Messaging Modernization with Confluent
Messaging middleware and queues make up a significant portion of legacy enterprise data architectures. Those architectures are buckling under the strain of a range of new requirements involving data volumes and scalability, fault tolerance, cloud migrations, heterogeneity of data sources and metadata, and more.
Originally conceived as a message queue, Apache Kafka® provides publish/subscribe messaging at scale, so it begins to address these requirements. However, Kafka alone isn’t sufficient to meet the messaging needs of today’s businesses. In addition to publish/subscribe capabilities and scalability, there are also requirements to connect to a broad array of external systems, easily merge and join related data from different sources into the same environment, process the resulting stream, and manage metadata along the way—all in an easily manageable or fully managed environment. Confluent provides a cloud-native messaging infrastructure that meets modern messaging requirements, enabling businesses to modernize their existing messaging architecture in incremental steps.
We’ll be covering the key capabilities that show that at the end of the day, Kafka is much more than simple messaging or pub/sub. We’ll also demonstrate how you can easily integrate Confluent with messaging middleware to begin unlocking data for new use-cases. Before we get to that, let’s take a step back and look at what a typical legacy messaging architecture looks like.
Context
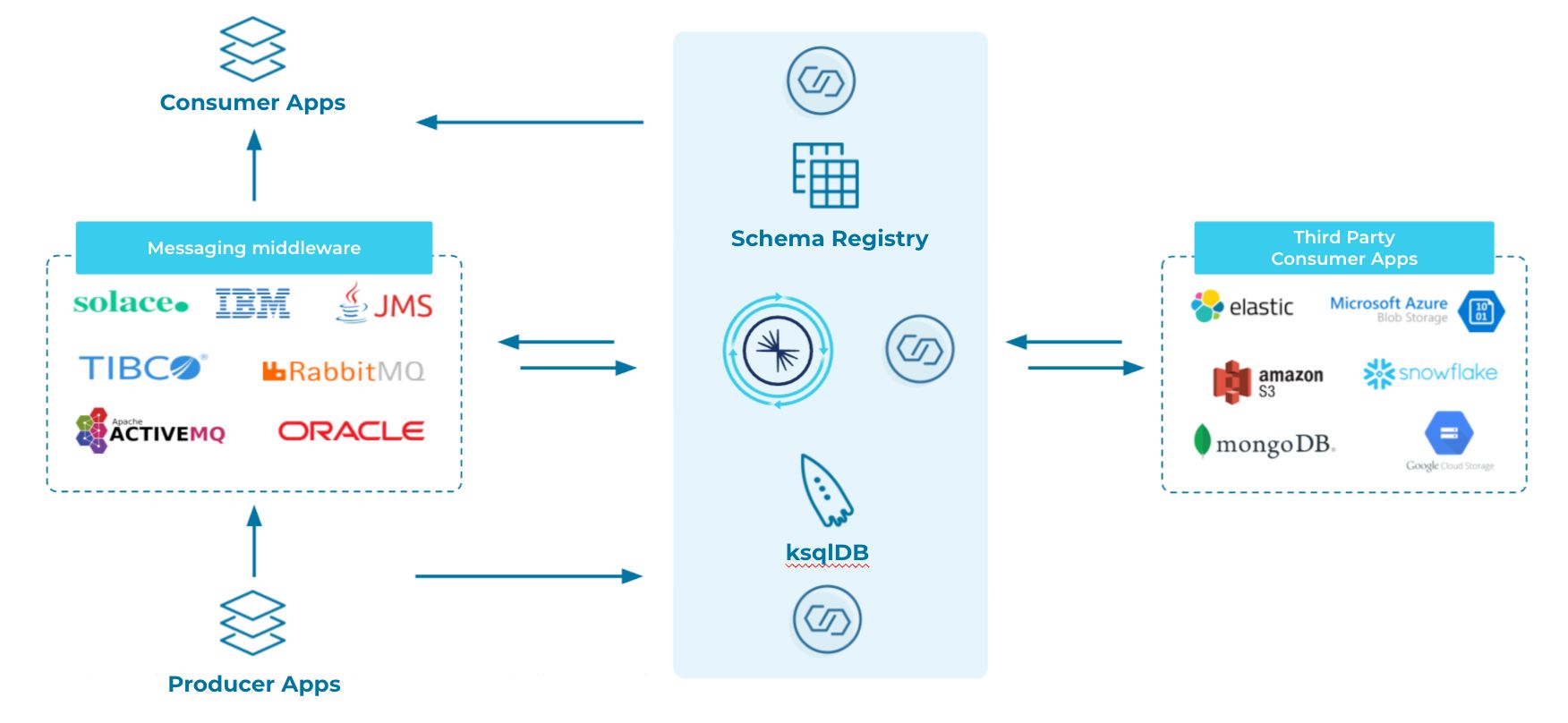
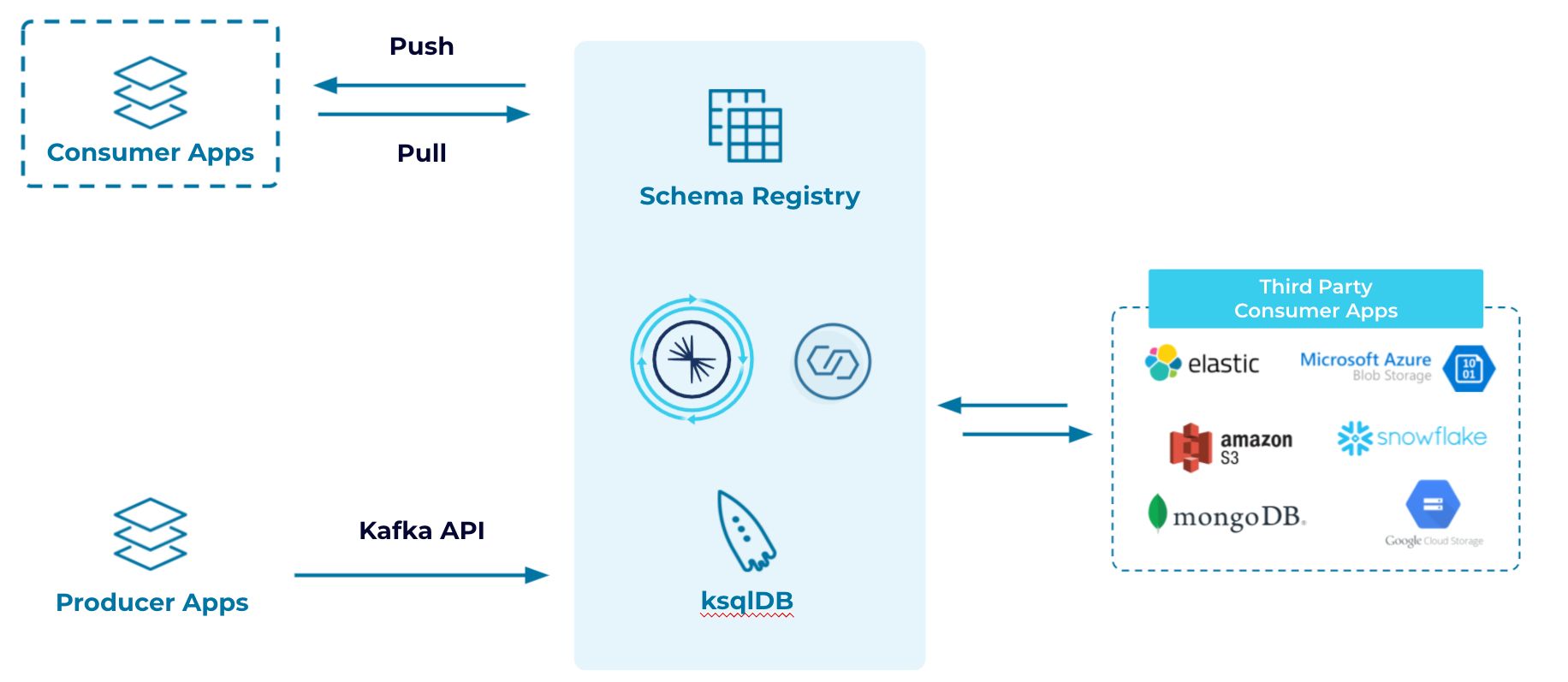
A typical messaging architecture is shown below:
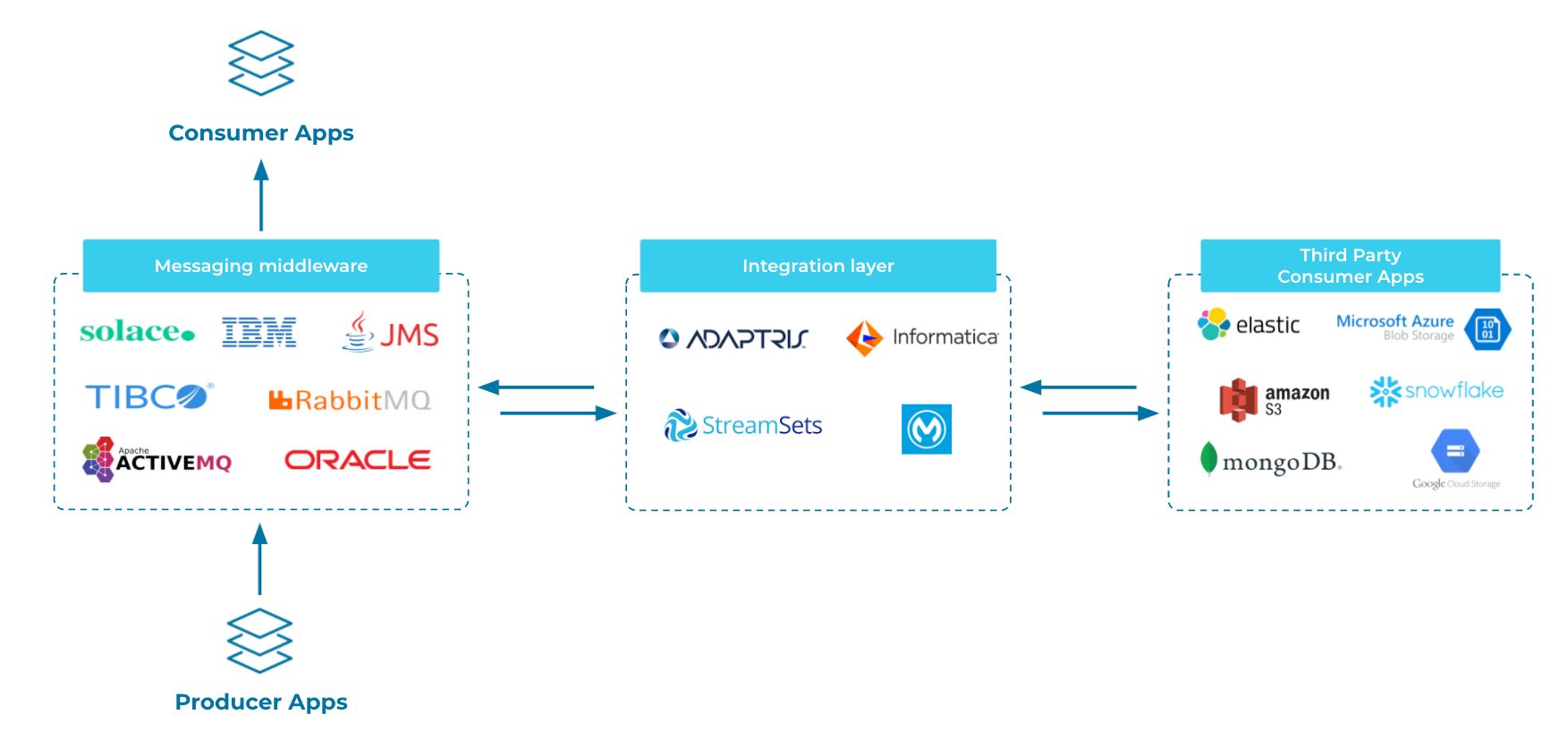
These architectures usually consist of:
- Messaging middleware: MQs such as RabbitMQ, ActiveMQ or TIBCO. It may also be Enterprise Service Bus systems (such as Oracle System Bus) between the producer and consumer applications.
- Integration layer: Transforms your data and feeds it to third party consumer applications on-premises or on the cloud (using, for example, Adaptris, Informatica, IBM, Streamsets or Mulesoft).
