[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Qu'est-ce qu'Apache Flink ?
Apache Flink est un cadre de traitement de données open source qui offre des fonctionnalités uniques en matière de traitement des flux et de traitement par lots. Il s'agit d'un outil prisé pour la création d'applications et d'architectures hautement performantes, évolutives et axées sur les événements.
Créez facilement des flux de données réutilisables de haute qualité avec le seul service Apache Flink® + Kafka en tant que service entièrement géré et cloud native du secteur, qui fournit des analyses et un streaming de données complets grâce à Confluent.
Comment fonctionne Apache Flink ?
Apache Flink est un cadre et un moteur de traitement distribué pour les calculs avec état sur des flux de données illimités et limités. Flink s'adapte à tous les environnements de clusters courants et effectue des calculs à la vitesse en mémoire, à n'importe quelle échelle. Les développeurs créent des applications pour Flink à l'aide d'API telles que Java ou SQL, qui sont exécutées sur un cluster Flink par le framework.
Alors que d'autres systèmes de traitement de données populaires tels qu'Apache Spark et Kafka Streams se limitent au streaming de données ou au traitement par lots, Flink prend en charge les deux. Il s'agit donc d'un outil polyvalent pour les entreprises issues des secteurs de la finance, de l'e-commerce et des télécommunications (entre autres), qui peuvent désormais effectuer le traitement des flux et par lots au sein d'une plateforme unifiée. Apache Flink permet aux entreprises de développer des applications modernes : détection de la fraude, recommandations personnalisées, analyse des marchés boursiers ou encore apprentissage automatique.
Architecture et composants clés d'Apache Flink
Kafka Streams est une bibliothèque intégrée à votre application, tandis que Flink est un moteur autonome de traitement des flux qui est déployé indépendamment. Apache Flink exécute votre application dans un cluster Flink déployé par vos soins. Il apporte des solutions aux problèmes complexes rencontrés par les systèmes de traitement des flux distribués : tolérance aux défaillances, livraison exactly-once, haut débit et latence faible. Ces solutions s'appuient sur des points de contrôle, des points de sauvegarde, la gestion des états et la sémantique temporelle.
L'architecture de Flink est conçue pour le traitement des flux et par lots. Elle peut gérer des flux de données illimités et des jeux de données limités, ce qui permet de traiter et d'analyser les données en temps réel. Flink garantit également l'intégrité des données et la cohérence des instantanés, même dans des scénarios de traitement d'événements complexes.
Le diagramme ci-dessous présente les composants de Flink ainsi que son flux d'exécution. Le code du programme ou la requête SQL sont composés dans un graphe d'opérateur qui est ensuite transmis par le client à un gestionnaire de jobs. Celui-ci divise le job en opérateurs qui s'exécutent en tant que tâches sur les nœuds qui exécutent des gestionnaires de tâches. Ces tâches traitent les données de streaming en continu et interagissent avec diverses sources de données, telles que le système de fichiers distribués Hadoop (HDFS) et Apache Kafka.
