[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Spring for Apache Kafka Deep Dive – Part 4: Continuous Delivery of Event Streaming Pipelines
For event streaming application developers, it is important to continuously update the streaming pipeline based on the need for changes in the individual applications in the pipeline. It is also important to understand some of the common streaming topologies that streaming developers use to build an event streaming pipeline.
Here in part 4 of the Spring for Apache Kafka Deep Dive blog series, we will cover:
- Common event streaming topology patterns supported in Spring Cloud Data Flow
- Continuous deployment of event streaming applications in Spring Cloud Data Flow
Part 3 showed you how to:
- Set up the local development environment for Spring Cloud Data Flow
- Create and manage event streaming pipelines, including a Kafka Streams application using Spring Cloud Data Flow
For a refresher on how to set up the local development for Spring Cloud Data Flow, see part 3.
In this blog post, let’s try another REST client implementation to access the Spring Cloud Data Flow server, the Spring Cloud Data Flow shell for handling event stream deployment, as you have already seen the Spring Cloud Data Flow dashboard usages in part 3.
First, download and start the Spring Cloud Data Flow shell:
wget http://central.maven.org/maven2/org/springframework/cloud/spring-cloud-dataflow-shell/2.1.0.RELEASE/spring-cloud-dataflow-shell-2.1.0.RELEASE.jarjava -jar spring-cloud-dataflow-shell-2.1.0.RELEASE.jar
Common event streaming topologies in Spring Cloud Data Flow
Named destinations
In Spring Cloud Stream terms, a named destination is a specific destination name in the messaging middleware or event streaming platform. For instance, in Apache Kafka®, it is the name of the Kafka topic itself. In Spring Cloud Data Flow, a named destination (a Kafka topic) can either be treated as a direct source or sink based on whether it (the Kafka topic) acts as a publisher or a consumer.
This is especially useful for Apache Kafka users, because in most of the cases, the event streaming platform is Apache Kafka itself. You would either consume data from a Kafka topic, or you would produce data into a Kafka topic. Spring Cloud Data Flow lets you build an event streaming pipeline from/to a Kafka topic using named destination support. If a topic doesn’t exist at the time of event stream deployment, it gets created automatically by Spring Cloud Data Flow using Spring Cloud Stream.
The Stream DSL syntax requires the named destination to be prefixed with a colon ( : ).
Let’s say you want to collect the user/clicks events from an HTTP web endpoint and apply some filtering logic before publishing those events to a Kafka topic with the name user-click-events. In this case, your stream definition in Spring Cloud Data Flow would look like this:
http | filter > :user-click-events
Now the Kafka topic user-click-events is set up to receive the filtered user click events from an HTTP web endpoint. Let’s assume that you want to create another event streaming pipeline that consumes these filtered user click events to apply some business logic before storing them in an RDBMS. The Stream DSL in this case would look like this:
:user-click-events > transform | jdbc
Both of the above streams virtually form an event streaming pipeline that receives the user/click events from the http source—filtering the unwanted filtered data via filter processor, applies some business logic via transform processor, and eventually stores the transformed data into an RDBMS using jdbc sink.
Named destinations are also useful when developing event streaming pipelines for the fan-in/fan-out use cases.
