Getting Started with Scala and Apache Kafka
If you’re getting started with Apache Kafka® and event streaming applications, you’ll be pleased to see the variety of languages available to start interacting with the event streaming platform. It goes way beyond the traditional Java clients to include Scala as well. Unfortunately, there is less beginner content for Scala developers compared to Java. Scala developers might feel a little bit left out, and the idea that the two languages are close enough does not help. That’s why this blog post provides a quick tour of the Kafka client applications in Scala and explores what’s worth considering when importing Java dependencies in your Scala code to consume and produce data.
This blog post highlights the first Kafka tutorial in a programming language other than Java: Produce and Consume Records in Scala. It’s the first tutorial in a series dedicated to alternative programming languages. The tutorial covers the very basics of producing and consuming messages in Kafka, while this blog post goes beyond the tutorial and shares some additional concepts that provide important context for the tutorial.
The application example
Kafka is a distributed event log. It enables you to publish and subscribe to messages with different order and delivery guarantees. Programs publishing messages are called producers, and programs subscribing to messages are called consumers. With these two programs, you are able to decouple your data processing. Let’s clone the following example project:
git clone https://github.com/DivLoic/kafka-application4s.git cd kafka-application4s tree -L 3
Outputs:
#. #├── build.sbt #├── project/ #│ └── ... #└── src/ # ├── main/ # │ ├── resources/ # │ └── scala/ # └── test/ # ├── resources/ # └── scala/
To simulate a realistic project, this module uses many popular Scala dependencies. The file project/Dependencies.scala separates external libraries into two blocks. You can find the essential dependencies for this tutorial in the Kafka clients library and the Confluent serializers.
lazy val kafkaClientsDeps: List[ModuleID] = "org.apache.kafka" % "kafka-clients" % "2.6.0" :: "io.confluent" % "kafka-avro-serializer" % "6.0.0" :: Nil
The following describes the practical use case that guides the rest of this blog post. The kafka-application4s module comes with a simple content rating exercise. There are two topics:
- tv-show-topic: where the entire TV show collection is produced
- rating-topic: where ratings on the same shows are produced
The goal is to produce, consume, and process these TV shows. The dataset used in the example is strongly inspired by TV shows on Netflix, Prime Video, Hulu, and Disney+. Based on the dataset columns, the records use the following schemas:
case class Key(@AvroName("show_id") showId: String)
case class Rating(user: String, value: Short)
case class TvShow(platform: Platform, name: String, releaseYear: Int, imdb: Option[Double])
Produce records
First, you want to have an application capable of uploading the entire dataset into Kafka that is also capable of generating rating events associated with the TV shows. Here is an example of what it should look like in the end: producer recording.
The ProducingApp.scala class goes through the essential aspects of producing data into Kafka. The very first thing you need is a way to configure the app and its inner Kafka clients. The example uses the following default config file (src/main/resources/producer.conf) that can be overridden later by passing a path through the JVM argument -Dconfig.file=<path>.
serializer-config {
schema.registry.url = "http://localhost:8081"
schema.registry.url = ${?SCHEMA_REGISTRY_URL}
# ...
}
producer-config {
acks = all
bootstrap.servers = "localhost:9092"
bootstrap.servers = ${?BOOTSTRAP_SERVERS}
max.in.flight.requests.per.connection = 1
...
}
tv-show-topic-name: "DEV_TV_SHOW"
timeout: 5 s
...
This example uses pureconfig as the configuration parser. The most important observation is that the two first blocks will be converted to a Map[String, _], as required by the Kafka clients.
ProducingApp.scala is separated into four parts:
- Configure the clients
- Produce a batch of records
- Produce events as records
- Produce a record in a transaction
You need to create an instance of KafkaProducer[K, V]. The type parameters in this definition refer to the record key type (K) and the record value (V). The Kafka client library comes with a series of classic serializers, but in this case, the goal is to serialize your own structure (the Rating and TvShow case classes). Avro helps to serialize records in an efficient way. You need to create the following instances of Serializer[T], a class brought by the Kafka client package:
val keySerializer: Serializer[Key] = ??? val tvShowSerializer: Serializer[TvShow] = ??? val ratingSerializer: Serializer[Rating] = ???
There are a few methods to achieve this, but this example showcases the reflective method by implementing the reflectionAvroSerializer4S function (see HelperSerdes.scala) using the well-known Avro4s library. Note: Since Confluent 5.4.0, a reflective serializer exists in Java but might not cover all the basic Scala types you are familiar with.
The serializers in this example are Schema Registry compatible. The Serializer#configure method is used to pass in the Schema Registry URL in a Map[String, _]. Then you have to specify whether this object aims to serialise keys or values by passing a second parameter, isKey, which is a Boolean. Now you can use the serializers to create your producer as follows:
val producer = new KafkaProducer[Key, TvShow]( config.producerConfig.toMap.asJava, // producer-config bloc from conf file keySerializer, tvShowSerializer )
The config.producerConfig.toMap function builds the producer configs listed in the producer.conf file.
