Multi-Region Clusters with Confluent Platform 5.4
Running a single Apache Kafka® cluster across multiple datacenters (DCs) is a common, yet somewhat taboo architecture. This architecture, referred to as a stretch cluster, provides several operational benefits and unlocks the door to many uses cases. Stretch clusters provide better durability guarantees and make disaster recovery much easier by avoiding the problem of offset translation and restarting clients. However, in order to operate a reliable stretch cluster, datacenters must be relatively close to each other and have a very stable, low latency, and high-bandwidth connection among the DCs.
This changes with the release of Confluent Platform 5.4, which includes Multi-Region Clusters built directly into Confluent Server. Now operators can choose to replicate data on a per-region basis, synchronously or asynchronously, per topic. This functionality allows operators to increase data durability and automate client failover in the event of a disaster.
To utilize Multi-Region Clusters, three distinct features are necessary: Follower Fetching, Observers, and Replica Placement.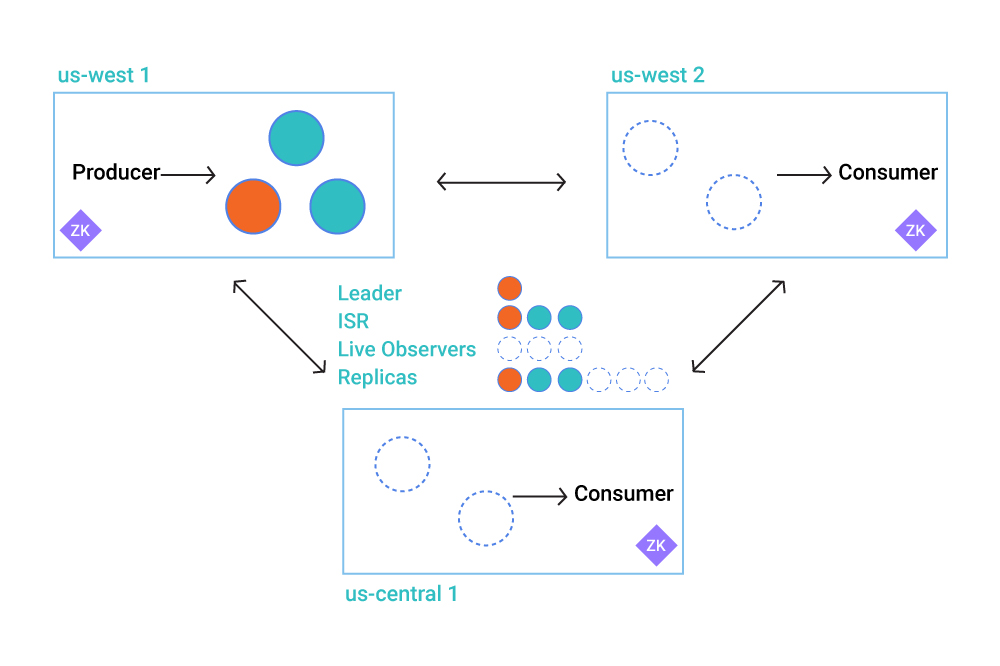
Follower Fetching
Follower Fetching, also known as KIP-392, is a feature of the Kafka consumer that allows consumers to read from a replica other than the leader. The motivation for this KIP was to allow consumers to reduce expensive cross-WAN traffic in a multi-datacenter environment. The Kafka broker has long had rack awareness for balancing partition assignment across multiple logical “racks,” but that’s as far as the “awareness” went. With KIP-392, consumers can read from local brokers by supplying their own rack identifier when first talking to the leader.
