Deploying Kafka Streams and KSQL with Gradle – Part 2: Managing KSQL Implementations
In part 1, we discussed an event streaming architecture that we implemented for a customer using Apache Kafka®, KSQL from Confluent, and Kafka Streams. Now in part 2, we’ll discuss the challenges we faced developing, building, and deploying the KSQL portion of our application and how we used Gradle to address them. In part 3, we’ll explore using Gradle to build and deploy KSQL user-defined functions (UDFs) and Kafka Streams microservices.
Introduction
Inspired by a methodology we introduced on the customer project from part 1, we’ll explore how to write a KSQL event streaming application, covering what our scripts look like, how we organize them in a Git repository, and how we combine them together into pipelines. We selected Gradle as our build tool, and wrote a custom Gradle plugin called gradle-confluent to structure and enable this methodology. We’ll demonstrate using Gradle to execute and test our KSQL streaming code, as well as building and deploying our KSQL applications in a continuous fashion.
Red Pill Analytics has made the gradle-confluent plugin available under the Apache 2.0 License on GitHub, as well as in the Gradle plugin portal. If you’re interested in participating on the project or just want to discuss its direction, I’d love to chat, maybe get a new feature request or, fingers crossed…a pull request!
Sample repository
If you want to follow along and execute all the commands included in this blog post (and the next), you can check out this GitHub repository, which also includes the necessary Docker Compose functionality for running a compatible KSQL and Confluent Platform environment using the recently released Confluent 5.2.1. The repository’s README contains a bit more detail, but in a nutshell, we check out the repo and then use Gradle to initiate docker-compose:
git clone https://github.com/RedPillAnalytics/kafka-examples.git cd kafka-examples git checkout confluent-blog ./gradlew composeUp
We can then verify that the clickstream, clickstream_codes, and clickstream_users topics are all there:
./gradlew ksql:listTopics> Task :ksql:listTopics Name: _confluent-metrics, Registered: false, Partitions: 12, Consumers: 0, Consumer Groups: 0 Name: _schemas, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: clickstream, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: clickstream_codes, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: clickstream_users, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: docker-connect-configs, Registered: false, Partitions: 1, Consumers: 0, Consumer Groups: 0 Name: docker-connect-offsets, Registered: false, Partitions: 25, Consumers: 0, Consumer Groups: 0 Name: docker-connect-status, Registered: false, Partitions: 5, Consumers: 0, Consumer Groups: 0
BUILD SUCCESSFUL in 1s 1 actionable task: 1 executed
KSQL primer
Building event streaming applications using KSQL is done with a series of SQL statements, as seen in this example. In the rest of my examples for this blog series, I’m using code from the Confluent KSQL Quick Start, with a very simple example demonstrated below:
CREATE STREAM clickstream (_time bigint, time varchar, ip varchar, request varchar, status int, userid int, bytes bigint, agent varchar) with (kafka_topic = 'clickstream', value_format = 'json');CREATE TABLE clickstream_codes (code int, definition varchar) with (key='code', kafka_topic = 'clickstream_codes', value_format = 'json');
CREATE TABLE events_per_min AS SELECT userid, count(*) AS events FROM clickstream window TUMBLING (size 60 second) GROUP BY userid;
The first two statements register an existing Kafka topic with KSQL as either a table or stream with a schema so that it can be queried in downstream processes. In this way, registration queries are more like regular data definition language (DDL) statements in traditional relational databases.
The third statement above is called a persistent query in KSQL terminology, as it selects data from an existing KSQL stream or table, creates or uses an underlying Kafka topic as a target, and initializes the event streaming process to transform and persist data to that topic. Because of this, persistent query statements are dependent on the creation of other KSQL streams and tables. Building an event streaming process using KSQL is about chaining a series of query statements together in a logical way, which we referred to as a pipeline during the project, and I’ll be using that nomenclature for this blog series as well.
