Introducing Health+ with Confluent Platform 6.2
For a modern, software-defined business, a platform for data in motion is critical to connecting every part of a vast digital architecture across an organization to harness the flow of data between applications, databases, cloud ecosystems, and more. Businesses use platforms like Apache Kafka® to process, react, and respond to ever-changing streams of data in real time. Because data in motion is the backbone of business-critical applications, lag or downtime can lead to mission-critical processes and applications failing, causing significant business disruption and data loss. When data stops being in motion, your business grinds to a halt.
With the release of Confluent Platform 6.2, we’re excited to introduce Health+ to provide the tools and visibility needed to ensure the health of your data-in-motion infrastructure and minimize business disruption with new intelligent alerts, cloud-based monitoring and visualizations, and a streamlined support experience. Health+ delivers three primary benefits to enhance the reliability of your data-in-motion use cases:
- Intelligent alerts to reduce the risk of downtime and data loss by identifying potential issues before they occur to avoid business disruption. These alerts are based on expert-tested rules and algorithms developed from running thousands of clusters in Confluent Cloud to keep your self-managed clusters running smoothly and highly available.
- Cloud-based monitoring dashboards to ensure the health of your environment(s) and quickly troubleshoot issues through real-time and historical visualizations of monitoring data. Our scalable, cloud-based solution also offloads expensive and infrastructure-intensive monitoring of self-managed services.