While this setup is suitable for many use cases, it does come with some issues around costs and complexity. Environments like this can require a large number of licenses, one for each of the middleware and integration layer systems. This can add up to a significant sum. Also, this setup is quite complex since maintaining and updating these various systems is a huge time sink and takes up valuable IT resources. Additionally, cloud migrations, multi-datacenter, or cross-region support are difficult to manage.
But messaging isn’t just about packing bytes onto a queue for large-scale downstream consumption. Standardizing connectivity, managing metadata, and stream processing are increasingly important as application architectures such as decoupled microservices and use cases like IoT take hold.
Also, these legacy messaging architectures aren’t cloud native. While it’s possible to move some or all of this pipeline to the cloud, it’s a piecemeal endeavor. Some components are much more costly and time consuming to migrate than others, and the benefits of running in the cloud are inconsistently realized.
Confluent provides critical capabilities above and beyond simple messaging, which we’ll leverage in an example described below.
Standardized connectivity
Standardized connectivity is provided with the Kafka Connect framework and the community of connectors available on Confluent Hub. We typically consider connectors for databases like Oracle, Snowflake, or MongoDB Atlas, but they’re equally applicable for pulling data from messaging systems in a code-free, configuration-driven way. Confluent provides fully managed connectors in Confluent Cloud as well as self-managed connectors for systems such as AWS SQS, IBM MQ, ActiveMQ, TIBCO EMS, RabbitMQ, and others. Kafka Connect can consume messages from any messaging platform and transform them into a standardized format, such as Apache Avro or Protobuf. This simplifies and standardizes the mechanism of consumption for downstream clients. You can fully decouple, standardize, and govern data across your systems and democratize data access for each of your consumers.