Managing KSQL dependencies
The first requirement to tackle: how to express dependencies between KSQL queries that exist in script files in a source code repository. If you consider the clickstream data example from the kafka-examples repository, our event streaming process looks something like this:
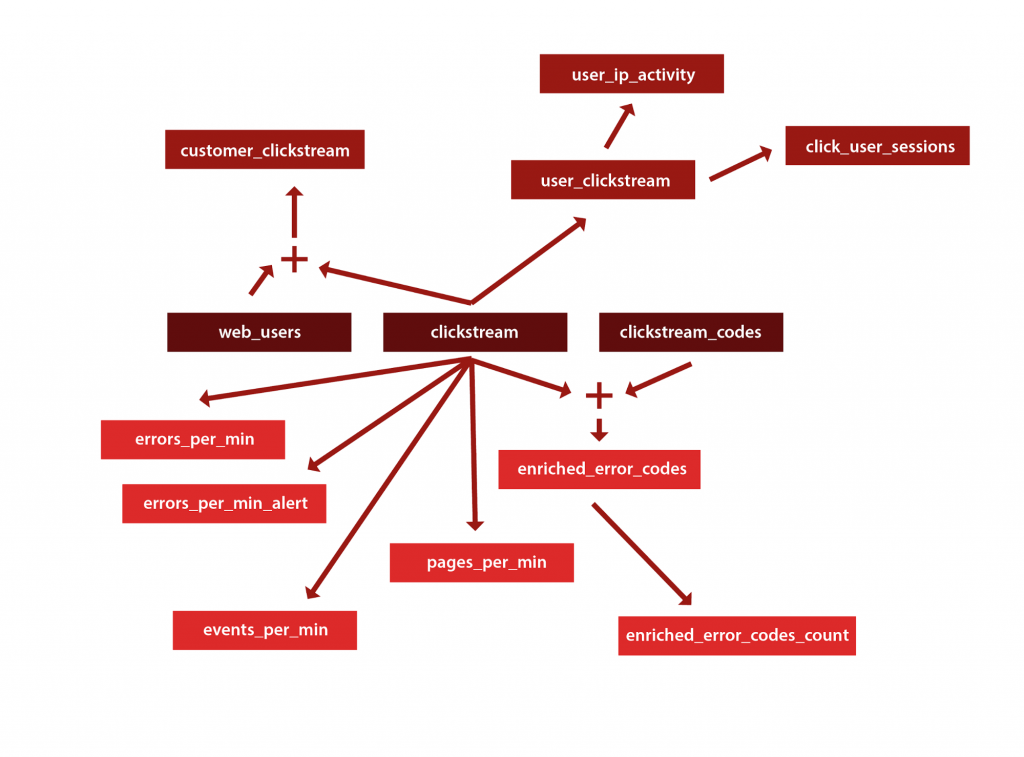
Figure 1. The KSQL pipeline flow
We have the clickstream stream, and the clickstream_codes and web_users tables that are defined on top of our source Kafka topics, so we need to ensure that those objects get created before any dependent objects. As a result, our tooling needed to provide a simple way to declare object-level dependencies—that clickstream gets created before user_clickstream, for instance. But I also wanted to introduce the pipeline concept: a group of SQL statements that work together to define an end-to-end process. This was important for two reasons:
- In KSQL, a complete pipeline is rarely defined in one or even two statements. We need to chain together many functional SQL statements to arrive at our target destination. I wanted the entire pipeline to be created and recreated with a single call so developers could easily rework their logic.
- Our SQL statements exist in script files, which need to live in a Git repository so multiple developers can work collaboratively on the total event streaming application. Smaller script files—meaning fewer statements per script—will help to reduce the number of merge conflicts occurring from accepted pull requests.
