Confluent named a Leader in the Forrester Wave: Streaming Data Platforms | Access the report
How Apache Kafka Enables Podium to “Ship It and See What Happens”
This a summary of Podium’s technological journey and an example of how our engineering team is tooling ourselves to scale well into the years to come. Here at Podium, we’re keenly focused on providing messaging tools to help local businesses modernize the way that they communicate with their customer base. What’s now become a full-blown end-to-end product suite servicing industries ranging anywhere from healthcare to home services started out much simpler, with business reviews management focused on automotive dealers.
What got us here won’t get us there…
In the early days, fresh out of Y Combinator, Podium frequently looked to the essays of Paul Graham as an instruction manual for how to thrive as a startup. Do Things That Don’t Scale was a fan favourite within the engineering org. That mantra evolved over time into an internally sourced one of “Ship It and See What Happens,” but the point remained the same: don’t over-engineer.
Our CTO likes to use a car analogy to describe Podium’s requisite evolution as we scale. The tooling has to change to fit the circumstances.
Then
In the early days of the company, the tech stack was akin to the composition of a Toyota Camry. The engine, transmission, axles, and brakes of a Camry are all designed to handle the low-grade stress expected to be placed upon them via the daily commute or a quick errand. Podium’s engineering “Camry” was a monolithic Rails app, single Postgres database, and outsourced DevOps.
Now
Podium’s infrastructure has evolved over the years to include a microservices architecture that runs within Kubernetes and distributed data tools like Apache Airflow and those found within the Apache Kafka® ecosystem. These tools allow us to handle the system load consisting of millions of conversations happening simultaneously on our platform. We started sprinkling in Kafka about three years ago, initially for simple queuing use cases, but it has now become a foundational piece of the infrastructure that we are using to build the engineering equivalent of a Ferrari.
Kafka use cases at Podium
Podium now uses the Kafka ecosystem everywhere within our infrastructure. Examples include:
- Moving functionality that requires exactly-once processing guarantees away from RabbitMQ and onto Kafka
- Building change data capture pipelines to pass data asynchronously across microservices
- Building a dead letter queue waterfall technique into data pipelines requiring high throughput so that errant messages don’t clog the pipeline but can still be triaged later
Deep dive of a recent Kafka use case
Podium has done a great job over the years of delaying refactors until the indicators say that the performance gains from a refactoring will be worth it to our customers. We recently hit a critical mass of indicators signaling that our conversation search needed to speed up, so we put a brief hold on the existing roadmap and prioritized the refactoring at the top of the list.
The existing search infrastructure still used a Postgres read replica to query and then surface results. The result set was slow to return and oftentimes surfaced unhelpful search results for the customer. For these reasons, we wanted to move to a solution that used Elasticsearch. However, any latency in a conversation’s availability in Elasticsearch was unacceptable, so a streaming solution seemed requisite—specifically, the combination of Kafka, Kafka Connect, ksqlDB, and Kafka Streams.
How the event streaming pipeline works with Elasticsearch
We first evaluated the “bookends” of the pipeline, defining what we wanted the records to look like when they were placed into Elasticsearch at the bottom of the pipeline. Then, we evaluated the contents of the database tables at the top of the pipeline to see which tables would need to be used.
