[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
How to Remove Apache Kafka Brokers the Safe and Easy Way With Confluent Server
The recent release of Confluent Cloud and Confluent Platform 7.0 introduced the ability to easily remove Apache Kafka® brokers and shrink your Confluent Server cluster with just a single command.
Removing Kafka brokers from a cluster seems simple at first glance—an intentional design decision from our user’s perspective—but under the hood, it turns out to have a surprising amount of subtlety and complexity. At Confluent, we work hard to make it as simple as possible to use Kafka at scale by removing complexity from your life.
Confluent Server takes care to drive everything behind the scenes, including moving partitions, guarding against new partitions being placed while partitions are moved off, and even shutting down the brokers at the end!
This blog post details what it takes to safely remove a couple of Kafka brokers from a cluster, and the related challenges for making it happen.
Why remove multiple Kafka brokers?
Before getting into the details of this new feature, it is first worth clarifying the problem space we were trying to solve.
Regular readers of the Confluent Blog may notice that the ability to remove a broker isn’t entirely new with Confluent Platform 7.0; it was first introduced in version 6.0 with the kafka-remove-brokers command.
The need to provide a better and more practical cluster shrink experience, alongside the ability to shrink your cluster in Confluent Cloud, drove us to enhance the functionality of the removal operation. Confluent Cloud’s unit of scale is the CKU (Confluent Unit for Kafka), and these are composed of multiple brokers. Thus, removing multiple brokers at a time became a necessity in order to provide a seamless downscaling option.
Unfortunately, the removal feature released in 6.0 had two notable drawbacks. The first issue was that removal caused intermittent under-replicated partitions in the cluster because the broker was first shut down before the partitions were moved off of it.
The second issue stemmed from the first—you could only remove one broker at a time and had to wait for the load to be rebalanced. Otherwise, you risked having insufficient in-sync replicas (ISRs) based on the Confluent Cloud configured value of 2.
Technically, you could remove multiple brokers in a safe way with the old API by simply issuing the removals one by one. The problem with this approach is that you don’t have a good idea if you can remove a broker until after you’ve already removed it. For example, say you wanted to remove five brokers from a cluster. It may not be until you remove the fourth broker that you discover you don’t have any capacity to remove any more. Worse yet, removing the fourth broker may have resulted in insufficient capacity for your cluster, causing under-replicated partitions and inability to serve data. Pre-computing the capacity you can safely remove can save you from this scenario.
Now that we’ve established what we want to remove from the cluster, let us dive into how that is actually done!
Reassigning partitions intelligently
There are better ways to remove brokers from the cluster. The first step is to reduce their load until they are no longer hosting any partitions.
Apache Kafka exposes the AlterPartitionReassignments API on the Controller Broker, allowing you to pass in a partition and its new target replica set ( the set of broker IDs that should host that partition). Once the API is called, the Kafka controller initiates the data movement, removing old replicas after all the new ones join the in-sync replica set—at which point the reassignment is deemed complete!
Kafka already provides a low-level tool called kafka-reassign-partitions to help with the use of this API, but it is very tricky to use. Users are required to manually stitch together a large JSON file consisting of each partition and its associated replicas.
Further, it does not help users with the very hard bin-packing problem of which broker to move replicas to. It’s not ideal to have users manually orchestrate their cluster shrinking operation—there is a lot of room for manual error. Thankfully, Confluent Platform offers Self-Balancing Clusters.
In an ideal world, there would be a solution that could automate cluster rebalancing operations away from the user’s hands. This could be achieved by some long-running process in the broker that keeps track of the cluster’s resources, understands their load, and can come up with an intelligent way of reassigning the partitions from the brokers that are to be removed. This cluster rebalancer would redistribute the partitions across the cluster to minimize the load impact on the remaining brokers.
Confluent’s Self-Balancing Clusters feature helps serve this exact purpose. The Balancer is a service that is responsible for executing the functions to ensure a Self-Balanced Cluster. It runs inside the Kafka controller and is responsible for any balancing-related functionality, such as bin packing and partition reassignments, as well as the actual broker removal operations. Through the use of per-partition metrics, it computes a plan that consists of partition reassignments, which distribute the load of the to-be-removed brokers evenly across the remainder of the cluster.
These reassignments are then incrementally assigned and resolved so as to not immediately overwhelm the cluster with thousands of reassignments at once.
Operation persistence and state machine
The amount of time it takes to rebalance partitions between brokers varies widely, and is heavily influenced by the amount of data on the broker’s disk. In the case of a Tiered Storage-enabled cluster with just a hundred gigabytes of data on disk, this can be as short as an hour. On the other end of the scale, a cluster without Tiered Storage that contains many terabytes of data on disk can take more than a day or two.
To ensure the rebalance operation remains uninterrupted, it must be resilient to node failures and restarts; the broker removal operation persists its progress to disk and restarts from its last step on any Balancer component failover.
In order for the Balancer to know from what step to restart the operation, we explicitly modeled the different phases of the broker removal operation in a state machine. Pictured below are the states through which the happy path of the broker removal operation goes through.