- Accelerated Confluent support to speed issue resolution and minimize business disruption with a streamlined support experience. We are enabling customers to securely share contextual metadata without manual entry for much faster and targeted enterprise support interactions, particularly in times of duress.
In this blog post, we’ll explore each of these benefits of Health+, along with additional enhancements in this release that make it easier to connect Confluent Platform clusters to Confluent Cloud, simplify disaster recovery operations, and accelerate the development of stream processing applications. As with previous Confluent Platform releases, you can always find more details about the features in the release notes or in the video below.
If you are interested in Health+, you can sign up below to try it for free.
Keep reading to get an overview of what’s included in Confluent Platform 6.2, or download and try Confluent Platform now if you’re ready to get started.
Reduce risk of downtime
More and more enterprises are using Kafka to power delightful customer experiences and data-driven, backend operations in real time. However, Kafka lacks effective alerting mechanisms to help you find and troubleshoot issues within its ecosystem, jeopardizing the success of these business-critical initiatives. It’s especially challenging to ensure high availability and resilience, often requiring organizations to dedicate significant time, resources, and expertise to deal with any Kafka-related issues. Health+ helps reduce risk of downtime and data loss with intelligent alerts to identify potential issues before they occur and avoid business disruption.
Health+ Intelligent Alerts: Customizable notifications to keep your clusters running smoothly and ensure high availability
With cluster metadata being continuously analyzed through an extensive library of expert-tested rules and algorithms, Health+ provides you with insights into cluster performance and health, helping you spot potential problems before they occur. We provide a growing set of intelligent alerts accompanied by Confluent-backed recommendations on how to solve key issues, enabling self-managed deployments to power reliable, highly durable real-time applications and systems without the heavy operational burden required to keep Kafka running smoothly.
With Health+, your deployment securely sends only its metadata—not topic/payload data—back to Confluent over HTTPS, and we analyze that data to identify problems and make suggestions on configuration optimizations based on algorithms developed from running our own Confluent Cloud service. We then categorize what we find in that analysis and notify you at different levels of severity.
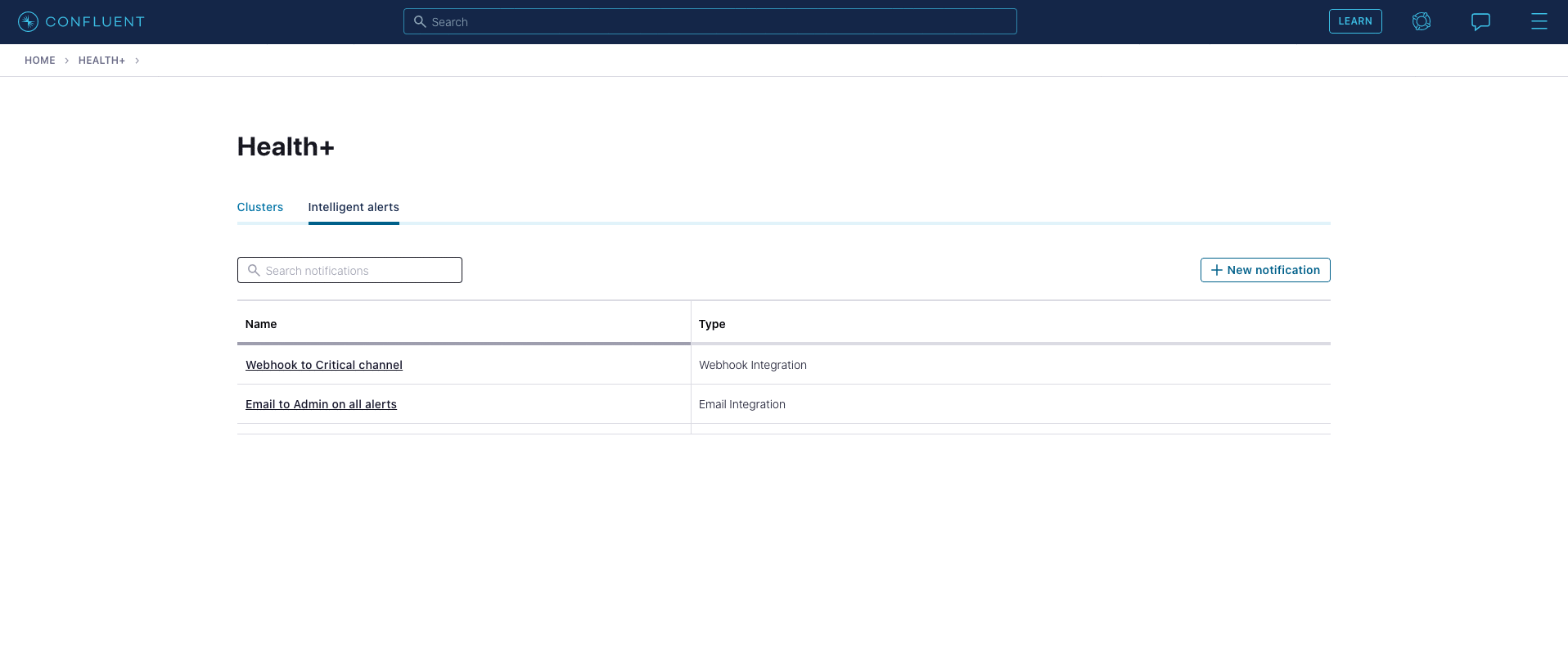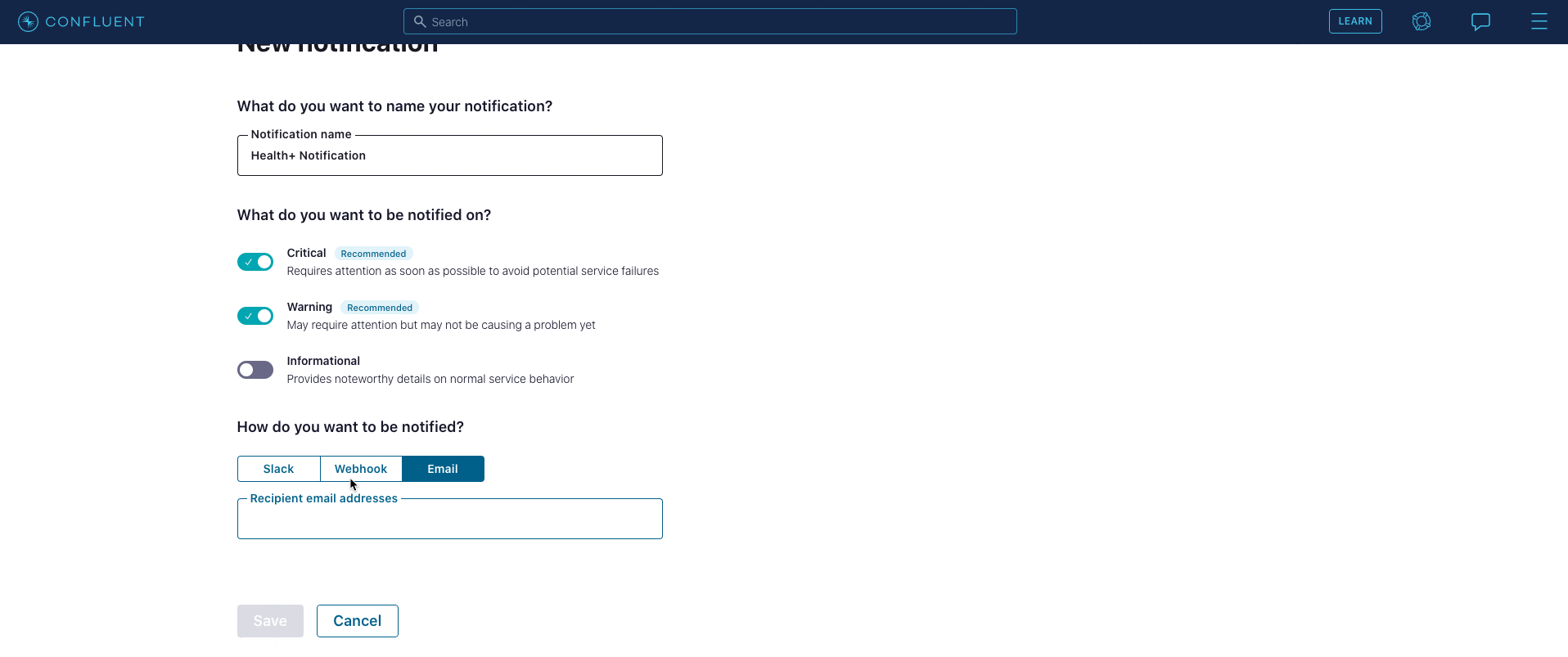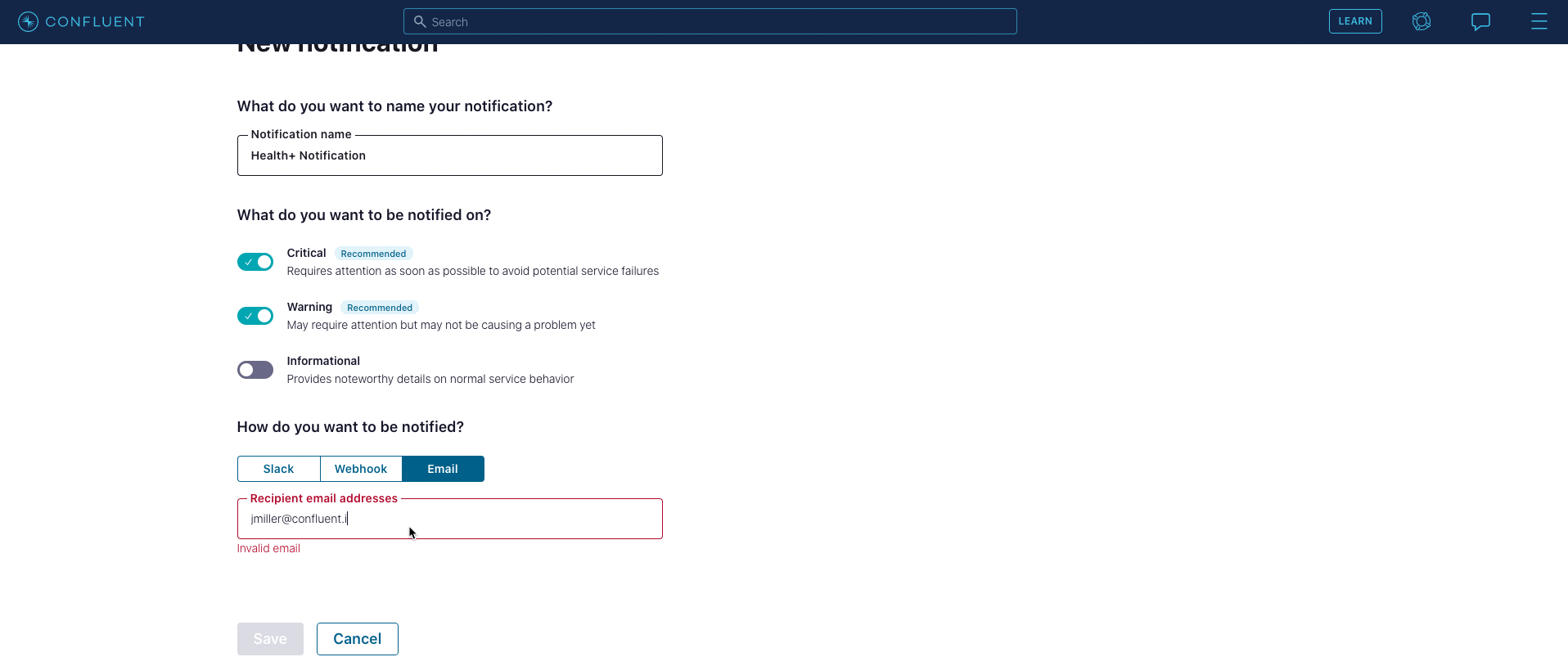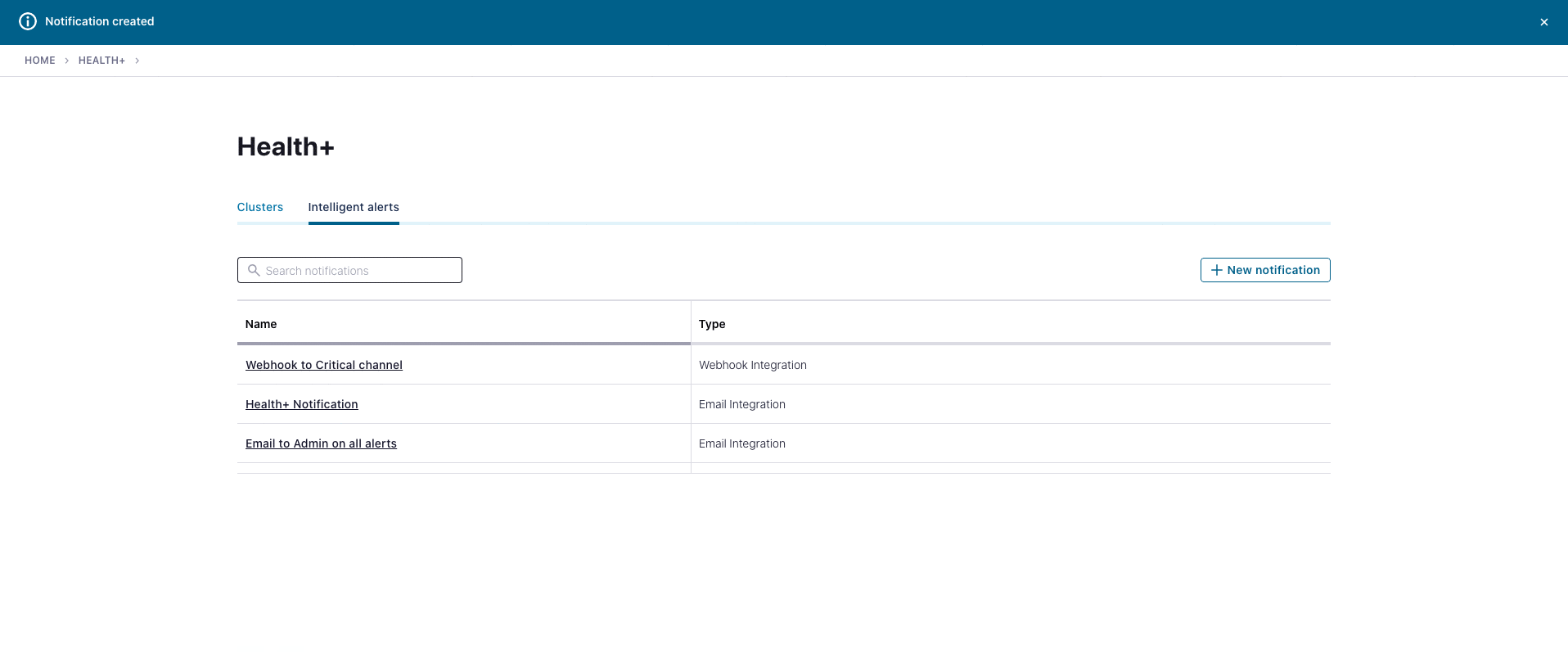
There are 10 total validations available today (with many more to come), including:
- Request handler idle percentage
- Network processor idle percentage
- Active controller count
- Offline partitions
- Unclean leader elections
- Under replicated partitions
- Under min in-sync replicas
- Disk usage
- Unused topics
- No metrics from cluster in one hour
And we will continue to build additional alerts in Health+ with future enhancements on the roadmap.