The resulting records in Elasticsearch needed to look like this:
{
"user_uid": "ff3b56b0-264d-4346-a27f-1cf1e3b76c79",
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"step": "needs_review_invite"
}
Postgres and Debezium at the top of the pipeline
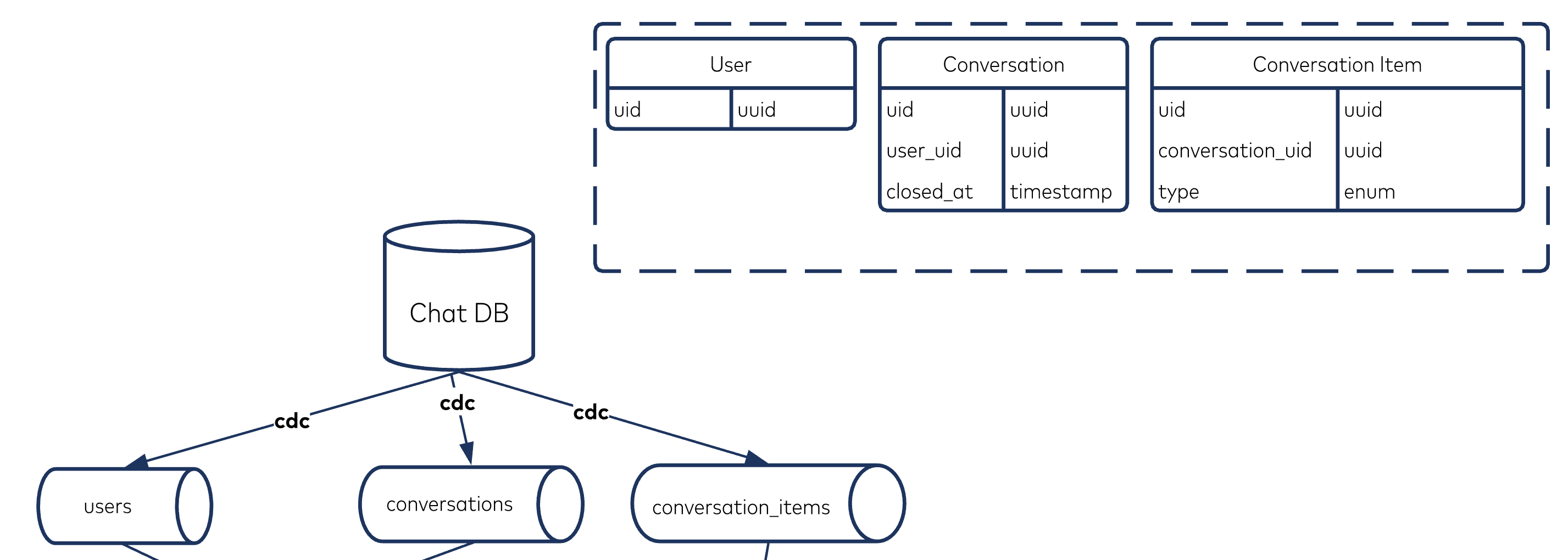
The tables that mattered (users, conversations, and conversation_items) were sent to Kafka via change data capture using the Debezium PostgreSQL CDC Connector (io.debezium.connector.postgresql.PostgresConnector).
Calculating step
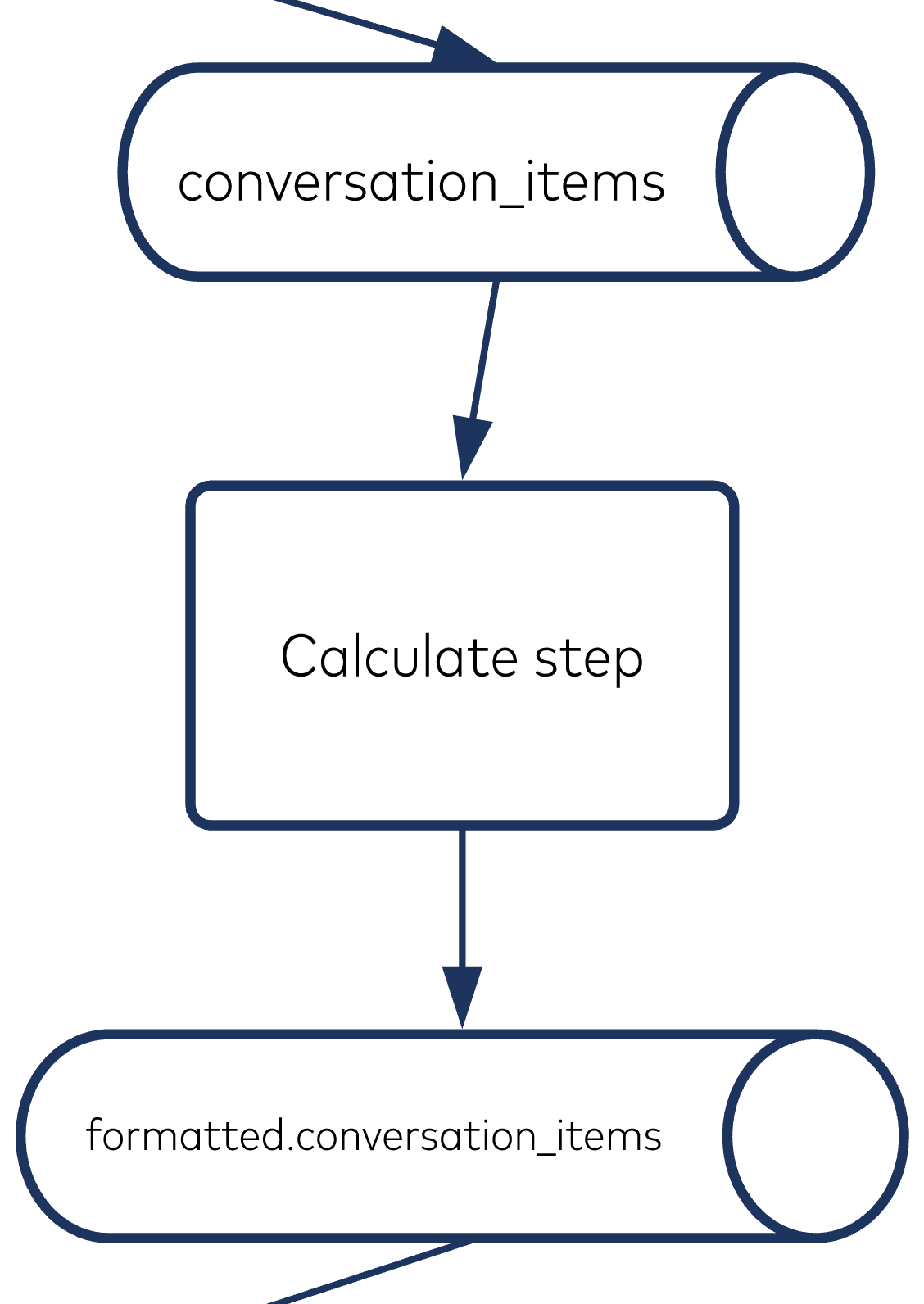
A conversation_item can be one of three unique types:
- Message
