[Live Demo] Tableflow, Freight Clusters, Flink AI Features | Register Now
Designing and Architecting the Confluent CLI
It is often difficult enough to build one application that talks to a single middleware or backend layer; e.g., a whole team of frontend engineers may build a web application that talks to a company’s API. This challenge is greatly compounded when building an application that has to run on a variety of platforms and architectures, must communicate with multiple backends, and be used in mission-critical workflows. These are a few of the design and implementation considerations we had to make when creating the command line interface (CLI) tools for cloud and on-prem deployments of Confluent.
Confluent publishes two CLI clients, one for cloud (ccloud) and one for on-prem (confluent)—though our vision is to unify these into one binary, stay tuned! Both of these are compiled from the same repository. Our CLIs are designed to be:
- Complete: allow you to fully manage your Confluent deployment
- Intuitive: have predictable, consistent command syntax
- Stable: breaking changes are rare and communicated well beforehand
For example, ccloud lets you create a fully managed Apache Kafka® cluster in Confluent Cloud on AWS with a simple command:
$ ccloud kafka cluster create --cloud aws --region us-west-2
Or continuously monitor the status of your cluster:
# Assumes cluster ID is lkc-abc123
# (use `ccloud kafka cluster list` to get your cluster’s ID)
$ watch -n5 "ccloud kafka cluster describe lkc-abc123 -o json | jq '{status}[]' | xargs -I{} echo 'Your Kafka cluster is {}.'"
Your Kafka cluster is UP.
This syntax has not changed since our 1.0 release over a year ago. Functionality like this is also available in our cloud UI (see images below), although for programmatic and scripting use cases it is typically easier to use a command-line interface.
Our CLIs are especially interesting because they’re the only interface that has to accommodate both human and programmatic usage. Confluent’s CLI team designs and maintains the framework, including core functionality like authentication. Other functional teams (e.g., Connect, Schema Registry) contribute code to the clients in order to expose the features they build. The ratio of CLI team engineers to contributing engineers is quite small, so the team and contribution process needs to be efficient.
This blog post will describe aspects of our design philosophy, the technical decisions we made, our general engineering processes, and the lessons we learned while building these tools that power the daily interactions of the more than 2,500 organizations using Confluent. If you are building CLIs or frontend applications in general, or are curious about how Confluent’s CLIs work, read on!
Choosing the tools for the job

At the outset, we had to decide which language to use for writing our CLI. There were several considerations that ultimately led us to decide on using Go:
- Our CLI has to run on a wide variety of operating systems and architectures and interface with a diverse set of cloud providers (Google Cloud Platform, Microsoft Azure, Amazon Web Services). We wanted to write code once and cross-compile with minimum extra effort. A single machine should be able to cross-compile without extra toolchains, VMs, etc.
- It needs to be easy for other teams to contribute to our codebase.
- Customers should not have to install extra dependencies in order to use our CLI. On-prem users will have Java installed, but this is not a guarantee for cloud users.
- Writing networking code should be as easy as possible.
- Bumpers are good. A strongly-typed language with robust testing tooling is better than an untyped or optionally-typed language, even if materially more verbose code is required.
Go satisfies these criteria, respectively:
- Easy cross-compilation is one of the main selling points of Go—just set the GOOS and GOARCH environment variables to the desired OS and architecture for your binary.
- Many other teams at Confluent already use Go, and for those that use other languages like Java, the syntax of Go is generally quite natural to pick up.
- Go binaries bundle all dependencies and a Go runtime into a single native binary file. No dependencies are needed provided cgo is avoided (even then, almost all users have some appropriate C runtime available).
- Go is designed for easy networked programming, and it’s very fast to write code to perform HTTP requests to query APIs, for instance.
- Even though Go has verbose requirements like writing lots of if err != nil { … } blocks, it’s a type-safe language where unexpected errors and behavior are rare. Go also has well-designed built-in testing tools.
A pain point we faced with Go is its dependency management system. When we started the CLI, go mod was still under development, and it took until about Go 1.15 before we stopped having issues with dependency management. One reason dependencies were painful is that, in general, you can only have one version of a dependency across your project. This is in contrast to Node.js, for example, where each dependency has its own tree of sub-dependencies. Also, the syntax of versioning in go mod is also not always intuitive as, say, Node.js. For example, a reference in go.mod to a git branch or tag of a dependency is automatically changed to a version string based on a datetime and a commit hash, which is less intuitive. Finally, since we have several private dependencies hosted on GitHub, it was not a fun surprise when a new Go release required us to start specifying GONOSUMDB=github.com/confluentinc and GOPRIVATE=github.com/confluentinc in our Makefiles—although the notion of using databases to verify checksums of packages is ultimately quite useful.