So we needed to manage the dependencies that exist within a pipeline, while also managing the dependencies that exist between pipelines. I considered several approaches for solving this requirement, including:
- A YAML file defining pipelines and the dependencies that exist within and between them
- Rigid file naming standards that had built-in dependency metadata
- I briefly considered using the Gradle task Directed Acyclic Graph (DAG), as task dependency management is one of Gradle’s strongest features
I’m an avid Gradle fan, having spoken on the subject many times at conferences and written custom plugins for a variety of different development and DevOps use cases. Our first Gradle requirement on this project was building KSQL user-defined functions, and we also eventually used it to build our Kafka Streams microservices. Once Gradle was established as our primary build tool, I knew I wanted to use it for managing our functional KSQL code as well.
In the end, I decided to use simple alphanumeric file and directory structure naming and ordering. Why? Because it’s simple: no additional config files to manage or inflexible naming standard to abide by. Developers are able to declare the dependencies between files and directories with whatever naming standard they want to use as long as proper sort ordering is considered. We can see how our clickstream process is represented hierarchically:
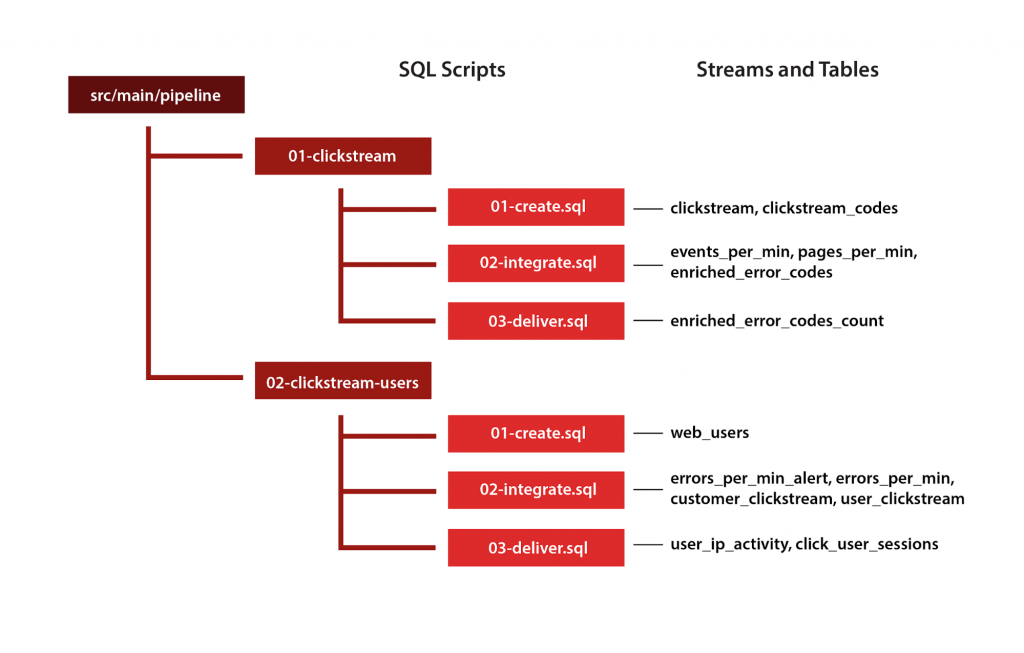
Figure 2. Mapping streams and tables to a SQL script hierarchy
With simple alphanumeric dependency management, we are declaring that the SQL scripts in the 01-clickstream directory should be deployed before the ones in the 02-clickstream-users directory, because it contains persistent queries that have dependencies on tables or streams created in the first directory. Within the 01-clickstream directory, we want the scripts to be executed in the following order: 01-create.sql, followed by 02-integrate.sql, followed by 03-deliver.sql.
This is what I mean by simple alphanumeric dependency management. There is no practical limit to the recursion depth for the plugin, and there is also no explicit naming standard that is required. Red Pill Analytics chose the create, integrate, and deliver standard within a pipeline for our project, but the plugin doesn’t care whether you use that standard or another one…or whether you use no standard at all across the different directories. It also doesn’t care how many statements exist in each script. Developers just develop…period.
