[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Getting Started with GraphQL and Apache Kafka
GraphQL and Apache Kafka® are sometimes troubled with misconceptions. One of the reasons for this is that people are often familiar with one but not the other. GraphQL is mostly used in the frontend with the server part most often implemented in Node.js. Kafka is often used as an integration layer between backend components. By clearing up some of the misconceptions around these technologies, we will gain better insight into how both technologies can be used together. Using them together is a way to bridge the gap between backend and frontend code, by making the data on Kafka easily accessible in a familiar way to the frontend.
GraphQL basics
GraphQL is a query language originally from Facebook that is now open source. The common way to implement GraphQL is by having a single endpoint to process all of the requests. The type of requests that can be handled by a server and what they take as input and output is described in a schema. With GraphQL, you always need to specify what and how you want the output to be. This can help to reduce traffic, and also paves the way for smooth deprecation. For example, a field name might be replaced by firstName and lastName. Here is what it looks like simplified in a schema:
type Person {
@deprecated
name: String
firstName: String!
lastName: String!
}
The server could support all three for some time, while the clients can move to the new fields when they want to. Once there are no requests for the name field anymore, it can be removed from the server.
It’s possible to declare that fields will never be empty to prevent unnecessary null checking. In the example above, name might be null, but lastName can’t be null. The GraphQL schema needs to be fully typed and might contain comments to explain how they work. While the GraphQL query has its own syntax, the result is always returned as JSON.
Introspection is part of the specification, so by doing specified queries, the schema can be retrieved from the same endpoint, which is used for the actual queries. This is quite powerful as it can be used to generate code easily, without having to deal with versions or other factors to match a certain specification with a certain endpoint. This also makes it clear which schema is used in production and what is available in, for example, an acceptance environment.
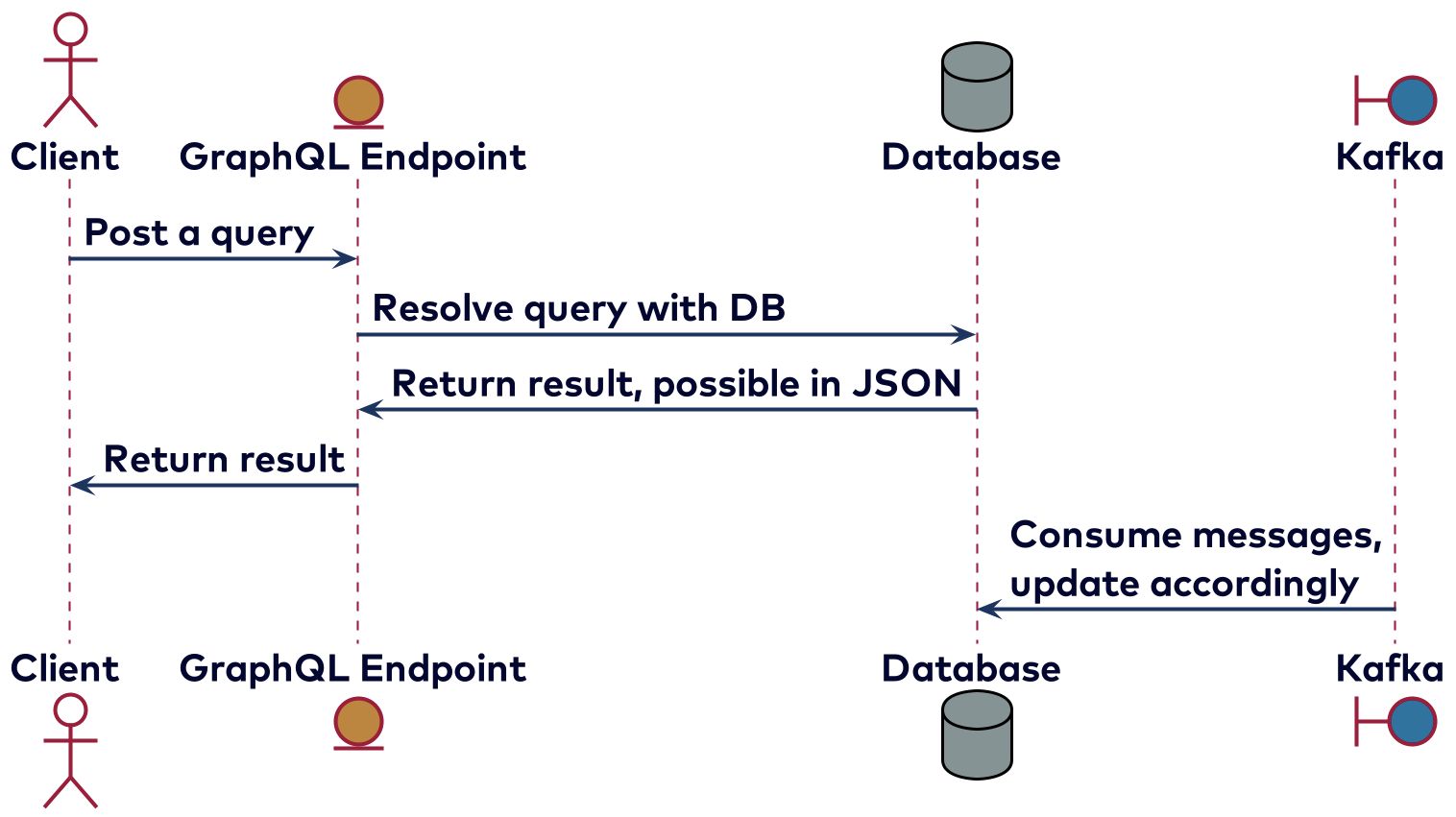
The GraphQL spec describes three kinds of executing operations: query, mutation, and subscription. These are roughly self-describing. A query is mostly meant to fetch data because this won’t change anything—multiple queries could be executed in parallel. Most of the time a database will be used to resolve the queries, but there are other possibilities, like getting the result by calling a REST endpoint of another service. The picture below shows the sequence diagram of using GraphQL to resolve a query using a database.
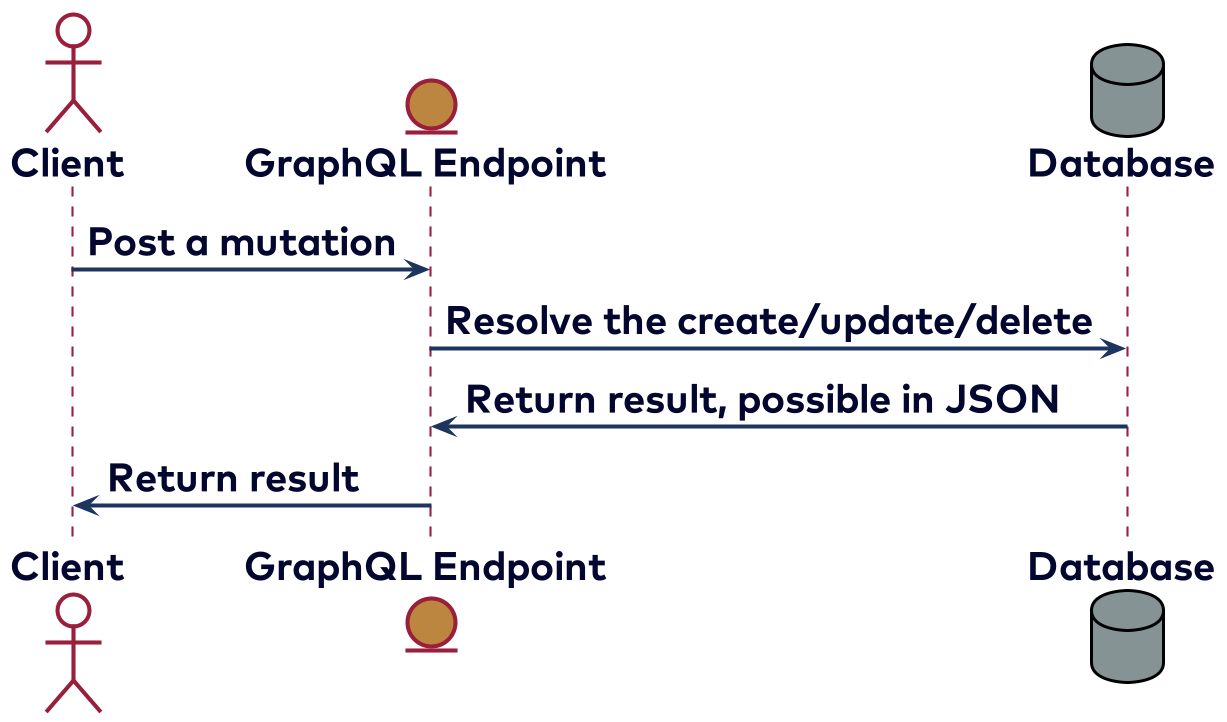
Mutations are meant for changing things, like sending a message or updating preferences. Because they might influence each other, mutations are handled serially. While not part of the GraphQL spec, queries and mutations are often implemented as a single HTTP call, where the body of the response will contain the requested data and, optionally, errors. Some clients and servers also support using WebSockets for queries and mutations. A mutation happens as shown in the picture below, where steps 2 and 3 might be repeated when multiple mutations are present in the payload received from the client.
