[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
The Value of Apache Kafka in Big Data Ecosystem
This is a repost of a recent article that I wrote for ODBMS.
In the last few years, there has been significant growth in the adoption of Apache Kafka. Current users of Kafka include Uber, Twitter, Netflix, LinkedIn, Yahoo, Cisco, Goldman Sachs, etc. Kafka is a scalable pub/sub system. Users can publish a large number of messages into the system as well as consume those messages through a subscription, in real time. This blog explains why Kafka is becoming popular and its role in the Big Data eco system.
Limitations of the one-size-fits-all model
For a long time, databases have been the primary place where people store and process the most interesting data. Database vendors keep adding new features such as search, streaming and analytics so that more interesting work can be done inside the database. Overtime, this model is no longer ideal for two reasons. First of all, databases become expensive as people try to collect other data sets such as user behavior tracking records, operational metrics, application logs, etc. Those data sets are equally important as transactional data for deriving new insights, but can be two to three orders of magnitude larger. Since traditional databases typically rely upon expensive high end storage systems (e.g. SAN), storing all those data sets in a database becomes prohibitively expensive. Second, as more features are accumulated, databases become more complicated and it gets harder to add new features while still maintaining all the legacy ones. A multi-year release cycle is common among database vendors.
Emergence of specialized distributed systems
To overcome these limitations, people started building specialized systems in the last 10 years. Those systems were designed to do just one thing, but do it really well. Because of their simplicity, it’s more feasible to build them as distributed systems that run on commodity hardware. As a result, those specialized systems are much more cost effective than SAN-based databases. Often, such systems were built as open source projects, which further drives down the cost of ownership. Also, since those specialized systems focus on just one thing, they can be developed and improved much faster than monolithic databases. Hadoop pioneered this approach. It specializes in offline processing by providing a distributed file system (HDFS) and a computation engine (MapReduce) for storing and processing data in batches. By using HDFS, companies can now afford to collect additional data sets that are valuable, but are too expensive to store in databases. By using MapReduce, people can generate reports and perform analytics on those new data sets in a more cost effective way. This pattern has since been repeated in many other areas.
- Key/value stores: Cassandra, MongoDB, HBase, etc.
- Search: Elastic search, Solr, etc.
- Stream processing: Storm, Spark streaming, Samza, etc.
- Graph: GraphLab, FlockDB, etc.
- Time series: Open TSDB, etc.
- …
Such specialized systems enable companies to derive new insights and build new applications that were not possible before.
Feeding specialized systems
While those specialized systems have revolutionized the IT stack, it brings a new challenge: how to feed data into those systems. First, remember there is a wide variety of interesting data types ranging from transactional records, to user tracking data, operational metrics, service logs, etc. Often, the same data set needs to be fed into multiple specialized systems. For example, while application logs are useful for offline log analysis, it’s equally important to search individual log entries. This makes it infeasible to build a separate pipeline to collect each type of data and directly feed it into each relevant specialized system. Second, while Hadoop typically holds a copy of all types of data, it is impractical to feed all other systems off Hadoop since many of them require data more real time than what Hadoop can provide. This is where Kafka comes into play. Kafka has the following nice features.
- It’s designed as a distributed system and can store high volume of data on commodity hardware.
- It’s designed as a multi-subscription system. The same published data set can be consumed multiple times.
- It persists data to disks and can deliver messages to both realtime and batch consumers at the same time without performance degradation.
- It has built-in redundancy and therefore can be used to provide the reliability needed for mission critical data.
Most of those companies mentioned at the beginning invariably have adopted several of those specialized systems. They use Kafka as a central place to ingest all types of data in real time. The same data in Kafka is then fed to different specialized systems. We refer to this architecture as a stream data platform as depicted in the figure below. Adding additional specialized systems into this architecture is easy since the new system can get its data by simply making an extra subscription to Kafka.