So I wrote the plugin to ensure that SQL scripts are executed according to the hierarchy in the repository filesystem. This wasn’t very difficult; Gradle has a built-in FileTree object which is designed to deal with file hierarchies in which file order dependency is managed by a simple FileTree.sort() call.
But just executing all the CREATE and INSERT statements in the correct order isn’t the end of the story. When re-running a collection of scripts, the streams and tables may already exist, and we noticed a major bottleneck in the development process with developers having to drop any existing tables or streams prior to re-executing their pipelines. For instance, if I wanted to recreate the clickstream_codes table, I issue the following:
ksql> CREATE TABLE clickstream_codes (code int, definition varchar) with (key='code', kafka_topic = 'clickstream_codes', value_format = 'json');
…but then I get:
Topic already registered: CLICKSTREAM_CODES
Bummer. So I’ll need to DROP the table first, right? Here it goes:
ksql> DROP TABLE IF EXISTS clickstream_codes;
…and I get:
Cannot drop CLICKSTREAM_CODES. The following queries read from this source: [CSAS_ENRICHED_ERROR_CODES_2]. The following queries write into this source: []. You need to terminate them before dropping CLICKSTREAM_CODES.
Real bummer, man. I have a persistent query running that I first need to TERMINATE. So to complete the process of recreating the clickstream_codes table, I have to execute all of the following:
ksql> TERMINATE QUERY CSAS_ENRICHED_ERROR_CODES_2;
Message
Query terminated.
ksql> DROP TABLE IF EXISTS clickstream_codes;Message
Source CLICKSTREAM_CODES was dropped.
ksql> CREATE TABLE clickstream_codes (code int, definition varchar) with (key='code', kafka_topic = 'clickstream_codes', value_format = 'json');
Message
Table created
So we just need to add all of this to the SQL script that we add to our source repository, right? Not exactly. The non-starter with that approach is the TERMINATE statement. The query ID CSAS_ENRICHED_ERROR_CODES_2 is an auto-incrementing name, and it will change each time a query is terminated and restarted. So even if we wanted to include boilerplate DROP and TERMINATE statements in our SQL scripts, it’s not actually possible.
Our final requirement: Remove any boilerplate from our SQL scripts that might be required for them to be re-runnable. This was necessary for both the developer experience and for certain automated deployment options.
The developer experience: Executing pipelines
We usually had five people concurrently developing with KSQL in each sprint, and because Oracle GoldenGate was delivering most of our data sources to shared dev and test clusters, the developers were coding against these shared environments. Most of us installed the Confluent Platform on our Macs with brew install confluent-oss to have the ksql CLI available for doing ad hoc analysis, but it isn’t actually required in our development process using Gradle. Our plugin uses the KSQL REST API, and combined with having the Gradle Wrapper checked into our Git repository, our KSQL pipelines can be executed from anywhere as long as a JVM is installed.
The heart of a Gradle build is the build script, which by default is defined using a build.gradle file. We have the KSQL example code in the the ksql subdirectory (called subprojects in Gradle) of our repository. Additional configurations used later on are currently commented out in GitHub, so we can just uncomment those additional configurations as we need them. Below is the bare-bones requirement for applying the gradle-confluent plugin for KSQL management using the plugins{} and confluent{} closures:
plugins {
id "com.redpillanalytics.gradle-confluent" version '1.1.11'
}
confluent {
enablePipelines true
}
All plugin-wide configurations are made using the confluent{} closure, with the main purpose being the ability to override what I hope are fairly reasonable defaults; enablePipelines true is the default value and is being explicitly set here just for demonstration purposes. All of these properties, as well as their default values, are documented in the API documentation. We can use the ./gradlew ksql:tasks --group confluent command to see the new tasks available under the Confluent task group. Notice I’m prefacing all task names with ksql: because our KSQL project exists in the ksql subdirectory, which would be unnecessary if our configuration and code existed in the root of the repository:
Confluent tasks --------------- deploy - Execute any configured deployment tasks. listTopics - List all topics. pipelineExecute - Execute all KSQL pipelines from the provided source directory, in hierarchical order, with options for auto-generating and executing DROP and TERMINATE commands. pipelineScript - Build a single KSQL deployment script with individual pipeline processes ordered and normalized. Primarily used for building a KSQL queries file used for KSQL Server startup. pipelineSync - Synchronize the pipeline build directory from the pipeline source directory. pipelineZip - Build a distribution ZIP file with original pipeline source files plus the KSQL queries file generated by 'pipelineScript'.
