[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Using Apache Kafka Command Line Tools with Confluent Cloud
If you have been using Apache Kafka® for a while, it is likely that you have developed a degree of confidence in the command line tools that come with it. I am talking about tools that you know and love such as kafka-console-producer, kafka-console-consumer and many others. The popularity of these tools results mainly from the job well done by the community, which has shared thousands of articles, blogs, tutorials and presentations about Apache Kafka and how to use it effectively. These tools are important for developers who work with Apache Kafka, which is why we also provide the same tools with the Confluent Platform.
Over a year ago, we announced the first release of Confluent Cloud™: the simplest, fastest, most robust and cost-effective way to run Apache Kafka in the public cloud. As an Apache Kafka as a service solution, Confluent Cloud allows you to focus on building applications instead of building and managing infrastructure.
While Confluent Cloud provides its own CLI to allow developers manage their topics, some of them might prefer the tools that come with the community edition of Apache Kafka. The good news is that Confluent Cloud is 100% compatible with Apache Kafka and, therefore, the same tools that you know and love can be used here, too.
In order to get the admin tools from Apache Kafka working with Confluent Cloud, simply follow the steps outlined in the rest of this blog post. The steps outlined in this blog will be very useful if you need to maintain clusters both on prem and in Confluent Cloud.
Creating a configuration file
If have used the producer API, consumer API or Streams API with Apache Kafka before, you know that the connectivity details to the cluster are specified via configuration properties. While this might be a no brainer for applications developed to interact with Apache Kafka, people often forget that the admin tools that come with Apache Kafka work in the same way. That means that once you have the configuration properties defined (often in a form of a config.properties file), either applications or the tools will be able to connect to clusters.
With Confluent Cloud clusters, this is no different. Its native CLI is also built upon the same principles. It creates a configuration properties file in the user home directory of the machine containing the connectivity details that you provided during its execution, such as:
- Bootstrap broker list
- Cluster API key
- Cluster API secret
Thereafter, any subsequent command that you issue (i.e., ccloud topic list) will read that file and use it to establish connectivity to the cluster. So the first thing you need to do to interact with your Confluent Cloud clusters via native Apache Kafka tools is to generate a configuration properties file—either by executing the ccloud init command or creating it manually.
Start by accessing the cluster details available in the Confluent Cloud UI. For that, you will need to click in the cluster name that you want the admin tools to connect, as shown in Figure 1.
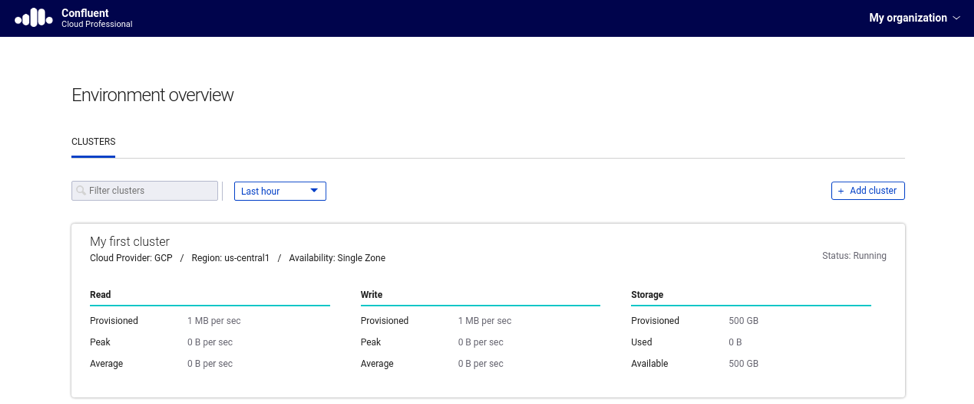
Figure 1. Accessing the cluster in Confluent Cloud
Then, click in the option “Data In/Out” available in the left/upper side of the UI. That will show a sub-menu containing two options, Clients and CLI respectively. Click on the “Clients” option. Figure 2 below gives an example of what you should see after doing these steps.