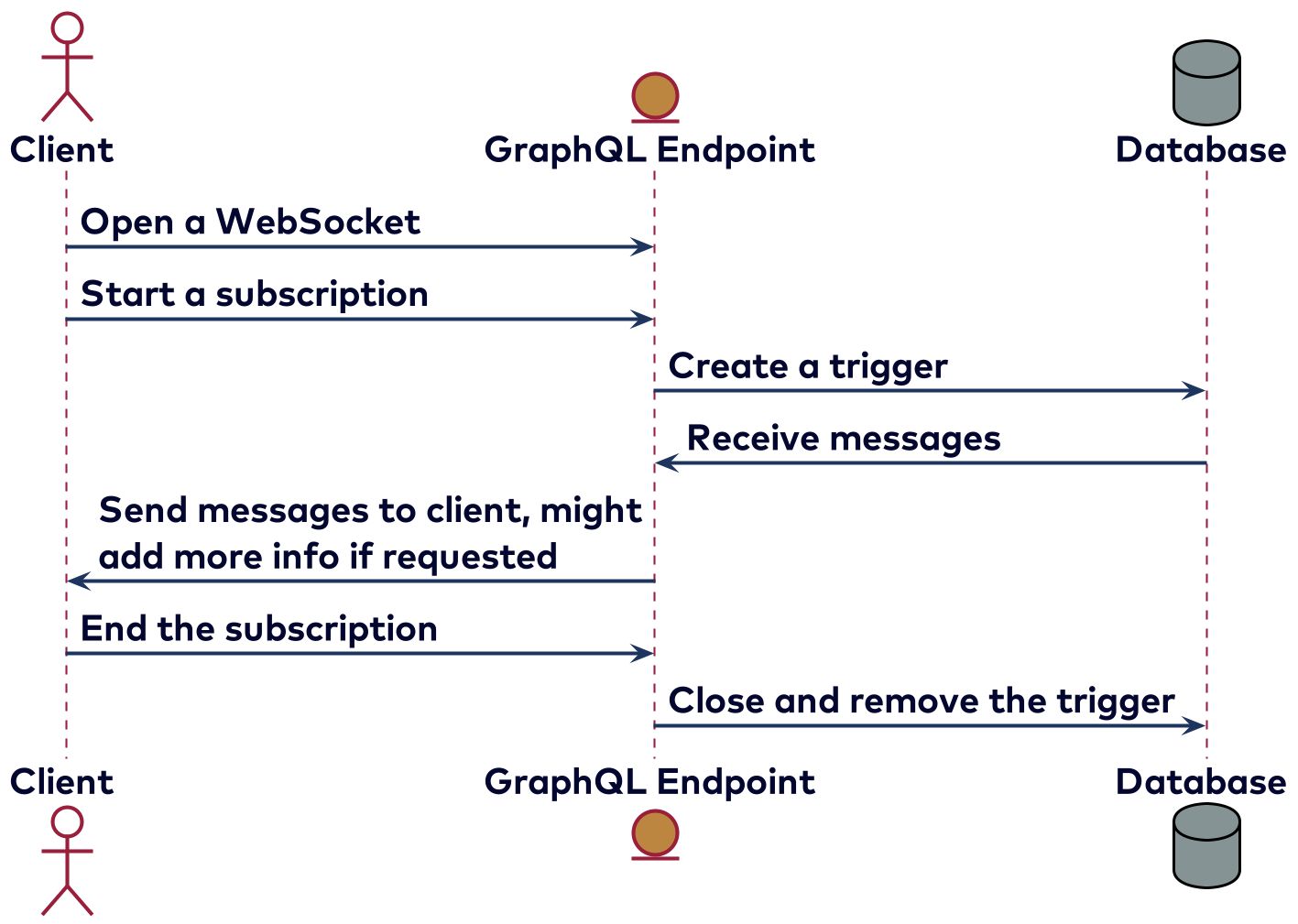
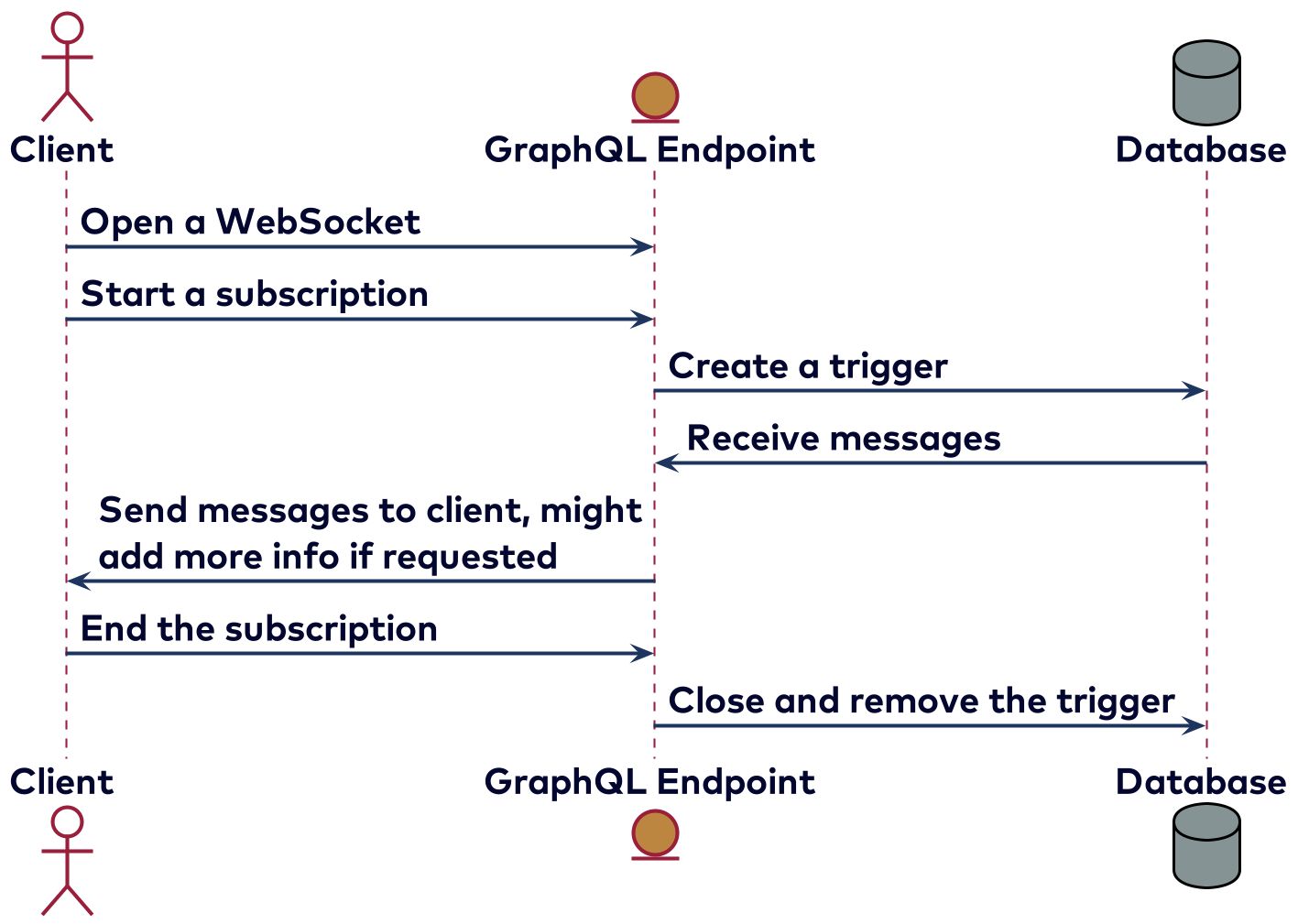
Instead of having a single response, a subscription will return an event stream. Although they are usually implemented using web sockets, using server-sent events is also possible. A simple example of a subscription is receiving messages in a chat application. Here the client might be interested in only receiving the messages from one channel and all direct messages. Because subscriptions are stateful they are harder to implement, and not all clients and servers support subscriptions. Some clients also might not be compatible with some servers—this is mainly because there is no clear specification to implement GraphQL over websockets, since GraphQL is protocol agnostic. There are multiple ways to implement subscriptions depending on how to create the stream. For example, it’s possible to poll using a timestamp, or to set a trigger in the database. It might look something like the diagram below.