As mentioned earlier, ProducingApp.scala has multiple parts and each part illustrates a different production scenario. To do so, you will create different instances of KafkaProducer. Each instance is configured with the values from the config map config.producerConfig.toMap, then you specifically add or overwrite some producer configs.
val baseConfig: Map[String, AnyRef] = config.producerConfig.toMapval config1 = baseConfig ++ Map("client.id" -> "client1", "linger.ms" -> s"60000") val producer1 = new KafkaProducer[Key, TvShow](config1, keySerializer, tvShowSerializer)
val config2 = baseConfig ++ Map("client.id" -> "client2", "retries" -> "0") val producer2 = new KafkaProducer[Key, Rating](config2, keySerializer, ratingSerializer)
val config3 = baseConfig ++ Map("client.id" -> "client3", "transactional.id" -> "client3") val producer3 = new KafkaProducer[Key, Rating](config3, keySerializer, ratingSerializer)
The first producing example demonstrates how to batch records in fewer produce requests. Setting the "linger.ms=60000" tells the producer to wait longer before sending the content of its buffer to the brokers. It reduces networking and takes better advantage of compression. You then wrap all the TvShow instances in a ProducerRecord and send it to Kafka with the KafkaProducer#send method. Each call to send returns a Java future.
val maybeMetadata: Vector[Future[RecordMetadata]] = Dataset.AllTvShows.toVector.map {
case (showIdKey, showValue) =>
val record = new ProducerRecord[Key, TvShow]("topic-name", showIdKey, showValue)
producer1 send record
}
At this point, as you are probably familiar with Scala, you might want to convert this Java future into a Scala future and traverse this collection to get a scala.concurrent.Future[Vector[RecordMetadata]]]. But before you go through any complex operations, you need to know that ProducerRecord#flush lets you block the program until all records get written to Kafka with all the required acknowledgments. Note the use of Try to handle the potential non-retryable errors like InterruptedException that your Scala compiler won’t warn you about.
Try {
producer1.flush()
producer1.close()
logger info "Successfully produce the complete tv show collections"
}.recover {
case error: InterruptedException => logger error("☠️ ☠️ ☠️", error)
case error => logger error("Surprise 🎊", error)
}
You did it! You’ve just loaded your TV show catalogue into Kafka!
The second producer example describes how to send single events with lower latency. Setting the "retries=0" in this context of random data generation might be more appropriate because you will periodically send new records anyway. Note, since Kafka 2.1.0, this setting default value is Int.MaxValue.
val rating: Short = Random.nextInt(5).toShort
val eventTime: Long = Instant.now.toEpochMilli
val (showKey, showValue) = // ....
val genHeader = new RecordHeader("generator-id", s"..." getBytes)
val showHeader = new RecordHeader("show-details", s"..." getBytes)
val randomRecord: ProducerRecord[Key, Rating] = new ProducerRecord[Key, Rating](
"topic-name2",
null, // let the defaultPartitioner do its job
eventTime,
showKey,
Rating(randomUUID().toString.take(8), rating),
new RecordHeaders(Iterable[Header](genHeader, showHeader).asJava)
)
producer2 send randomRecord
In addition to a new config, this example shows how to indicate an event time to your records and also how to add technical metadata information with the headers. Add this code in a thread and run it multiple times via a Java timer.
val generator = new java.util.Timer()
val tasks: Seq[TimerTask] = (0 until 3) map { =>
// code from previous snippet
}
tasks foreach (generator schedule(_, 1000L, 1000L))
It is important to note that producers are thread safe. The producer instance will be accessed by different threads across the app, and its buffers are filled in parallel. This is not the case for the consumer, as described later.
The third producer example shows how to realize a transaction by setting "transactional.id=ID". Performing a transaction means all the messages sent in the context of this transaction will be either written successfully or marked as the elements of a failed transaction (in order to skip them). After calling KafkaProducer#initTransactions, include the following snippet in an infinite loop:
val record1, record2, record3 = // …
Try {
producer3.beginTransaction()
producer3.send(record1, producerCallback)
producer3.send(record2, producerCallback)
producer3.send(record3, producerCallback)
producer3.commitTransaction()
logger info "A transaction of 3 records has been completed."
