Kafka Connect Deep Dive – Converters and Serialization Explained
Kafka Connect is part of Apache Kafka®, providing streaming integration between data stores and Kafka. For data engineers, it just requires JSON configuration files to use. There are connectors for common (and not-so-common) data stores out there already, including JDBC, Elasticsearch, IBM MQ, S3 and BigQuery, to name but a few.
For developers, Kafka Connect has a rich API in which additional connectors can be developed if required. In addition to this, it also has a REST API for configuration and management of connectors.
Kafka Connect is modular in nature, providing a very powerful way of handling integration requirements. Some key components include:
- Connectors – the JAR files that define how to integrate with the data store itself
- Converters – handling serialization and deserialization of data
- Transforms – optional in-flight manipulation of messages
One of the more frequent sources of mistakes and misunderstanding around Kafka Connect involves the serialization of data, which Kafka Connect handles using converters. Let’s take a good look at how these work, and illustrate some of the common issues encountered.
Overview
- Kafka messages are just bytes
- Configuring converters
- JSON and schemas
- Common errors
- Troubleshooting tips
- Internal converters
- Applying a schema to messages without a schema
- Conclusion
- Interested in more?
Kafka messages are just bytes
Kafka messages are organized into topics. Each message is a key/value, but that is all that Kafka requires. Both key and value are just bytes when they are stored in Kafka. This makes Kafka applicable to a wide range of use cases, but it also means that developers have the responsibility of deciding how to serialize the data.
In configuring Kafka Connect, one of the key things to standardize on is the serialization format. You need to make sure that anyone reading from the topic is using the same serialization format as those writing to the topic. Otherwise, confusion and errors will ensue!
There are various serialization formats with common ones including:
- JSON
- Avro
- Protobuf
- String delimited (e.g., CSV)
There are advantages and disadvantages to each of these—well, except delimited, in which case it’s only disadvantages 😉
Choosing a serialization format
Some guiding principles for choosing a serialization format include:
- Schema. A lot of the time your data will have a schema to it. You may not like the fact, but it’s your responsibility as a developer to preserve and propagate this schema. The schema provides the contract between your services. Some message formats (such as Avro and Protobuf) have strong schema support, whilst others have lesser support (JSON) or none at all (delimited string).
- Ecosystem compatibility. Avro, Protobuf, and JSON are first-class citizens in the Confluent Platform, with native support from the Confluent Schema Registry, Kafka Connect, ksqlDB, and more.
- Message size. Whilst JSON is plain text and relies on any compression configured in Kafka itself, Avro and Protobuf are both binary formats and thus provide smaller message sizes.
- Language support. For example, support for Avro is strong in the Java space, whilst if you’re using Go, chances are you’ll be expecting to use Protobuf.
If I write to my target in JSON, must I use JSON for my topics?
No, not at all. The format in which you’re reading data from a source, or writing it to an external data store, doesn’t need to have a bearing on the format you use to serialize your messages in Kafka.