Health+ is built on our deep understanding of data-in-motion infrastructure that is rooted in experience managing thousands of clusters in Confluent Cloud that meet our 99.95% uptime SLA. Our global team has over 1 million hours of Kafka experience and operates some of the largest use cases for data in motion while solving problems across thousands of clusters every week. Without the requisite expertise, it’s very difficult for teams to determine the right set of metrics to track. We’ve codified our expertise into our intelligent alerts and have identified what we consider the most important Kafka metrics that customers should monitor and alert on, whether you’re just starting with Kafka or leveraging the platform as your organization’s central nervous system.
In addition, you can customize the types of notifications that you receive and choose to receive them via Slack, email, or webhook—seamlessly fitting into your day-to-day workflows and operations. Each notification that you get is aimed at avoiding larger downtime or data loss by helping identify small issues before they become bigger problems that disrupt the business.
Ensure system health
Kafka is often used for real-time, mission-critical applications, but it lacks GUI-driven monitoring to ensure that systems are built to deliver on the promises of data availability and business SLAs. It requires third-party tooling for monitoring, and most tools fail to curate the most critical metrics around the health, availability, and performance of the Kafka environment. Health+ helps ensure the performance and stability of your environments and quickly troubleshoot issues through real-time and historical visualizations of monitoring data.
Health+ Monitoring Dashboards: Cloud-based visualizations of critical health metrics for simple troubleshooting
As customers adopt data in motion throughout their organization, their monitoring needs grow as well. Health+ offloads expensive and performance intensive monitoring of self-managed services through a scalable, cloud-based solution. It enables you to view the most important monitoring metrics over a period of time in a single dashboard.