- Review invite
- Review
One of Podium’s features helps brick-and-mortar businesses collect reviews from their customers to place on platforms like Google reviews.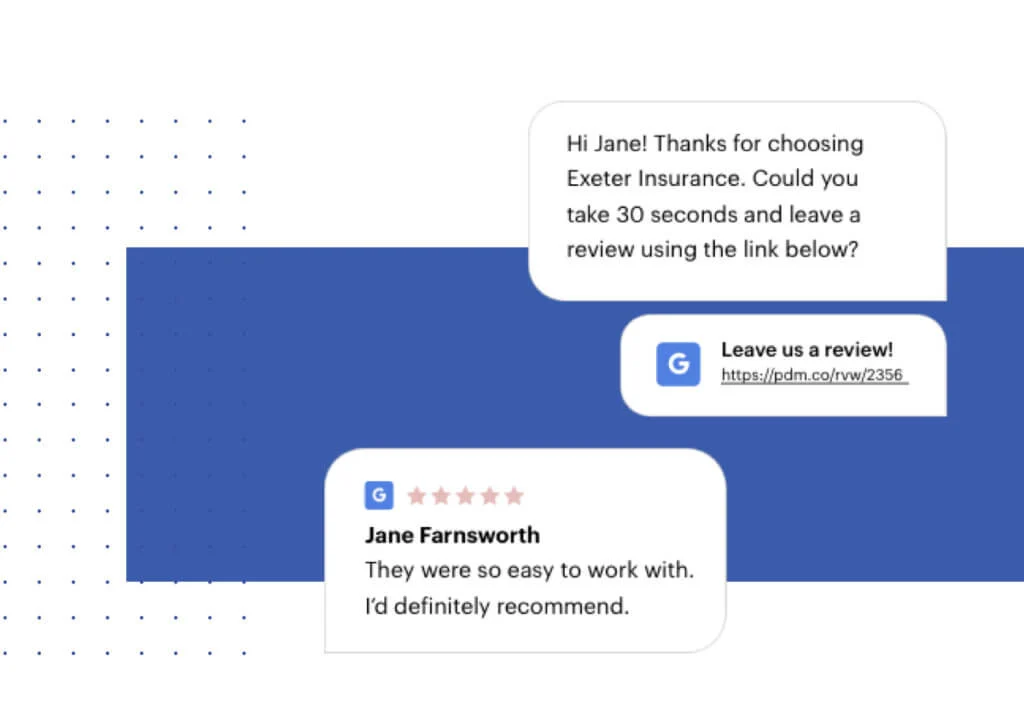 In the example provided, Jane is a customer of Exeter Insurance and just left their office. Jane will receive a text message from the team at Exeter thanking her for her time and asking for a review. Jane leaves a five-star review about Exeter Insurance on Google. Exeter’s team will be notified of the new review, and they can respond to the review within Google or to Jane herself, all from within the Podium platform.