Parallel event streaming pipelines
It is a common use case to construct parallel event streaming pipelines by forking the same data from the event publishers of the primary stream processing pipeline. Take a primary event stream such as:
mainstream=http | filter --expression= | transform --expression= | jdbc
When the stream named mainstream is deployed, the Kafka topics that connect each of the applications are created by Spring Cloud Data Flow automatically using Spring Cloud Stream. Spring Cloud Data Flow names these topics based on the stream and application naming conventions, and you can override these names by using the appropriate Spring Cloud Stream binding properties. In this case, three Kafka topics will be created:
- mainstream.http: The Kafka topic that connects the http source’s output to the filter processor’s input
- mainstream.filter: The Kafka topic that connects the filter processor’s output to the transform processor’s input
- mainstream.transform: The Kafka topic that connects the transform processor’s output to the jdbc sink’s input
To create parallel event stream pipelines that receive the copy from the primary stream, you need to use the Kafka topic names to construct the event streaming pipeline. For example:
- You may want to tap into the http application’s output to construct a new event streaming pipeline that receives unfiltered data. The Stream DSL would look like:
unfiltered-http-events=:mainstream.http > jdbc
- You may also want to tap into the filter application’s output to get a copy of the filtered data for use in another downstream persistence:
filtered-http-events=:mainstream.filter > mongodb
In Spring Cloud Data Flow, the name of the event stream is unique. Hence, it is used as the consumer group name for the application that consumes from the given Kafka topic. This allows for multiple event streaming pipelines to get a copy of the same data instead of competing for messages. To learn more about tap support, refer to the Spring Cloud Data Flow documentation.
Partitioned event stream
Partitioning support allows for content-based routing of payloads to downstream application instances in an event streaming pipeline. This is especially useful when you want to have your downstream application instances processing data from specific partitions. For instance, if a processor application in the data pipeline that is performing operations based on a unique identifier from the payload (e.g., customerId), the event stream can be partitioned based on that unique identity.
For more information on partitioning support in Spring Cloud Data Flow, refer to the Spring Cloud Data Flow documentation.
Function composition
With the function composition, you can attach a functional logic dynamically to an existing event streaming application. The business logic is a mere implementation of java.util.Function, java.util.Supplier, or java.util.Consumer interfaces that map to processor, source, and sink, respectively.
If you have a functional logic implemented using java.util.Function, you can represent this java.util.Function as a Spring Cloud Data Flow processor and attach it to an existing source or sink application. The function composition in this context could be the source and processor combined into one single application: a new source, or it could be the processor and sink combined into a single application: a new sink. Either way, the transformation logic represented in the processor application can be composed into a source or sink application without having to develop a separate processor application.
This flexibility opens up interesting new opportunities for event streaming application developers. The blog post Composed Function Support in Spring Cloud Data Flow provides a use case walkthrough through this functionality. You can also refer the Spring Cloud Data Flow documentation on function composition feature.
Multiple input/output destinations
By default, Spring Cloud Data Flow represents the one-to-one connectivity between the producer (source or processor) and the consumer (processor or sink) applications in the event streaming pipeline.
If the event streaming pipeline requires multiple input and output bindings, Spring Cloud Data Flow would not configure those bindings automatically. Instead, the developer is responsible for configuring the multiple bindings more explicitly in the application itself. It is also possible to have a non-Spring-Cloud-Stream application (Kafka Connect application or a polyglot application, for example) in the event streaming pipeline where the developer explicitly configures the input/output bindings. To highlight this distinction, Spring Cloud Data Flow provides another variation of the Stream DSL where the double pipe symbol (||) indicates the custom bindings configuration in the event streaming pipeline.
The following sample has multiple event streaming pipelines illustrating some of the above event streaming topologies. This sample has the Kafka Streams application used in part 2, which computes the number of user clicks per region based on the user/clicks and user/region events it receives from the userClicks and userRegions Kafka topics, respectively. The user region data is maintained in a KTable state storage while the user click data is interpreted as KStreams records. The output of the Kafka Streams application is sent to a demo application called log-user-clicks-per-region, which logs the result. To simulate the user clicks/region events, the sample http-ingest application that is built on top of the existing out-of-the-box HTTP application ingests the user/clicks and user/region events into userClicks and userRegions Kafka topics, respectively.
