[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Streams and Tables: Two Sides of the Same Coin
We are happy to announce that our paper Streams and Tables: Two Sides of the Same Coin is published and available for free download. The paper was presented at the Twelfth International Workshop on Real-Time Business Intelligence and Analytics (BIRTE) held in conjunction with the 44th International Conference on Very Large Data Bases (VLDB) in Rio de Janeiro, Brazil, in August of this year.
The BIRTE workshop attracted many participants and hosted a keynote, research, industry and demo session as well as a panel discussion about data stream processing.
Paper summary
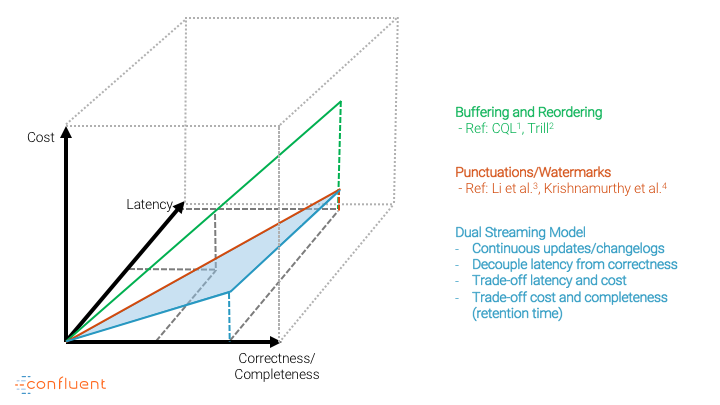
The paper is a joint work between Confluent and Humboldt-Universität zu Berlin that describes the Dual Streaming Model, which is the foundation of Kafka Streams’ and KSQL’s stream processing semantics:
In this paper, we introduce the Dual Streaming Model to reason about physical and logical order in data stream processing. This model presents the result of an operator as a stream of successive updates, which induces a duality of results and streams. As such, it provides a natural way to cope with inconsistencies between the physical and logical order of streaming data in a continuous manner, without explicit buffering and reordering. We further discuss the trade-offs and challenges faced when implementing this model in terms of correctness, latency, and processing cost. A case study based on Apache Kafka illustrates the effectiveness of our model in the light of real-world requirements.
Original Source
The Dual Streaming Model builds on the so-called stream-table duality, which allows you to unify data streams and relational tables into a holistic data processing model. Thus, data streams and continuously updating tables are the two core abstractions in the model. Additionally, the Dual Streaming Model decouples the handling of data that arrives later (i.e., out-of-order) from latency concerns and opens up a design space between processing cost, accepted latency and result completeness for the user that no other model offers.
The wide adoption and growth of Kafka Streams and KSQL among enterprises shows that the Dual Streaming Model solves real-world problems across all types of industries. As a result, we are elated to share our paper for free so you can become the stream processing expert in your company and take the business to the next level.
Happy reading! 🙂
Next steps
- Download the paper Streams and Tables: Two Sides of the Same Coin
- View the slides from BIRTE 2018
- Download Confluent Platform to try out Kafka Streams and KSQL
- Read the Kafka Streams and KSQL documentation
- Check out this recommended read by Eno Thereska: Watermarks, Tables, Event Time, and the Dataflow Model
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.