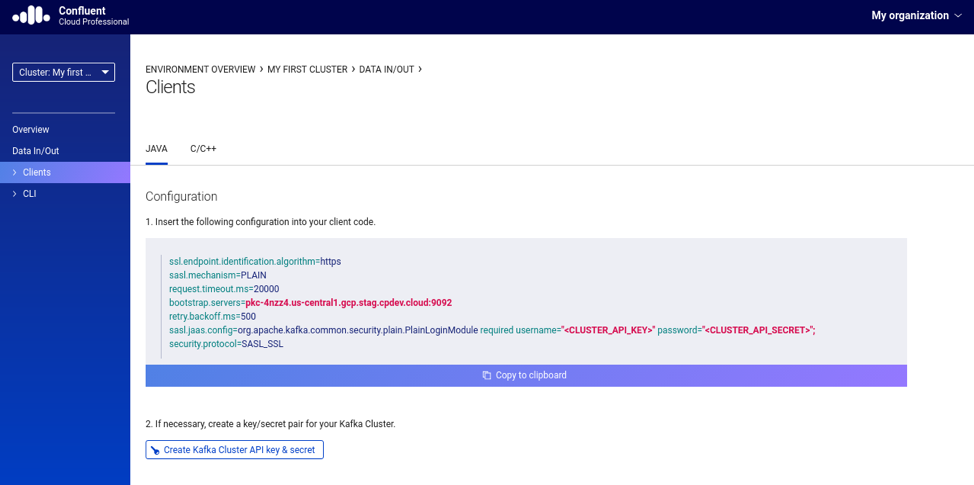
Figure 2. Client configuration for the selected cluster
It will be shown a configuration that you should use in your clients. This is exactly what we need to have the Apache Kafka admin tools accessing clusters in Confluent Cloud. Before copying the configuration, make sure to generate a key/secret pair by clicking in the “Create Kafka Cluster API key and secret” button. The UI will ask you to confirm that the information that is about to be provided is confidential and, therefore, you should keep it safe. Please do that.
Then, after selecting the checkbox option to confirm, you will be presented with the configuration that should be included in the configuration properties file. Listing 1 below shows an example of a configuration properties file that has the same content of what the ccloud tool would generate.
ssl.endpoint.identification.algorithm=https sasl.mechanism=PLAIN request.timeout.ms=20000 bootstrap.servers=<BOOSTRAP_BROKER_LIST> retry.backoff.ms=500 sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="<CLUSTER_API_KEY>" \ password="<CLUSTER_API_SECRET>"; security.protocol=SASL_SSL
Listing 1. Sample configuration properties file
Keep this configuration properties file in a secure location. Remember that through it anyone can access your cluster and create any sort of mess they want, whether it is creating and/or deleting topics, producing more records than what your cluster has been sized to handle, as well as oversubscribing partitions by introducing new consumer group members.
Using Apache Kafka command line tools
Here comes the fun part. We are going to use the configuration properties file created in the previous section with some of the tools that Kafka developers typically use. In the following examples; you should assume that the file config.properties has the same content shown on Listing 1, and has been properly modified to include the information from the Confluent Cloud cluster.
Let’s start by using the kafka-console-producer to produce records to a topic. Listing 2 shows an example of this:
kafka-console-producer --broker-list <BOOSTRAP_BROKER_LIST> --producer.config config.properties --topic <TOPIC_NAME> --property "parse.key=true" --property "key.separator=:"
Listing 2. Using the kafka-console-producer to produce records to a topic
Notice that besides the config.properties file we also had to provide the bootstrap broker list endpoint as well. Some admin tools from Apache Kafka were created to connect to the cluster based on information provided as a parameter. So though it may sound like the bootstrap broker list endpoint is provided twice, this is necessary to properly establish connectivity with the cluster.
Another interesting thing to notice is that the usage of kafka-console-producer allows us to produce records with keys, as seen in Listing 2. Sometimes you want to test if the partitioning model for a given topic is working as expected, and in order to do that, you ought to produce records with keys.
Similarly, you may want to simulate the consumption behavior with the kafka-console-consumer tool. Listing 3 presents an example of consuming records from a topic and printing both key and value for each record consumed:
kafka-console-consumer --bootstrap-server <BOOSTRAP_BROKER_LIST> --consumer.config config.properties --topic <TOPIC_NAME> --property "print.key=true"
Listing 3. Using the kafka-console-consumer to consume records from a topic
Another interesting admin tool is the kafka-consumer-groups. It is often used to troubleshoot potential problems related to records consumption within a consumer group, such as verifying the offset details of a given consumer group or determining its lag issues. Since this tool operates at a consumer group level, you need to know the name of the consumer group that you want to check. If you want to know which consumer groups are available, you can list them using the example from Listing 4:
kafka-consumer-groups --bootstrap-server <BOOTSTRAP_BROKER_LIST> --list --command-config config.properties
Listing 4. Listing the existing consumer groups
Once you get the name of the consumer group you want to inspect, you can use the example shown in Listing 5 to gather its offset details:
kafka-consumer-groups --bootstrap-server <BOOSTRAP_BROKER_LIST> --command-config config.properties --describe --group <CONSUMER_GROUP>
Listing 5. Showing the offset details of a given consumer group
Will this work in any situation?
It is important to note that connectivity from your end to Confluent Cloud clusters is necessary. It’s easy to find yourself trying to understand why your tools are not working when in reality you are facing connectivity issues. Trying to ping the cluster address won’t work because most cloud providers disable ICMP traffic coming from the internet.