Our methodology considers individual directories in the src/main/pipeline directory as containing complete end-to-end KSQL pipelines for a specific pattern or use case, and this is why we use the create, integrate, deliver standard when naming our code. The 02-clickstream-users pipeline reuses streams from the 01-clickstream pipeline—supporting reuse is one of the reasons we introduced the dependency management. So it was very important that developers be able to test a complete pipeline with a single Gradle task: pipelineExecute. We can see the command line options available for this task using the help --task option:
==> ./gradlew help --task ksql:pipelineExecute> Task :help Detailed task information for ksql:pipelineExecute
Path :ksql:pipelineExecute
Type PipelineExecuteTask (com.redpillanalytics.gradle.tasks.PipelineExecuteTask)
Options --from-beginning When defined, set 'ksql.streams.auto.offset.reset' to 'earliest'.
--no-create When defined, CREATE statements in SQL scripts are not executed. Used primarily for auto-generating and executing applicable DROP and/or TERMINATE statements. --no-drop When defined, applicable DROP statements are not auto-generated and executed. --no-reverse-drops When defined, DROP statements are not processed in reverse order of the CREATE statements, which is the default. --no-terminate When defined, applicable TERMINATE statements are not auto-generated and executed. --pipeline-dir The base directory containing SQL scripts to execute, including recursive subdirectories. Default: value of 'confluent.pipelineSourcePath' or 'src/main/pipeline'. --rest-url The REST API URL for the KSQL Server. Default: value of 'confluent.pipelineEndpoint' or 'http://localhost:8088'.Description Execute all KSQL pipelines from the provided source directory, in hierarchical order, with options for auto-generating and executing DROP and TERMINATE commands.
Group confluent
We can execute our individual pipeline directory using the --pipeline-dir parameter; if we don’t specify this parameter, the task simply executes all SQL statements found recursively in the entire src/main/pipeline directory. This is the killer feature for the plugin: allowing developers to focus on just their individual pipelines or deploy several dependent layers as part of a broader integration test. Let’s execute just the code in 01-clickstream folder as an example:
==> ./gradlew ksql:pipelineExecute --pipeline-dir 01-clickstream> Task :ksql:pipelineExecute 0 queries terminated. 0 objects dropped. 6 objects created.
BUILD SUCCESSFUL in 2s 2 actionable tasks: 1 executed, 1 up-to-date
This was our first time executing the 01-clickstream pipeline, so no objects needed to be dropped and no queries were terminated. Let’s run the pipeline again, but this time, add the -i option to the end, so we get a detailed look at the DROP and TERMINATE handling occurring under the covers. I’ve removed some of the Gradle noise from the output in case your screen looks a little different than mine:
==> ./gradlew ksql:pipelineExecute --pipeline-dir 01-clickstream -i
[..]
> Task :ksql:pipelineExecute
Task ':ksql:pipelineExecute' is not up-to-date because:
Task.upToDateWhen is false.
Terminating query CTAS_ENRICHED_ERROR_CODES_COUNT_3...
DROP TABLE IF EXISTS ENRICHED_ERROR_CODES_COUNT DELETE TOPIC;
Terminating query CSAS_ENRICHED_ERROR_CODES_2...
DROP STREAM IF EXISTS ENRICHED_ERROR_CODES;
Terminating query CTAS_PAGES_PER_MIN_1...