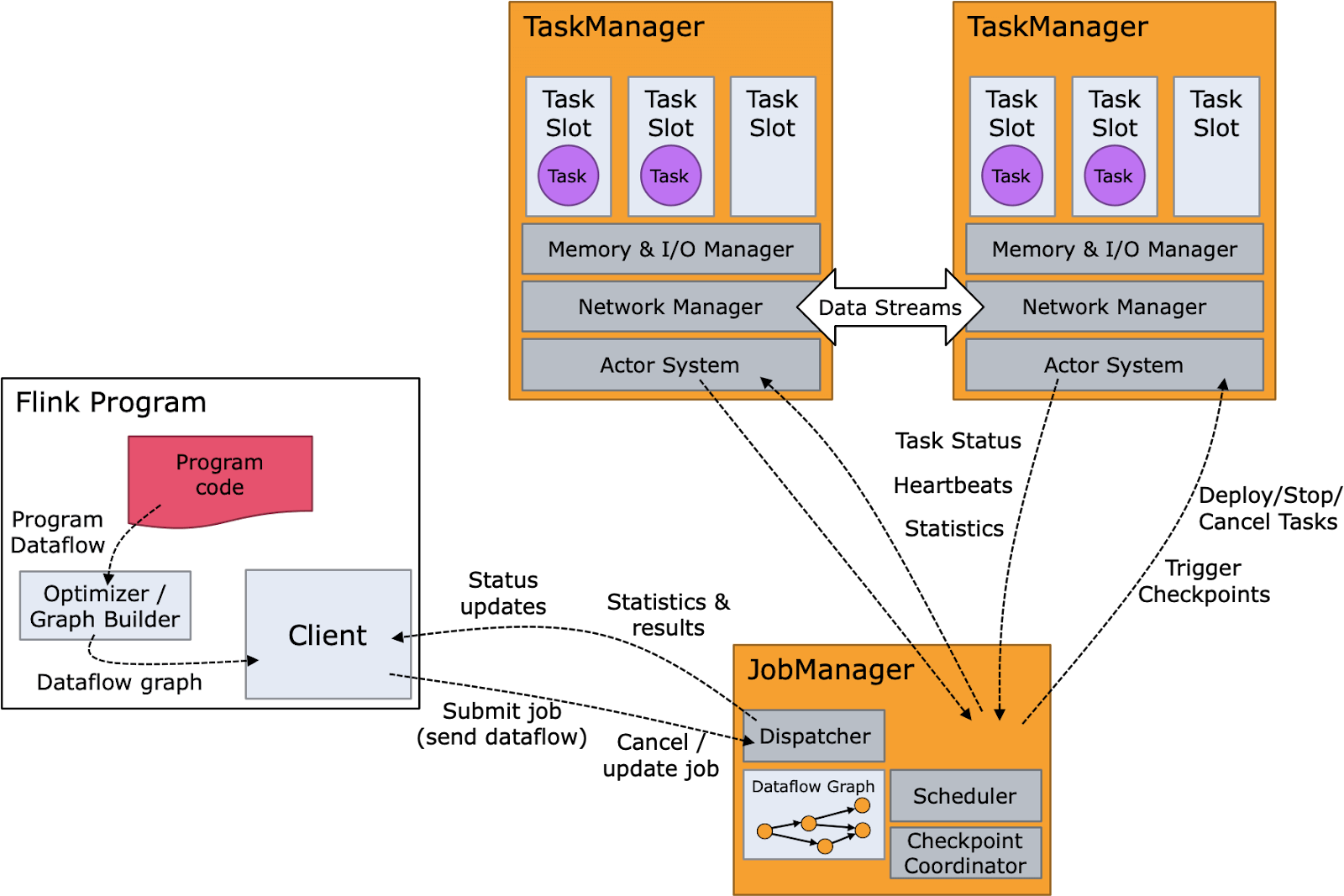
Avantages d'Apache Flink
L'architecture performante d'Apache Flink et ses nombreuses fonctionnalités en font une solution populaire : gestion sophistiquée des états, points de sauvegarde, points de contrôle, sémantique de traitement de l'heure des événements ou encore garanties de cohérence exactly-once pour le traitement stateful.
Le traitement des flux stateful de Flink permet aux utilisateurs de définir des calculs distribués sur des flux de données continus. Des analyses complexes du traitement des événements sur les flux d'événements peuvent ainsi être réalisées, telles que les jointures à fenêtres, les agrégations et le rapprochement de modèles.
Flink peut gérer à la fois des flux limités et illimités, unifiant ainsi les processus de traitement des flux et par lots. C'est une fonctionnalité particulièrement utile pour les cas de streaming en temps réel qui nécessitent le traitement des deux types de données.