Thus, you might want to test the connectivity using a port-based approach. A good way to verify if your cluster is reachable from the machine that is running the tools is by using the netcat tool. Listing 6 below shows an example of how to check if the cluster port is reachable:
nc -zv <BOOSTRAP_BROKER_LIST> 9092
Listing 6. Checking if the cluster’s port is able to receive connections
If the command shown in Listing 6 reveals that the machine is unable to reach the cluster port, then you will need to address the connectivity issue. For that, you will need to understand a bit of the network topology that the machine is relying on.
The most common topology is when you’re connecting to the cluster via the public internet. In this scenario, the machine used for running the tools needs to have access to the public internet via some internet gateway, which in turn means that it needs a public IP address. If that is true and you still can’t reach the cluster port, then you should check any firewall rules that might be applied to the machine. Certain subnets have restrictions on accessing endpoints from the public internet, so you will need to create exceptions for the ports used by the cluster, notably the port 9092.
If this machine is running in a private subnet and doesn’t have a public IP address, it might need to be associated with a NAT (Network Address Translation) gateway that will ensure outbound connectivity.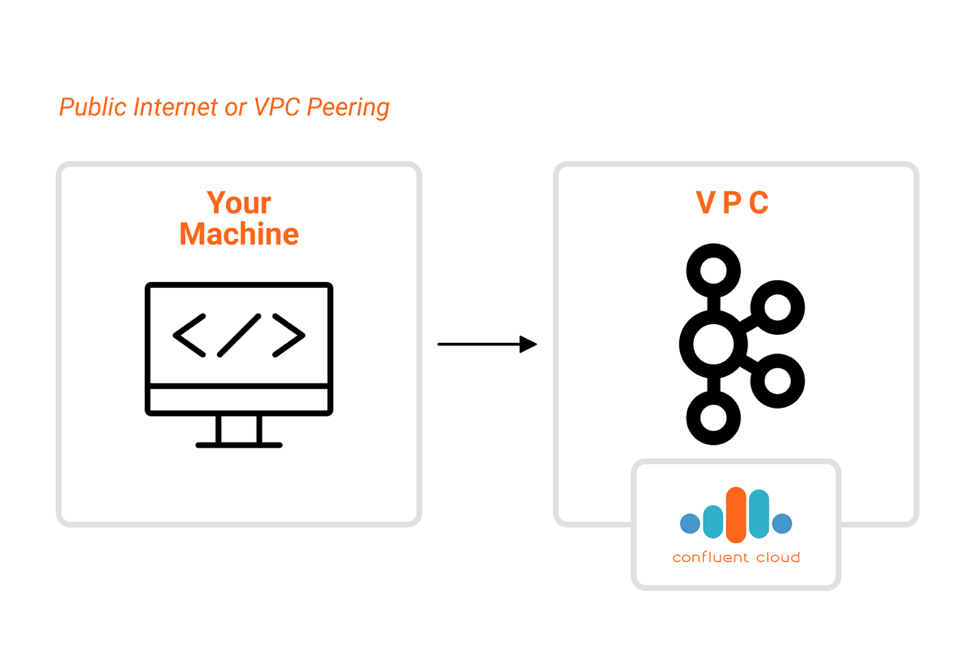 Another situation that you should take into consideration is accessing the cluster from a private channel via an internal endpoint. This occurs when you are accessing the cluster via VPC peering, in which the VPC that hosts the cluster has been peered with another VPC where you intend to run your applications and the tools. In this situation, you need to find out not only if both VPCs has been properly peered but also if there are any firewall rules that can interfere with the connection, which in this case can be be either inbound (connections getting into the cluster VPC) or outbound (connections getting out of your machine).
Another situation that you should take into consideration is accessing the cluster from a private channel via an internal endpoint. This occurs when you are accessing the cluster via VPC peering, in which the VPC that hosts the cluster has been peered with another VPC where you intend to run your applications and the tools. In this situation, you need to find out not only if both VPCs has been properly peered but also if there are any firewall rules that can interfere with the connection, which in this case can be be either inbound (connections getting into the cluster VPC) or outbound (connections getting out of your machine).
Confluent Platform tools are also available
While it’s great to know that the tools from Apache Kafka works seamlessly with clusters from Confluent Cloud, you should know that you are not restricted to that. Users of Confluent Cloud have free-of-charge and unlimited access to the components of Confluent Platform, such as Confluent Control Center, ksqlDB, Confluent Replicator, connectors and others. You can leverage these along with the Kafka tools you already know, and run them anywhere you want, whether if it’s in your laptop, in any on-prem datacenter or in a given cloud provider.
To learn more about Apache Kafka as a service, check out Confluent Cloud, a fully managed streaming data service based on Apache Kafka. Use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage.*
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...