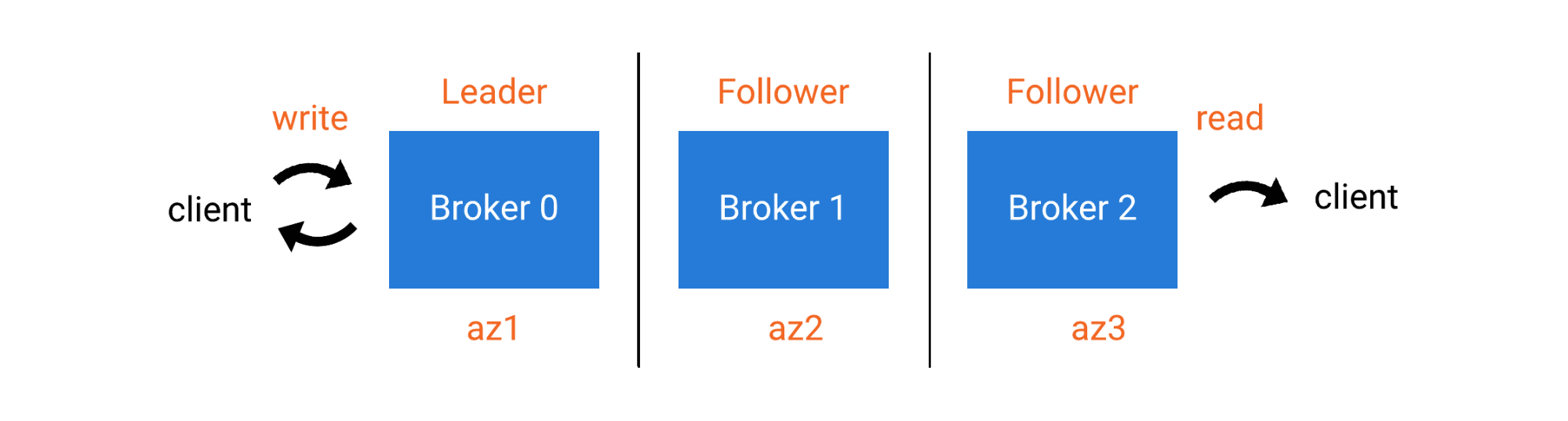
The algorithm follows this sequence:
- Brokers configure broker.rack and replica.selector.class
- Consumers configure client.rack
- One consumer makes a fetch request to the leader
- If the partition is rack aware and the replica selector is set, pick a “preferred read replica”
- The consumer starts reading from the preferred read replica
- Periodically, the consumer checks back with the leader for a refreshed replica selection
For now, Apache Kafka has a single implementation of the replica.selector.class, which is a rack-aware selector. This class was intentionally made into a pluggable interfaces so users can supply their own implementation depending on their needs.
In a multi-datacenter cluster, network ingress and egress can be very costly—certainly more costly than network traffic within a datacenter. Cost here can mean dollars of course, but it also means latency and throughput. Even if a cluster is contained within a single datacenter, the traffic within a single rack will have lower latency than it would between racks. Certainly, a Kafka cluster spanning multiple datacenters will have significantly higher costs for network traffic between datacenters than within a given datacenter. By allowing consumers to read from the closest replica, we are able to leverage data locality. This means better performance and lower cost.
Observers
Observers in Confluent Platform are effectively asynchronous replicas. They replicate partitions from the leader like followers, but an observer can never participate in the in-sync replica (ISR) list or become a partition leader. What makes them asynchronous is that, since they never join the ISR, they are never considered when we increment the high watermark. Let’s explore that for a moment.
When writing data to a partition in Apache Kafka, the preferred configuration is to set the acks producer configuration property to all. This causes the producer to wait until all members of the current ISR acknowledge the written record(s). Essentially, this is how Apache Kafka provides durability.
Previously, any replica not belonging to the ISR was considered out of sync. As long as the number of replicas in the ISR is at or above the min.isr value for that partition, the partition is considered healthy and the durability requirement is satisfied. Now with the introduction of Observers, there is a replica type which could be in sync but will never join the ISR. This provides us with a replica type that replicates data like normal, but does not affect durability semantics and cannot become a leader. Observers give us these benefits:
- Improved durability without sacrificing write throughput
- Replicates across slower/higher-latency links without falling in and out of sync (also known as ISR thrashing)
- Complements Follower Fetching (described above)
Even though an Observer may lag behind the leader replica, all of its records are valid, and it knows which records should be visible according the partition’s replication semantics. This means we can safely read from an Observer using Follower Fetching as described above.
Observers are also useful for disaster recovery, specifically in cases where an Observer is located in a secondary datacenter and the rest of the replicas are in a primary datacenter. Potential leaders in a disaster recovery scenario do not affect replication during normal operation.