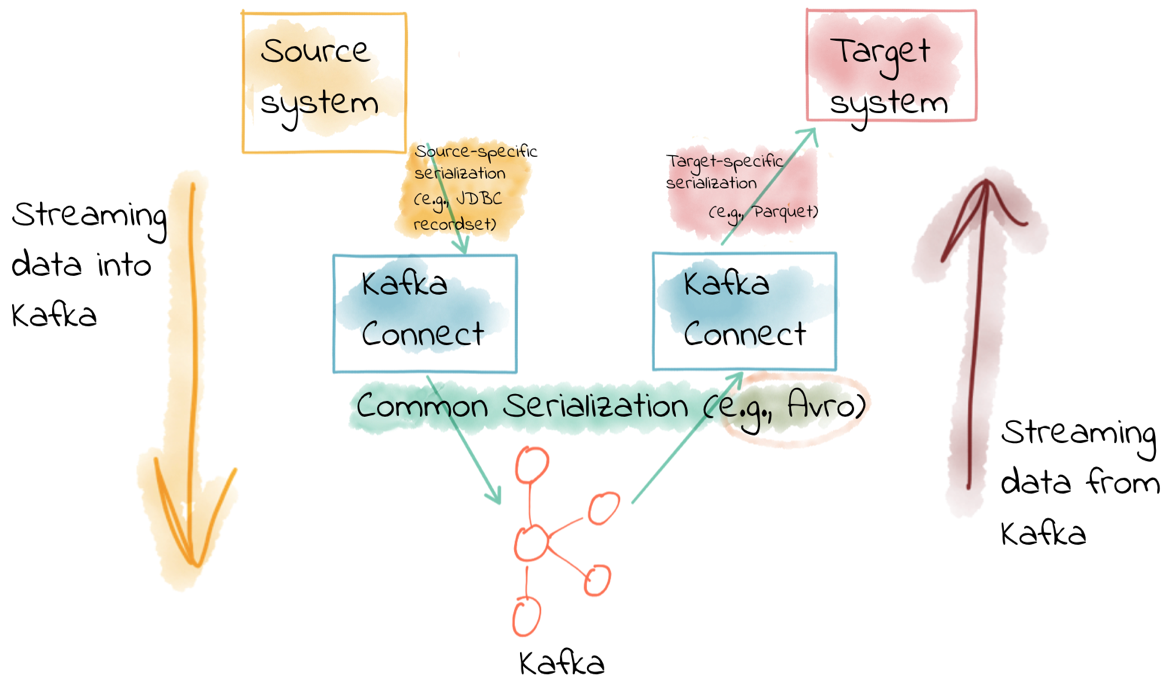
A connector in Kafka Connect is responsible for taking the data from the source data store (for example, a database) and passing it as an internal representation of the data to the converter. Kafka Connect’s converters then serialize this source data object onto the topic.
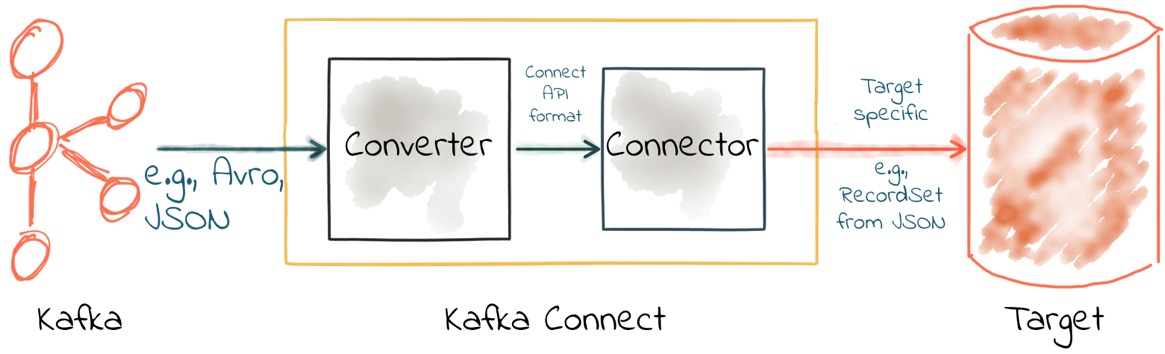
The same happens in reverse when using Kafka Connect as a sink—the converter deserializes the data from the topic into this internal representation, which is passed to the connector to write to the target data store using the appropriate method specific to the target.
What this means is that you can have data on a topic in Avro (for example), and when you come to write it to HDFS (for example), you simply specify that you want the sink connector to use that format.
Configuring converters
Kafka Connect takes a default converter configuration at the worker level, and it can also be overridden per connector. Since using the same serialization format throughout your pipelines is generally a good idea, you’ll often just set the converter at the worker, and never need to specify it in a connector. But maybe you’re pulling data from someone else’s topic and they’ve decided to use a different serialization format—in that case you’d set this in the connector configuration. Even though you override it in the connector’s configuration, it’s still the converter that performs the work.