}.recover {
case _ =>
logger error "A failure occurs during the transaction."
producer3.abortTransaction();
}
Be careful, as this part of the code could throw a ProducerFencedException, a UnsupportedVersionException, and an AuthorizationException if you don’t meet all the required conditions for a transaction. Also, this example uses a new signature of the send method. Here, you pass a Kafka callback that gets called once you’ve reached the required acknowledgments (acks) from the broker.
val producerCallback: Callback = new Callback {
override def onCompletion(metadata: RecordMetadata, exception: Exception): Unit = Option(exception)
.map(error => logger error("fail to produce a record due to: ", error))
.getOrElse(logger info s"Successfully produce a new record to kafka: ${
s"topic: ${metadata.topic()}, partition: ${metadata.partition()}, offset: ${metadata.offset()}"
}")
}
The three examples above showcase producing records in Kafka. When using Confluent Cloud to run this example, you can also use the data flow feature for a full picture of what’s been done so far.
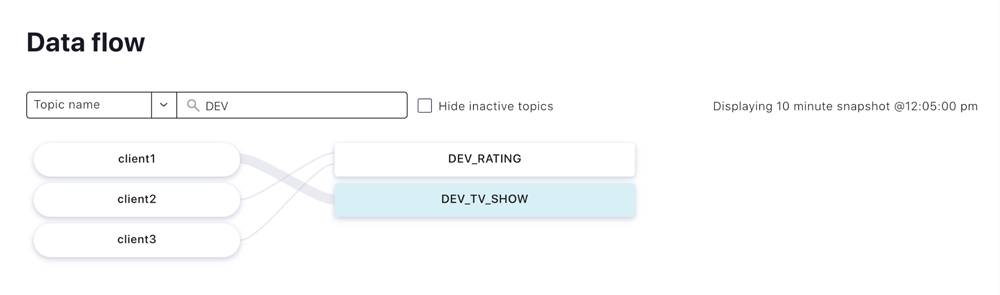
If you want to try a more step-by-step approach to Kafka producers in Scala, don’t hesitate to check out the Kafka tutorial: Produce and Consume Records in Multiple Languages.
Consume records
Now the goal is to consume back the records that were sent into the topics. This is an example of what the next program should look like: consumer recording.
The ConsumingApp.scala class goes through the essential aspects of consuming data from Kafka. Similar to producers, you will configure the app and its inner Kafka clients first. See the complete consumer.conf file. This time, the main class is separated into three parts:
- Configure the clients
- Consume records from beginning
- Consume the latest records
To create an instance of KafkaConsumer[K, V], use the deserialisers corresponding to the serializers used previously. The function reflectionAvroDeserializer4S (see HelperSerdes.scala) helps to instantiate one for each case class you have. They also need to be configured with the Schema Registry URL.
keyDeserializer.configure(config.deserializerConfig.toMap.asJava, true) tvShowDeserializer :: ratingDeserializer :: Nil foreach (_.configure(config.deserializerConfig.toMap.asJava, false))
You now have everything you need to configure your Kafka clients.
val baseConfig: Map[String, AnyRef] = config.consumerConfig.toMap
val consumerConfig1 = baseConfig ++ Map( "group.id" -> "groupe1", "fetch.max.bytes" -> "50") asJava
val consumer1 = new KafkaConsumer[Key, TvShow]( consumerConfig1, keyDeserializer, tvShowDeserializer)
In the first example, you will configure the consumer to begin reading from the first record of the topic. This consumer is specifically configured with "group.id=group1", so its backtracking won’t affect any other consumer instance. To do so, use the KafkaConsumer#assign with all the partitions you’d like to consume from as a parameter and call the KafkaConsumer#seekToBeginning method. You are ready to call the KafkaConsumer#poll method, which returns a subset of your Kafka messages wrapped in a ConsumerRecords[K, V] instance. This subset of records can be limited by a couple of factors:
- A size limit, which is set to the maximum by default
- A number limit, which is set to 500 records by default
You will start from the beginning and poll a limited number of records by lowering the size limit. Setting "fetch.max.bytes=50" fetches the 50 first bytes of TV shows by calling KafkaConsumer#poll once.
val tvShowPartition: Vector[TopicPartition] = //... consumer1.assign(tvShowPartition asJava) consumer1.seekToBeginning(consumer1.assignment())val records: ConsumerRecords[Key, TvShow] = consumer1.poll((2 seconds) toJava)
If you run the program, you will see that it fetches 200 records, which is lower than the record limit of 500. However, there are a lot more TV shows produced on that topic (about 5,481). If you delete the fetch.max.bytes config, you will see the count jump to 500, and if you change the max.poll.records, it will go even beyond that.