DROP TABLE IF EXISTS pages_per_min;
Terminating query CTAS_EVENTS_PER_MIN_0...
DROP table IF EXISTS events_per_min;
DROP TABLE IF EXISTS clickstream_codes;
DROP STREAM IF EXISTS clickstream;
CREATE STREAM clickstream (_time bigint,time varchar, ip varchar, request varchar, status int, userid int, bytes bigint, agent varchar) with (kafka_topic = 'clickstream', value_format = 'json');
CREATE TABLE clickstream_codes (code int, definition varchar) with (key='code', kafka_topic = 'clickstream_codes', value_format = 'json');
CREATE table events_per_min AS SELECT userid, count(*) AS events FROM clickstream window TUMBLING (size 60 second) GROUP BY userid;
CREATE TABLE pages_per_min AS SELECT userid, count(*) AS pages FROM clickstream WINDOW HOPPING (size 60 second, advance by 5 second) WHERE request like '%html%' GROUP BY userid;
CREATE STREAM ENRICHED_ERROR_CODES AS SELECT code, definition FROM clickstream LEFT JOIN clickstream_codes ON clickstream.status = clickstream_codes.code;
CREATE TABLE ENRICHED_ERROR_CODES_COUNT AS SELECT code, definition, COUNT(*) AS count FROM ENRICHED_ERROR_CODES WINDOW TUMBLING (size 30 second) GROUP BY code, definition HAVING COUNT(*) > 1;
4 queries terminated.
6 objects dropped.
6 objects created.
:ksql:pipelineExecute (Thread[Execution worker for ':',5,main]) completed. Took 3.772 secs.
The pipelineExecute command makes it very easy to iterate on our KSQL code, without having to copy/paste code from SQL scripts into the KSQL CLI or bothering to write DROP and TERMINATE statements every time we want to test an end-to-end pipeline. You may have noticed that the DROP statements execute in the reverse order of the CREATE statements. This was by design, which makes sense if you think about it. The first table/stream created is the last one dropped, and the last one created is the first one dropped. If you don’t care for that feature, turn it off using the --no-reverse-drops option.
Building KSQL artifacts
While executing KSQL scripts from a source code repository is useful for developers and might even suffice for some organizations as a deployment practice, gradle-confluent is really designed to build and publish artifacts that can then be used in an automated deployment process. I wrote artifact generation and handling using Gradle’s built-in support for Maven-style artifacts.
We can execute the ./gradlew build to build a ZIP distribution artifact with all of our KSQL in it, or ./gradlew build publish to build the artifact and publish it to a Maven-compatible filesystem or server. Let’s make a few changes to our build.gradle file in the ksql directory to publish to a local Maven repository, which defaults to the ~/.m2 directory. Of course, a local Maven repository is not fit for real environments, but Gradle supports all major Maven repository servers, as well as AWS S3 and Google Cloud Storage as Maven artifact repositories. We’re also hard-coding our version number to 1.0.0, although we would normally use a plugin such as the axion-release-plugin to handle release management with semantic versioning and automatic version bumping:
plugins {
id "com.redpillanalytics.gradle-confluent" version "1.1.11"
id 'maven-publish'
}
publishing {
repositories {
mavenLocal()
}
}
group = 'com.redpillanalytics'
version = '1.0.0'
Now we can build and publish the artifacts with a single Gradle statement, executing both tasks at once:
==> ./gradlew ksql:build ksql:publish -i Tasks to be executed: [task ':ksql:assemble', task ':ksql:check', task ':ksql:pipelineSync', task ':ksql:pipelineScript', task ':ksql:pipelineZip', task ':ksql:build', task ':ksql:generatePomFileForPipelinePublication', task ':ksql:publishPipelinePublicationToMavenLocalRepository', task ':ksql:publish'] [...] > Task :ksql:build Skipping task ':ksql:build' as it has no actions. :ksql:build (Thread[Execution worker for ':',5,main]) completed. Took 0.0 secs. :ksql:generatePomFileForPipelinePublication (Thread[Execution worker for ':',5,main]) started. [...] > Task :ksql:publish Skipping task ':ksql:publish' as it has no actions. :ksql:publish (Thread[Execution worker for ':',5,main]) completed. Took 0.0 secs.BUILD SUCCESSFUL in 1s 5 actionable tasks: 5 executed
In the above command, the plugin built a .zip file with all our pipeline code but also published that file as a Maven artifact, generating the POM file as well. The artifact has all the source scripts, but it also contains a file called ksql-script.sql, which can be used as a KSQL queries file for running in headless, non-interactive mode if we wanted to deploy in that manner. The ksql-script.sql file is cleaned up—it removes all comments, inter-statement line breaks, etc. If you execute the above command in the root directory, you should see the ksql-pipeline-1.0.0.zip in the ksql/build/distributions directory and also in our local Maven publication location, which is ~/.m2/repository/com/redpillanalytics/ksql-pipeline/1.0.0/.
