Flink で「調理」:Flink を使ったリアルタイム検索拡張生成 (RAG) をマスター
商用およびオープンソースの大規模言語モデル (LLM) は急速に進化しており、開発者は生成 AI を活用した革新的なビジネスアプリケーションを作成できるようになりました。ただし、プロトタイプから本番環境に移行するには、ビジネスニーズに合わせた正確でリアルタイムのドメイン固有のデータを統合し、強固なセキュリティ対策を講じて大規模に展開する必要があります。
すぐに古くなる可能性のある静的な事前トレーニング済みデータに依存すると、不正確さや「ハルシネーション」につながる可能性があります。さらに、LLM は、文脈に関連した的確な回答を生み出すために重要となる、分野特有の知識を理解し、統合することに苦労することがよくあります。
その結果、生成 AI システムのパフォーマンスと信頼性を高めるために、リアルタイムでコンテキスト固有のデータを提供できる方法の必要性が高まっています。ここで検索拡張生成 (RAG) が役立ちます。RAG は、ライブデータストリームを AI モデルと統合し、生成された出力の正確性と関連性を保証する有望なソリューションを提供します。
このブログでは、Confluent Cloud で Apache Kafka®と Apache Flink®を使用してリアルタイムの航空会社データを利用する RAG 対応の Q&A チャットボットを構築する方法について説明します。
グラウンディング技術としての RAG
ユースケースを掘り下げる前に、RAG がビジネス関連データで言語モデルをグラウンディングする唯一のソリューションではないことに注意することが重要です。より伝統的な微調整アプローチを採用することもできますが、次のような欠点があります。
微調整には厳選されたトレーニングデータセットが必要だが、簡単に入手できない可能性がある。
データセットがすぐに古くなってしまうと、微調整の結果が不正確になる可能性がある。
微調整では、RAG と比較して、より多くの計算リソースが必要になる場合がある。
微調整には非常に特殊なスキルセットやドメイン知識が必要となり、そうしたシステムの構築と維持にかかるコストがさらに増加する。
モデルは、微調整して新しい情報を学習すると、古い情報を忘れる傾向があり (いわゆる「破滅的忘却」)、判断や制御が非常に困難となる。
ブランディングやクリエイティブライティングなど、特定のトーンやスタイルに出力を合わせる必要がある分野では、微調整が引き続き役立ちます。
さて、RAG 対応のチャットボットに戻りましょう。
RAG の説明
RAG ベースの AI システムの構築は、独自の食材と特殊なツールを使用して料理をするようなことと考えられます。構造化データも非構造化データも、入念に作られたレシピ (この場合はシステムプロンプト) に基づいてフードプロセッサー (LLM) に送る新鮮な食材のようなものと考えられます。フードプロセッサーのパワーと容量は、作る料理の規模と複雑さによって異なります。しかし、本当の魔法使いはすべてを監督するシェフであり、ここでデータオーケストレーションが役立ちます。リアルタイム AI システムでは、Flink がこのシェフの役割を担い、すべてのステップを調整します。一方、Kafka はシェフのテーブルとして機能し、すべてがシームレスに準備され、配信されるようにします。
チャットボットのような RAG ベースの AI システムを構築するためには、2つの重要なパターンに従う必要があります。
データの準備:調理する前に材料を洗い、切り刻み、並べる必要があるのと同様に、ナレッジベースに取り込む前にデータを準備する必要があります。
推論:シェフがさまざまなツールを使用して材料を組み合わせるのと同じように、オーケストレーターは関連するコンテキストを各プロンプトに接続し、それを LLM に送信して応答を生成します。
Confluent Cloud for Apache Flink の AI 機能がこれらのパターンなどでどう役立つかを見てみましょう。
RAG に Flink を使用