Now that you are done consuming old messages, it’s time to move on to the second part of the consumer process. The first thing to note is that by default auto.offset.reset is set to latest. This lets you start at the end of the stream the first time you start the application. Also, you will use a different group.id which places this consumer in its own consumer group. This time, you are going to consume rating events. As stated earlier, consumers are not thread safe. So if you want to have a consumer running in the background, you have to create it, use it, and close it in the same thread. To do this, use an ExecutorService from Java.
val scheduler = Executors.newSingleThreadScheduledExecutor()
scheduler.schedule(() => {
val consumer2 = new KafkaConsumer[Key, Rating]( //…
while (!scheduler.isShutdown) {
// consume and process here
}
consumer2.close()
}, 1, TimeUnit.SECONDS)
For this scenario, the question is: How many ratings did we get since the uptime? In order to answer this, we won’t keep track of our consumption. By setting "enable.auto.commit"="false", the consumer won’t commit its consumed offset. You can see the offset as a marker telling Kafka at which point of the stream our application is located. Without it, the application always starts at the end of the stream. You can then print the rating count from each generator.
Polled user-66c7d63a: 10 ⭐️, user-9d32d80a: 1 ⭐️, user-fb725bf6: 8 ⭐️.
This example is really specific. In general, what you want is to keep track of your consumption to process every single message. That’s why enable.auto.commit is true by default. But manual commit will give even more control on your processing guarantees.
while (!scheduler.isShutdown) {
Try {
val records = consumer2.poll(config.pollingTimeout.toJava)
// consumer2.commitSync() // commit here for at-most once behavior
records.iterator().asScala.toVector
}.recover {
case error => // ...
}.foreach { records =>
records.map(process)
// consumer2.commitSync() // commit here for at-least once behavior
}
}
Whether you commit the offset of your messages right after polling them or after processing them determines which processing semantic to use. “At-most once” semantics mean taking the risk of missing records in case of a crash but avoiding processing records multiple times. “At-least once” semantics mean the opposite. Every message gets processed at least once, and some might be processed multiple times in case of a crash.
You’ve now completed your introduction to Kafka clients with Scala by exploring an example of a consumer application. To see what you’ve made so far, you can use the Confluent Cloud data flow interface.
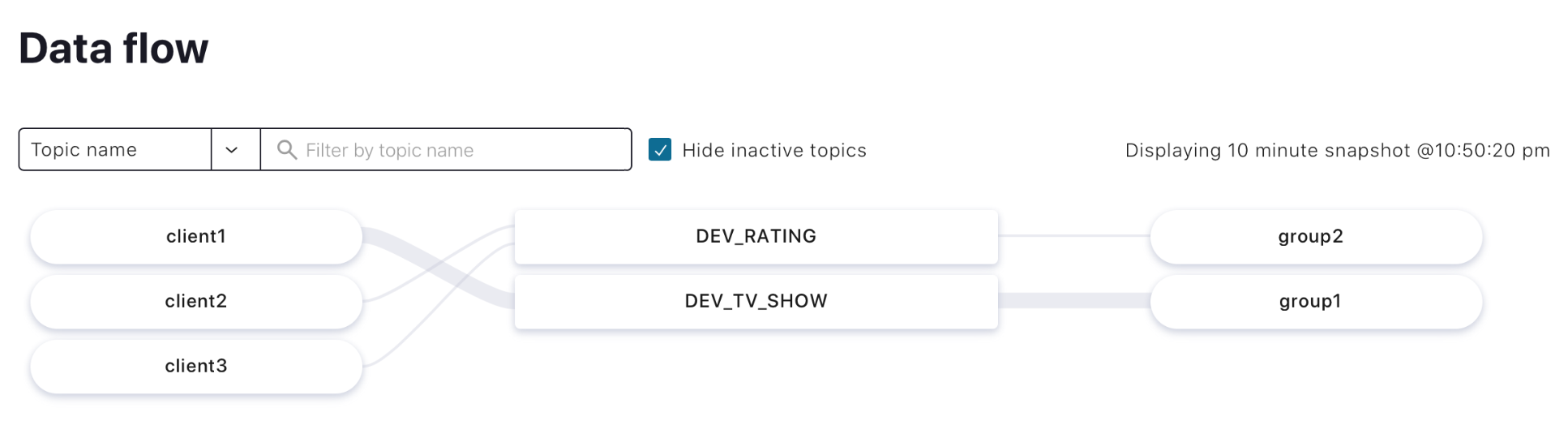
If you want to try a more step-by-step approach to the Kafka consumer in Scala, don’t hesitate to check out the tutorial: Produce and Consume Records in Multiple Languages.
Conclusion
This blog post described how to create and configure Kafka clients using a few producer and consumer configurations, outlined an approach to serialization via a reflective method and how this technique lets you write schema from the code, featured the main methods of the KafkaConsumer and KafkaProducer instances, and discussed a few Java exceptions for keeping your code safe. Of course, this is just a small subset of the possible exceptions, but you get the idea and now know what to look for.
Next steps
If you like the idea of promoting other language clients for Kafka, we need your help! We are looking for other community contributors to create tutorials similar to this Scala tutorial. If you are into C#, Node.js, Ruby, Python, or Go, check out the open issues to create another produce and consume tutorial. For further reading, check out the blog post Getting Started with Rust and Apache Kafka.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