Another reason we chose Go (in spite of any gripes about dependency management) is the robust ecosystem of tools in the open source community. Our CLI is built on top of the Cobra CLI framework, which provides a trove of useful functionality for defining and parsing arguments and flags, creating hierarchical commands, etc. We also heavily rely on GoReleaser for generating binaries and archives for all of the platforms we support, and for publishing those build artifacts to S3.
Testing, testing, 1, 2, 3…
In developing the CLI, we defined three types of tests:
- Unit tests are Go functions calling other Go functions and checking the results. There is no input flag/argument parsing, and any state is mocked. Generally, these are intended to test that a single function meets certain postconditions given the preconditions the test sets up. For example, we might write a unit test for this function (which is used for the ccloud admin promo list command):
func formatExpiration(seconds int64) string { t := time.Unix(seconds, 0) return t.Format("Jan 2, 2006") }By creating the following test, using the built-in testing package as well as Testify (again, this is a real test in our codebase):
func TestFormatExpiration(t *testing.T) { date := time.Date(2021, time.June, 16, 0, 0, 0, 0, time.Local) require.Equal(t, "Jun 16, 2021", formatExpiration(date.Unix())) } - Integration tests execute commands by making system calls to a real CLI binary, but all API responses are provided from a mocked backend. Integration tests can detect CLI changes that break compatibility with the API, and they can correspond to calling several internal functions (including parsing and validating flags and arguments).
- System tests execute commands using a real CLI binary and a real (non-production) backend. These can detect API changes that break compatibility with the CLI, and they are often designed to replicate real, multi-step customer workflows.

We run all of these tests on every PR build for our CLI repository. We need to run these CI tests on Windows, Mac, and Linux since our customers use all of these platforms, and we ideally don’t want to host and maintain that infrastructure ourselves. At the time we were getting started, Azure Pipelines was a natural fit for our project because it was the only cloud CI solution to offer this functionality. In particular, it offered Windows “agents” (build hosts) in addition to Linux and Mac agents. We have been quite pleased with the performance, stability, YAML job syntax, and even the UI of Azure Pipelines.
The only downside we have experienced is that you can’t ssh into worker VMs, unlike with other tools such as SemaphoreCI. And although we are able to run most of our tests via Azure Pipelines, we have a set of on-prem system tests that run via Jenkins because there was already complex infrastructure and configuration in place that would be needlessly time-consuming to try to replicate in the cloud. Nonetheless, both CI systems are integrated as GitHub webhooks so contributors to our codebase don’t feel much friction from having two systems behind the scenes.
In addition to checking the pass/fail results of tests, we have also attempted to remain vigilant about code coverage. For unit tests, Go has built-in support for generating coverage metrics, but for integration and system tests, the situation becomes much trickier. We created the open-source bincover tool in order to measure integration test coverage as well. Together, go test and bincover give us coverage metrics for unit and integration tests. System test coverage is not automatically measured at the moment, but that is arguably acceptable since system tests are designed to “cover” real-world customer workflows rather than lines of code.
Updates: Shipping and receiving
The release and update infrastructure for our CLI is arguably the most important aspect of our tooling, especially since we release on a relatively frequent weekly or bi-weekly cadence. Without robust release tooling, incomplete or faulty releases can be shipped and developer toil can be greatly increased. Similarly, imperfect update logic can, in the worst case, completely block customer updates and require massive communication efforts and extra manual effort.
As mentioned, we use goreleaser to generate binaries and archives for a new release. We follow a simple branching strategy where new releases are tagged from the latest tip of the master branch of our repository (hotfix releases can always be generated by branching off from a specific release tag if needed). We use gon to notarize Apple binaries, which is required as of macOS Catalina. This limits us to releasing from Mac machines—though, if necessary, we could set up a remote Mac build host, but no one wants to maintain additional infrastructure.
We have a simple Makefile script that tags and publishes new Docker Hub images containing our CLI for cloud or on-prem. We also have a Makefile script that takes all of the commit messages since the last release and generates release notes for cloud and on-prem. This allows for manual editing as needed. Finally, we wrote a utility that takes Cobra command descriptions, examples, flags, and arguments, and automatically generates command reference documentation for cloud and on-prem. The release process also runs this script and generates and merges the necessary PRs into our documentation repositories.