There is a lot of content available about what GraphQL is, but this post covers the general concept. Now we’ll dive into some common misconceptions, and clarify each of them.
GraphQL misconceptions
GraphQL needs a graph database
This confusion is understandable, as they both seem to be about graphs. With GraphQL, you are free to implement the resolvers, which are the functions that do the actual work. It doesn’t specify anything about how the data is actually stored, and it’s not uncommon to use GraphQL with relational or document databases. It’s even possible to generate a schema based on a relational database, like Hasura or PostGraphile, where the resolvers are generated based on the tables. For document databases, similar things exist, like Mongoose for MongoDB. It’s also available for graph databases like Neo4j, Dgraph, and FaunaDB. So while a graph database is certainly an option, it’s not a requirement. If the data is very much like a graph, then it might be an option worth exploring.
GraphQL is owned by Facebook
This could be a problem if you invest deeply in tech and it might be abandoned or developed in another direction by the owner. While GraphQL was originally developed by Facebook in 2012, it was open sourced in 2015. In 2019, the GraphQL foundation was created in order for the specification and reference implementations to evolve. A lot of companies are members of this foundation. With this in place, the future looks good even if Facebook decides to stop using GraphQL at some point.
GraphQL is better than REST
You can find opinions on the web from people who are so excited by GraphQL that they think that it’s better than REST or will even replace it. For example, see articles by Prisma and Apollo, with Hasura, Imaginary Cloud, and Google being more subtle. We won’t dig too deep into this comparison, but there are a few reasons why GraphQL might not be a good fit compared to REST, for example, for server-to-server communication, especially if you want all of the available information. In this case, GraphQL causes a lot of overhead on both the client and server side compared to REST. Another major downside is the availability of the tooling around authentication, caching, monitoring, and such. Although it is improving all the time, there is simply less available because it hasn’t been around very long. GraphQL might also be confusing for clients to start with, especially once the schema becomes large. With REST, this is easier—you could have an OpenAPI definition with only the endpoints relevant for specific kinds of users, or you could even share the endpoint relevant for them to use.
GraphQL is just for frontend
It’s certainly one of the areas where GraphQL is used a lot. The Apollo client library provides a full solution for managing application state and is one of the most mature clients available. There is an area where GraphQL might be even better suited, and that’s for mobile apps. In contrast to the web, they are harder to update because some of the users have automatic updates disabled. Users might have a slow connection or limit for how much data can be downloaded, so preventing over-fetching is also more important here. Something that web and mobile apps have in common in the context of this blog post is that it’s likely a bad idea to connect them directly to Kafka. Confluent REST Proxy is a REST alternative that can be used to enable access to Kafka from a browser.
GraphQL is only for JavaScript
It’s certainly true that the Apollo GraphQL client for frontend is one of the most used client implementations of GraphQL. As a server, the Apollo Node.js implementation is also frequently used. However, currently there are GraphQL client and server implementations available for most major programming languages. Lacinia (a Clojure server implementation) and GraphQL Kotlin (a Kotlin client and server implementation) provide good experiences on the Java virtual machine (JVM). Recently, Netflix open sourced DGS, which is specifically for Spring Boot, and it looks promising. Spring GraphQL is in a milestone phase towards a 1.0 release which could be interesting as well.
Kafka
Kafka was developed at LinkedIn to provide a shared layer to connect backend services. This way a service could just put the data in Kafka instead of having specific connections, possibly with different formats, for each service that needed the data. Data in Kafka is produced in the form of records—these have a key, value, headers, and some metadata, like a timestamp. Both the key and the value are in binary format, so some coordination between producers and consumers is needed to be able to read the data. Check out the free Apache Kafka 101 course on Confluent Developer to learn more about the basics of how Kafka works.
Kafka misconceptions
Kafka is just a message queue
In essence, this is kind of correct, as Kafka’s main use case is to decouple sending a message by a producer from consuming the messages in a streaming fashion by another app, which is a consumer. The concept of topics is used to handle different streams of messages. Contrary to traditional message queues, however, the retention period of the messages is independent of how or when they are consumed. This way, multiple consumers can read the messages from the same topic. Topics can be configured in such a way that the last message with the same key will always be retained. For example, this can be used to get a stream containing user setting messages, where for each user the latest settings will always be available.
Another major difference with most queues is the huge ecosystem that has been built around Kafka. For example, with Kafka Streams, it’s easy to use the stream of settings and combine it with a stream of transactions that a user might want a notification of in order to create a stream with notifications. Another example is Kafka Connect, which makes it easy to import and export messages to and from other data sources. You can use this for change data capture (CDC) with databases. The mutations done by an application on the database can be captured as events and put on a Kafka topic. Because multiple consumers can easily consume the same topic, this might be a good scalable fit for GraphQL subscriptions.
Kafka can’t be used to mutate data
The messages in Kafka are immutable, so this is somewhat correct in the sense that once a message has been successfully sent to a Kafka broker, the message can’t be changed anymore. However, that doesn’t mean it can’t be used to do mutations. The simplest way to mutate data is to add a message with the same key but with an updated value. If such a topic is connected to a database, the old message can be overwritten in the database.
More complex patterns are also possible, such as CQRS. With CQRS, the reads are separated from the writes so that data can’t be changed directly. A CQRS architecture could be implemented in the following way. In order to mutate information in the system, a command type of message will be put on Kafka. An application handling the command might in turn produce event messages if the proper conditions are met. Another app can consume those events and thus build a projection of the system. This projection can be used to handle the queries. In this case, we need all of the events to build the projection, which is also why such a setup is called event sourcing. The second proof of concept will use such a setup.
Kafka is hard to maintain
It’s certainly not easy to set up Kafka properly or to properly manage it as use grows over time. This does not need to be a reason to not start using Kafka, as there are many managed solutions available. By using a managed service, like Confluent Cloud, time can be saved on setting up and managing Kafka.
It’s not possible to do queries on Kafka
The main use for Kafka is streaming, where consumers can start from a certain point and receive all the messages that are added after that message. By using either Kafka Streams or ksqlDB, it’s possible to quickly get a message for a certain key. For more complicated queries, you can stream the messages to a database and execute the queries on the database. It’s also possible to use either Kafka Streams or ksqlDB for more advanced queries. For example, you can compute aggregates over multiple messages or combine multiple topics to add information.
Connecting GraphQL and Kafka
Combining GraphQL with Kafka can be challenging as a lot of the implementation details are not straightforward. A good implementation depends on factors like how Kafka is used within a company, the demands of the clients, and nonfunctional requirements like security and scalability. We’ll break this down a bit and cover two different kinds of proof of concept.
Fundamentally, we must determine where the types for the GraphQL schema should come from. The schema can be created manually or created based on the schema of the messages on Kafka. The schema used for the messages on Kafka might be registered in Confluent Schema Registry, making it easy to access them and know the relation between the stored schemas and the topics. It might also be loosely coupled with the schemas stored in Git, for example. In this case, it’s still possible to use the same schemas for building a GraphQL schema, but because there are so many ways to do this, it will be much harder to build tooling around this.
It’s possible to create the schema such that it fits the client use case. This requires additional work but has some advantages. Certain fields might be left out, for example, fields that contain confidential information. Some fields might also be changed to make them easier to use; dates or currencies might be changed to properly formatted strings to make it easier to use them in apps. The type information on Kafka might already be available if Schema Registry is used. Those types can be reused to dynamically create the schema and also allows most of the resolvers to be generated automatically.
Additional information might be needed to connect multiple types. For example, if there is a topic with users and a topic with alerts for users. This relation might not be obvious from the schema. The user type might have an id field matching the userId field of an alert type. But this relation might as well be created by using specific key values. This is not required; a flat schema with just the types for all of the topics exposed through GraphQL might be enough.