Connectors that are written properly never [de]serialize the messages stored in Kafka, and always let the configured converter do that work.
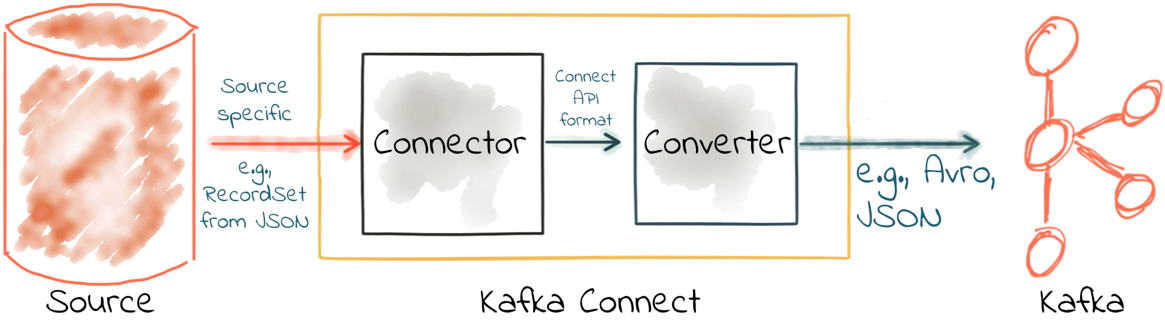
Remember, Kafka messages are just pairs of key/value bytes, and you need to specify the converter for both keys and value, using the key.converter and value.converter configuration setting. In some situations, you may use different converters for the key and the value.
Here’s an example of using the String converter. Since it’s just a string, there’s no schema to the data, and thus it’s not so useful to use for the value:
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
Some converters have additional configuration. For Avro, you need to specify the Schema Registry. For JSON, you need to specify if you want Kafka Connect to embed the schema in the JSON itself. When you specify converter-specific configurations, always use the key.converter. or value.converter. prefix. For example, to use Avro for the message payload, you’d specify the following:
"value.converter": "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url": "http://schema-registry:8081",
Common converters include:
- Avro
io.confluent.connect.avro.AvroConverter
- Protobuf
io.confluent.connect.protobuf.ProtobufConverter
- String
org.apache.kafka.connect.storage.StringConverter
- JSON
org.apache.kafka.connect.json.JsonConverter
- JSON Schema
io.confluent.connect.json.JsonSchemaConverter
- ByteArray
org.apache.kafka.connect.converters.ByteArrayConverter
JSON and schemas
Whilst JSON does not by default support carrying a schema, Kafka Connect supports two ways that you can still have a declared schema and use JSON. The first is to use JSON Schema with the Confluent Schema Registry. If you cannot use the Schema Registry then your second (less optimal option) is to use Kafka Connect’s support of a particular structure of JSON in which the schema is embedded. The resulting data size can get large as the schema is included in every single message along with the schema.
If you’re setting up a Kafka Connect source and want Kafka Connect to include the schema in the message it writes to Kafka, you’d set:
value.converter=org.apache.kafka.connect.json.JsonConverter value.converter.schemas.enable=true
The resulting message to Kafka would look like the example below, with schema and payload top-level elements in the JSON:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int64",
"optional": false,
"field": "registertime"
},
{
"type": "string",
"optional": false,
"field": "userid"
},
{
"type": "string",
"optional": false,
"field": "regionid"
},
{
"type": "string",
"optional": false,
"field": "gender"
}
],
"optional": false,
"name": "ksql.users"
},
"payload": {
"registertime": 1493819497170,
"userid": "User_1",
"regionid": "Region_5",
"gender": "MALE"
}
}
Note the size of the message, as well as the proportion of it that is made up of the payload vs. the schema. Considering that this is repeated in every message, you can see why a serialisation format like JSON Schema or Avro makes a lot of sense, as the schema is stored separately and the message holds just the payload (and is compressed at that).