Metadata integration and data governance
Confluent Schema Registry, available as a fully managed service and as a self-managed software, is relevant to every producer that can feed messages to your Kafka cluster. Every application serializes messages for delivery to the Kafka data pipeline. Confluent’s Schema Registry is integrated into that serializer. The serializer makes a call to Schema Registry to see if it has a schema for the data the application wants to publish. If it does, then Schema Registry passes that schema to the application’s serializer, which uses it to encode the message as raw bytes. When you use the Confluent Schema Registry, it’s automatically integrated into the serializer with no manual effort needed. As a result of this, your data pipelines will contain well-structured events with self-documenting schemas. You simply need to have all applications use the serializer when publishing. By managing both the schema and the messages, Confluent can ensure the context of the data travels with it, even through a complex and heterogeneous data pipeline.
But if you’ve worked with messaging systems a lot, then you know that while standardized metadata is nice, it’s not enough. In addition to centralized schema registration, we provide governance, including data lineage capabilities, data flow diagrams, and audit logs. We also offer the ability to establish and enforce data contracts, where Confluent enforces server-side schema compatibility to ensure that messages published to and stored in Kafka always conform to a predefined schema (if they do not, they are rejected). This is a crucial feature particularly for larger enterprises with compliance and legal requirements where a wishful “please follow our conventions” plea to the developers and systems involved is not going to work.
Processing and analyzing data in motion the easy way
Apache Kafka is used for storing and transmitting event streams. But how can developers work with these streams easily? How can we, say, perform real-time analytics or drive continuous intelligence on customer data?
Here, the streaming database ksqlDB lets you quickly build robust and complete applications that process, filter, aggregate, and transform streams and tables of data with a lightweight SQL syntax. You can use ksqlDB as a fully managed service in Confluent Cloud, or run it yourself. As we’ll see in the example walkthrough, ksqlDB gives the power to join and enrich data in motion from different parts of the organization regardless of the source system in real-time in the large scale of data volumes that businesses today have to deal with.
There are ways of processing and aggregating data flowing through message-oriented middleware and message queues. However, the method will be specific to the message queue and may be unable to utilize the capabilities brought by Kafka, such as persistence and replayability. This makes it impossible for any aggregation coming out of a single queue to be authoritative or complete. While any single queue might offer the ability to process or aggregate the data in that queue with low latency, or the ability to connect to a third-party data source to ingest a stream, you’ll be hard-pressed to find the combination of broad connectivity, persistent event streaming at scale, and accessible SQL-based stream processing that you can have with Confluent. You need all of it in order to meet modern requirements: A platform that can stream events from any queue or third-party system, in use now or in the future, while also serving as an authoritative and persistent system of record that can scale to handle arbitrarily large data volumes, and can process and aggregate those streams in real time regardless of source.
Fully managed as a cloud service
Confluent Cloud provides all of these capabilities—connectors, Schema Registry, ksqlDB, etc.—in a fully managed, elastically scalable cloud service. You can get started with the example walkthrough below for a proof of concept and scale it to production without having to come up the learning curve of hosting, managing and maintaining your own distributed systems infrastructure.
Example walkthrough
We provide a documented packaged example of Messaging Integration with Confluent which you can use to get started. The example leverages connectors for ActiveMQ, IBM MQ, TIBCO EMS, and RabbitMQ to turn their data into Kafka-compatible event streams, and ksqlDB for processing these streams in real-time—setting you up to stream data to a modern sink such as Elastic Cloud, Snowflake, or MongoDB.
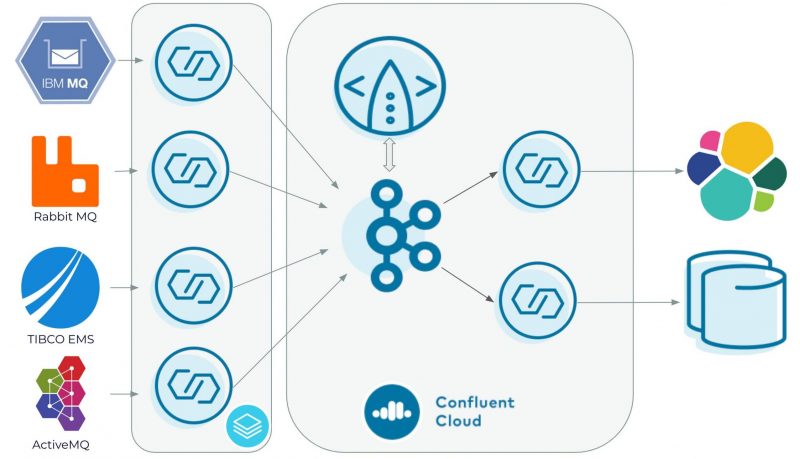
In this example:
- Connectors continuously import and export data between Confluent and third party systems, including message queues and databases. In this case, we take care to automatically infer the source schema and register it with Confluent Schema Registry. This process is the same regardless of source.
- ksqlDB runs continuous ‘streaming’ queries to extract fields of interest, apply data types, provide abstraction, define new streams, and combine them—all in real-time. We extract fields out of JSON-formatted data that originates from multiple message queues. Then we cast the fields into types. For example, we extract an id field from JSON, convert it to a field in an event, cast it to an int, and make it a primary key which is used in a join. In doing this, we also clean the data, removing the queue-specific references allowing us to more easily reason about the data. Then we can combine the streams with either a UNION or a JOIN clause, even though they originally live in separate and unaffiliated messaging systems.
We extended cp-all-in-one to include ActiveMQ, TIBCO EMS, IBM MQ, and RabbitMQ as well as their source connectors. We also expanded it to optionally use Confluent Cloud for Kafka, Schema Registry, and ksqlDB, making the docker footprint significantly lighter. The example walkthrough also includes an on-prem option which runs the message queues, their source connectors, ksqlDB, and Kafka along with Confluent Control Center within your local system as cp-all-in-one originally intended.
The idea behind this example walkthrough is to accustom you to integrating messaging systems of your choice with Confluent, and to concretely illustrate the value of a complete data in motion solution with respect to messaging systems. Once you’ve worked with the walkthrough, you’re encouraged to follow the pattern it set forth within your own environment. At the conclusion of the exercise you should feel very confident integrating any messaging system with Confluent. This allows you to unlock the value in integrating data from messaging systems for new use cases, such as building real-time customer applications or with cloud-based applications.