How you handle topics is related to their types. If one type of message always goes to the same topic, then it’s straightforward to know the correct topic based on the type. If the topics are more dynamic, it becomes harder. An example of this is multi-tenancy, where depending on the credentials used a different topic has to be used. By leveraging ksqlDB, it’s possible to get the type information for any topic. Using ksqlDB to get the types has some disadvantages, including that ksqlDB doesn’t support multiple message types on the same topic yet.
Because Kafka is made for streaming it seems to be a perfect fit with GraphQL subscriptions. Sometimes there might be valid reasons to skip this, like scaling performance. GraphQL subscriptions are often implemented using WebSockets, which require a long-held connection between the client and server and introduces some challenges. At Kafka Summit Europe 2021, the talk Delivering: From Kafka to WebSockets covered scaling WebSockets. When the traffic is low, this might not be a problem. With GraphQL, it’s possible to add arguments when opening a stream. This can be used to filter messages on the server, such that not every message from Kafka is sent to all subscribed clients.
An architecture where Kafka is used to implement the subscriptions while the queries and mutations are implemented using a database could also be viable. This might be combined with Apollo Federation, as explained in Using Subscriptions with Your Federated Data Graph, such that properties of the Kafka message can be used to fetch additional information. There is a limit on how many concurrent subscriptions can be handled depending on the implementation. Before going all in on Kafka with GraphQL subscriptions, it’s a good idea to create a proof of concept of a single stream and test its limits.
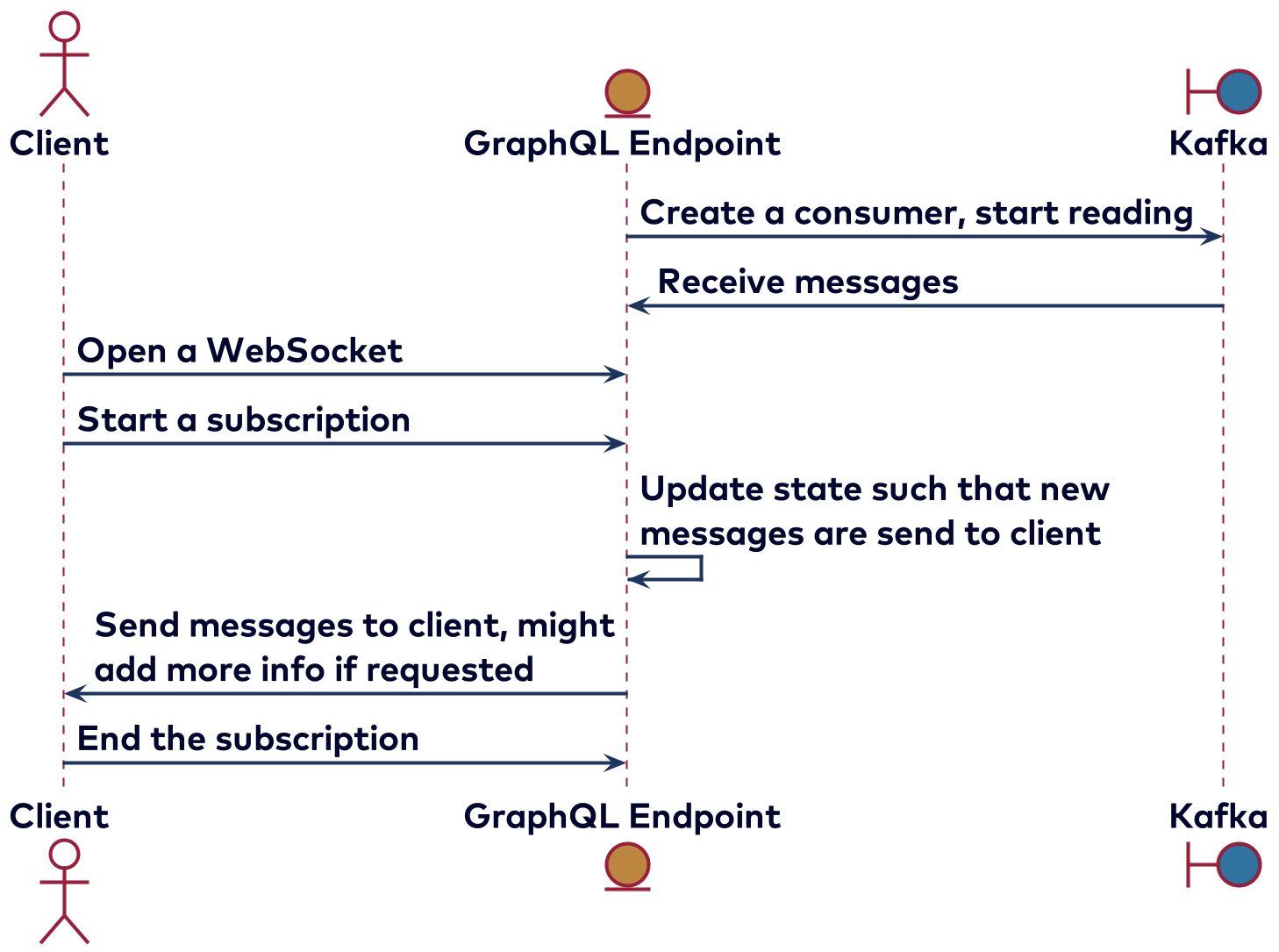
A simple way to implement subscriptions is by creating a Kafka consumer for each subscription started. This could be a viable solution when there will be only a few clients. Starting a new consumer for each subscription also has the advantage of being able to read from the start or use specific consumer groups based on the authentication. Consumer groups help with scaling and storing specific offsets for different consumers. It’s risky to rely on this trough, given that the protocol used for subscriptions has no mechanism to know if a message has reached the client correctly. Such a setup would look like the diagram below.
Mostly for scaling reasons, it’s probably a better idea to start consuming from Kafka directly. The disadvantage is that consumers might miss messages. Depending on the use case, this might be fine, such as if a client can get the last 10 messages by doing a query. The subscription can then be used to keep the view up to date as new messages are produced to Kafka and received by the client via the subscription. Such a setup can be roughly visualized via the diagram:
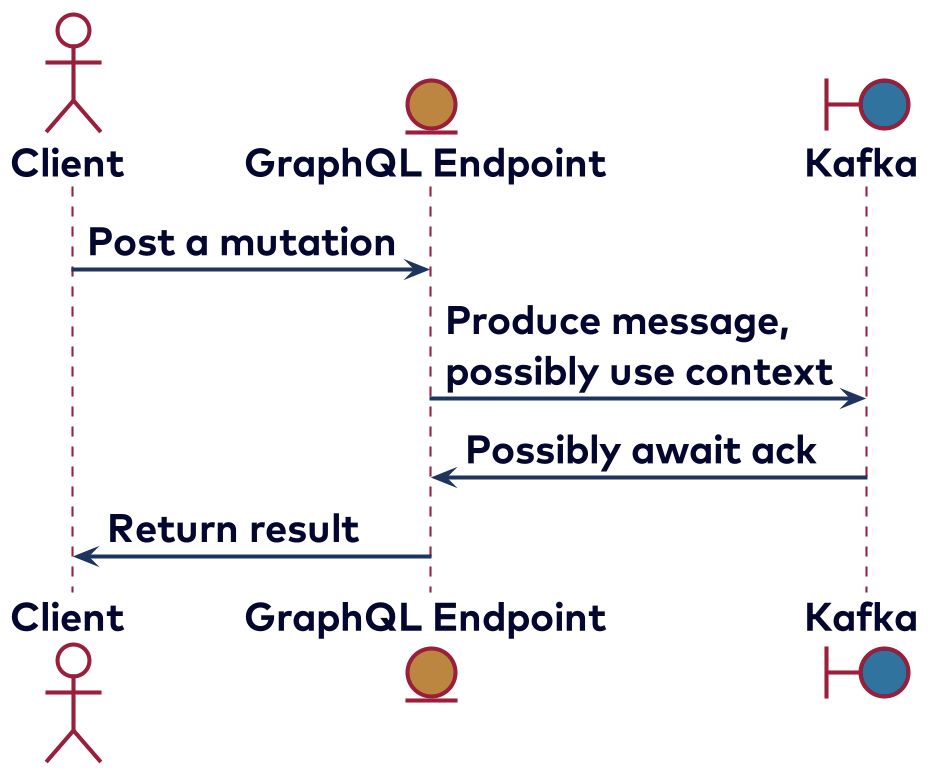
Mutations in GraphQL can be implemented by producing a message to Kafka, such as when initiating a transaction in the proof of concept using the information supplied to create the message together with the context. This still begs the question of what to return, and there are several possibilities. Most GraphQL implementations are based on a database, and in that case, the new or mutated entity will be returned. You could use this to get an ID back, which might be used for further requests. With Kafka it’s less straightforward. One possibility is to simply send back true if a message was indeed created and the produce method was called. We could also wait to get the acknowledgement from the broker and optionally also return the partition or timestamp of the message. This would look like the diagram below:
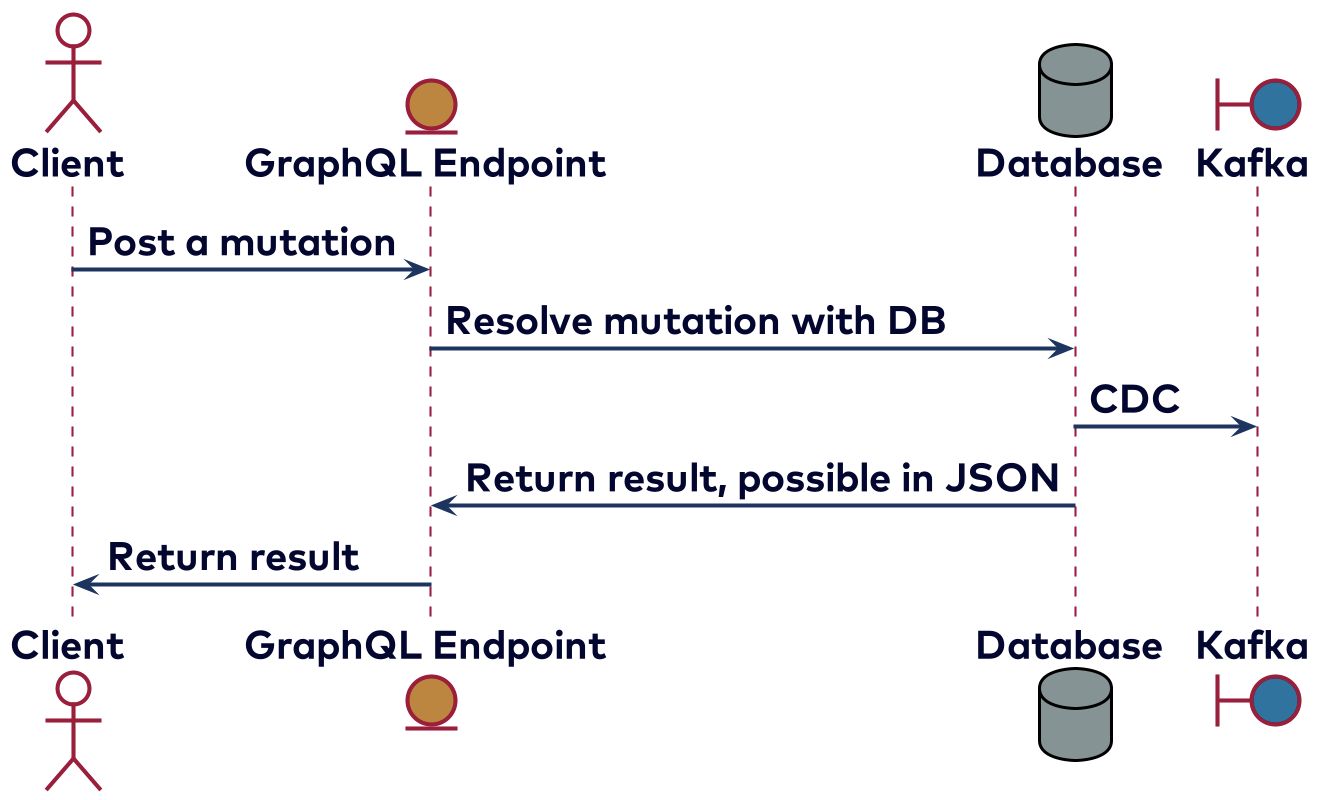
Another viable approach is to implement the GraphQL part in a more traditional way, directly against a database. Using change data capture will still get the changes as messages to Kafka such that other services might process the changes made. Below is a simplified diagram of how this would work.
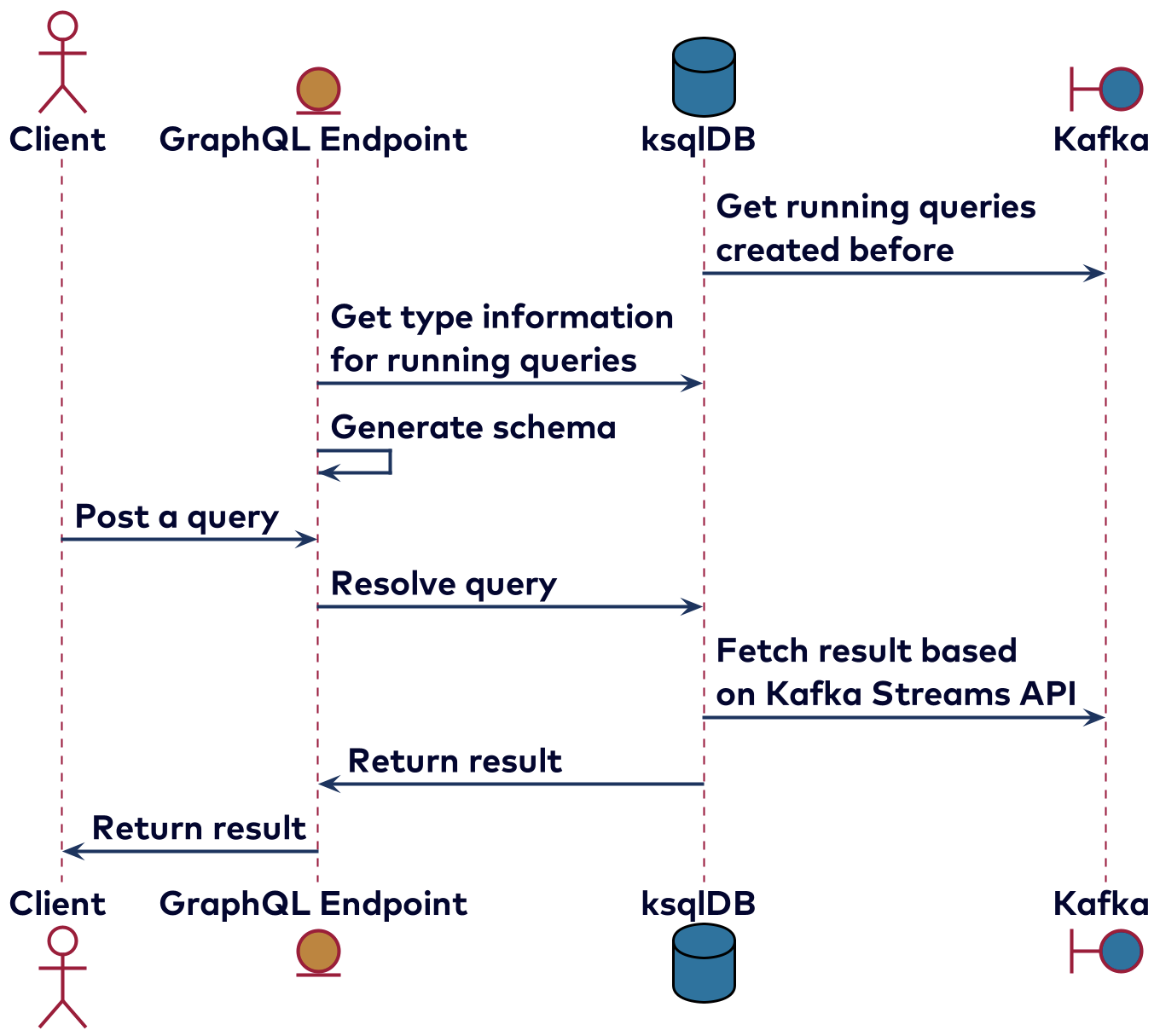
The hard part about implementing queries is that even a query using a key is not possible with the Kafka API. Using only Kafka, the best we can do is consume all of the messages and filter on the key, which is very inefficient. Kafka Streams or ksqlDB can be used to handle queries to some degree. In this case, intermediate topics might be used with the data eventually being stored on RocksDB instances. This allows for quick access to the data by key. This implementation could look like the diagram below:
More complex queries can be handled by storing the messages in a database. This can be done using Kafka Connect (or with consumers when mapping a message to the database might be less straightforward, like when CQRS is used). Instead of simply overwriting a database entry with the same key, it should mutate the entry in a specific way. The flexibility of GraphQL resolvers makes it possible to implement the subscription and mutations directly on Kafka and use database queries to implement the queries. In this case, it is important that the data might be only eventually consistent. Thus, it might take some time before a mutation has been processed such that the result can be queried. If you are mainly interested in using queries, the Cost-Effective GraphQL Queries Against Kafka Topics at Scale talk could be interesting.