Flink a également été conçu pour exécuter des applications stateful à pratiquement toutes les échelles. Il peut traiter des données parallélisées en des milliers de tâches réparties sur plusieurs machines et gérer efficacement de grands jeux de données. C'est donc la solution idéale pour les applications qui doivent évoluer jusqu'à des milliers de nœuds avec une latence et une perte de débit minimales.
Flink propose également des API en couches pour gérer les flux à différents niveaux d'abstraction. Les développeurs bénéficient ainsi de suffisamment de flexibilité pour gérer tous les cas d'usage du traitement des flux, qu'ils soient courants ou hyper-spécialisés.
Flink dispose de connecteurs pour les systèmes de messagerie et de streaming, les banques de données, les moteurs de recherche et les systèmes de fichiers tels qu'Apache Kafka, OpenSearch, Elasticsearch, DynamoDB, HBase et toute base de données disposant d'un client JDBC.
Flink fournit également diverses interfaces de programmation, notamment l'API Streaming SQL et Table de haut niveau, l'API DataStream de niveau inférieur et l'API ProcessFunction pour un contrôle précis. Cette flexibilité permet aux développeurs d'utiliser l'outil adéquat pour chaque problème et prend en charge à la fois les flux illimités et les jeux de données limités.
Le moteur prend également en charge de nombreux langages de programmation, notamment Java, Scala, Python et d'autres langages JVM comme Kotlin, ce qui explique sa popularité auprès des développeurs.
Cas d'utilisation d'Apache Flink
Flink a été conçu comme un processeur de données générique, pourtant, sa prise en charge native des flux illimités a contribué à sa popularité en tant que processeur de flux. Flink affiche des cas d'usage très similaires à ceux de Kafka, bien que ses objectifs soient quelque peu différents. Kafka assure généralement le streaming événementiel tandis que Flink est utilisé pour traiter les données de ce flux. Flink et Kafka sont souvent utilisés conjointement aux fins suivantes :
-
Traitement par lots : Flink est particulièrement performant dans le traitement des jeux de données limités, ce qui en fait la solution idéale pour les tâches de traitement par lots traditionnelles où les données sont limitées et traitées par blocs.
-
Traitement des flux : Flink est conçu pour gérer des flux de données illimités. En offrant un traitement continu des données en temps réel, il convient parfaitement aux applications nécessitant une analyse et une surveillance en temps réel.
-
Applications axées sur les événements : les capacités de Flink en matière de traitement des flux événementiels en font un outil précieux pour créer des applications axées sur les événements, par exemple des systèmes de détection de la fraude et des anomalies, des systèmes de transactions par carte de crédit, la surveillance des processus métier, etc.
-
Mise à jour des applications stateful (points de sauvegarde) : le traitement stateful et les points de sauvegarde de Flink permettent la mise à jour et la gestion des applications stateful. Ainsi, la cohérence et la continuité sont assurées, même en cas d'échec.
-
Application du streaming : le champ d'application du streaming pris en charge par Flink est large, du simple traitement des données en temps réel au traitement d'événements complexes et à la détection de modèles.
-
Analyse des données (lots, streaming) : grâce à sa capacité de gestion des données par lots et de streaming, Flink est un moteur idéal pour l'analyse des données, qu'elles soient en temps réel ou historiques.
- Pipelines de données/ETL : Flink est utilisé dans la conception de pipelines de données pour les processus ETL, où les données sont extraites de diverses sources, transformées et chargées dans des entrepôts de données ou d'autres systèmes de stockage pour une analyse plus approfondie.
Apache Flink : les défis
Apache Flink présente une architecture complexe. Cette solution peut s'avérer difficile à comprendre, à utiliser et à déboguer, même pour les utilisateurs expérimentés. Les développeurs et opérateurs de Flink sont souvent confrontés à des complexités liées aux filigranes personnalisés, à la sérialisation, à l'évolution des types, etc.