Below is the Schema Registry in Confluent Cloud showing the registered schema from the message queue systems. In this case, the end user didn’t have to do anything besides configuring the example to point at a specific Confluent Cloud URL. The schema was inferred by the connector when the data was serialized to Avro and then automatically registered to the provided schema registry, which happened to live in Confluent Cloud:
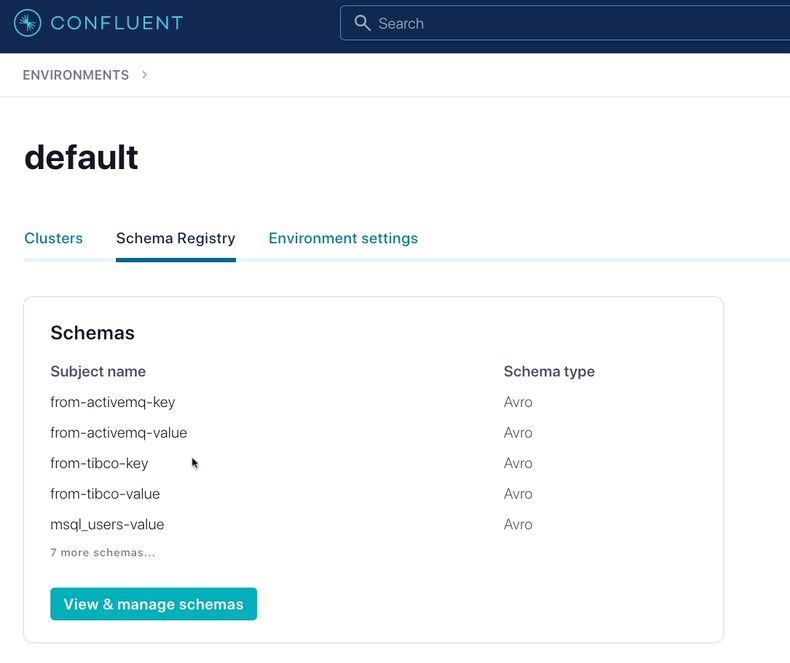
As additional streams are derived in ksqlDB, those schemas are registered automatically as well. This ensures integrity as data from different sources start to interact with each other. Neither the end user nor the developer have to work here, it just happens. But you can see the registered schema in each step if you need to:
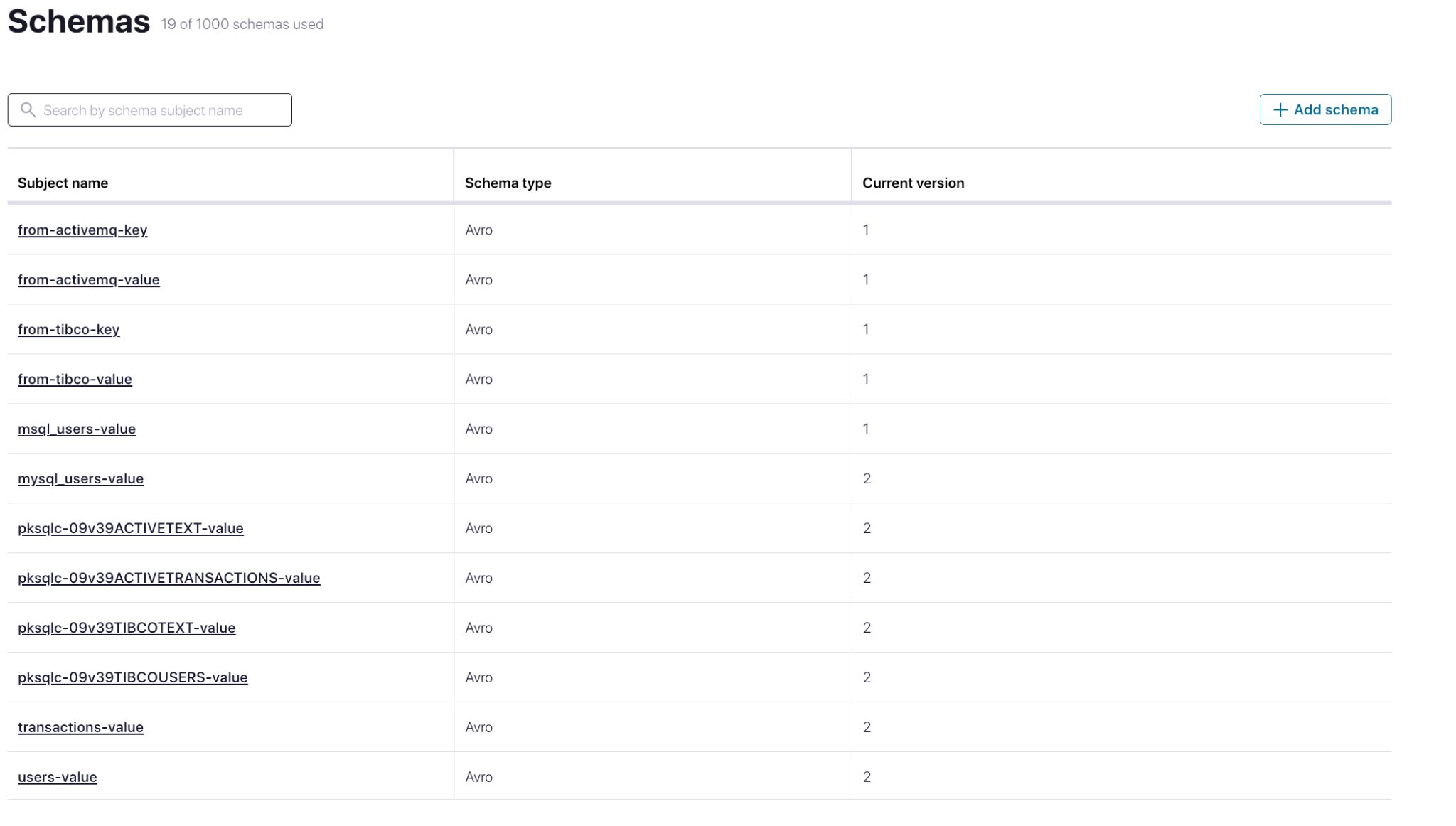
ksqlDB in Confluent Cloud includes a data flow diagram which visualizes each transformation step. In this case, we’re processing event streams from TIBCO and ActiveMQ, but this logic will work equally well with data from any message queue (no modifications needed).