The final implementation detail that we’ll cover is authentication. One of the most commonly used ways to add authentication to GraphQL is by using JSON Web Tokens (JWTs). These can be validated, and any additional properties can be added to the context. Using JWTs make it possible, for example, to add the email from the context extracted from the JWT to the messages put on Kafka. It can also be used to filter messages received on a Kafka stream by user ID. A more complex way of setting authentication and authorization might be needed, like adding horizontal authorization by adding an API key. Note that authentication is not set up in the two examples we will cover in this blog post. There are some additional security concerns, some specific to GraphQL, that you might want to take care of as well. This checklist by Khalil Stemmler explains seven additional concerns.
Proof of concept
We’ll now dive into two proofs of concept, along with some of the pros and cons of the setup. Both projects are available on GitHub and should be easy to set up locally using Docker. One is centered around ksqlDB and the other around event sourcing. The projects have GitHub discussions enabled if you have any questions or suggestions. They can be used as inspiration on how to implement GraphQL combined with Kafka. These projects have not been tested at scale in production and might lack other non-functionals required to run in production. These examples implement all three executing operations available in GraphQL to demonstrate what is possible.
The first project was set up in order to get acquainted with ksqlDB. The main branch is a bit more complicated, but is not compatible with the current version of ksqldb-graphql. Because that project was used to create practically the whole GraphQL endpoint, I simplified it a bit in the “just-persons” branch. The complete project, ksqlDB-GraphQL-poc, can be found on GitHub. It uses a setup with Docker Compose to bring up a data cluster, create some topics and schemas, and define a table and some streams in ksqlDB. It then uses the REST API on ksqlDB to dynamically create the GraphQL schema and the resolvers. It’s a quick way to start using GraphQL, which through the ksqlDB API can be quite powerful. This solution does require you to run ksqlDB, which is part of the Confluent Platform and licensed under the Confluent Community License. Below is an overview of the project.
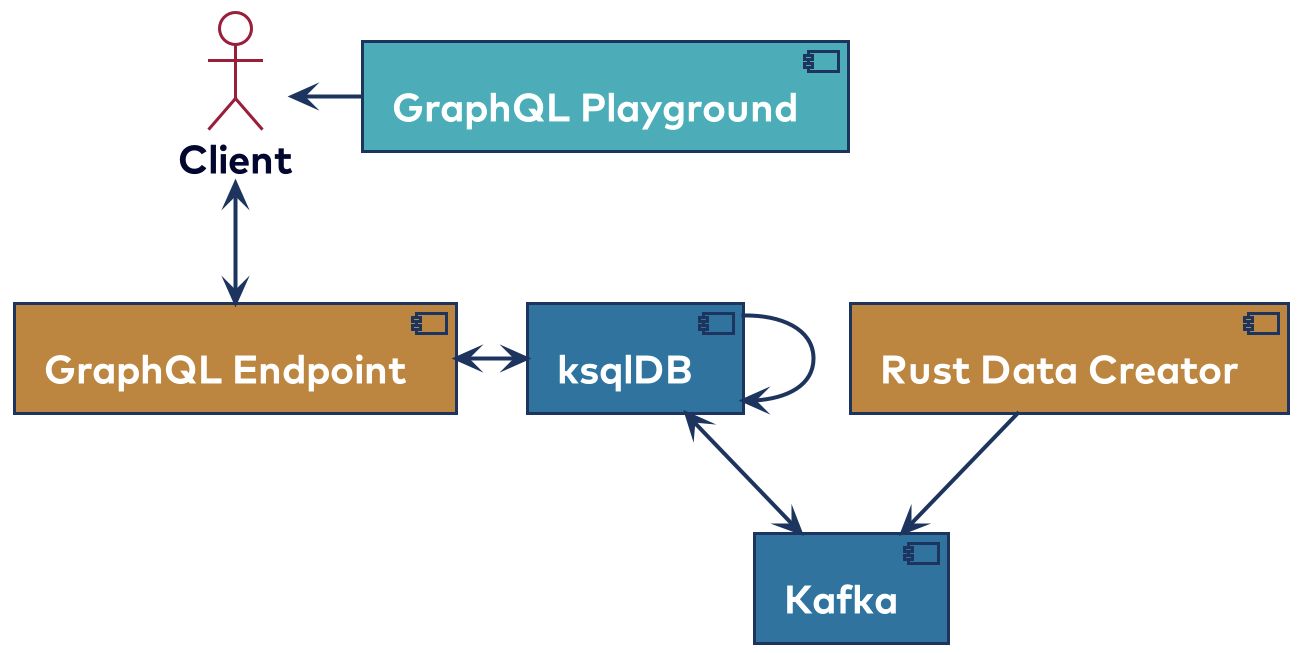
The data created from the data creator will be persons, one every five seconds. ksqlDB will read those and create tables, both for all the persons by ID, and use a SELECT to get the total number of persons by birth year. The ksqldb-graphql project also spins up a GraphQL Playground to easily interact with the GraphQL endpoint. The ksqldb-graphql project itself has the status of being a proof of concept. Below are examples of all three GraphQL operations.
Because we created two tables in ksqlDB, we can query those tables using a GraphQL query. To get the number of persons for a certain year, we can issue a query like so:
query {
PERSONS_BY_BIRTHYEAR(BIRTHYEAR: 1983){
BIRTHYEAR
TOTAL
}
}
This will return a JSON response where the total depends on how long the project has been running. It looks like this:
{
"data": {
"PERSONS_BY_BIRTHYEAR": {
"BIRTHYEAR": 1983,
"TOTAL": 1
}
}
}
With mutations, it should be possible to add data to Kafka. So we can add a person like this:
mutation {
PERSONS (
ID_KEY: "gklijs"
ID: "gklijs"
FIRST_NAME: "Gerard"
LAST_NAME: "Klijs"
BIRTHDAY: {
YEAR: 1983
MONTH: 8
Day: 23
}
){
statusCode
}
}
We only get a statusCode back, which will be the result of the REST call to ksqlDB. So if it is processed correctly, it will be this:
{
"data": {
"PERSONS": {
"statusCode": 200
}
}
}
The last thing we can do is use subscriptions. This will allow us to see either the persons themselves or the counts as they are put on Kafka. Updates on the counts:
subscription {
PERSONS_BY_BIRTHYEAR {
BIRTHYEAR
TOTAL
}
}
…give a stream of messages like this:
{ "data": { "PERSONS_BY_BIRTHYEAR": { "BIRTHYEAR": 1983, "TOTAL": 2 } } }
The main advantage of this approach is that it’s very easy to set up, especially if you are already using ksqlDB. To build out a solution that goes beyond proof of concept, it might be useful to look into the ksqlDB API.
The second project to highlight is a banking demo originally built for a workshop about Clojure. It has seen several iterations, where other frameworks or even other programming languages are sometimes used. It allows you to create bank accounts tied to a user and transactions. Some rules are in place (e.g., the balance can never be below € -500,00). There is a UI that can also simulate a bank employee view which has access to all accounts. The latest iteration can be found at bkes-demo. The project uses CQRS and event sourcing and consists of several components as shown below.