==> zipinfo ksql/build/distributions/ksql-pipeline-1.0.0.zip Archive: ksql/build/distributions/ksql-pipeline-1.0.0.zip Zip file size: 3593 bytes, number of entries: 9 drwxr-xr-x 2.0 unx 0 b- defN 19-Feb-13 13:05 01-clickstream/ -rw-r--r-- 2.0 unx 381 b- defN 19-Feb-13 13:05 01-clickstream/01-create.sql -rw-r--r-- 2.0 unx 566 b- defN 19-Feb-13 13:05 01-clickstream/02-integrate.sql -rw-r--r-- 2.0 unx 562 b- defN 19-Feb-13 13:05 01-clickstream/03-deliver.sql drwxr-xr-x 2.0 unx 0 b- defN 19-Feb-13 13:05 02-clickstream-users/ -rw-r--r-- 2.0 unx 247 b- defN 19-Feb-13 13:05 02-clickstream-users/01-create.sql -rw-r--r-- 2.0 unx 962 b- defN 19-Feb-13 13:05 02-clickstream-users/02-integrate.sql -rw-r--r-- 2.0 unx 472 b- defN 19-Feb-13 13:05 02-clickstream-users/03-deliver.sql -rw-r--r-- 2.0 unx 2312 b- defN 19-Feb-13 13:05 ksql-script.sql 9 files, 5502 bytes uncompressed, 2397 bytes compressed: 56.4%
Deploying KSQL artifacts
We preferred to use the KSQL REST API for deployment because the ksql.queries.file functionality was still in progress. We want to deploy our KSQL pipelines using the ZIP artifact instead of source control, so we need to define a Gradle dependency on the ksql-pipeline artifact (or whatever we named the Gradle project building our pipelines) so that Gradle can pull that artifact from Maven to use for deployment. We are changing our build.gradle file again, adding the repositories{} and dependencies{} closures, and have specified '+' instead of a hard-coded version number, which instructs Gradle to use the most recent version it can find. Note that the dependency change can be made to the build script in the repository by uncommenting out one line:
plugins {
id "com.redpillanalytics.gradle-confluent" version "1.1.11"
id 'maven-publish'
}
publishing {
repositories {
mavenLocal()
}
}
group = 'com.redpillanalytics'
version = '1.0.0'
repositories {
mavenLocal()
}
dependencies {
archives 'com.redpillanalytics:ksql-pipeline:+'
}
With our KSQL pipeline dependency added, we get a few more tasks when we run ./gradlew ksql:tasks --group confluent, specifically the pipelineExtract and pipelineDeploy tasks:
Confluent tasks --------------- [...] pipelineDeploy - Execute all KSQL pipelines extracted from an artifact dependency, in hierarchical order, with options for auto-generating and executing DROP and TERMINATE commands. pipelineExecute - Execute all KSQL pipelines from the provided source directory, in hierarchical order, with options for auto-generating and executing DROP and TERMINATE commands. pipelineExtract - Extract the KSQL pipeline deployment dependency (or zip file) into the deployment directory. [...]
