[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Sharing is Caring: Multi-tenancy in Distributed Data Systems
Most people think that what’s exciting about distributed systems is the ability to support really big applications. When you read a blog about a new distributed database, it usually talks about how they scaled some use case to a gazillion requests per second. It’s true that distributed systems let you solve problems that couldn’t be handled by a single server, and, yes, modern applications are more data-intensive, but I think this focus on scaling single use cases misses the bigger change distributed systems bring.
What is most exciting to me about distributed systems is not just that they scale, but that horizontal scalability gives them the capacity to operate at a scope that is datacenter-wide or company-wide. The ability to scale, makes it possible to treat these systems not just as a layer in an app, but rather a layer that puts together data across many apps, and maybe even your entire company.
What makes this interesting is that when you change the scope of a system from supporting a single application, to supporting an entire company, totally new problems arise. A great example of this is Apache Mesos. Operating systems have had facilities for managing processes in the scope of a single server more or less forever (process isolation, scheduling, cron, init.d, etc). What Mesos does, in large part, is provide similar functionality (starting and managing processes) but do it at datacenter scope rather than single machine scope. This seems simple enough, but what’s exciting is that by doing this, many new problems that were solved in an ad hoc manner are now suddenly a core part of the problem domain that the system can address. For example, machine utilization goes from being a problem worked on by humans manually moving apps around between machines to something that can be modeled and optimized in software.
I think this change of scope is even more interesting for data systems.
What many people have forgotten is that the client-server relational database was originally envisioned to operate at a very broad scope. You’d have one big database with all the company’s data there, and it would support many applications, ad hoc queries, and reporting needs. It was supposed to look something like this:
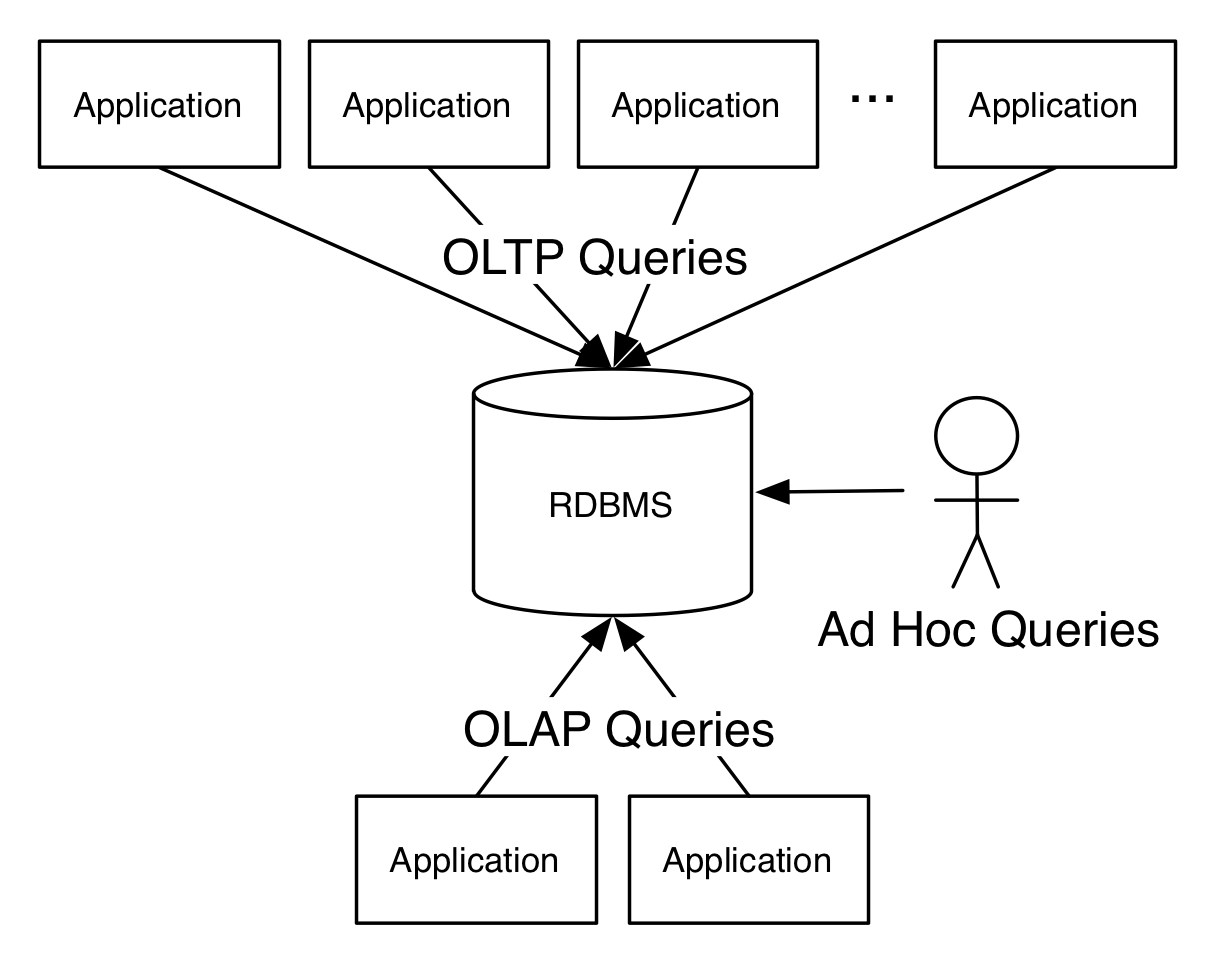