If you’re consuming JSON data from a Kafka topic into a Kafka Connect sink, you need to understand how the JSON was serialised. If it was with JSON Schema serialiser, then you need to set Kafka Connect to use the JSON Schema converter (io.confluent.connect.json.JsonSchemaConverter). If the JSON data was written as a plain string, then you need to determine if the data includes a nested schema. If it does—and it’s in the same format as above, not some arbitrary schema-inclusion format—then you’d set:
value.converter=org.apache.kafka.connect.json.JsonConverter value.converter.schemas.enable=true
However, if you’re consuming JSON data and it doesn’t have the schema/payload construct, such as this sample:
{
"registertime": 1489869013625,
"userid": "User_1",
"regionid": "Region_2",
"gender": "OTHER"
}
…you must tell Kafka Connect not to look for a schema by setting schemas.enable=false:
value.converter=org.apache.kafka.connect.json.JsonConverter value.converter.schemas.enable=false
As before, remember that the converter configuration option (here, schemas.enable) needs the prefix of key.converter or value.converter as appropriate.
Common errors
Here are some of the common errors you can get if you misconfigure the converters in Kafka Connect. These will show up in the sinks you configure for Kafka Connect, as it’s this point at which you’ll be trying to deserialize the messages already stored in Kafka. Converter problems tend not to occur in sources because it’s in the source that the serialization is set. Each of these will cause the connector to fail, with a headline error of:
ERROR WorkerSinkTask{id=sink-file-users-json-noschema-01-0} Task threw an uncaught and unrecoverable exception (org.apache.kafka.connect.runtime.WorkerTask)
org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded in error handler
at org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator. execAndHandleError(RetryWithToleranceOperator.java:178)
at org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator.execute (RetryWithToleranceOperator.java:104)
After this error, you’ll see a further stack trace describing exactly why it erred. Be aware that the above error will be thrown for any fatal error in a connector, so you may well see this for errors unrelated to serialization. To quickly visualize what errors you can expect with which misconfiguration, here’s a quick reference:

Problem: Reading non-JSON data with JsonConverter
If you have non-JSON data on your source topic but try to read it with the JsonConverter, you can expect to see:
org.apache.kafka.connect.errors.DataException: Converting byte[] to Kafka Connect data failed due to serialization error: … org.apache.kafka.common.errors.SerializationException: java.io.CharConversionException: Invalid UTF-32 character 0x1cfa7e2 (above 0x0010ffff) at char #1, byte #7)
This could be caused by the source topic being serialized in Avro or another format.
Solution: If the data is actually in Avro, then change your Kafka Connect sink connector to use:
"value.converter": "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url": "http://schema-registry:8081",
OR if the topic is populated by Kafka Connect, and you can and would rather do so, switch the upstream source to emit JSON data:
"value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false",
Problem: Reading non-Avro data with AvroConverter
This may be the most common error that I see reported again and again on places like the Confluent Community mailing list and Slack group. It happens when you try to use the Avro converter to read data from a topic that is not Avro. This would include data written by an Avro serializer other than the Confluent Schema Registry’s Avro serializer, which has its own wire format.
org.apache.kafka.connect.errors.DataException: my-topic-name at io.confluent.connect.avro.AvroConverter.toConnectData(AvroConverter.java:97) … org.apache.kafka.common.errors.SerializationException: Error deserializing Avro message for id -1 org.apache.kafka.common.errors.SerializationException: Unknown magic byte!