Critically, for each of these steps in the release process, there is also code to roll back changes; if any step of a release fails, we can run one command to “un-release” before retrying. Similarly, performing a release involves running just one command (make release). Based on our past experiences with software release processes growing out-of-hand in terms of complexity, manual checks, etc., we have consciously put in a lot of effort to ensure that deployments remain as “one-touch” as possible. This requires keeping track of the dependency order of steps in the release (i.e., drawing and maintaining a directed acyclic graph) and, as mentioned, ensuring that the process can be reverted when any type of failure occurs.
On the user side, the CLI automatically checks at most once per day for available updates (users can always check manually by running ccloud update or confluent update). If an update is found, the CLI will prompt the user to update, keeping the majority of our users on the most recent version. (We monitor the versions in use via the User-Agent headers to our API.) The CLI checks for updates by listing all of the versions available in our S3 bucket and deciding whether the latest version found in S3 is newer than the current version installed. One trick to keep in mind is that the S3 API paginates results, so it is critical for our update code to be aware of pagination since we have released a large number of versions (more than fits in one page of API results). If an update is available and the user agrees to download it, the CLI binary attempts to replace itself; if the user/file has insufficient permissions, the update will be canceled. All of this update tooling (and our code that publishes artifacts to S3) is written in-house and is not based on e.g. goreleaser.
Structuring the codebase and keeping it tidy
With dozens of contributors, thousands of commits, and many thousands of lines of code, it is critical to organize our repository in an intuitive, consistent way.
We generally followed the Standard Go Project Layout suggested by Kyle Quest. A few of our significant top-level directories are:
- cmd: Contains sub-folders that define each of the applications and tools within our repository (the CLI, our linter, our release notes generator, etc.).
- debian: Contains packaging scripts for generating Debian and RPM packages for the on-prem version of the CLI, which is included with Confluent Platform.
- internal: Most of the CLI code is contained within here. A cmd sub-folder defines a hierarchy of folders/files corresponding to the commands and sub-commands in our CLI. A pkg sub-folder contains similarly organized files that contain code which is potentially used by multiple commands (e.g., internal/pkg/netrc contains utility functions used for reading and editing netrc files).
- In cases where heavy customization is needed between cloud and on-prem Confluent deployments, we create two similarly-named files, for example: internal/cmd/kafka/command_cluster_cloud.go and internal/cmd/kafka/command_cluster_onprem.go.
- test: This folder primarily contains integration tests, “golden” expected output files, and our mocked API server. Interestingly, we wrap our mock APIs for all of the various backends we support (see the next section) in a single TestBackend struct, so in some ways it is easier to interact with our mocked backend than the real things!
- /: It is worth calling out our top-level directory, which contains a number of files, such as CI configurations, goreleaser and gon configurations, and our customer-facing CLI install scripts. This is one area where extra vigilance is required: it is all too tempting to add a new file in here when it doesn’t fit squarely within an existing directory or when it seems pointless to create a directory that will contain a single file. However, these “single files” add up over time, and then dedicated cleanup efforts are required to reorganize the repository. It’s better to prevent these types of issues from developing by having strict policies around adding top-level files.
An advantage of our repository’s organization is that it helps enable our framework contributor model. In this model, different feature-level teams (such as the ksqlDB team, the security team, etc.) own their respective commands and sub-commands within the CLI. This means that those teams are responsible for proposing UX, providing implementation, and writing tests for their features within the CLI. The CLI team acts as gatekeepers and supporters: we ensure any new commands agree with our UX and grammar guidelines, we verify that test coverage is sufficient for new commands, and we help contributors get up and running quickly with adding new commands. This latter point includes writing extensive documentation and copy-pasteable examples for purposes such as adding new commands or unit tests. Overall, this framework operating model significantly accelerates the velocity with which we can ship new features and greatly reduces our ongoing operational burden as we can delegate many feature-specific questions to the relevant teams.
Finally, one way that we maintain the cleanliness of our code is by using a custom linting engine that is integrated with our Cobra-based command hierarchy. Our linter, which uses some third-party libraries like gospell, checks for typos in command names, ensures patterns like hyphenated-command-names rather than squishedcommandnames, checks that various fields are singular or plural, checks if fields end with proper punctuation, etc. Overall, the linter allows us to define arbitrary rules and then apply those rules to commands, arguments, flags, descriptions, etc. (exceptions can also be defined when necessary).