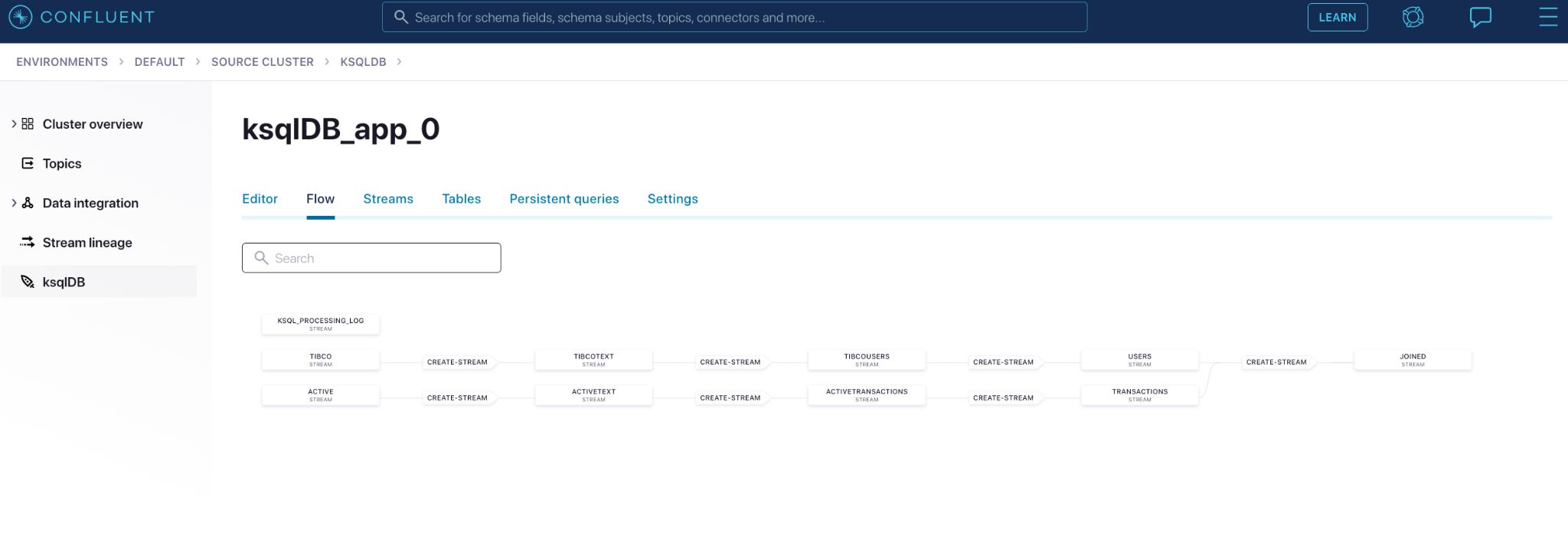
While the above example showcases a join between two data streams from two message queues (TIBCO and ActiveMQ, respectively), joins aren’t the only thing you can do. You can also combine more streams from more queues. Below, we do that in Confluent Platform, combining streams from IBM MQ, ActiveMQ, TIBCO EMS, and RabbitMQ. The interface of the Confluent Platform is just like Confluent Cloud’s, demonstrating that the context switch between self-managed and fully managed Confluent is very easy.
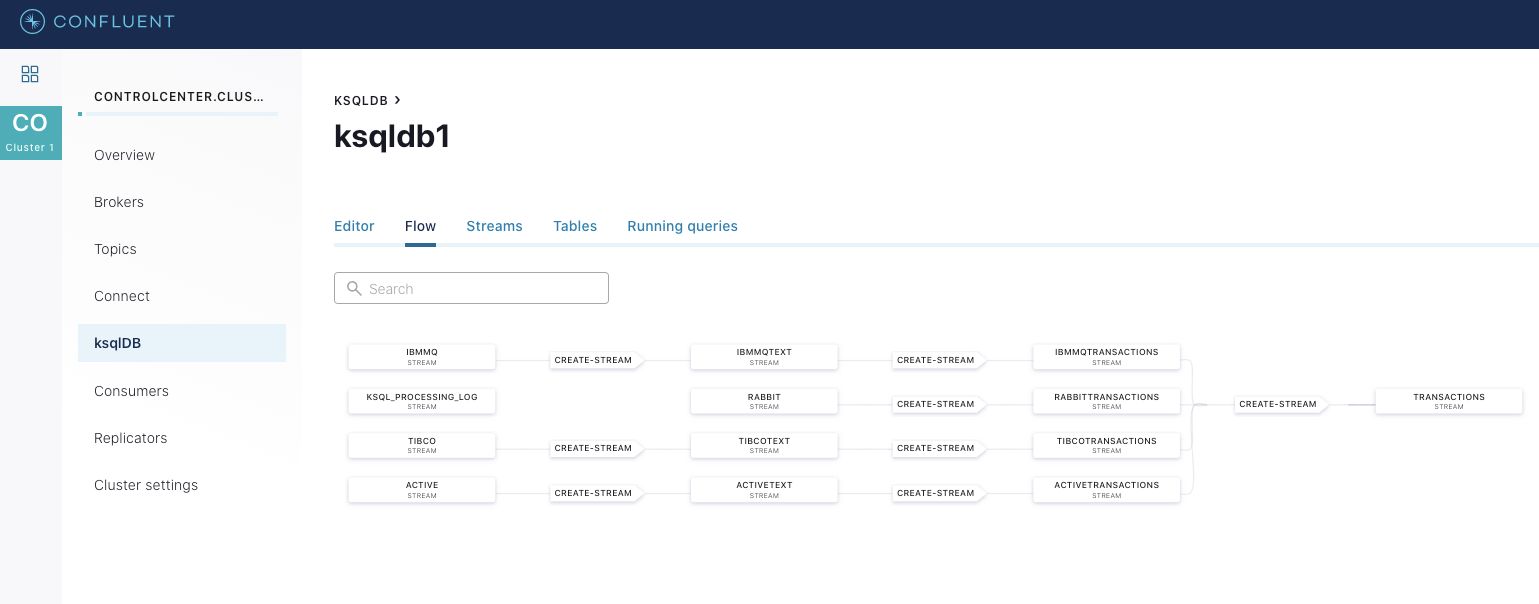
Confluent also shows you the created streams as well as their underlying Kafka topics. As you can see, the data is well isolated in each step. Every