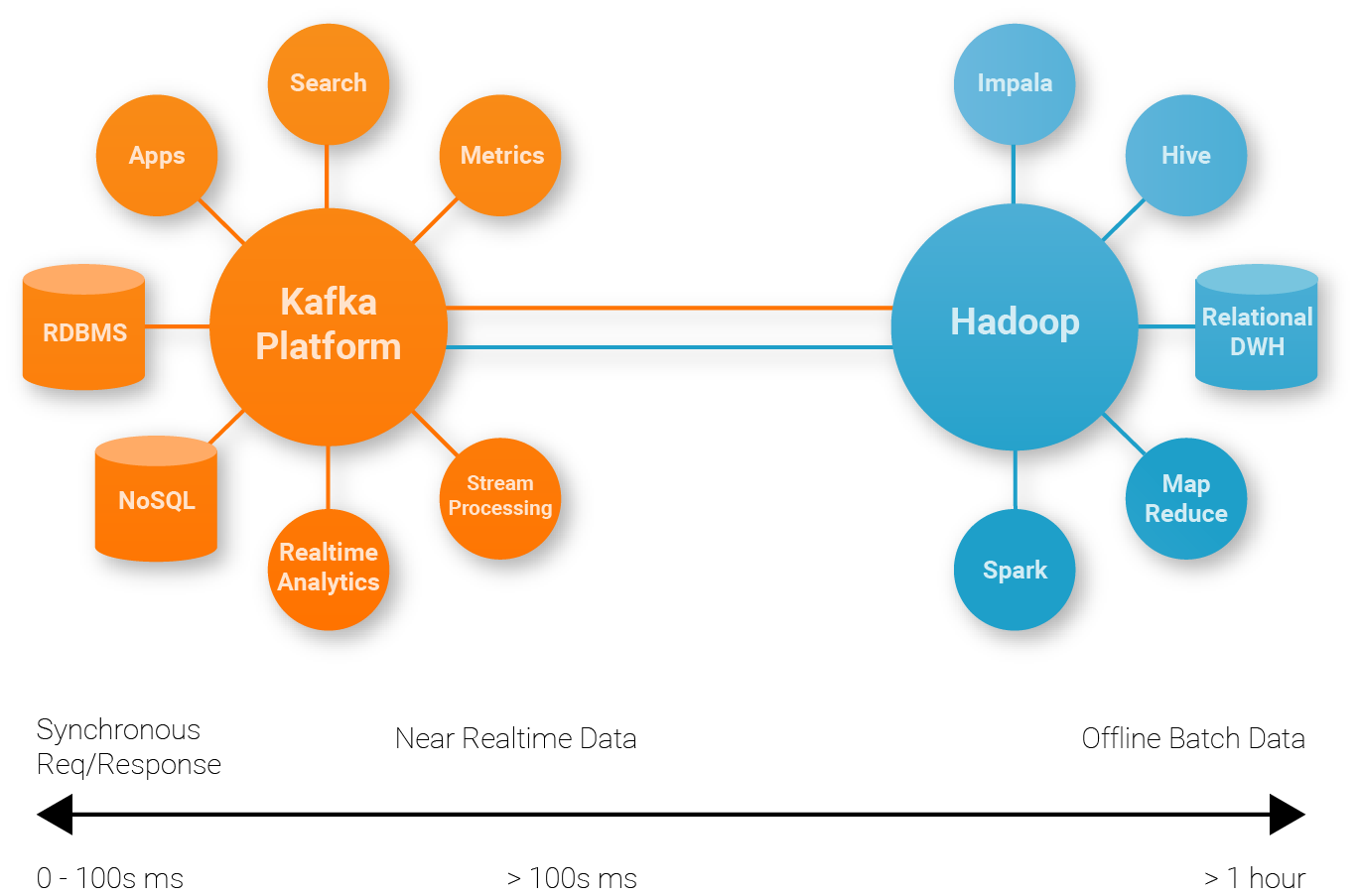
What’s Next ?
The trend in the industry is that multiple specialized systems will co-exist in the Big Data eco system. A stream data platform powered by distributed pub/sub systems like Kafka will play an increasingly important role in this eco system as more companies are moving towards more realtime processing. An impact of this is that one may have one rethink the data curation process. Currently, much of the data curation such as schematizing the data and evolving the schemas is deferred until after the data is loaded into Hadoop. This is not ideal in the stream data platform since the same data curation process then has to be repeated in other specialized systems as well. A better approach is to reason about data duration early when the data is ingested into Kafka. This is part of what we are doing at Confluent and you can find more details in our web site.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Unlocking Data Insights with Confluent Tableflow: Querying Apache Iceberg™️ Tables with Jupyter Notebooks
This blog explores how to integrate Confluent Tableflow with Trino and use Jupyter Notebooks to query Apache Iceberg tables. Learn how to set up Kafka topics, enable Tableflow, run Trino with Docker, connect via the REST catalog, and visualize data using Pandas. Unlock real-time and historical an...



Shifting Left: How Data Contracts Underpin People, Processes, and Technology
Explore how data contracts enable a shift left in data management making data reliable, real-time, and reusable while reducing inefficiencies, and unlocking AI and ML opportunities. Dive into team dynamics, data products, and how the data streaming platform helps implement this shift.