Introducing Apache Kafka™ for the Enterprise
In May, we introduced our first enterprise-focused feature, Confluent Control Center, with the 3.0 release of Confluent. Today, more than 35% of the Fortune 500 companies use Kafka for mission-critical applications and we are committed to offering enterprise-focused capabilities to further help companies in their adoption of a Kafka-based streaming platform. In that direction, I’m delighted to share the details of our extensions to Confluent Enterprise that are needed to simplify running Kafka in production at scale.
The new capabilities introduced in this new release include multi-datacenter replication, auto data balancing, which are joined by enhancements to Confluent Control Center. In this blog, I will describe these new capabilities in Confluent Enterprise.
Highly Available Multi-Datacenter Streaming
Every major enterprise has multiple datacenters. While geo-distribution is critical for higher durability and fault tolerance, it presents many unique challenges. First, your applications and hence data lives in different datacenters across the globe. Likely your applications need to access data sitting in another data center. This means that data needs to be continuously synchronized amongst data centers. In addition to data synchronization, you also need to ensure that compliance and security policies are applied consistently to all the data copies across the various data centers. Furthermore, multi-datacenter deployments need to pay special attention to security and ensure that data is encrypted over-the-wire as it leaves data center boundaries.
There is widespread demand for running Kafka to enable multi-datacenter streaming. Broadly, there are two ways in which Kafka enables multi-datacenter streaming:
- To replicate streams of events from various data centers into a central data center for analytics.
- To create synchronously updated identical Kafka mirrors across data centers to enable failover for disaster recovery.
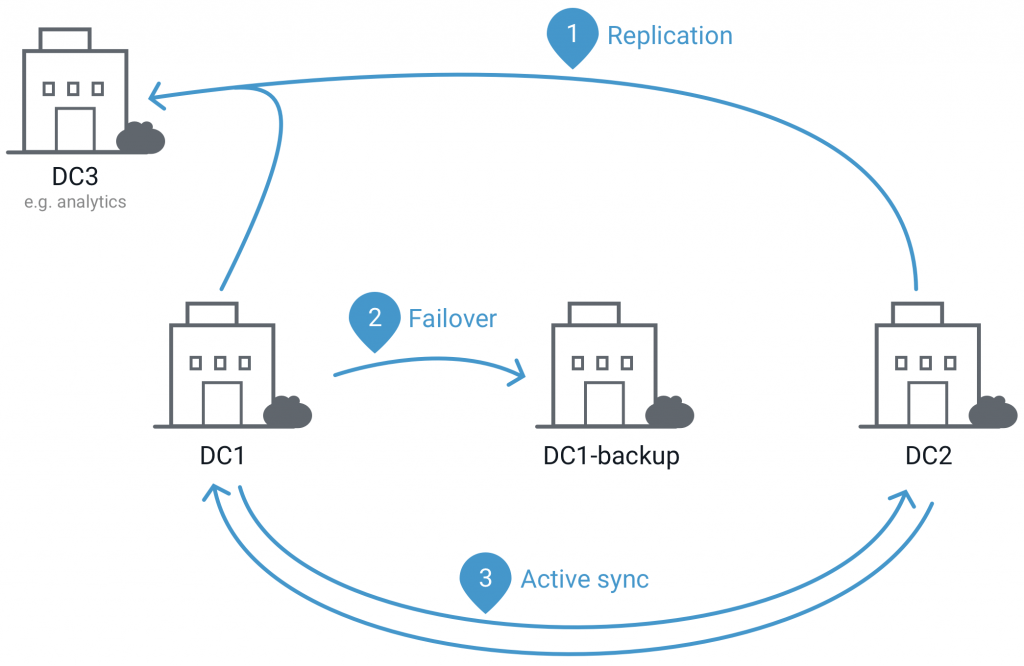
Through our own experience of running Kafka across several data centers at LinkedIn and helping several companies do the same, we have collected best practices and operational experience and have built those into the new Multi-DC (MDC) Replication feature available in Confluent Enterprise. In this first release, MDC Replication addresses the first use case outlined above for multi-dc streaming — making the process of deploying Kafka to replicate event streams into a central data center for analytics much simpler.
MDC Replication is built using Kafka Connect and enables the following things:
- Offers centralized configuration and management of multi-datacenter Kafka deployments
- Enables highly-available and durable cross-datacenter replication
- Integrates with security capabilities in Apache Kafka to encrypt and authenticate replicated data
- Makes it easy to set up identical Kafka mirrors across datacenters by replicating authorization and topic configuration settings
- Allows replicating entire clusters or a subset of topics, including renaming topics on the fly
Learn more about MDC Replication in this comprehensive reference architecture for Enterprise Kafka written by Gwen Shapira.
Using Confluent to manage your transition to the cloud or back
MDC Replication is relevant to enterprises for achieving another significant objective — managing the migration to the public cloud. Every organization is planning (or already implementing) a migration to the public cloud. This transition takes several years, presents new set of challenges and requires careful engineering to do correctly and efficiently.