Confluent は、最も効率的なストレージエンジン、120点超のソースおよびシンクコネクター、Flink の強力なストリーム処理エンジンに基づいて構築された完全なデータストリーミングプラットフォームを提供します。モデルをテーブルや関数と同等の第一級オブジェクトとして導入する Flink SQL の最新機能により、使い慣れた SQL 構文を使用して LLM やその他の AI モデルを直接操作することで AI 開発を簡素化できます。
Flink SQL のml_predict() や federated_search() のような新しい定義済み関数により、推論と検索機能をシームレスに統合しながら、Flink でデータ処理パイプラインをオーケストレーションすることができます。
関連する各ステップを詳しく見てみましょう。
ステップ1:データの準備
「なくなった手荷物を探すのを手伝ってもらえますか?」、「次に空いているフライトのビジネスクラスのチケットはいくら?」などの顧客の質問に答えるチャットボットで、次のような多種多様なデータに関するインテリジェンスが必要です。
顧客の ID と現在の予約
価格情報と航空会社の変更ポリシー
航空会社の手荷物規定文書
カスタマーサービスのログとチケット
このような AI アシスタントの有効性は、自然言語によるクエリの文脈をどれだけ理解し、関連性のある信頼できる結果をリアルタイムで得られるかにかかっています。
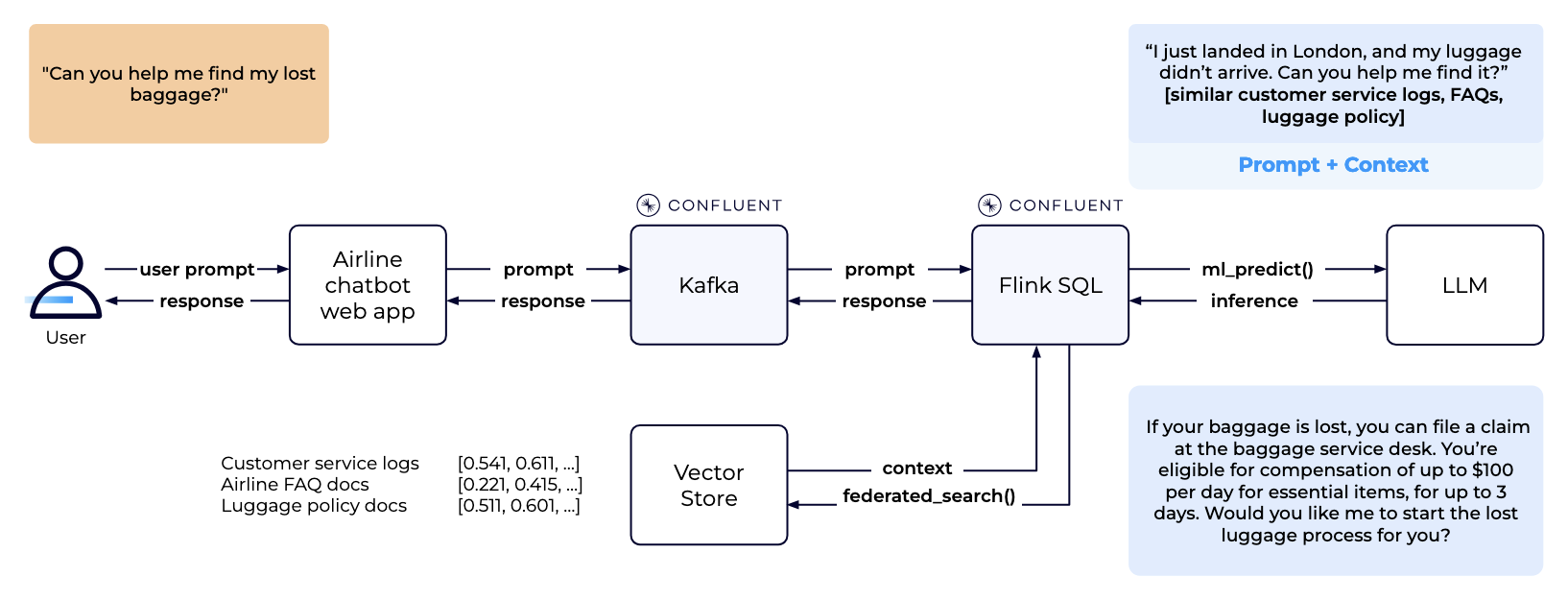
これを実現するには、上記のソースから非構造化データを取り込み、それを小さな部分に分割 (チャンク化) し、ベクター埋め込みに変換して、埋め込みをベクターストアに保存する必要があります。ベクター埋め込みはデータと関連するコンテキストの数値表現です。「関連するコンテキスト」は、あらゆる RAG ベースのアプリケーションの中心となります。次の図では、これを実現するために Confluent Cloud でリアルタイムパイプラインを構築する方法を示しています。
「これは本当にリアルタイムのイベントベースのパイプラインである必要があるのか」とお考えでしょうか。その答えはもちろん、ユースケースによって異なりますが、ほとんどの場合、古いデータよりも新しいデータの方が優れています。
数行の SQL を記述するだけで、Flink に埋め込み作成用のパイプラインを設定できます。
ステップ2:推論
ベクターストアにプライベートなビジネスデータが継続的に格納されるようになったため、推論のために LLM へ送信する前に、ベクターストアを使用して関連するコンテキストを取得し、その場でプロンプトを補強することができます。LLM から生成された応答はウェブアプリケーションに簡単にストリーミングできます。次の図は、Confluent Cloud での RAG の動作を示しています。
「なぜ Flink + Kafka の組み合わせなのか」と疑問に思われるかもしれません。RAG ワークフローのオーケストレーションに役立つツールは多数存在するため、これは妥当な質問です。Kafka や Flink などのイベントドリブン型アーキテクチャとテクノロジーに基づくリアルタイムシステムは、さまざまな業界で構築され、成功裏に拡張されています。リアルタイム AI システムでも同じパターンを利用できます。
さらに、Confluent のようなデータストリーミングプラットフォームを使用すると、アーキテクチャを完全に分離し、ダウンストリームとの互換性確保のためにスキーマを標準化し、インフライトストリーム処理が可能になり、どこからでも任意のストリームを組み合わせてリアルタイムでデータを充実化できるようになります。これは、概念実証からエンタープライズアプリケーションに移行する際に重要です。さらに、すぐに使えるデータリネージとガバナンスの統合も利用できます。
ここまで、シンプルな RAG 対応の Q&A チャットボットを構築したい方に最適となる、Flink SQL を使用してデータを準備し、生成 AI アプリケーション用に取得する方法を説明しました。より多くの機能を備えた AI アシスタントを構築することが目標である場合は、読み進めてください。