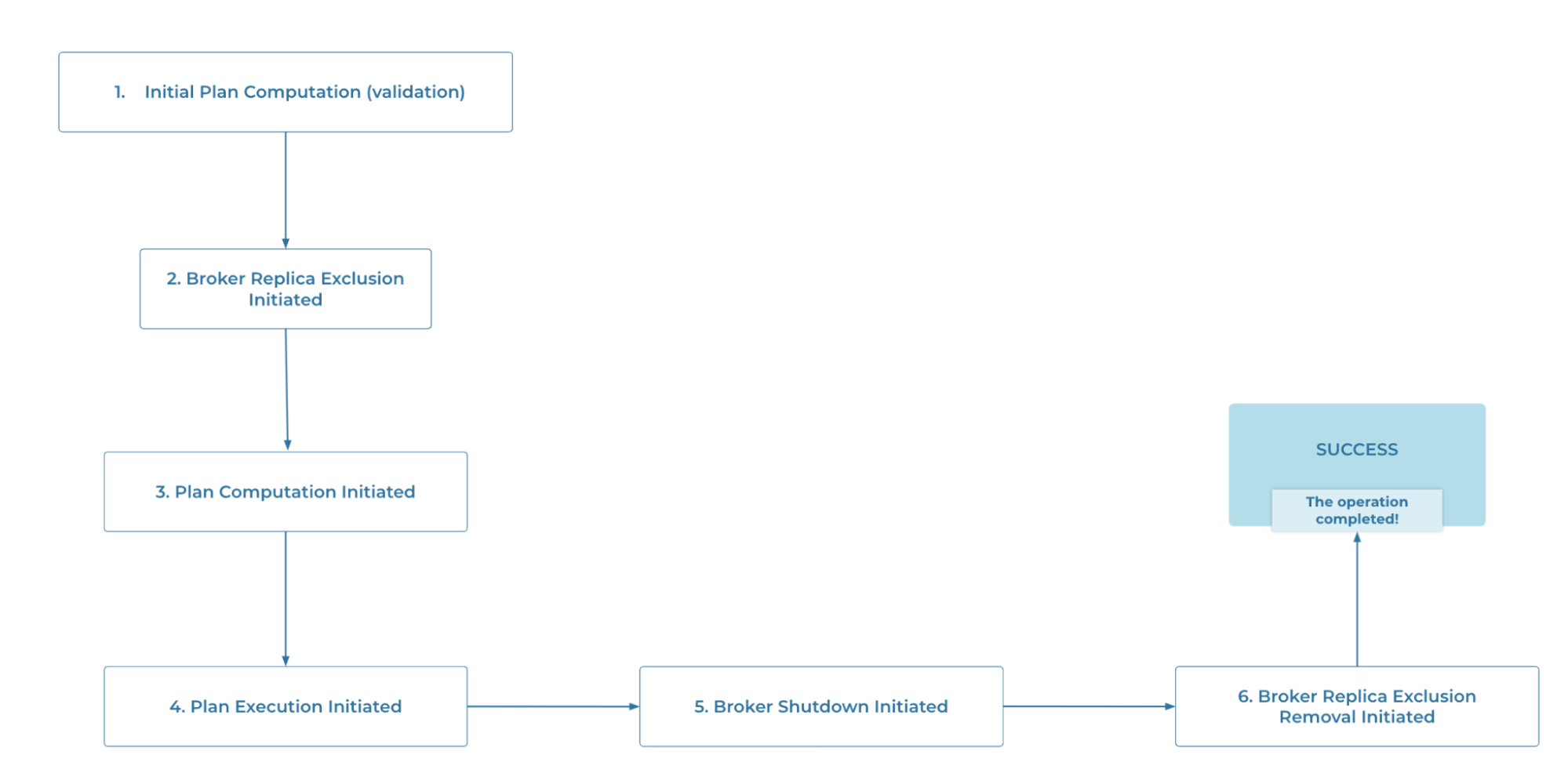
The happy path of the broker removal operation
At the beginning of the operation, and every time the operation enters a new phase, the Balancer component persists the latest state the removal operation was in. While users are asked to retry any unexpected failures from the broker removal operation, the Balancer gracefully handles known failure cases like the component itself being restarted. In such cases, it simply starts from the same operation that was last persisted.
The Balancer uses a Kafka topic with a replication factor of 3 for persisting the operation’s state. The Protobuf formatted records inside the topic enable the Balancer to rebuild its entire state in case of a system failure, minimizing recovery time and the impact to any ongoing rebalances. It’s very handy when the component you’re developing is part of a reliable data store like Kafka!
In case the Balancer is interrupted due to a broker restart, it will consume everything from its topic at startup, detect that there was an ongoing removal operation, and simply resume from where it left off.
What could go wrong?
Of course, robust software is never straightforward to design. You need to account for all sorts of validations and race conditions, and in the case of a long-running operation like this, many can crop up!
Preliminary validations
The most obvious and immediate issues are ones of capacity—it is possible that after removing N brokers, the cluster no longer has the necessary capacity to accommodate the cluster-wide resources. A more extreme version of this is one where the post-removal size of the cluster is less than the replication factor of a given partition—e.g., if a partition has a replication factor of 5, it is not valid to shrink the cluster to a size of four brokers.