The solution is to check the source topic’s serialization format, and either switch Kafka Connect’s sink connector to use the correct converter, or switch the upstream format to Avro (which is a good idea). If the upstream topic is populated by Kafka Connect, then you can configure the source connector’s converter as follows:
"value.converter": "io.confluent.connect.avro.AvroConverter", "value.converter.schema.registry.url": "http://schema-registry:8081",
Problem: Reading a JSON message without the expected schema/payload structure
As described earlier, Kafka Connect supports a special structure of JSON messages containing both payload and schema. If you try to read JSON data that does not contain the data in this structure, you will get this error:
org.apache.kafka.connect.errors.DataException: JsonConverter with schemas.enable requires "schema" and "payload" fields and may not contain additional fields. If you are trying to deserialize plain JSON data, set schemas.enable=false in your converter configuration.
To be clear, the only JSON structure that is valid for schemas.enable=true has schema and payload fields as the top-level elements (shown above).
As the message itself states, if you just have plain JSON data, you should change your connector’s configuration to:
"value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false",
If you want to include the schema in the data, you can either switch to using Avro (recommended), or you can configure Kafka Connect upstream to include the schema in the message:
"value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "true",
Troubleshooting tips
Finding the Connect worker log
To find the error log from Kafka Connect, you need to locate the Kafka Connect worker’s output. The location of this depends on how you launched Kafka Connect. There are several ways to install Kafka Connect, including Docker, Confluent CLI, systemd and manually from a downloaded archive. You’ll find the worker log in:
- Docker: docker logs container_name
- Confluent CLI: confluent local log connect
- systemd: Log file is written to /var/log/confluent/kafka-connect
- Other: By default, Kafka Connect sends its output to stdout so you’ll find it in the terminal session that launched Kafka Connect
Finding the Kafka Connect configuration file
To change configuration properties for Kafka Connect workers (which apply to all connectors run), set the configuration accordingly:
- Docker – Set environment variables, for example, in Docker Compose:
CONNECT_KEY_CONVERTER: io.confluent.connect.avro.AvroConverter CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081' CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'
- Confluent CLI – Use the configuration file etc/schema-registry/connect-avro-distributed.properties
- systemd (deb/rpm) – Use the configuration file /etc/kafka/connect-distributed.properties
- Other – When you launch Kafka Connect, you specify the worker properties file, for example:
$ cd confluent-5.5.0 $ ./bin/connect-distributed ./etc/kafka/connect-distributed.properties
Inspecting a Kafka topic
Let’s say we’ve hit one of the errors shown above, and want to troubleshoot why our Kafka Connect sink connector can’t read from a topic.
We need to check the data on the topic that is being read, and ensure it’s in the serialization format that we think it is. Also, bear in mind that all the messages need to be in this format, so don’t just assume that because you’re now sending messages in the correct format to the topic there won’t be a problem. Existing messages on the topic are also read by Kafka Connect and other consumers.
Below, I describe troubleshooting this from the command line, but there are a few other tools to be aware of:
- Confluent Control Center includes the feature to visually inspect topic contents, including automagic determination of the serialization format
- ksqlDB’s PRINT command will print the contents of a topic to the console, including automagic determination of the serialization format
- The Confluent CLI tool includes the consume command, which can be used to read both string and Avro data
If you think you’ve got string/JSON data…
You can use console tools including kafkacat and kafka-console-consumer. My personal preference is kafkacat:
$ kafkacat -b localhost:9092 -t users-json-noschema -C -c1
{
"registertime":1493356576434,"userid":"User_8","regionid":"Region_2","gender":"MALE"}
Using the excellent jq, you can also validate and format the JSON:
$ kafkacat -b localhost:9092 -t users-json-noschema -C -c1|jq '.'