高度な RAG:推論とワークフロー
LLM が複雑な論理的推論と多段階の問題解決に苦労していることは、よく知られた事実です。したがって、AI アプリケーションが単一の自然言語クエリを構成可能な複数部分から成る論理クエリに分割したり、HyDE やナレッジグラフなどの別のパターンを使用して完全な回答が得られる可能性が高くなる方法で分野に固有のデータを生成したりできるようにする必要があります。次に、エンドユーザーがこうした情報をリアルタイムで利用できるようにする必要があります。
Flink Table API を使用すると、外部 API の推論と呼び出しに役立つ定義済み関数 (UDF) を使用して Python アプリケーションを作成し、アプリケーションのワークフローを合理化できます。
さらに、強力な状態管理機能を備えた Flink を使用すると、通常はステートレスである LLM を補強するメモリ (AI アシスタントの場合はセッション履歴) を管理できます。
AI の信頼性の確保:RAG システムでの後処理
ほとんどのエンタープライズ AI アシスタントには、LLM 応答の健全性チェックやその他の安全対策を実行する RAG システムでの後処理と呼ばれる最終ステップが必要です。これは、イベントドリブン型パターンにとってもう一つの絶好の機会となります。推論ワークフローから分離された別の Flink ジョブを使用して、例えば、価格の検証や紛失した手荷物の補償ポリシーのチェックを行うことができます。
これらすべてが Confluent Cloud でどのように統合されるかを見てみましょう。
結論
Confluent は、Flink SQL の AI モデル推論により、データ処理と AI タスクの両方に統合されたプラットフォームを提供することで、RAG 対応の生成 AI アプリケーションの開発と展開を簡素化します。リアルタイムで高品質かつ信頼性の高いデータストリームを活用することで、RAG パターンを使用して独自の分野固有のデータで LLM を拡張し、LLM が最も信頼性が高く正確な応答を提供できるようにすることができます。
実際の動作を確認するには、RAG チュートリアルでベクターエンコーディングに Flink を使用する手順と MongoDB Atlas のようなベクターデータベースをリアルタイムの情報で継続的に更新する方法の説明をご覧ください。追加のリソースについては生成 AI ハブをご覧ください。
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Why Is My Apache Flink® Job Not Producing Results?
An Apache Flink® job not producing results often indicates an issue with watermarks, which are necessary for handling out-of-order message processing in time-based aggregations from Kafka. Watermarks balance data loss and latency by defining how long to wait for late messages. Incorrectly setting...


{kind=link}

The AI Silo Problem: How Data Streaming Can Unify Enterprise AI Agents
Salesforce has Agentforce, Google launched Agentspace, and Snowflake recently announced Cortex Agents. But there’s a problem: They don’t talk to each other…