Consuming all the APIs
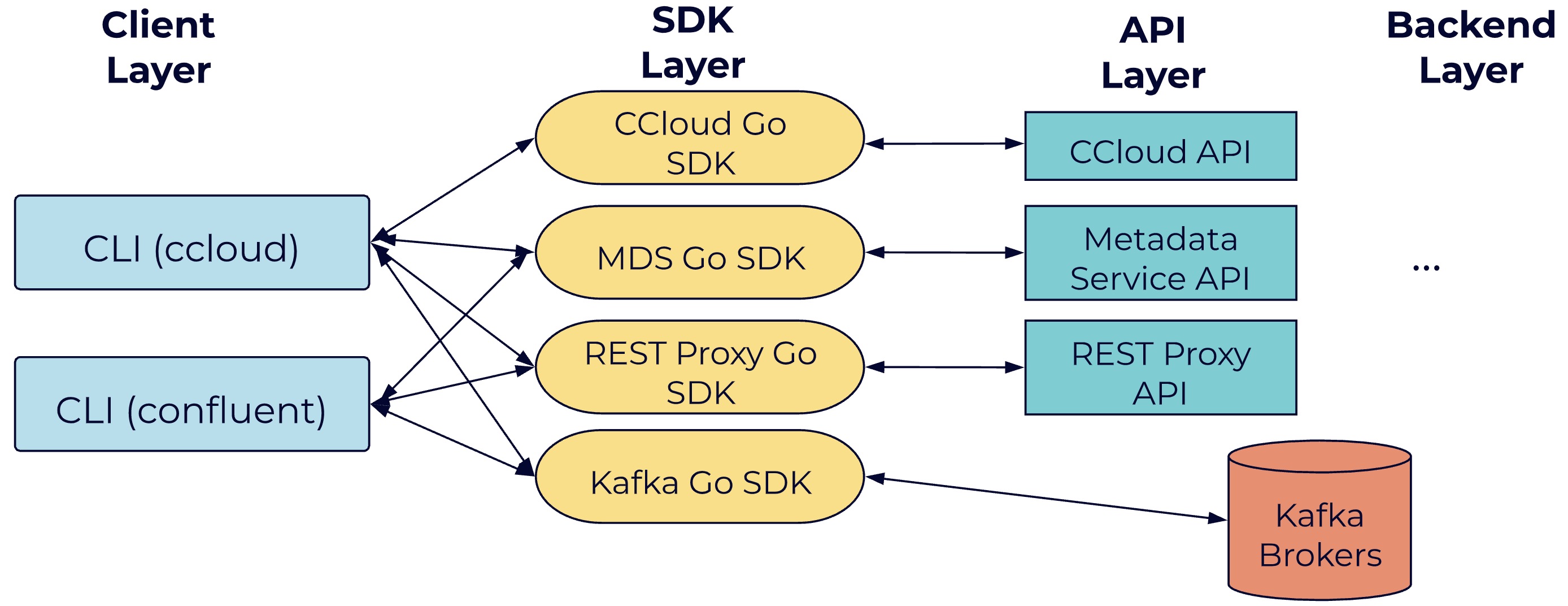
Our CLIs can potentially communicate with several different backends, and these various APIs must all be exposed through a single unified customer interface. This adds a decent amount of complexity to the CLI. For example, Confluent REST Proxy exposes certain cluster management features, while the Metadata Service has APIs for managing features such as RBAC and audit logs. Of course, for the end-user, all of this complexity is opaquely wrapped beneath a single, straightforward CLI experience. For example, to consume from a topic my-example-topic from the beginning, a user might run the following sequence of commands:
$ ccloud login $ ccloud kafka cluster use lkc-abc123 $ ccloud api-key store myapikey myapisecret $ ccloud kafka topic consume my-example-topic -b
This sequence of commands ultimately requires communicating with Kafka brokers, but prerequisites like storing a valid API key and ensuring the user has appropriate permissions touch the Confluent Cloud and Metadata Service APIs as well.
Since all of these APIs are built by different teams, and APIs may change frequently, the central challenges we faced were how to avoid (1) dealing with different ways of interacting with different teams’ APIs and (2) doing manual (and perhaps duplicative) work like adding code to call new API routes that teams add. Fortunately, we were aware of this problem relatively early in the development of Confluent, and we were able to engage with other teams to establish some degrees of standardization.