If this was your mental model of how the world worked then you would understandably think that the rise of specialized data systems–Hadoop, ElasticSearch, Cassandra, Kafka, and so on–represent a ferocious rise in complexity. But the above picture hasn’t represented reality for a long, long time (if ever).
A better representation of what happened in the relational database era would be this:
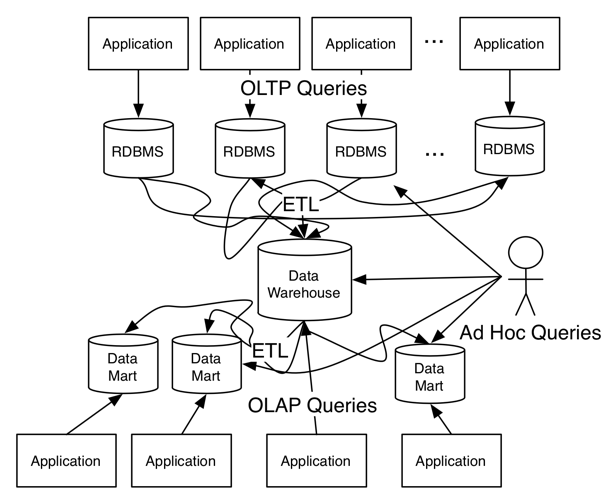
The only unrealistic part of this picture is that it only shows a handful of database instances, while a big organization likely has hundreds or thousands.
It’s true that it was all relational databases, but the scope of the relational database fell from company scope to application scope. And in a microservice world, the idea of a database per application has gone from a convention to a command.
There is really nothing simple about this.
Why did this happen? I think there were two reasons:
- Putting all the data in one big database machine was a lot more expensive than several smaller machines (the cost of “big iron” scales super-linearly).
- It wasn’t really safe to put all these uses on the same physical machine because of performance isolation and security considerations.
But as the scope of the database fell from company-wide to single-application-only it’s functionality declined as well. After all, relational databases let you do things with the data in them. You can join tables together, and compute things on top, you can watch tables with triggers, you can pre-compute things with materialized views. But—and this is critical—you can only do this within the scope of a single database.
The emergence of the data warehouse was really a way to try to get back the originally intended company-wide scope. If you put all the data in a single database somewhere else, where crunching on it wouldn’t break anything, then you could get some of the company-wide scope back.
Data warehouses are what allows you to see how your clicks turn into leads, leads turn into sales and sales drive logins to your applications and break this down by all the dimensions of your customers, products, etc. You can do this because your entire company has been put back in one database—allowing you to easily join data and generate reports.
This brings us to what I really want to talk about: multi-tenancy.
The horizontal scalability you get with a modern distributed system helps solve one of the two problems that lead to the abandonment of company-scope for data systems. Horizontal scalability, done right, lets you grow elastically on cheap hardware. Suddenly it can be cool again to put all the data in one place in an operational system.
