or functionality described may change. Customers should make their purchase decisions based upon services, features, and functions that are currently available.
Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc.
Apache® and Apache Kafka® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks. All other trademarks are the property of their respective owners.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...