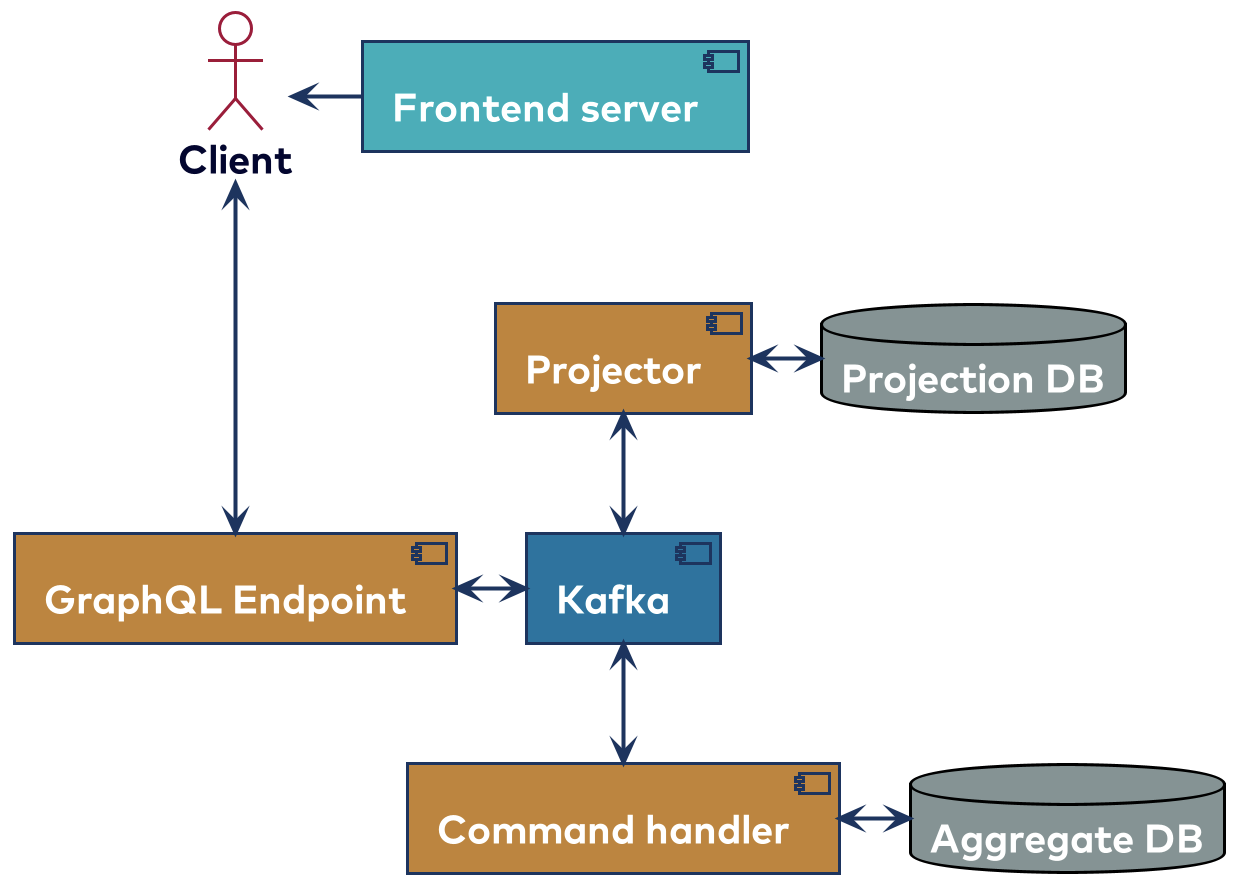
The graphql-endpoint uses a schema that is written by hand. Most of the types used do have Avro types that look about the same. Avro is a way of serializing data, and the Confluent Schema Registry allows you to register Avro schemas to allow schema evolution. One of the main reasons for using a declared schema is simply that it’s the default way to use the GraphQL library. It’s also used to format the monetary amount on the server side so that the clients don’t need to bother with it. While the new-balance field is of type long in the Avro schema; it is changed in the GraphQL resolver to being a string. In this case, all the messages between the components are also sent through Kafka.
For the queries, a query bus is used. This is a construct that sends a query message to the Projector and awaits a response from the Projector. The Projector has an in-memory database that builds a projection based on the events coming in from Kafka. Because of this setup, it is able to handle queries like “give me the last x transactions of bank account y.” Below is how you can issue a query in this system:
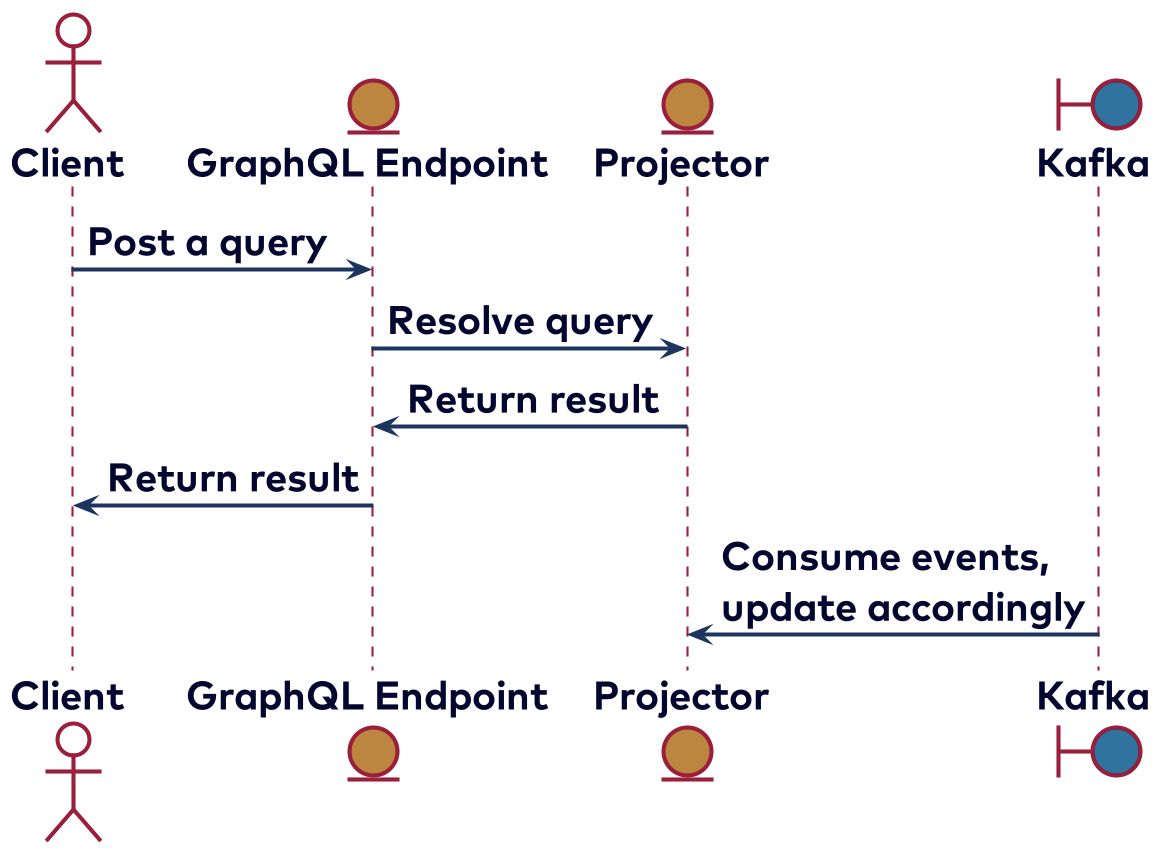
There are several queries available, and all have their own Avro type in this case given that the GraphQL endpoint and the projector will use Kafka messages to communicate. Below is an example of a query:
query {
transaction_by_id(id: 1){
descr
iban
}
}
This can be used to fetch specific information from a transaction if the ID is known. This results in something like the following:
{
"data": {
"transaction_by_id": {
"descr": "initial funds",
"iban": "NL66OPEN0000000000"
}
}
}
For mutations, a command bus is used. The idea is about the same as the query bus, but instead of generating a message for the projector, it is sent to the command handler. If the command fails, the reason that it has failed is also returned to the client if the client asked for it. For example, when trying to transfer too much money, a message will be returned stating that there are insufficient funds.