{
"registertime": 1493356576434,
"userid": "User_8",
"regionid": "Region_2",
"gender": "MALE"
}
If you get something like this, with a bunch of “weird” characters, chances are you’re looking at binary data, as would be written by something like Avro or Protobuf:
$ kafkacat -b localhost:9092 -t users-avro -C -c1 ڝ���VUser_Region_MALE
If you think you’ve got Avro data…
You should use a console tool designed for reading and deserializing Avro data. Here, I’m using kafka-avro-console-consumer. Make sure you specify the correct Schema Registry URL at which the schema is held:
$ kafka-avro-console-consumer --bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--topic users-avro \
--from-beginning --max-messages 1
{"registertime":1505213905022,"userid":"User_5","regionid":"Region_4","gender":"FEMALE"}
As before, you can pipe the resulting output through jq if you want to format it:
$ kafka-avro-console-consumer --bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--topic users-avro \
--from-beginning --max-messages 1 | \
jq '.'
{
"registertime": 1505213905022,
"userid": "User_5",
"regionid": "Region_4",
"gender": "FEMALE"
}
Internal converters
When run in distributed mode, Kafka Connect uses Kafka itself to store metadata about its operations, including connector configuration, offsets and so on.
These Kafka topics themselves can be configured to use different converters through the internal.key.converter/internal.value.converter settings. However, these settings are purely for internal use, and indeed have been deprecated as of Apache Kafka 2.0. You should not change these, and you will get warnings from Apache Kafka as of version 2.0 if you do try to configure them.
Applying a schema to messages without a schema
A lot of the time, Kafka Connect will bring data in from places where there is already a schema, and retaining that schema is just a matter of using a suitable serialization format such as Avro. All downstream users of that data then benefit from the schema being available to them, with the compatibility guarantees that something like Schema Registry provides. But what if there is no explicit schema?
Maybe you’re reading data from a flat file using the FileSourceConnector (which is not recommended for production, but is often used for PoCs). Or, perhaps you’re pulling data from a REST endpoint using the REST connector. Since both of these, along with others, have no inherent schema, it’s up to you to declare it.
Sometimes you’ll just want to pass the bytes that you’ve read from the source through and put them on a topic. But most of the time, you’ll want to do the Right Thing and apply a schema so that the data can be used. Doing it once as part of the ingestion, instead of pushing the problem onto each consumer (potentially multiple), is a much better pattern to follow.
You can write your own Kafka Streams application to apply schema to data in a Kafka topic, but you can also use KSQL. This post shows how to do it against JSON data pulled from a REST endpoint. Let’s look here at a simple example of applying a schema to some CSV data. Obviously to be able to do this, we have to know the schema itself!
Let’s say we’ve got a Kafka topic testdata-csv with some CSV data in it. It looks like this:
$ kafkacat -b localhost:9092 -t testdata-csv -C 1,Rick Astley,Never Gonna Give You Up 2,Johnny Cash,Ring of Fire
By eyeballing it, we can guess at there being three fields, maybe something like:
- ID
- Artist
- Song
If we leave the data in the topic like this, then any application wanting to use the data—whether it’s a Kafka Connect sink, bespoke Kafka application or whatever—will need to guess this schema each time. Or, just as bad, the developer for each consuming application will need to constantly go back to the team providing the data to check about the schema and any changes to it. Just as Kafka decouples systems, this kind of schema dependency forces a hard coupling between teams, and it’s not a good thing.
So what we’ll do is simply apply a schema to the data using KSQL, and populate a new, derived topic in which the schema is present. From KSQL, you can inspect the topic data:
ksql> PRINT 'testdata-csv' FROM BEGINNING; Format:STRING 11/6/18 2:41:23 PM UTC , NULL , 1,Rick Astley,Never Gonna Give You Up 11/6/18 2:41:23 PM UTC , NULL , 2,Johnny Cash,Ring of Fire
The first two fields here (11/6/18 2:41:23 PM UTC and NULL) are the timestamp and key of the Kafka message, respectively. The remaining fields are from our CSV file. Let’s register this topic with ksqlDB and declare the schema:
ksql> CREATE STREAM TESTDATA_CSV (ID INT, ARTIST VARCHAR, SONG VARCHAR) \ WITH (KAFKA_TOPIC='testdata-csv', VALUE_FORMAT='DELIMITED'); Message ---------------- Stream created ----------------
Observe that ksqlDB now has a schema for the stream of data:
ksql> DESCRIBE TESTDATA_CSV; Name : TESTDATA_CSV Field | Type ------------------------------------- ROWTIME | BIGINT (system) ROWKEY | VARCHAR(STRING) (system) ID | INTEGER ARTIST | VARCHAR(STRING) SONG | VARCHAR(STRING) ------------------------------------- For runtime statistics and query details run: DESCRIBE EXTENDED <Stream,Table>;
Check that the data is as expected by querying the ksqlDB stream. Note that at this point we’re simply acting as a Kafka consumer against the existing Kafka topic—we’ve not changed or duplicated any data yet.