For each API, we create a corresponding “Go SDK,” which is a simple client library that takes typed request objects, performs all the low-level HTTP communication work, and returns typed response objects or errors. Hence, the CLI itself does not need to concern itself with directly touching APIs or parsing responses. From the CLI’s perspective, it is just calling Go functions and dealing with semantic, typed objects.
For all except one legacy SDK, we generate these Go SDKs automatically via openapi-generator. Our own Arvind Thirunarayanan contributed some required improvements to the tool—one of the perks of working at a pro-open-source company like Confluent! OpenAPI specs can be declared via easily-readable YAML files, which include specifications of routes, parameters, request types, etc. When API changes are made, openapi-generator can be used with CI hooks to automatically publish new SDK versions. In turn, our CLI can manually update to newer SDK versions as needed.
In cases where APIs overlap (such as when a command is available for both cloud and on-prem Confluent deployments), we just use an if statement when initializing our hierarchy of CLI commands in order to add a subcommand that talks to the appropriate API. An advantage of this approach is that we can present a single, unified CLI experience even if underlying APIs are different. For example, we might map parameter names from one API to match those of another. In turn, this helps us guide different API and backend teams towards a converged future where middleware and backend layers will expose equivalent feature sets and interfaces regardless of the deployment environment.
Back to grammar school
We considered a variety of CLI grammars used in the industry when deciding how to name commands and flags in our CLI. For instance, the Kubernetes CLI defines commands like kubectl get pods, where commands are of the form verb noun. The AWS CLI has commands like aws s3 cp <source> <target>, where s3 is a top-level command grouping or (abbreviated) product name, and cp is an abbreviated verb. In another realm, the Stripe CLI offers syntax like stripe customers create, using noun(s) verb where resources might be plural. There are a lot of different grammar design options, and at the end of the day what matters is choosing something that feels familiar to developers, isn’t overly cumbersome to type, and most importantly, a format that enables consistency throughout the CLI.
In the Confluent CLI, commands are of the form noun [sub-noun] verb [positional arguments] --hyphenated-flag-names. Nouns corresponding to resources or sub-resources are kept singular whenever possible (“Kafka cluster” not “Kafka clusters”). The small set of standard verbs we allow, such as create, list, etc., are also singular. Positional arguments are required in a consistent way. For example, any “describe” command requires the ID of the resource to be described as the first positional argument. Every command and flag name is entirely lowercase; where multiple words are required for a single command or flag, hyphens are used (“service-account” not “serviceAccount”). Any resource that can be managed with Confluent (a connector, a service account, a Kafka cluster) must support at least the basic CRUD operations. Finally, we aim to have as few positional arguments as possible in order to minimize the burden on the user of remembering the order of parameters. To capture all this with an example, a valid command in the CLI is:
$ confluent iam rolebinding create --principal User:appSA --role DeveloperWrite --resource Topic:users --kafka-cluster-id abc123
Whereas an invalid command would be:
# Invalid command example $ ccloud kafka make consumergroup --Name test-cg --sessiontimeout 60
Since consumergroup is not hyphenated, make is not a standard verb, the verb make comes before the (sub-)noun consumergroup, --Name should not be capitalized (and should likely be a position argument), and --sessiontimeout should be hyphenated.
The natural tradeoff when aiming for maximizing consistency is that sometimes commands can feel verbose, or commands might not fit into natural groupings. For example, ccloud service-account is somewhat verbose to type, but to mitigate this, our CLIs have installable shell completion (ccloud completion or confluent completion) as well as an interactive command shell with autocompletion (ccloud shell). See the demo below, and this blog post for details.
Conclusion
We reviewed a few of the design and architectural decisions we made at Confluent when creating our customer-facing CLIs. CLI development has made a resurgence in recent years as every prominent developer company and infrastructure provider seems to offer at least one CLI (AWS, GCP, Azure, Stripe, MongoDB, Elastic, etc.). However, there are not many universal best practices. The stories told and considerations presented in this article will not be right for every CLI, but we hope that at the least, they illuminate the types of discussions that you should have with your colleagues and customers when creating new command-line tools. In the future, we hope to share more about our efforts to unify all the command-line tooling at Confluent, and we also hope to make our CLI source available so that we can better engage with the community and share more direct examples of our practices and design decisions in action.
Get in touch
The CLI team is highly responsive to user feedback and is interested in hearing about both bug reports and feature requests—any way to help us serve users better. If you would like to provide any suggestions or feedback, feel free to file a reach out on the Confluent Forum, send us an email at cli-team@confluent.io, or file a ticket through Confluent Support. We look forward to hearing from you!
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...