Flink pose peut être un peu plus de difficultés que la plupart des systèmes distribués en termes de déploiement et d'exploitation des clusters, notamment en ce qui concerne le réglage des performances en fonction du choix du matériel et des caractéristiques des jobs. Les utilisateurs sont nombreux à s'interroger sur les raisons derrières certains problèmes de performance tels que la contre-pression, la lenteur et la restauration des points de sauvegarde à partir d'états trop volumineux. Parmi les autres problèmes fréquents, on compte la correction des défaillances des points de contrôle et le débogage des échecs de jobs (comme les erreurs liées au manque de mémoire).
Les entreprises qui utilisent Flink s'appuient généralement sur des équipes d'experts chargées de développer des jobs de traitement des flux et d'assurer le bon fonctionnement du framework de traitement des flux. D'un point de vue financier, Flink n'est donc adapté qu'aux grandes entreprises ayant des besoins complexes et avancés en matière de traitement des flux.
Flink, Kafka et Spark : quelles sont leurs différences et quand les utiliser ?
Kafka Streams est une bibliothèque client populaire utilisée pour le traitement des flux, en particulier lorsque les données d'entrée et de sortie sont stockées dans un cluster Kafka. Parce qu'elle dépend de Kafka, elle tire parti des avantages de la plateforme de manière native.
ksqlDB vient ajouter la simplicité de SQL à Kafka Streams. Il fournit ainsi un bon point de départ pour le traitement des flux et en élargit le public.
Les utilisateurs de Kafka et les clients de Confluent confient souvent le processus de traitement des flux à Apache Flink, et ce pour différentes raisons. Par exemple, le traitement de flux complexes se traduit fréquemment par un état intermédiaire volumineux pour lequel Apache Kafka n'est pas toujours adapté. En effet, une fois un certain volume atteint, cet état affecte les ressources et la planification indispensables au bon fonctionnement du cluster Kafka. Par ailleurs, il est parfois nécessaire de traiter séparément les flux issus de plusieurs clusters Kafka, des flux Kafka internes avec des flux externes, etc.
Apache Flink constitue son propre système distribué, avec ses propres difficultés et nuances opérationnelles. Il est donc difficile de déterminer si ses avantages l'emportent sur ses complexités ou sur les coûts qui lui sont associés, en particulier lorsque d'autres technologies de traitement des flux telles que Kafka Streams ou Apache Spark sont disponibles.
Flink entièrement géré avec Confluent : avantages
Le cloud change totalement la donne et permet une utilisation optimale d'Apache Flink. En proposant Apache Flink en tant que service cloud entièrement géré, nous pouvons fournir à Flink les mêmes avantages que Confluent Cloud apporte à Kafka. Les difficultés et nuances opérationnelles qui font d'Apache Flink une solution complexe et coûteuse (sélection du type d'instance ou du profil matériel, configuration des nœuds, sélection d'état en back-end, gestion des instantanés et des points de sauvegarde, etc.), sont gérées pour vous. Cela permet à vos développeurs de se consacrer à la logique de leur application plutôt qu'aux nuances propres à Flink.
Cette approche permet d'intégrer les fonctionnalités de Flink à Confluent Cloud, mais aussi de réévaluer, (d'un point de vue financier) l'utilisation de Flink pour le traitement des flux. Flink peut donc être utilisé pour d'autres cas d'usage à un stade plus précoce du parcours de streaming des entreprises. Par ailleurs, en choisissant la couche de traitement des flux qui leur convient, les développeurs peuvent s'en tenir à une seule plateforme au fil de l'évolution de leurs besoins.
Avec son interface SQL performante et bien établie, Flink est le point de départ idéal pour les utilisateurs finaux qui se mettent au traitement des flux, mais aussi pour Confluent dans son adoption d'Apache Flink.
Confluent Chronicles: The Force of Kafka + Flink Awakens
Introducing the second issue of the Confluent Chronicles comic book! Trust us, this isn’t your typical eBook. Inside you’ll find a fun and relatable approach to learn about the challenges of streaming processing, the basics of Apache Flink, and why Flink and Kafka are better together.