stream defined in ksqlDB has a registered schema that’s shown here, even intermediary streams that are derived from other ones:
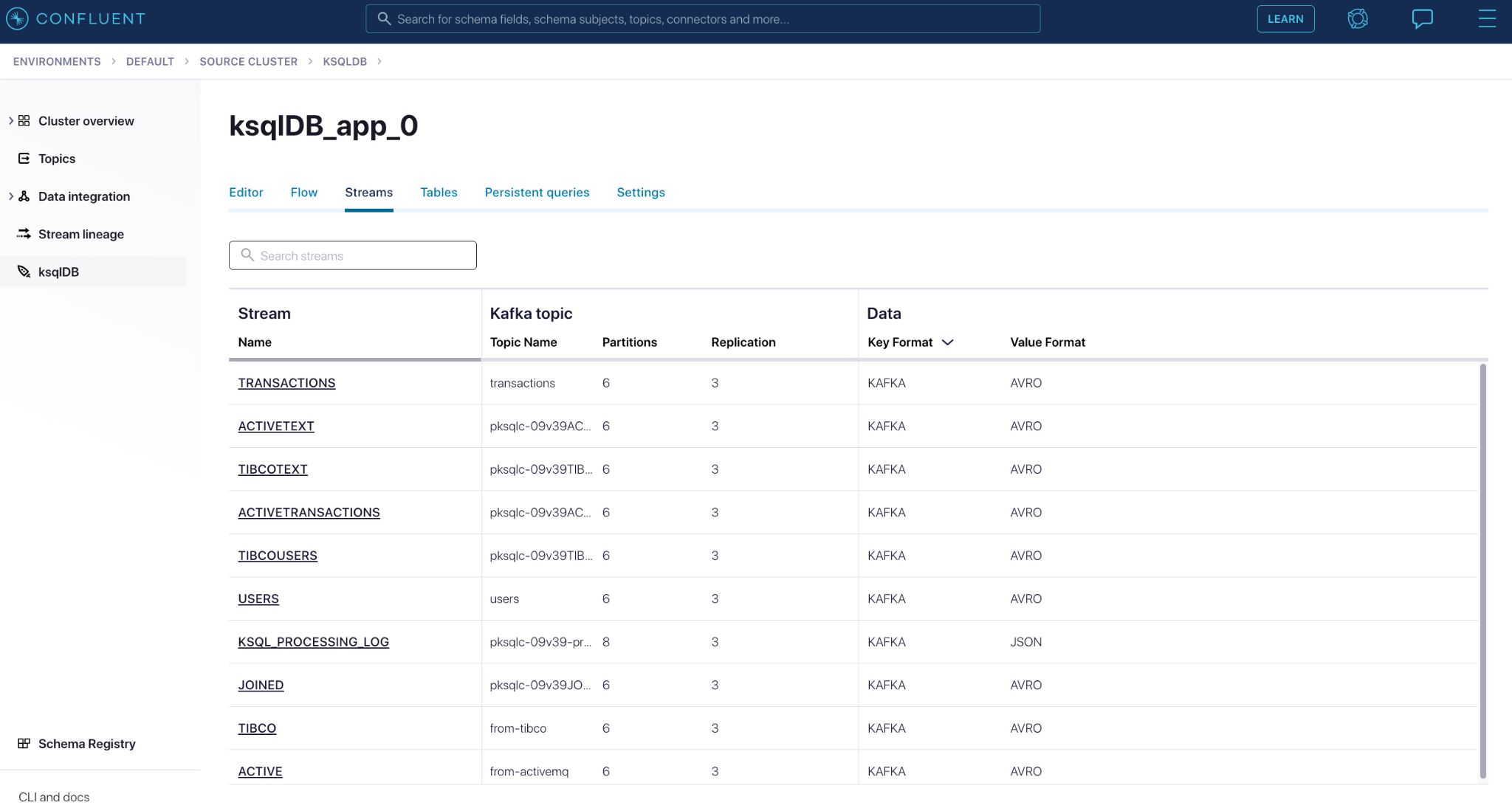
And of course, you can also introspect the specific queries, allowing you to break complex processing operations of different streams into simple operations and revisit them. Here’s how to create new streams in Confluent Cloud:
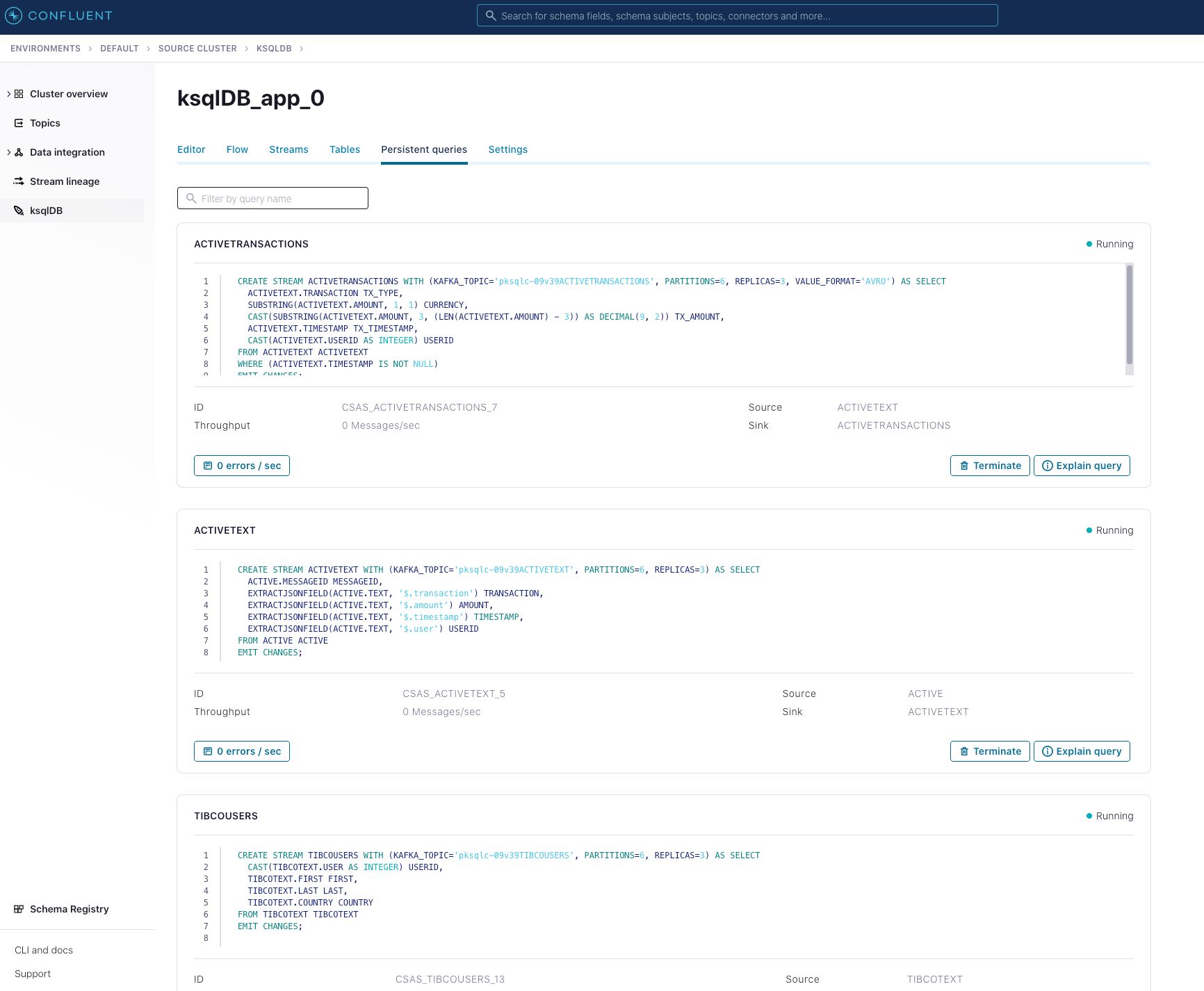
When running in the Confluent Platform, you can see this interface in Confluent Control Center, where it’s almost identical.
Plus, our new data lineage interface in Confluent Cloud shows you the data flowing from the messaging systems and joining together in ksqlDB at a high level.