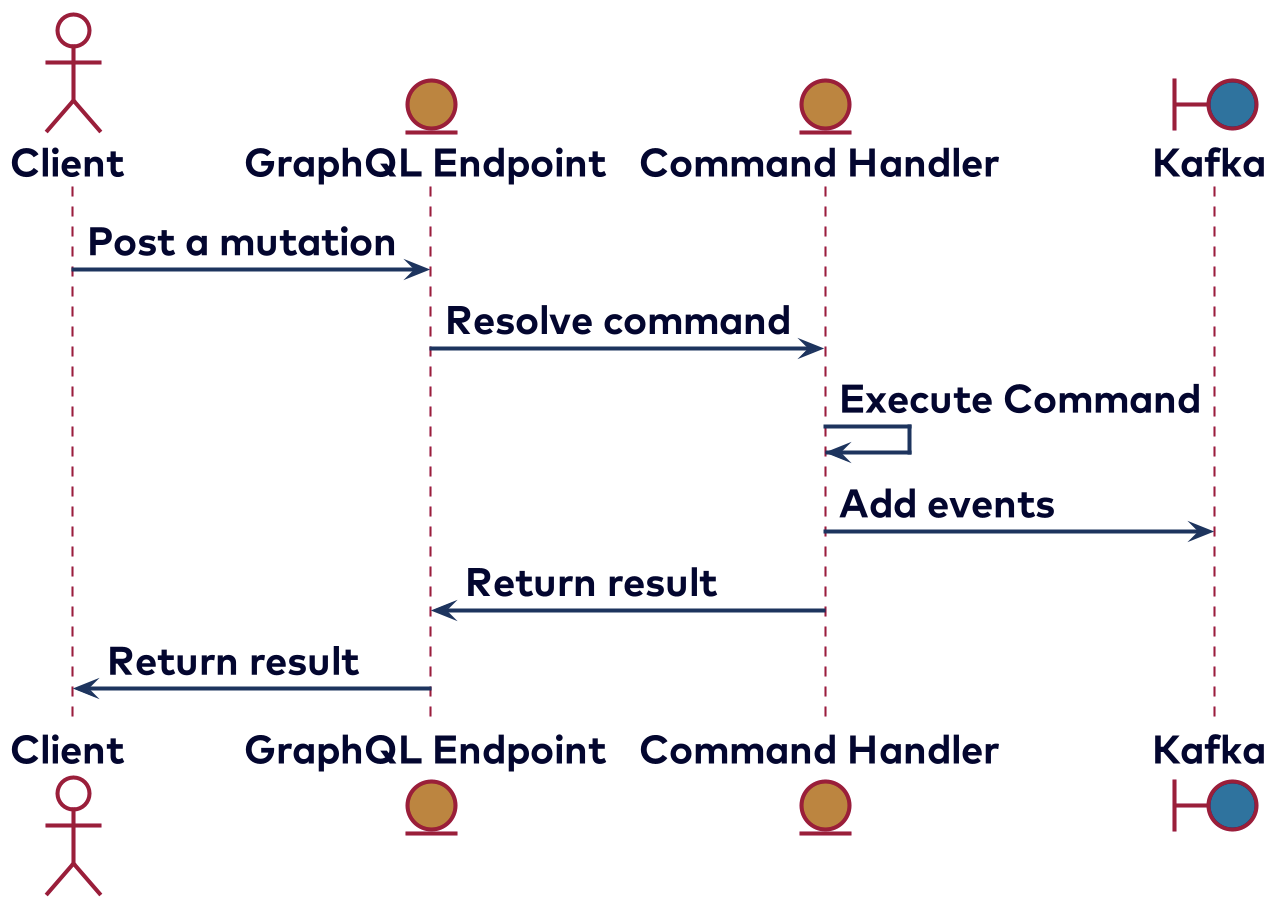
The two available mutations are to open or retrieve a bank account, and to transfer money. The mutation to open or retrieve the bank account looks like this:
mutation {
get_account(username: "gerardklijs",
password: "test1234") {
iban
token
}
}
This could actually combine multiple query and command messages from the GraphQL endpoint because it first needs to know if the account already exists, and to create a new one if not. If it was newly created or existing with the correct password, the response will be this:
{
"data": {
"get_account": {
"iban": "NL32OPEN0116336786",
"token": "64863395589341241872"
}
}
}
The only available subscription is on the transactions. This stream is created by the Projector, and contains all of the transactions. At the graphql-endpoint, this stream will be consumed. With every transaction, for each active subscription, it will be checked if the transaction should be sent to the client. You can see transactions on one’s bank account in near real time on the frontend and only see/receive the details of the transaction that the client is interested in.
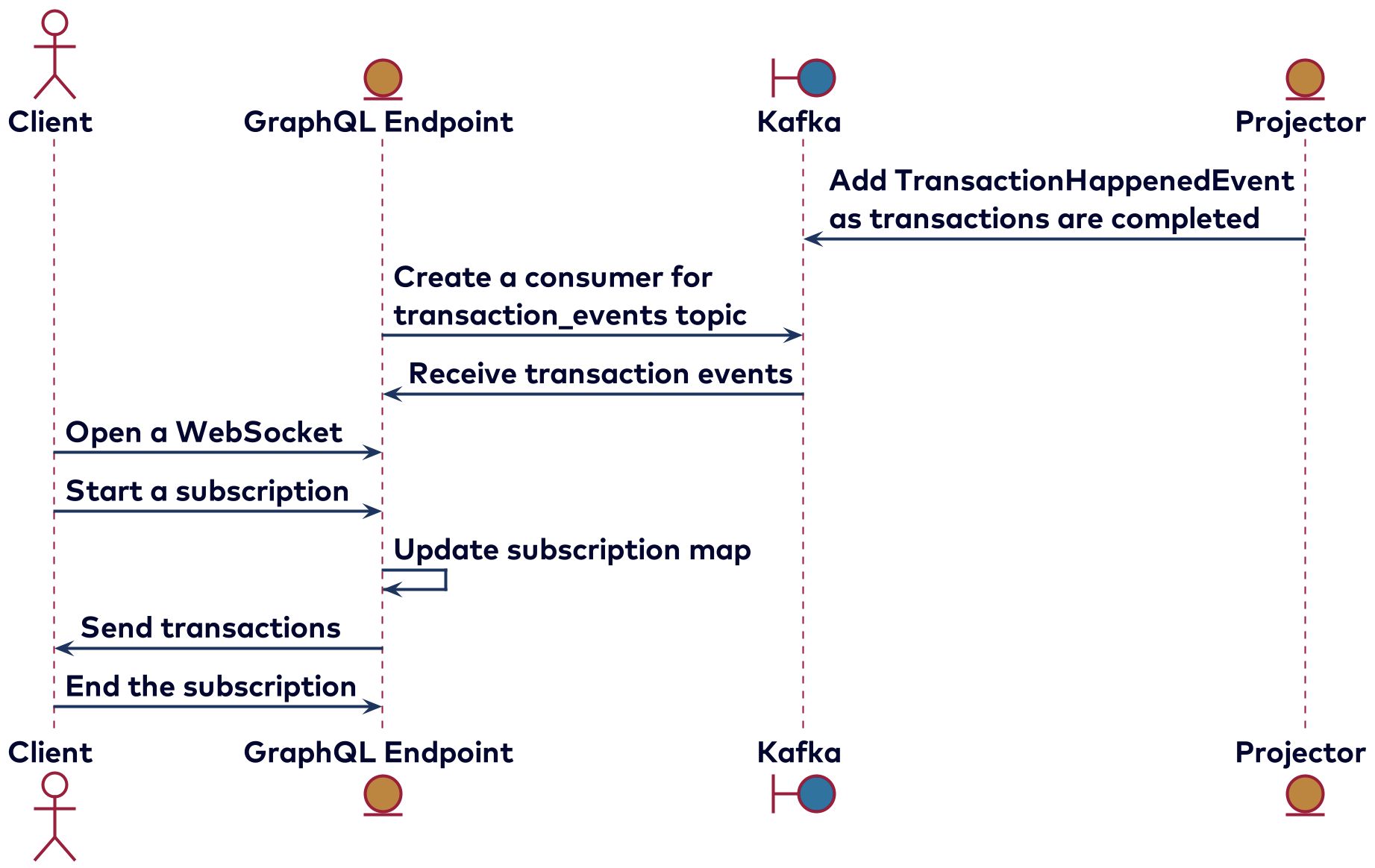
You can set a combination of filters depending on the properties of the transaction. Here is an example of a subscription that will only receive transactions for a specific bank account:
subscription {
stream_transactions(iban: "NL66OPEN0000000000") {
id
new_balance
}
}
As this has been processed in the endpoint, any new transactions will be sent by a WebSocket to the client like this:
{
"stream_transactions": {
"id": 7,
"new_balance": "€1.000.000.000.000.021,00",
"descr": "test for presentation"
}
}
Conclusion
As we have seen, there is no straightforward way to combine GraphQL with Kafka. It depends on the use case on the client side and how you’ve already implemented Kafka. One thing we do know is that GraphQL has the power to bridge the gap between backend and frontend.
If you’d like to learn more:
- Watch my Kafka Summit talk, where I delve into this topic in more detail
- Listen to my Streaming Audio episode to learn more
- Check out Confluent Developer to find more getting started guides for various programming languages
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