Now we can execute with the ./gradlew ksql:deploy task, which executes the dependent task pipelineExtract to extract the .zip artifact into the build directory. As a dependency, it also executes the pipelineDeploy task, which functions similarly to the pipelineExecute task, except that it executes the KSQL scripts from the extracted .zip artifact instead of what’s in the src/main/pipeline directory in source control. So the deploy task can be used to execute all or a subset of our KSQL code without having to checkout the Git repository, which is handy for actual deployments.
==> ./gradlew ksql:deploy> Task :ksql:pipelineDeploy 6 queries terminated. 13 objects dropped. 13 objects created.
BUILD SUCCESSFUL in 8s 2 actionable tasks: 2 executed
KSQL directives
Because gradle-confluent auto-generates certain statements, we immediately faced an issue defining how options around those statements would be managed. For the DROP STREAM/TABLE statement, for instance, I needed to control whether the DELETE TOPIC option was appended to the end of a statement. A simple command line option for the Gradle pipelineExecute and pipelineDeploy tasks was not sufficient because it wouldn’t provide the granularity to define this on individual streams or tables. To solve this, I introduced the concept of directives in the plugin. Directives are simply smart comments in our KSQL scripts that control how certain statements are generated. To date, we’ve only introduced the --@DeleteTopic directive, but others can be introduced as needed.
Directives are signaled using --@ followed by a camelcase directive name just above the CREATE STREAM/TABLE command. In this way, directives are similar to annotations on classes or methods in Java.
To see the --@DeleteTopic directive in action, we’ll modify the 01-clickstream/03-deliver.sql script to include it (it’s already added in the Git repository):
-- Aggregate (count&groupBy) using a TABLE-Window --@DeleteTopic CREATE TABLE ENRICHED_ERROR_CODES_COUNT AS SELECT code, definition, COUNT(*) AS count FROM ENRICHED_ERROR_CODES WINDOW TUMBLING (size 30 second) GROUP BY code, definition HAVING COUNT(*) > 1;
Now we can execute the 01-clickstream pipeline directory and see the effect it has on the generated DROP command:
==> ./gradlew ksql:pipelineExecute --pipeline-dir 01-clickstream -i Tasks to be executed: [task ':ksql:pipelineSync', task ':ksql:pipelineExecute'] :ksql:pipelineSync (Thread[Execution worker for ':',5,main]) started. [...] > Task :pipelineExecute> Task :ksql:pipelineExecute Terminating query CTAS_ENRICHED_ERROR_CODES_COUNT_61... DROP TABLE IF EXISTS ENRICHED_ERROR_CODES_COUNT DELETE TOPIC; [...] CREATE TABLE ENRICHED_ERROR_CODES_COUNT AS SELECT code, definition, COUNT(*) AS count FROM ENRICHED_ERROR_CODES WINDOW TUMBLING (size 30 second) GROUP BY code, definition HAVING COUNT(*) > 1; 8 queries terminated. 6 objects dropped. 6 objects created. :ksql:pipelineExecute (Thread[Execution worker for ':',5,main]) completed. Took 2.721 secs.BUILD SUCCESSFUL in 2s 2 actionable tasks: 2 executed
Conclusion
Supporting the development, unit testing, and deployment of KSQL code was the motivation for writing a custom Gradle plugin for the Confluent Platform. But there are additional pieces of the architecture that we need to build and deploy, specifically, custom KSQL user-defined functions and Kafka Streams microservices, which we’ll cover in part 3 of this series. We’ll reuse some existing core and non-core Gradle plugins to solve these two use cases.
Interested in more?
Download the Confluent Platform and learn about ksqlDB, the successor to KSQL.
Other articles in this series
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.