For example, you can view broker throughput, topic throughput, replicated partitions, disk usage, network handler pool usage, request handler pool usage, and much more. Health+ visualizes this data clearly and succinctly, enabling DevOps and platform teams to dig into problems and analyze usage of their system.
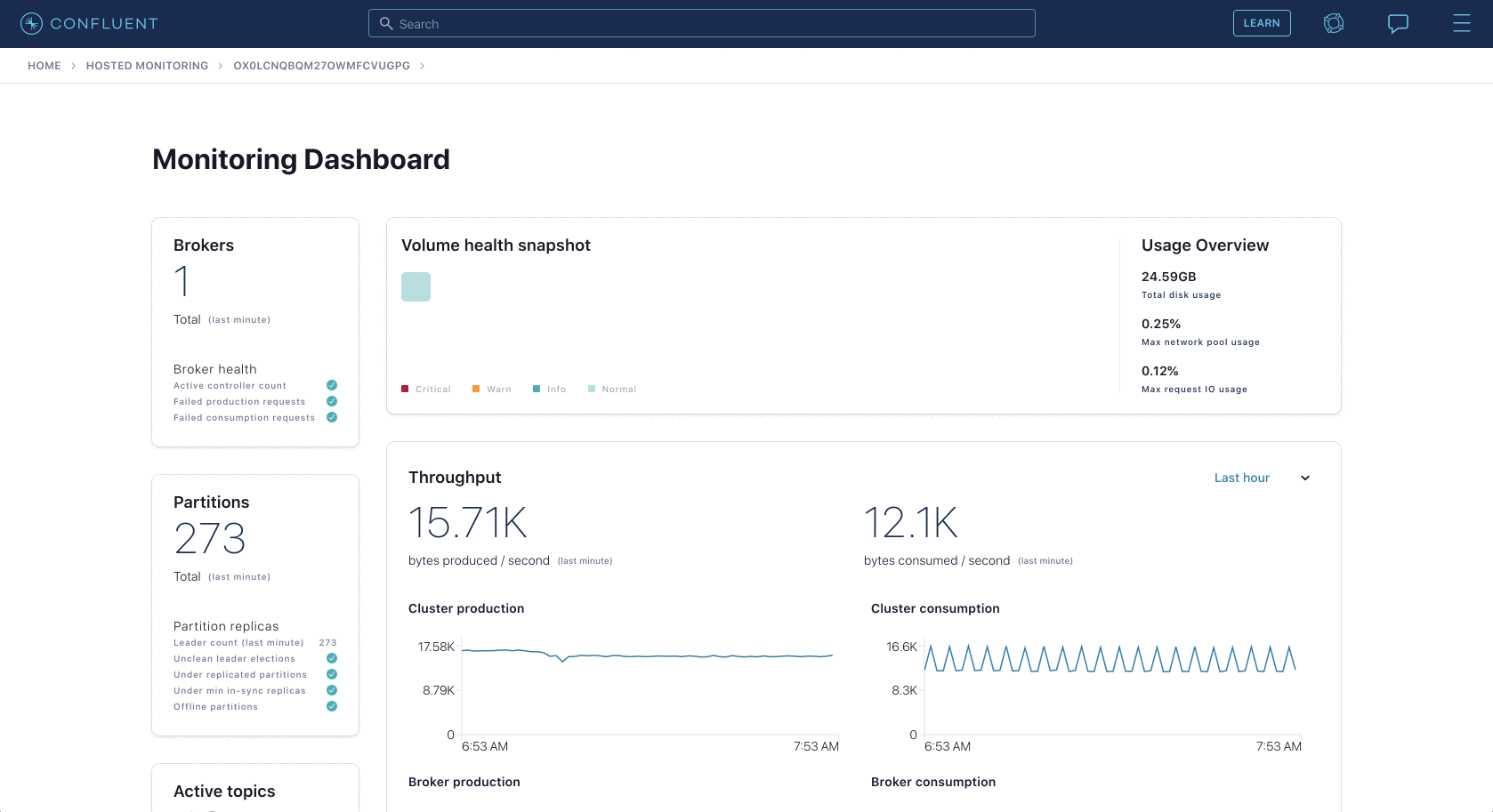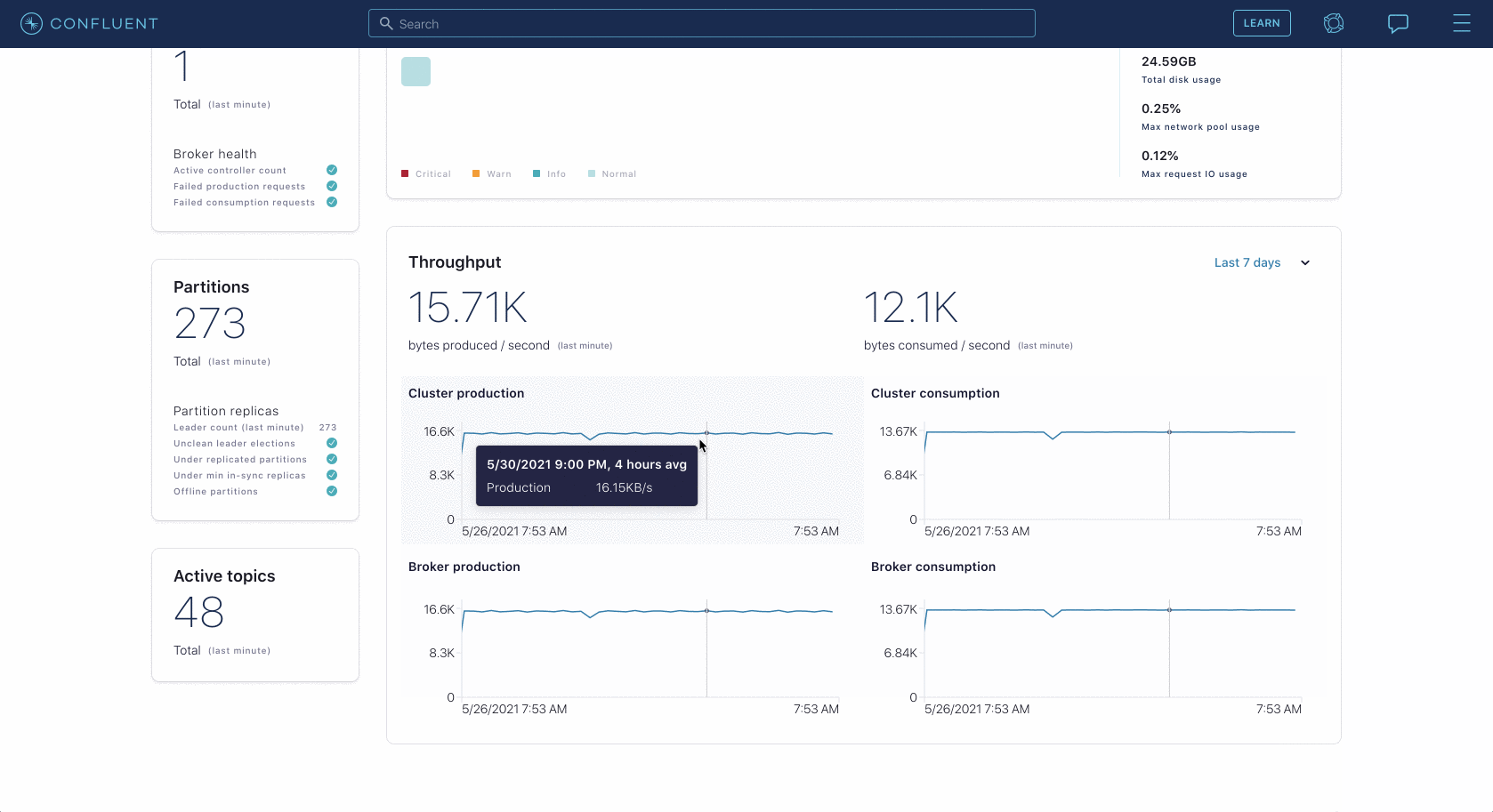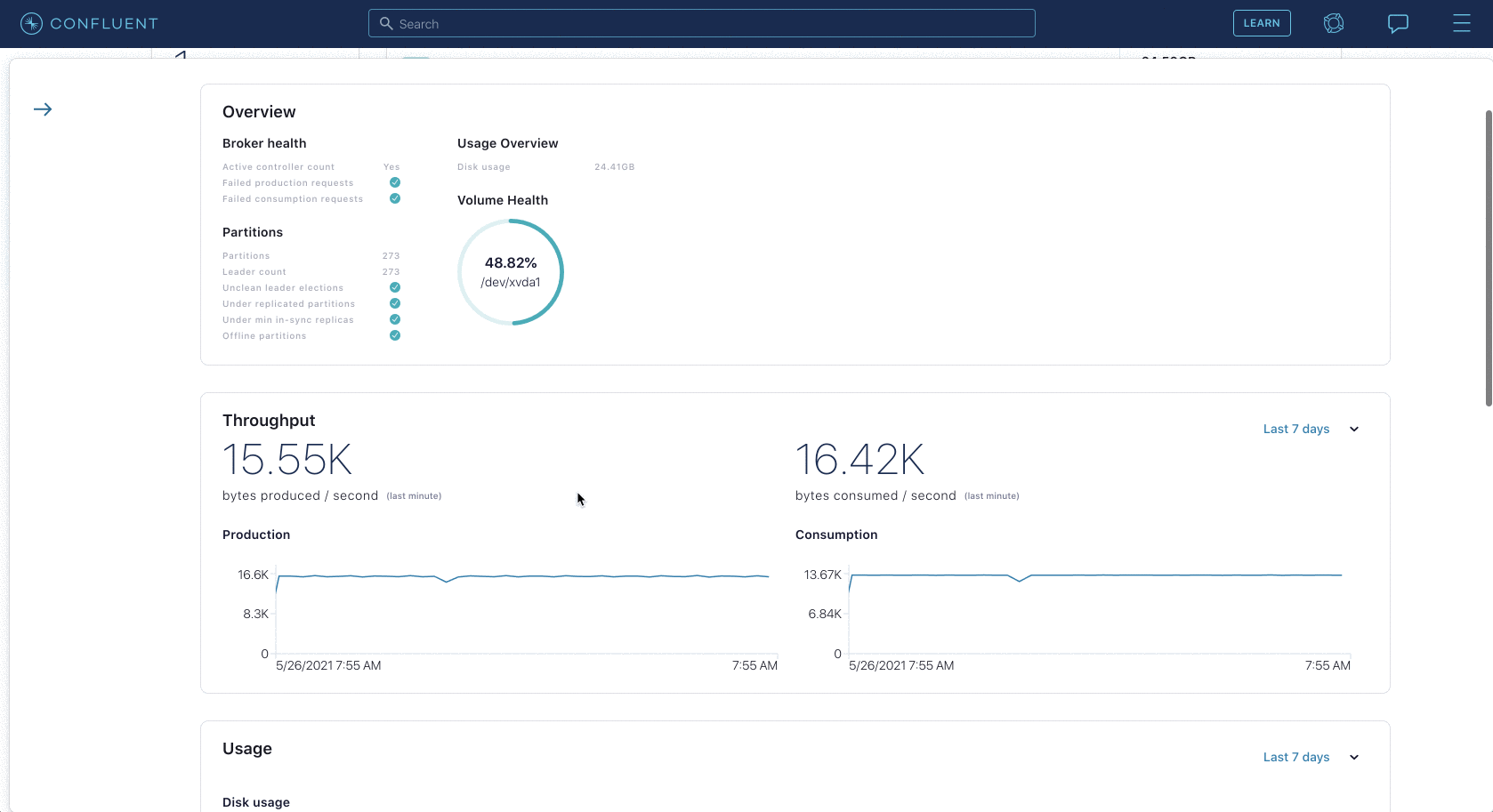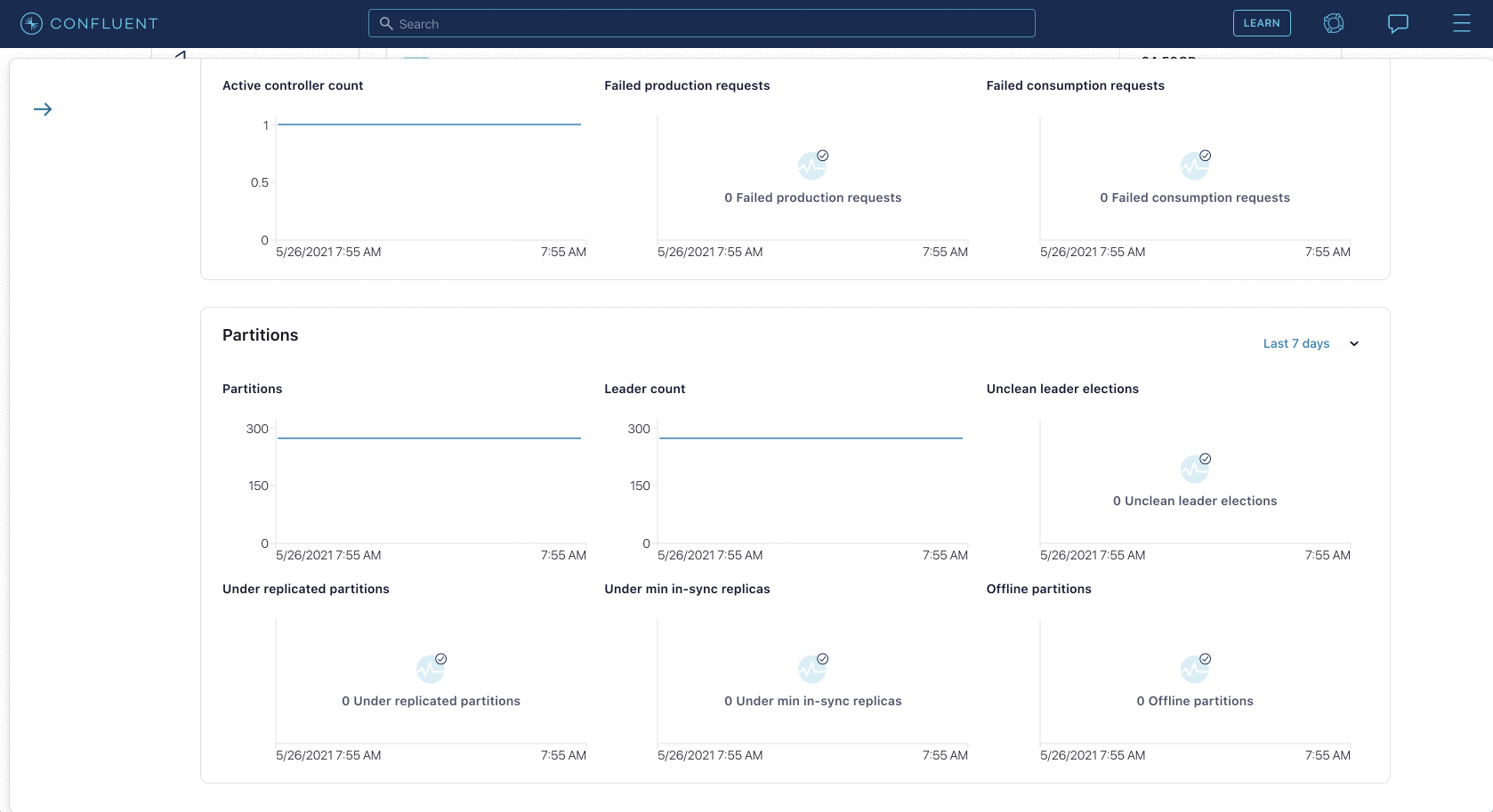
Not only can you view real-time and historical monitoring data of your connected Confluent Platform services, but you also get Confluent-backed insights and recommendations. Based on over 1 million hours of our collective Kafka expertise and extensive battle testing in our Confluent Cloud managed service, you can see what we consider healthy metrics, combined with troubleshooting details when an unhealthy state is detected.