But that is only half the problem: scalability alone doesn’t let you go from single-application scope back to company scope. All it lets you do is replace your expensive single-application Oracle or MySQL instance with a single-application distributed database cluster. It doesn’t let you collapse all the disparate databases back into one and make it easy to operate across all the data again.
To make this possible you also have to make it safe to co-locate different use cases, applications, or data sets in a single cluster. This co-location is what I mean by multi-tenancy. And specifically I mean more than just doing this in a limited way, say by diligently planning a few carefully tested applications to co-locate and hoping that their characteristics don’t change. I mean doing this in an elastic and dynamic way that scales up to usage by an entire company’s worth of applications, all being evolved continuously by an organization full of engineers, all without the whole thing tipping over.
Unlike scalability, multi-tenancy is something of a latent variable in the success of systems. You see hundreds of blog posts on benchmarking infrastructure systems—showing millions of requests per second on vast clusters—but far fewer about the work of scaling a system to hundreds or thousands of engineers and use cases. It’s just a lot harder to quantify multi-tenancy than it is to quantify scalability.
But despite all the attention put on scalability, in my experience, real multi-tenancy is actually the far harder property to achieve. Nothing impresses me more than seeing a system run as a service for thousands of users across a company, especially if this can be done without the system needing a protective layer of bureaucracy to keep it from breaking.
Unlike scalability, the only way to really “benchmark” multi-tenancy is to do it. If you hear about many organizations using a system at company scale, then clearly there must be some way to do that. Likewise, in my experience, if you don’t know about anyone doing it, it probably isn’t possible. Good multi-tenancy is hard enough that it just doesn’t happen by accident. A system gains the capability to run this way only when someone tries to do it, hits the many issues big and small, and fixes them.
This has always been our vision for Apache Kafka—we wanted it to be a system that could operate at company scale and bring together streams of data from many parts of the organization. More importantly we also had the job of making this work as we developed Kafka at LinkedIn, we ran it as a freely accessible service that was used by thousands of engineers and connected to by tens of thousands of processes.
The kind of applications that emerge when you have everything that happens in your company represented and stored as a subscribable stream of events is quite amazing, and the kind of problems you have to find and fix to make a system that runs this way are equally amazing.
The last few years have seen us take a lot of really big steps towards this vision in the Kafka community. We’ve added security features that let you authenticate users to the cluster, encrypt the data that is transmitted, and control access to data at a granular level. This is obviously critical for making it possible to use Kafka for applications with sensitive data. We’ve added quotas that let you throttle applications to a predetermined read- or write-rate. This lets you host many applications on a shared cluster without the danger of a single rogue application using more than its fair share of resources.
These features, as well as all the groundwork that had come before, have let a large number of companies deploy Kafka as a company-wide data pipeline. You can see this architecture in place at companies like Netflix, Uber, and Yelp as well, increasingly inside of many large Fortune 500 enterprises, which often have an orders-of-magnitude more complex data integration problem than many of the younger, smaller, Silicon Valley tech companies.
There is, of course, nothing wrong with deploying Kafka for a single big application. That is where most people start, after all. But the advantage of Kafka is not just that it can handle that large application but that you can continue to deploy more and more apps to the same cluster as your adoption grows, without needing a siloed cluster for each use. We’ve talked about this vision before as an event streaming platform–a central home for streams of data that connect disparate applications, systems, datacenters, and make all this data available for real-time processing.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Unlocking Data Insights with Confluent Tableflow: Querying Apache Iceberg™️ Tables with Jupyter Notebooks
This blog explores how to integrate Confluent Tableflow with Trino and use Jupyter Notebooks to query Apache Iceberg tables. Learn how to set up Kafka topics, enable Tableflow, run Trino with Docker, connect via the REST catalog, and visualize data using Pandas. Unlock real-time and historical an...



Shifting Left: How Data Contracts Underpin People, Processes, and Technology
Explore how data contracts enable a shift left in data management making data reliable, real-time, and reusable while reducing inefficiencies, and unlocking AI and ML opportunities. Dive into team dynamics, data products, and how the data streaming platform helps implement this shift.