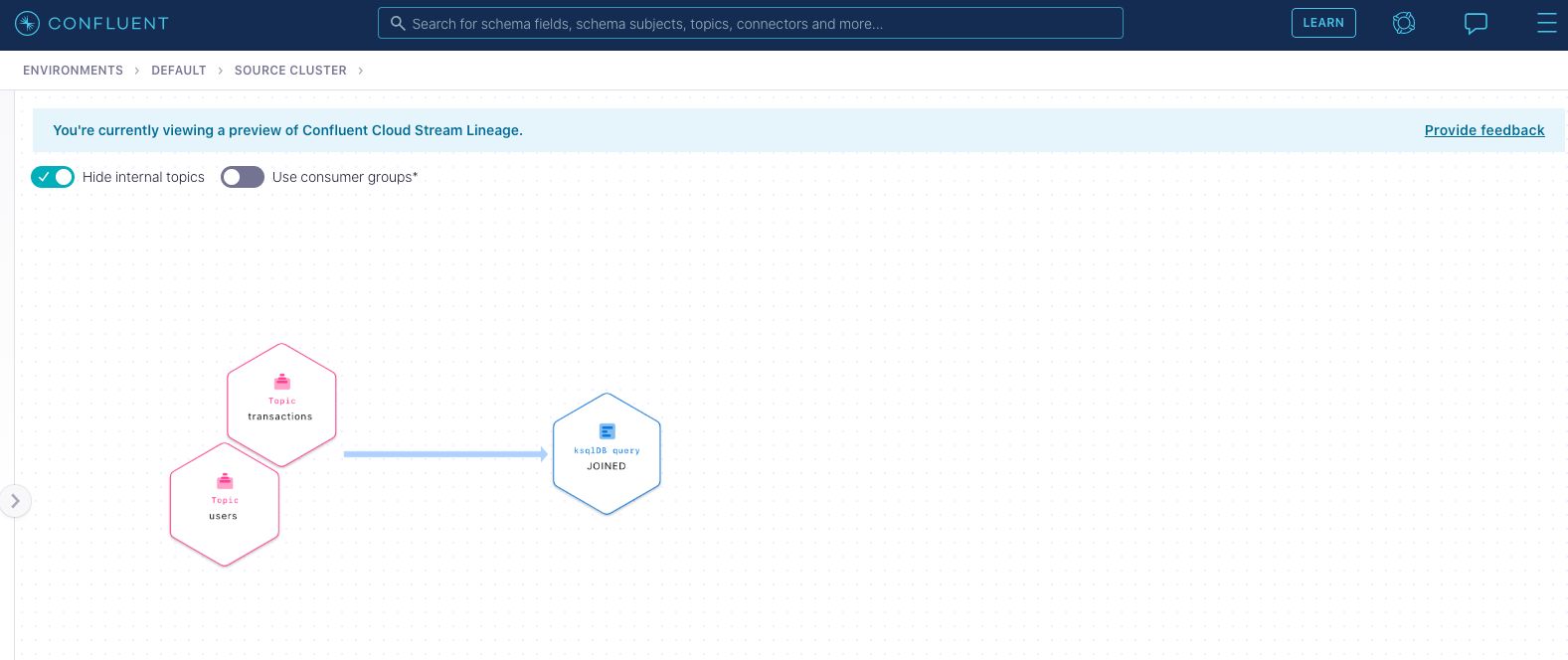
In our example this is a pretty simple flow, but one can imagine using this interface to make sense of all of your data flows as complexity increases.
This example presumes on-prem messaging systems, so we co-locate and self-manage Confluent Platform, including Kafka Connect, the connectors themselves, and Confluent Control Center, which has a similar interface to Confluent Cloud. Below we see Confluent Control Center showing the status of self-managed source connectors to message queues and a self-managed sink connector to Elastic (although if you need to, you can also use a fully managed sink connector in Confluent Cloud to Elastic Cloud):
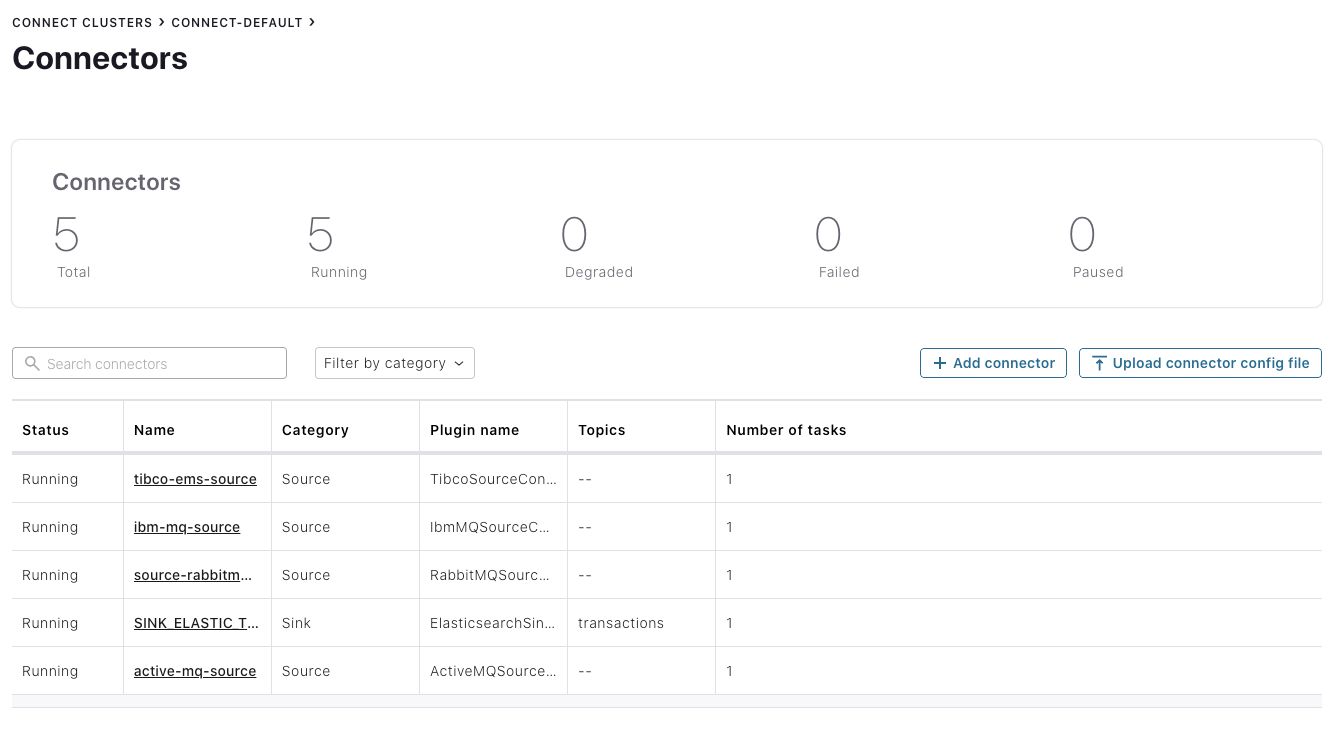
We encourage you to check out the associated whitepaper where we walk you through this in more detail to the level of a tutorial, providing a base from which to launch your own messaging integration/migration proof of concept exercises and then evolve them to production.
Real-world messaging modernization
Of course, once you’ve gone through the tutorial to prove the concept, it’s important to develop a long term modernization strategy that’s effective and non-disruptive to your business.
Step 1: Connect Confluent to existing messaging infrastructure
Confluent can be gradually introduced into an organization and can bring value without replacing or displacing any existing technology. This is the strategy we recommend for integration with messaging systems. You can start migrating your producer or consumer applications to connect to Confluent using our wide array of pre-built source (for connecting to producer apps) and sink (for connecting to consumer or third party apps) connectors. The experience is the same whether you’re moving data from message queues on-prem to Confluent Cloud or whether you’re using Confluent Platform on-prem.