Health+ continues to help organizations using our self-managed platform for data in motion to experience many of the same benefits of a cloud-native solution to make the troubleshooting process more targeted, efficient, and context driven.
Accelerated support experience
Supporting Kafka in-house can be significantly expensive and resource intensive, while leading to long and costly issue resolution times. Moreover, when problems do occur, the enterprise support team often lacks easy access to all the contextual information needed to help quickly identify and address issues to reduce downtime. With the latest release, we are speeding issue resolution time and minimizing business disruption with a streamlined and accelerated Confluent Support experience.
Health+ Accelerated Confluent Support: Targeted support to expedite issue resolution time
By enabling secure access of configuration and cluster metadata through Health+, we have a real-time view of performance for your Confluent Platform deployment.
The metadata provided for Health+ is much of the same data that you would send in a support ticket—it’s just provided securely on an ongoing basis to ensure the continued health of your environment. Manually sending the data is cumbersome and error prone, especially if a critical issue arises and you have to provide us the data while under duress. We have a standardized process and schemas to block sensitive information and collect only metadata, not payload/topic data.
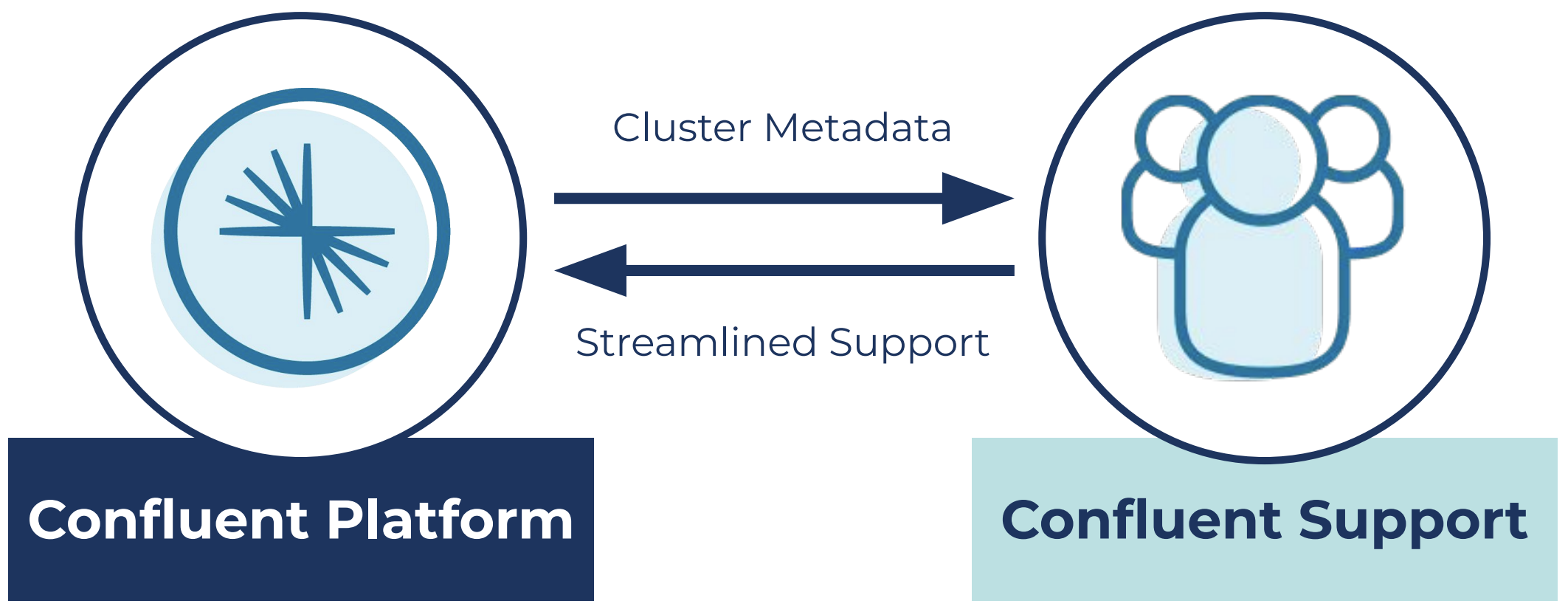
Securely share contextual data without manual entry for smoother enterprise support
Sharing this contextual information can help resolve your issues significantly faster and offloads many of the manual steps to provide targeted resolution of an issue.