In the example provided, Jane is a customer of Exeter Insurance and just left their office. Jane will receive a text message from the team at Exeter thanking her for her time and asking for a review. Jane leaves a five-star review about Exeter Insurance on Google. Exeter’s team will be notified of the new review, and they can respond to the review within Google or to Jane herself, all from within the Podium platform.
When Exeter’s employees are using the search functionality of Podium, they can filter conversations based on whether they “need a review invite” or “need review response.” That is where the “Calculate step” comes into play in the data pipeline. The messages flow into the “Calculate step” transformer looking like this:
{
"uid": "656071ea-a214-4794-8047-5da1f769e779",
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"type": "message"
}
{
"uid": "1b9020ec-7eb8-4173-a990-27335a025f87",
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"type": "review_invite"
}
{
"uid": "6702a109-34a7-41a8-a576-a930cf76293a",
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"type": "review"
}
We aggregate all the messages for a given conversation_uid to ultimately output messages that look like the following:
{
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"step": "needs_review_invite"
}
{
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"step": "needs_review"
}
{
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"step": "needs_review_response"
}
{
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"step": "finished"
}
Joining records in topics
We joined the records in the users topic to the records in the conversations topic via the user_uid foreign key reference existent on each conversations topic record. We then joined the records in the users.joined.conversations topic to the records in the formatted.conversation_items topic via the converation_uid foreign key reference existent on each formatted.conversation_items topic record.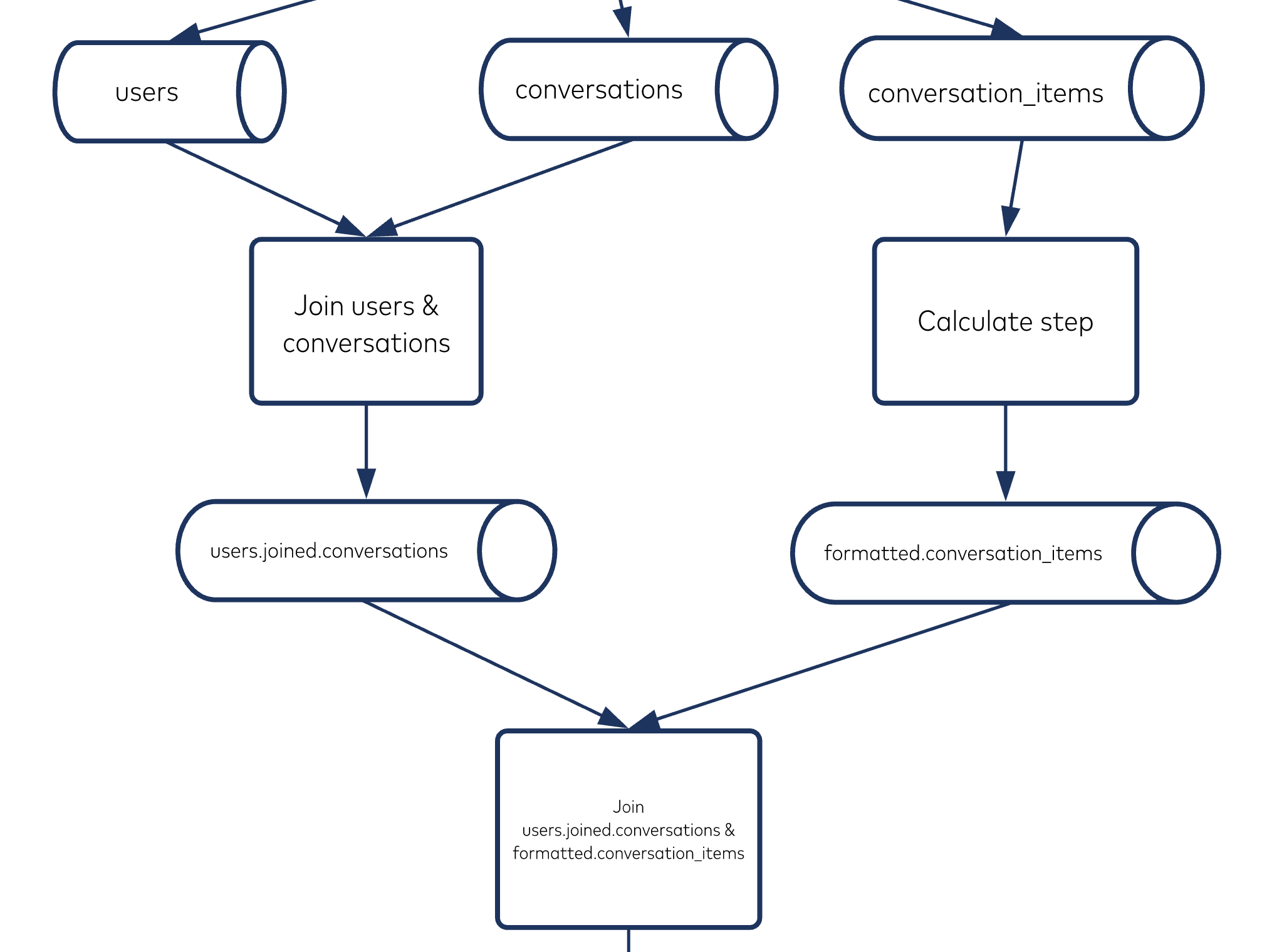
Sending tombstones to Elasticsearch