Replica Placement
Replica assignment in Apache Kafka has so far been limited to three strategies: round robin, rack-aware (KIP-36), and manual assignment. In order to complement the new Observers feature, and to further enable practical multi-datacenter deployments, we have created a new replica placement strategy for Confluent Platform. This JSON-based specification allows you to specify replica assignment as a set of matching constraints. Each placement also has a minimum count associated with it that allows users to guarantee a certain spread of replicas throughout the cluster.
For example, two replicas in region-a and one observer in region-b would be specified as:
{
"version": 1,
"replicas": [
{
"count": 2,
"constraints": {
"rack": "region-a"
}
}
],
"observers": [
{
"count": 1,
"constraints": {
"rack": "region-b"
}
}
]
}
In this case, by keeping the regular replicas in a single region and putting an observer in a different region, the partitions will have synchronous replication semantics within region-a but also asynchronously replicate to an observer in region-b.
An example of synchronous replication between region-a and region-b:
{
"version": 1,
"replicas": [
{
"count": 2,
"constraints": {
"rack": "region-a"
}
},
{
"count": 2,
"constraints": {
"rack": "region-b"
}
}
]
}
This is very similar to using rack-aware replica assignment except more precise counts of replicas in each rack can be given.
In Confluent Platform 5.4, the only included constraint type is matching on the broker’s broker.rack attribute (shown as the rack property in the above examples). Note that the “rack” here does not have to represent a physical datacenter rack, but rather it is a generic label used to represent the location of a node. Since multi-region and multi-zone Kafka clusters are likely to use the rack-aware partition assignment, we chose to reuse this broker configuration for our replica placement constraints. More robust node-to-replica matching is on our roadmap for future releases.
Multi-region ZooKeeper
No multi-datacenter conversation would be complete without mentioning ZooKeeper. For the “two datacenters” use case (one primary datacenter with a remote, standby datacenter), the current best practice is to deploy ZooKeeper nodes to each of these datacenters as well as a third “tie-breaker” datacenter. This is sometimes referred to as a 2.5 datacenter topology. The Kafka brokers are deployed to the two datacenters of interest, and a third datacenter is used only for the third ZooKeeper node. With this deployment, the cluster can lose a single datacenter without becoming unavailable.
The primary concern when deploying ZooKeeper across multiple regions is increased latency. In Kafka, the data being written to ZooKeeper is generally quite small, so there is not much concern about the throughput of data. The concern is that the system incurs additional fixed overhead as ZooKeeper nodes negotiate consistency on whatever metadata changes might happen in the cluster. Particularly, the write performance of ZooKeeper decreases rapidly as latency between the members of the quorum increases.
However, when Kafka is in a steady state of producing and consuming records without metadata changes, broker failovers, or deploying new consumers, there is not much interaction with ZooKeeper. This means that overall throughput should not be strongly affected by ZooKeeper latency, although any reduced bandwidth across a inter-datacenter link can affect replication performance depending on the partition’s configuration.
Where the additional ZooKeeper latency does come into play is for cluster operations like creating and deleting topics, leader election, reassigning partitions, or joining a consumer group. In particular, we have observed long delays when deleting a large number of partitions in a multi-datacenter cluster, so proceed with caution there.
Somewhat related to this is the proposal to remove ZooKeeper from Apache Kafka altogether. As of the time of this writing, the long-awaited KIP-500 is under discussion on the Kafka mailing list. It is just in the planning phases now, but, like most features, multi-DC replication will benefit from the scalability and decrease in operational overhead that KIP-500 will bring once it has been implemented.
Putting it all together
Running a single Kafka cluster across multiple regions has long been a desired architecture because it significantly streamlines disaster recovery and infrastructure operations. However, this architecture was only viable if data centers were very close to one another because of the cost to throughput, the operational overhead of dealing with replica placement, and the volume of cross-DC traffic the architecture creates. Confluent Platform 5.4 changes all of that.
By using observers and replica placements, partitions can failover to a secondary datacenter without requiring a human operator to issue more than a few CLI commands. This means that there are no networking changes, client restarts, or offset translations to worry about, and no one needs to write any custom code to make it work.
Follower fetching with observers allows users to benefit from read locality without losing write performance. This helps cut down on expensive inter-datacenter WAN traffic from consumers and in turn reduces latency between the clients and the observer replicas.
Want to learn more?
- See the Confluent Platform 5.4 documentation to get started
- Try the demo showcasing Multi-Region Clusters built directly into Confluent Server
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...