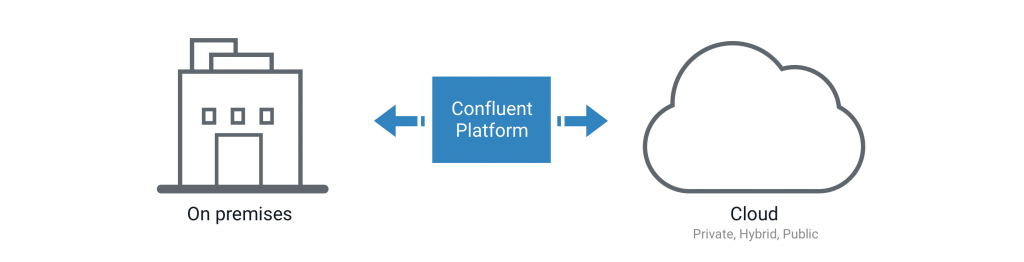
MDC Replication significantly simplifies the process of migrating your applications and their data to the public cloud. The core idea here is that instead of building point-to-point pipelines for every application between the on-prem data center and the public cloud, we make sure all the necessary data is centrally available in a Kafka cluster in our on-prem data-center. Then we use MDC Replication to stream all the data from the on-prem Kafka to a second Kafka cluster in AWS. From there, it is available for each application and datastore that needs it.
There are several advantages to using Kafka in this manner to create a streaming pipeline to the public cloud — centralized management and monitoring, continuous, highly-available, fault-tolerant and low-latency replication, security and compliance as well as significant cost savings.
Learn more about this reference architecture in this blog post that outlines how you can use Apache Kafka to migrate to AWS Cloud. In addition, we also offer professional services to help you manage multi-data center deployments as well as migration to AWS Cloud.
Automatic Data Balancing
The second major addition to Confluent Enterprise is the automatic data balancing capability. This is a long-awaited feature useful for operating Apache Kafka in production.
If you are using Apache Kafka in production, you are likely not balancing your workload across your data center resources. Instead, you accept a loss in performance and efficiency in order to avoid the risks associated with trying to balance load by hand. This means that while some nodes are not doing much at all, others are heavily taxed with large or many partitions, slowing down message delivery and possibly overrunning the system. Furthermore, balancing load by hand runs the risk of overwhelming a cluster and saturating network and I/O bandwidth while moving large amounts of data. So care should be taken to throttle the data movement required for load balancing to ensure that produce and consume SLAs are not violated.
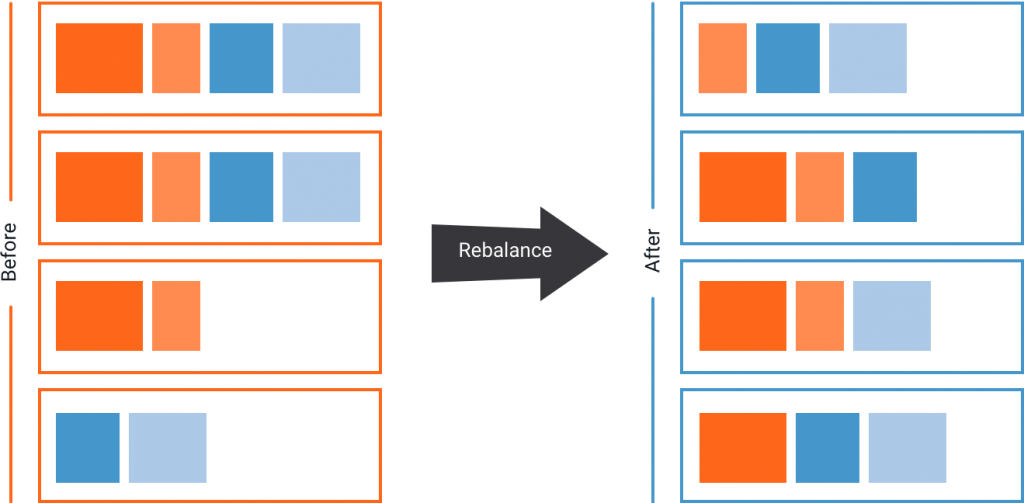
Confluent Enterprise helps you ensure optimal performance through auto-data balancing. When executed, this feature monitors your cluster for number of nodes, size of partitions, number of partitions and number of leaders within the cluster. It allows you to shift data to create an even workload across your cluster. It also integrates closely with the quotas feature in Apache Kafka to dynamically throttle data balancing traffic. The Auto Data Balancer allows you to make your Kafka cluster efficient, without the risks of moving partitions by hand.
Multi-Cluster Alerts, Monitoring and Control
In line with this emphasis on making your data reliably and efficiently available, even across geographically dispersed clusters and datacenters, the latest release of Confluent Control Center incorporates new multi-cluster monitoring and alerting features to assure that data being produced into Kafka is being consumed, within your defined latency constraints, at its intended destination.
Confluent Open Source and Confluent Enterprise
Starting with the 3.1 release, we’ll be splitting Confluent Platform into two packages — a pure open source download and an enterprise offering. We’re doing this to make it easy for people, who want the pure open source distribution, to easily start with just that.
Confluent Open Source is 100% open-source and includes Apache Kafka, as well as software that is frequently used with Kafka. This makes Confluent Open Source the best way to get started with setting up a production-ready Kafka-based streaming platform. Confluent Open Source includes clients for C, C++, Python and Go programming languages; connectors for JDBC, ElasticSearch, and HDFS; Schema Registry for managing metadata for Kafka topics; and REST Proxy for integrating with web applications.
Confluent Enterprise takes this to the next level by addressing requirements of modern enterprise streaming applications. It includes Confluent Control Center for end-to-end monitoring of event streams, MDC Replication for managing multi-datacenter deployments, and Automated Data Rebalancer for optimizing resource utilization and easy scalability of Kafka clusters.
Register to be Notified When Confluent 3.1 is Released
This improved release of Confluent will ship at the end of October. Register for this online event to hear one of our experts provide the final update live, as well as to receive an email notification when the release is posted on our site.
If you are interested in learning about Apache Kafka, stream processing and putting it to practical use in a company, sign up for the recently launched free online talk series.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...