Lastly, we only want “open” conversations available for search. You can think of a “closed” conversation similar to an archived email. This is where the closed_at on the conversations topic’s records comes into play.
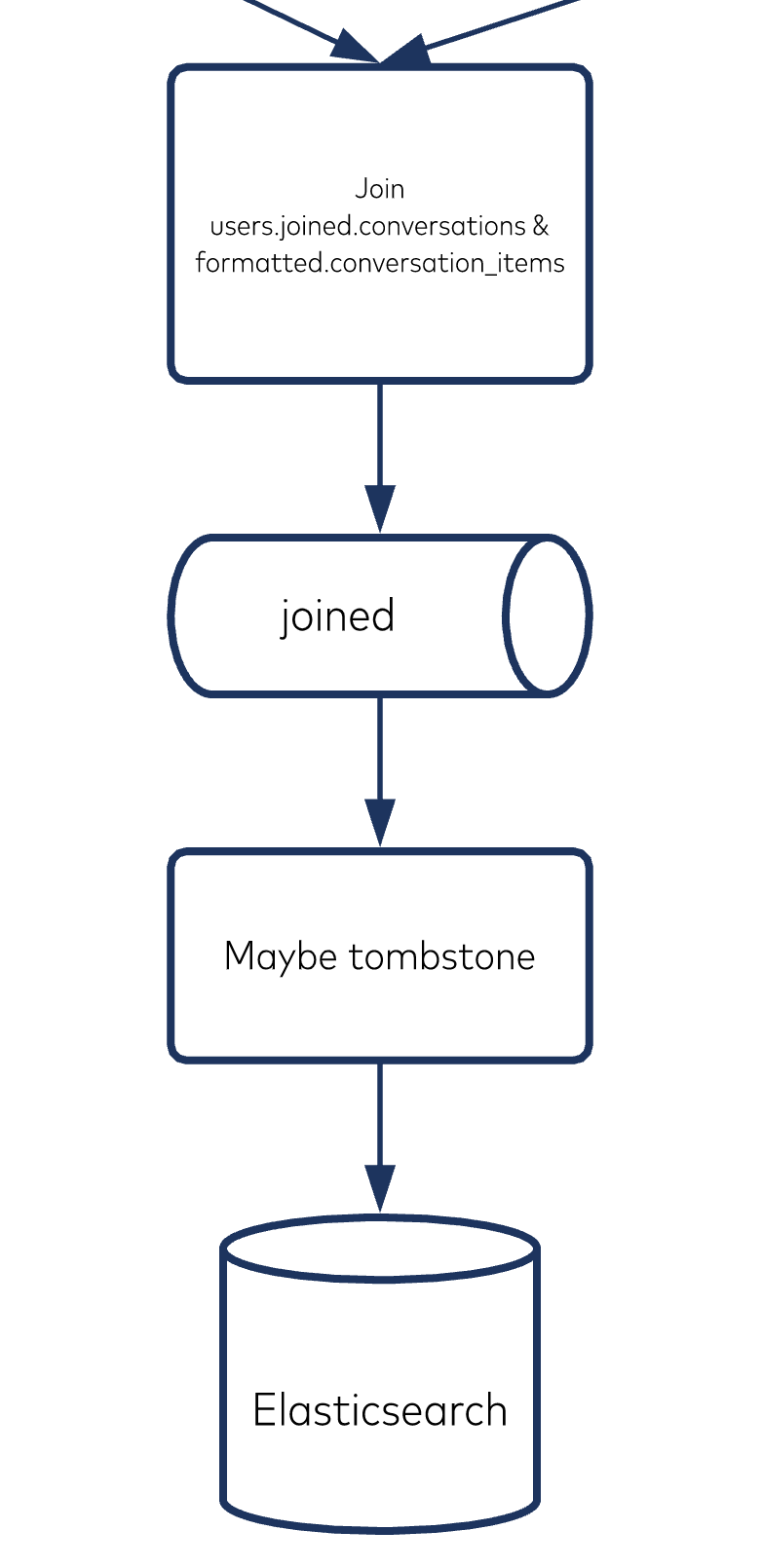
In the “Maybe tombstone” transformer, the records flowing in will look like this:
{
"user_uid": "ff3b56b0-264d-4346-a27f-1cf1e3b76c79",
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"conversation_closed_at": null,
"step": "finished"
}
{
"user_uid": "ff3b56b0-264d-4346-a27f-1cf1e3b76c79",
"conversation_uid": "72259851-6a25-4f7a-b8c7-8cdbfc0f1b26",
"conversation_closed_at": "2020-07-19 10:23:54",
"step": "finished"
}
If a record’s converation_closed_at timestamp is not null, then instead of passing through the record, we will want to pass through a tombstone (i.e., a record with the same key as the record that came in but a null value). This will tell the ElasticsearchSinkConnector that it needs to send a DELETE to the Elasticsearch instance and remove the record for that key, making that conversation unsearchable from the customer’s point of view.
Factors to consider
- Restreaming. You’ll need to restream at some point. Wiring up a comprehensive data pipeline locally (leaning on the Kafka ecosystem, which provides Docker images) and getting a few messages to successfully make it all the way through the transforms into the intended destination is only half the battle. Data at production scale is going to contain edge cases that you don’t stumble upon until the pipeline is in production. Given this, configure your pipelines for idempotency where necessary. (The blog post Processing Guarantees in Kafka is an excellent article that we’ve passed around at Podium countless times.)
- Versioning. We’ve found success at Podium with Kafka by starting simple. When we first tried adopting Kafka, we were publishing every single field imaginable for every single entity. That’s fine if you can guarantee that your upstream data is clean, but we didn’t have that luxury. Every now and then, we’d discover that a constraint on an