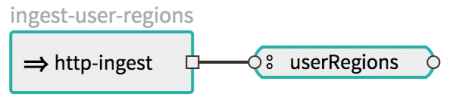
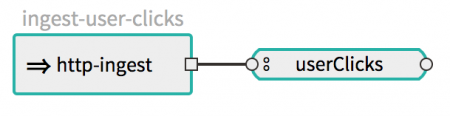
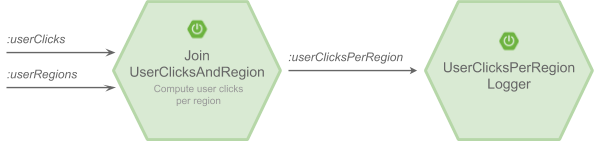
The http-ingest application listens at the configured HTTP web endpoint and publishes the events in a key/value pair. By default, the key is derived from the value of the HTTP request header named username, and the value is derived from the HTTP request payload. The HTTP request payload type is considered to be of String type by default.
For instance, if the http-ingest receives the following HTTP request:
curl -X POST http://localhost:9002 -H "username: Glenn" -d "americas" -H "Content-Type: text/plain"
It publishes the key/value output as Glenn/americas by deriving the key Glenn from the HTTP request header named username and the value americas from the HTTP payload. This way, the http-ingest application can be used to publish the user/region data.
The http-ingest also has a functional bean definition that looks like this:
@Bean public Function<String, Long> sendAsUserClicks() { return value -> Long.parseLong(value); }
With this functional bean enabled and attached to the http-ingest application (via function composition support as explained above), each payload can be converted from String to Long instead of the default payload type String. This way, with the function composition support at runtime, the same http-ingest application can be used to send user/clicks events.
For instance, if the http-ingest (with the above function enabled) receives the following HTTP request:
curl -X POST http://localhost:9003 -H "username: Glenn" -d 9 -H "Content-Type: text/plain"
It publishes the key/value output as Glenn/9 by deriving the key Glenn from the HTTP request header named username and the value 9 by converting the HTTP payload String to Long (by enabling the above sendAsUserClicks function).
This is one of the simplest possible ways to demonstrate the function composition in Spring Cloud Data Flow, as the same http-ingest application can be used to publish both the user/region as well as the user/clicks data at runtime.
For those curious, all the sample applications discussed in this blog post are available in spring-cloud-dataflow-samples. You can register these Maven artifacts as event streaming applications in Spring Cloud Data Flow.
Let’s create the event streaming pipelines after registering the individual applications using Spring Cloud Data Flow shell. If you haven’t already, download and start the Spring Cloud Data Flow shell after setting up Spring Cloud Data Flow.
wget http://central.maven.org/maven2/org/springframework/cloud/spring-cloud-dataflow-shell/2.1.0.RELEASE/spring-cloud-dataflow-shell-2.1.0.RELEASE.jar
java -jar spring-cloud-dataflow-shell-2.1.0.RELEASE.jar
You can register the http-ingest artifact as the Spring Cloud Data Flow source application from the Spring Cloud Data Flow shell:
dataflow:>app register --name http-ingest --type source --uri maven://org.springframework.cloud.dataflow.samples:http-ingest:1.0.0.BUILD-SNAPSHOT
Since we want to name the Kafka topics userRegions and userClicks explicitly, let’s use named destination support when creating the event stream to ingest the user/region and user/clicks events into their corresponding Kafka topics.
Start by creating an event stream that ingests users’ regions:
dataflow:>stream create ingest-user-regions --definition "http-ingest --server.port=9002 > :userRegions" --deploy
Create an event stream that ingests user click events:
dataflow:>stream create ingest-user-clicks --definition "http-ingest --server.port=9003 --spring.cloud.stream.function.definition=sendAsUserClicks --spring.cloud.stream.kafka.binder.configuration.value.serializer=org.apache.kafka.common.serialization.LongSerializer > :userClicks" --deploy
The function composition is enabled by setting the Spring Cloud Stream property spring.cloud.stream.function.definition to the function name sendAsUserClicks, which converts the HTTP payload from String to Long. We also need the set Kafka configuration property value.serializer to org.apache.kafka.common.serialization.LongSerializer to handle the Long type.