ksql> SET 'auto.offset.reset' = 'earliest'; Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest' ksql> SELECT ID, ARTIST, SONG FROM TESTDATA_CSV; 1 | Rick Astley | Never Gonna Give You Up 2 | Johnny Cash | Ring of Fire
Finally, create a new Kafka topic, populated by the reserialized data with schema. ksqlDB queries are continuous, so in addition to sending any existing data from the source topic to the target one, ksqlDB will send any future data to the topic too.
ksql> CREATE STREAM TESTDATA WITH (VALUE_FORMAT='AVRO') AS SELECT * FROM TESTDATA_CSV; Message ---------------------------- Stream created and running ----------------------------
Verify the data using the Avro console consumer:
$ kafka-avro-console-consumer --bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--topic TESTDATA \
--from-beginning | \
jq '.'
{
"ID": {
"int": 1
},
"ARTIST": {
"string": "Rick Astley"
},
"SONG": {
"string": "Never Gonna Give You Up"
}
}
[…]
You can even check the Schema Registry for the registered schema:
$ curl -s http://localhost:8081/subjects/TESTDATA-value/versions/latest|jq '.schema|fromjson'
{
"type": "record",
"name": "KsqlDataSourceSchema",
"namespace": "io.confluent.ksql.avro_schemas",
"fields": [
{
"name": "ID",
"type": [
"null",
"int"
],
"default": null
},
{
"name": "ARTIST",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "SONG",
"type": [
"null",
"string"
],
"default": null
}
]
}
Any new messages written to the original topic (testdata-csv) are automagically processed by KSQL, and written to the new TESTDATA topic in Avro. Now any application or team wanting to use this data can simply work with the TESTDATA topic, and take advantage of the Avro-serialized data with declared schema. You can also use this technique to change the number of partitions in a topic, the partitioning key and replication factor.
Conclusion
Kafka Connect is a very simple yet powerful tool to use for integrating other systems with Kafka. One of the most common sources of misunderstanding is the converters that Kafka Connect offers. We’ve covered that Kafka messages are just key/value pairs, and it’s important to understand which serialization you should use and then standardize on that in your Kafka Connect connectors. Lastly, if you’d like to look at the code samples used in this blog post, they are available on GitHub.
Interested in more?
- If you want to get started with Kafka connectors quickly so you can set your existing data in motion, check out Confluent Cloud today and the many fully managed connectors that we support. You can also use the promo code 60DEVADV to get $60 of additional free usage.* With a scales-to-zero, low-cost, only-pay-for-what-you-stream pricing model, Confluent Cloud is perfect for getting started with Kafka right through to running your largest deployments.
- For more information about Kafka Connect, you can refer to the documentation including that on serializers, as well as find help on the Confluent Community Forum.
- The quick ksqlDB snippet shown above barely scratches the surface of what’s possible with ksqlDB, so definitely check out Kafka Tutorials and ksqlDB blog posts for more.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Guide to Consumer Offsets: Manual Control, Challenges, and the Innovations of KIP-1094
The guide covers Kafka consumer offsets, the challenges with manual control, and the improvements introduced by KIP-1094. Key enhancements include tracking the next offset and leader epoch accurately. This ensures consistent data processing, better reliability, and performance.



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…