You no longer need to tell us about what versions are running or which topics are being utilized. We already have that context from the metadata that your deployment is sending, allowing us to focus on the issue at hand instead of spending time building out a picture of your environment. This helps us speed up issue identification and resolution in your self-managed Confluent environments, allowing you to focus on building real-time applications instead of tending to Kafka-related fire drills and working back and forth with Confluent Support.
The new streamlined support experience helps you diagnose problems immediately and dramatically reduce time to resolution. Now you can provide Confluent experts with secure access to historical metadata to quickly assess and conduct root cause analysis on your behalf without any manual data entry.
Additional enhancements
In addition to Health+, Confluent Platform 6.2 comes with enhancements to existing features that make it a more complete platform for data in motion to implement mission-critical use cases end to end. Here are some highlights.
Cluster Linking (preview)
Last fall, we introduced Cluster Linking in preview as part of the release of Confluent Platform 6.0. Cluster Linking allows you to mirror topics from one cluster to another without any additional tooling or infrastructure, such as MirrorMaker 2.
Confluent Platform 6.2 introduces a new failover command to Cluster Linking that makes it even easier to recover from disaster events. If you create a backup cluster in another region and have synced data with Cluster Linking, you can now call failover on the backup cluster with a single command. This makes disaster recovery failover simple, intuitive, and fast, allowing operators to achieve higher recovery time objectives (RTOs) with an easier-to-manage infrastructure and to continue ensuring high availability and resiliency of your Kafka deployment.
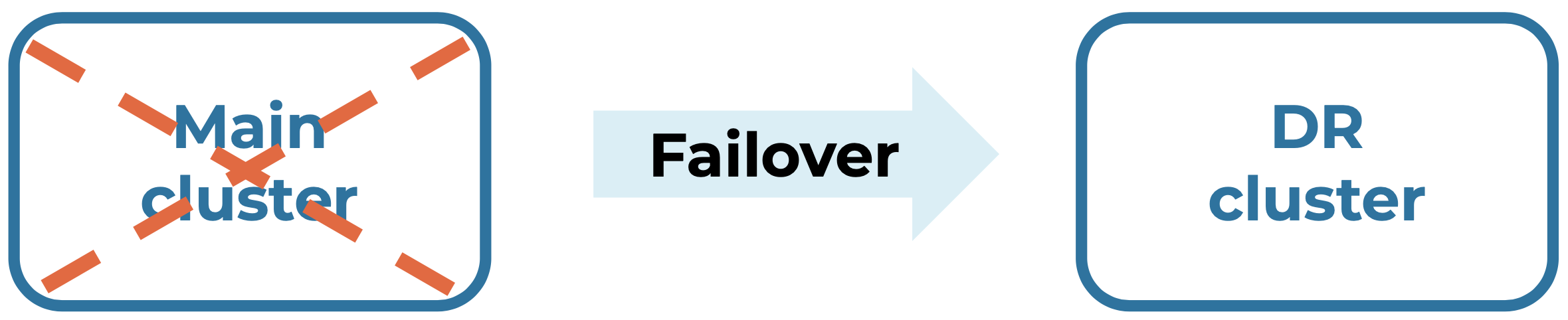
Failover command: If the main cluster goes down, call failover to stay up and running on your DR cluster
ksqlDB 0.17
Confluent Platform 6.2 also comes with ksqlDB 0.17, which includes several new enhancements that make it easier for developers to build real-time applications that leverage data in motion.
One of the biggest enhancements is that row keys now support all serialization formats. Previously, only a subset of serialization formats (Avro, JSON, delimited, etc.) were supported for row keys. Having only a subset of serialization formats available creates a disparity between key and value formats, but with ksqlDB 0.17, all serialization formats may now be used for row keys. Specifying a single serialization format to use for a given object better abstracts away underlying Kafka primitives, which makes it easier to use ksqlDB for stream processing.
With CP 6.2, any serialization format may be used for both the key and value:
CREATE STREAM s1 (x STRING, y STRING) WITH (format=’avro’);
CREATE STREAM s2 (x STRING, y STRING) WITH (format=’protobuf’);
ksqlDB 0.17 also includes a number of additional enhancements that streamline real-time application development:
- Pull queries may now target any number of rows via full table scans
- Multi-column row keys are now stored as separate columns
- Non-aggregate derived tables are now materialized and can serve pull queries
- Query migration tooling to help developers manage their SQL code is now available
- Support for in-line functions like map, reduce, and filter is now available
- Support for ARRAY and STRUCT keys is now available
- TIMESTAMP type support with associated builtins and operators is now available
For more details on ksqlDB 0.17, please check out this blog post. You can also check out the change log for a complete list of features and fixes.
Support for Apache Kafka 2.8
Following the standard for every Confluent release, Confluent Platform 6.2 is built on the most recent version of Kafka, in this case, version 2.8. Kafka 2.8 offers an early access version of KIP-500, which allows you to run Kafka brokers without Apache ZooKeeper, instead depending on an internal KRaft implementation. This highly anticipated architectural improvement enables support for more partitions per cluster, simpler operations, and tighter security. To try out KRaft with Confluent Platform 6.2 Docker images, please see cp-all-in-one-kraft, which should be used in development only and is not suitable for production.
Want to learn more?
Check out Tim Berglund’s video and podcast for an overview of what’s new in Confluent Platform 6.2, and download Confluent Platform 6.2 today to get started with a complete data-in-motion platform built by the original creators of Apache Kafka.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...