Since the Kafka Streams application kstreams-join-user-clicks-and-region has multiple inputs (one for user clicks events and another one for user region events), this application needs to be deployed as an app type. Also, it is the developer’s responsibility to explicitly configure the bindings to the appropriate Kafka topics.
Register this Kafka Streams application as an app type in Spring Cloud Data Flow:
dataflow:> app register --name join-user-clicks-and-regions --type app --uri maven://org.springframework.cloud.dataflow.samples:kstreams-join-user-clicks-and-region:1.0.0.BUILD-SNAPSHOT
We also have the demo application log-user-clicks-per-region that logs the result of the Kafka Streams application join-user-clicks-and-regions. Since the app type is not compatible with the other event streaming application types source, sink, and processor, this application also needs to be registered as an app type to work together as a coherent event streaming pipeline.
dataflow:> app register --name log-user-clicks-per-region --type app --uri maven://org.springframework.cloud.dataflow.samples:kstreams-log-user-clicks-per-region:1.0.0.BUILD-SNAPSHOT
Now that both applications are registered, let’s create the stream that bundles both the Kafka Streams application and its result logger:
dataflow:> stream create clicks-per-region --definition "join-user-clicks-and-regions || log-user-clicks-per-region"dataflow:>stream deploy clicks-per-region --properties "deployer.log-user-clicks-per-region.local.inheritLogging=true"
You can confirm that all three event streams (ingest-user-regions, ingest-user-clicks, and clicks-per-region) are deployed successfully using the stream list command from the Spring Cloud Data Flow shell.
Let’s send some sample data to observe the Kafka Streams aggregation in action.
The http-ingest application in the ingest-user-regions event stream accepts user region data at http://localhost:9002:
curl -X POST http://localhost:9002 -H "username: Glenn" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Soby" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Janne" -d "europe" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: David" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Ilaya" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Mark" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Sabby" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Gunnar" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Ilaya" -d "asia" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Chris" -d "americas" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Damien" -d "europe" -H "Content-Type: text/plain" curl -X POST http://localhost:9002 -H "username: Christian" -d "europe" -H "Content-Type: text/plain"
The http-ingest application in the ingest-user-clicks event stream accepts user clicks events at http://localhost:9003:
curl -X POST http://localhost:9003 -H "username: Glenn" -d 9 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Soby" -d 15 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Janne" -d 10 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Mark" -d 7 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: David" -d 15 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Sabby" -d 20 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Gunnar" -d 18 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Ilaya" -d 10 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Chris" -d 5 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Damien" -d 21 -H "Content-Type: text/plain" curl -X POST http://localhost:9003 -H "username: Christian" -d 12 -H "Content-Type: text/plain"
Once the above data is published, you will see the Kafka Streams application computing the real-time aggregation of user clicks per region and emit the result to the downstream application. In this case, it is the logger application and has the following result in the logs:
o.s.c.s.a.l.UserClicksPerRegion$Logger$1 : europe : 43 o.s.c.s.a.l.UserClicksPerRegion$Logger$1 : asia : 10 o.s.c.s.a.l.UserClicksPerRegion$Logger$1 : americas : 89
Given that this is a real-time event streaming pipeline, you can post more user/click and user/region events and see the results continue to update in real time.
Since we run all the event streaming applications in Docker, let’s delete the event streams before moving to the next sample:
dataflow:>stream destroy ingest-user-regions dataflow:>stream destroy ingest-user-clicks dataflow:>stream destroy clicks-per-region
Continuous deployment of event streaming applications
The applications composed in the event streaming pipeline can undergo changes autonomously, such as a feature toggle enablement or a bug fix. To avoid downtime from stream processing, it is essential to update or roll back such changes to the required applications without affecting the entire data pipeline.
Spring Cloud Data Flow provides native support for continuous deployment of event streaming applications. The application registry in Spring Cloud Data Flow lets you register multiple versions for the same event streaming application. With that, when updating an event streaming pipeline running in production, you have the option to switch to a specific version of the application(s) or change any of the configuration properties of the application(s) composed in the event streaming pipeline.