The ability of Apache Kafka to non-destructively permeate an organization allows you to keep your existing messaging middleware at the center of the rest of your architecture. This enables the use of stream processing from Confluent for the creation of curated streams. It also allows multiple independent consumers, historic data replayability, and transactions. This will also introduce the ability to send aggregate data to any connected destination, including third party systems such as data lakes, real time dashboards, or BI tools informed by the registered schema, as discussed in the provided example.
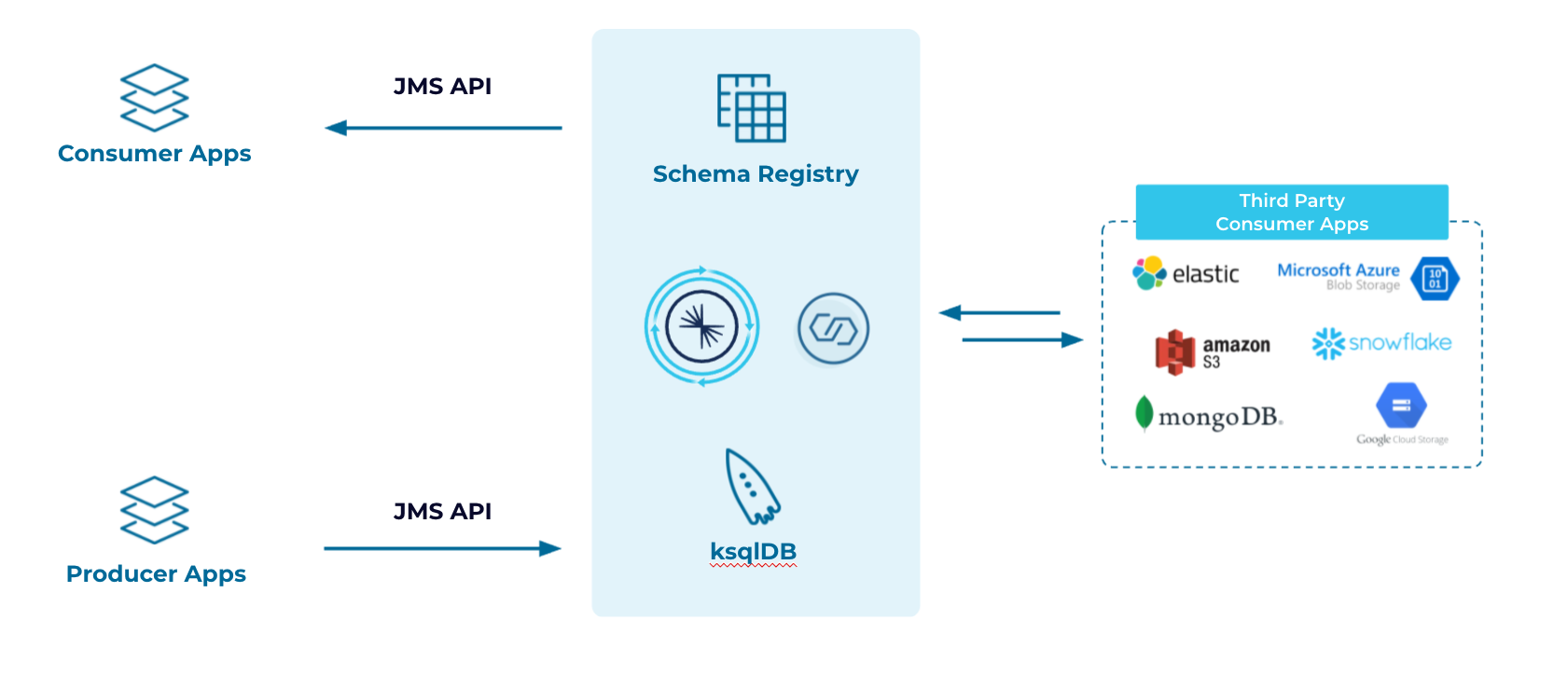
The architecture now looks something like this, with the Confluent bits being either in Confluent Cloud or self-managed with Confluent Platform:
Over the medium to longer term, you can start making minor modifications to existing consumer and producer applications that populate the messaging systems. We’ve found that since it’s widely in use already, applications that use JMS are a good place to start. With minor tweaks, applications that consume or produce using JMS can work with Confluent by simply changing their targets. You can accelerate your cloud migration by using our fully managed Confluent Cloud connectors to deliver events to specific endpoints; Elasticsearch, Snowflake, and MongoDB are just a few of our available connectors.
You can start replacing messaging middleware in this phase. All of the data you write will land in Kafka topics, but as far as your applications are concerned, they are talking to JMS Queues and Topics. You can also combine the most common enterprise messaging patterns (such as point-to-point or publish/subscribe routing semantics) with exactly-once delivery semantics, multi-stream transactions, a durable log, and replayability from Confluent.
Step 2: Retarget consumer and producer apps incrementally
Now that you’re set on a path to simplify your data architecture, you will already be reaping reduced costs with respect to licensing, operating expenses, risk and indirect costs—incurring additional savings over time. You’re also reaping the benefits of a future-proof architecture since it includes automatic load balancing, containerization, multi-data-center support, and high availability, fault tolerance, and horizontal scalability with a complete fully managed, cloud-native option.
At this point, you can start retooling and refactoring consumer and producer applications that utilize message queues to take advantage of Confluent. Applications that already utilize JMS to read and write to queues are a good place to start, since they can be easily retargeted to Confluent. Applications that don’t use JMS already can be ported to use our APIs in a subsequent step. Apache Kafka lends itself well to incremental adoption. You don’t need to cut over your entire infrastructure in one fell swoop in order to be effective.
Step 3: End-to-end data in motion with Confluent
Lastly, shift off of JMS completely and create more scalable streaming applications with new event-driven patterns, using ksqlDB for event notifications, event carried state storage, event sourcing, and command query responsibility segregation (CQRS) with read-only materialized views. You can also start seeing end-user performance improvements by leveraging the scale and distributed nature of Apache Kafka on the client side by incorporating the parallel consumer. You now have a future-proof and simplified messaging and integration cloud service at your disposal.
Get Started
For a live demo using the steps outlined in this blog, sign up for our webinar Evolving from Messaging to Data in Motion.
Have questions about how Confluent compares to traditional messaging systems from an architectural perspective? Check out this whitepaper for more detail.
For more information on Confluent’s solution for messaging modernization, see our solutions page.
For the detailed and reproducible walkthrough of messaging integration with Confluent, see the whitepaper and associated github repo.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Beyond Boundaries: Leveraging Confluent for Secure Inter-Organizational Data Sharing
Discover how Confluent enables secure inter-organizational data sharing to maximize data value, strengthen partnerships, and meet regulatory requirements in real time.



Real-Time Toxicity Detection in Games: Balancing Moderation and Player Experience
Prevent toxic in-game chat without disrupting player interactions using a real-time AI-based moderation system powered by Confluent and Databricks.