upstream database table was missing. We’d also discover that the data we expected to be non-nullable would have nulls in it or message bodies so large that Kafka Connect would choke on them. These mishaps were understandable given how large our team was growing and how quickly we were having to learn to effectively communicate across team boundaries that weren’t there just months prior.The first use case for Kafka with your users data may only require the user’s first_name and last_name. Push that data and only that data onto a topic called something like users.v1. If a second use case surfaces where teams will also need the user’s email, then create a new topic called users.v2 and publish data containing first_name, last_name, and email. Existing use cases can continue consuming from users.v1 and move to users.v2 if and when they deem necessary, while new use cases can start using users.v2 from the get-go.
Conclusion
Kafka and its ecosystem have helped Podium decouple our infrastructure and upgrade system performance when signals coming from our customer base reveal an issue within the existing architecture. Kafka has helped Podium gradually upgrade our metaphorical auto parts from a Camry to Ferrari, while still optimizing for feature speed to market. This approach has made it a joy to “Ship It and See What Happens.”
If you would like to learn more, check out Confluent Developer, the largest collection of resources for getting started with Kafka, including end-to-end Kafka tutorials, videos, demos, meetups, and podcasts.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



How to Implement Your First ML Function in Streaming
Learn how to add your first ML model to a real-time streaming pipeline. Learn a simple, low-risk pattern for inference, scoring, and deployment with Apache Kafka®.



Sustainable Streaming Architectures: A GreenOps Guide to Efficient, Low-Carbon Data Systems
Design energy-efficient, low-cost streaming systems. Learn GreenOps patterns to reduce compute waste, optimize storage, and lower the carbon footprint of real-time data.