Let’s walk through the developer experience with the same event stream that we used in part 3, using out-of-the-box event streaming applications.
If you don’t already have the event stream http-events-transformer created and deployed, you can perform the following shell commands to create and deploy the event stream. The sample below uses out-of-the-box event streaming applications that are registered in your Docker Compose setup:
dataflow:>stream create http-events-transformer --definition "http --server.port=9000 | transform --expression=payload.toUpperCase() | log"dataflow:>stream deploy http-events-transformer --properties "deployer.log.local.inheritLogging=true"
Once the stream is successfully deployed, post some data from the Spring Cloud Data Flow shell:
dataflow:>http post --target "http://localhost:9000" --data "spring"
In the skipper log, you will see the following:
log-sink : SPRING
The command stream manifest http-events-transformer shows all the applications for this event stream. For instance, you can see the transform application has the property "transformer.expression": "payload.toUpperCase()". The command stream history http-events-transformer shows the history for this event stream, listing all the available versions.
Now, let’s say you want to change the transformation logic used in the transform application without redeploying the entire stream and update the transform application in isolation.
dataflow:>stream update http-events-transformer --properties "app.transform.expression=payload.toUpperCase().concat('!!!')"
When you run the stream manifest http-events-transformer command again, you will see the transform application is now changed to include the expression property, which transforms each of the payloads by appending !!! at the end.
Once the stream is updated, post some data to test the update:
dataflow:>http post --target "http://localhost:9000" --data "spring"
In the skipper log, you will now see the following:
log-sink : SPRING!!!
The command stream history http-events-transformer will include the new event in the history of this stream. If you want to roll back the event stream to a specific version, you can use the command stream rollback http-events-transformer --releaseVersion.
After rolling back to the initial version of the event stream (where the transform application just did uppercase conversion):
dataflow:>stream rollback http-events-transformer --releaseVersion 1 Rollback request has been sent for the stream 'http-events-transformer'
Once the rollback is complete, post some data:
dataflow:>http post --target "http://localhost:9000" --data "spring" > POST (text/plain) http://localhost:9000 spring > 202 ACCEPTED
In the logs, you will now see the output which uses the initial transformer expression:
log-sink : SPRING
You can delete the event stream as follows:
dataflow:>stream destroy http-events-transformer Destroyed stream 'http-events-transformer'
Please note that all these operations can be performed from the Spring Cloud Data Flow dashboard as well.
Conclusion
We’ve covered some of the common event streaming topologies using Apache Kafka and Spring Cloud Data Flow with a sample application. You have also seen how Spring Cloud Data Flow supports continuous deployment of event streaming applications.
This Spring for Apache Kafka Deep Dive blog series has shown you how the Spring portfolio of projects, such as Spring Kafka, Spring Cloud Stream, and Spring Cloud Data Flow, help you build and manage applications efficiently on Apache Kafka.
Learn more
To learn more about using Spring Boot with Apache Kafka take this free course with expert videos and guides.
You can sign up for Confluent Cloud and use the promo code SPRING200 for an additional $200 of free Confluent Cloud usage.*
Related articles
- Spring for Apache Kafka Deep Dive – Part 1: Error Handling, Message Conversion and Transaction Support
- Spring for Apache Kafka Deep Dive – Part 2: Apache Kafka and Spring Cloud Stream
- Spring for Apache Kafka Deep Dive – Part 3: Apache Kafka and Spring Cloud Data Flow
- How to Work with Apache Kafka in Your Spring Boot Application
- Code samples for Spring Boot and Apache Kafka
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Powering AI Agents with Real-Time Data Using Anthropic’s MCP and Confluent
Model Context Protocol (MCP), introduced by Anthropic, is a new standard that simplifies AI integrations by providing a secure and consistent way to connect AI agents with external tools and data sources…