These evident capacity issues are easy enough to validate upfront—before initiating the removal operation, we first explicitly validate these possibilities and more by computing a reassignment plan that later gets discarded.
The purpose of this validation is to run through all the resource distribution logic and ensure that we can come up with a solution that distributes resources evenly. This indirectly also ensures that the Balancer component has collected all the necessary metrics it requires.
Race conditions
The trickier problem we wanted to design against was the ability for users to create new topics while the broker removal operation is in progress.
Because there are many actions that need to happen before we can safely shut down the brokers being removed, there is always the risk of a user of the cluster creating a new topic and some of that new topic’s partition replicas ending up on a broker we’re trying to remove!
Below is a diagram that goes over the steps in a shrink request and the zone in which new topic creations would invalidate our previously computed plan.
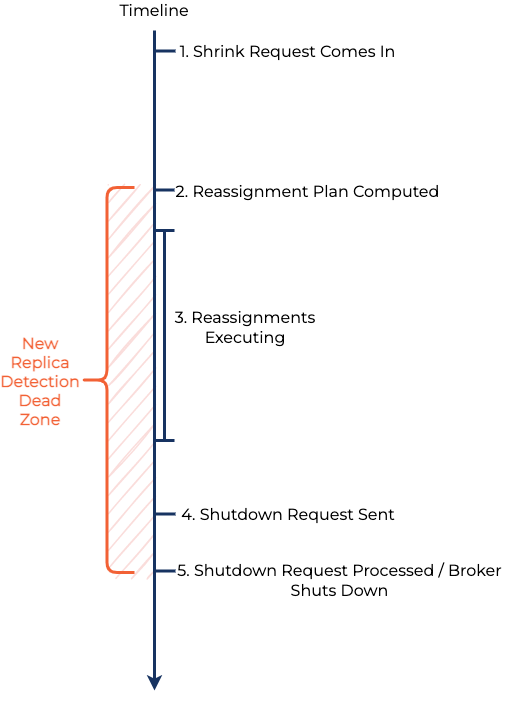
This can happen at any point during the broker removal operation, and given the length of time it can take to remove a broker, we don’t want to fence our users out from creating new topics.
One might think of a naive solution that periodically checks whether a broker has replicas on it before shutting it down and repeats the partition reassignment steps as necessary. But this solution only narrows the window in which race conditions can occur, since a partition can still be created immediately after the final check, but before the broker is terminated. There needs to be a stronger guarantee.
Replica exclusions
After a thorough design process aimed at solving the aforementioned replica placement issue in a consistent and reliable manner, the team developed a new feature called Broker Replica Exclusion.
This is a control-plane API that allows the user to mark a broker as excluded for any new replica placement, essentially forbidding any new replicas to be placed on it.
Any broker marked as excluded will not have any new replicas placed on it during new topic or new partition creation as part of the automatic replica assignment—and in the case of a user-requested explicit assignment containing an excluded broker, an exception is thrown.
Once marked, the exclusion is persisted and is not removed until the API is called again with the explicit intention of removing said exclusion. The operation cleans up after itself by removing the replica exclusion only after the broker is confirmed to be shut down.
Additionally, to help with simplicity in the broker removal layer and drive good API design , the exclusion API is atomic and idempotent in its design.
Exclusion requests are processed atomically. Either the entire set of exclusions are applied, or none are—such as in the case of trying to delete an exclusion that doesn’t exist.
To shutdown or not to shutdown
If you recall from earlier in this blog post, the second drawback of the old remove broker API was that it shut down the broker before the reassignments were started. In the context of Confluent Cloud, that same shortcoming became a generalized problem—the issue became that the command itself does the shutdown.
Confluent Cloud runs on Kubernetes by leveraging a StatefulSet that consists of multiple pods in order to denote the Kafka cluster. In this model, a Kubernetes pod is a Kafka broker.
As Confluent Cloud is configured with the default container restartPolicy of Always, Kubernetes would immediately restart a Kafka pod that just finished its controlled shutdown process. This would not allow us to shut down the Kafka pod for good from the application layer itself—the pod would start right back up!
Additionally, this went against the Operator pattern convention in the Kubernetes world. Confluent already follows that pattern via the Confluent Operator component, which is responsible for managing the lifecycle of Kafka.
The solution we wanted was to have the broker removal operation move all replicas off of the broker and ensure it stayed excluded for new replica placement. Confluent Operator would then pick the cluster shrink operation back up by shutting down the broker for good and removing it from the statefulset.
Unfortunately, the solution was not as simple as changing the removal operation to never issue a shutdown. Since the removal operation was already released with Confluent Platform 6.0 and that version of it did shut down the broker, reverting that behavior would be a backwards-incompatible change and break the contract of the API.
The backwards-compatible change we went with introduced a new boolean flag called toShutdown, which denoted whether the removal operation should go ahead with shutting down the broker. This necessary conditional behavior made us arrive at our final state machine model, which now ends up with two possible paths as it incorporates this fork: shouldShutdown=true and shouldShutdown=false.
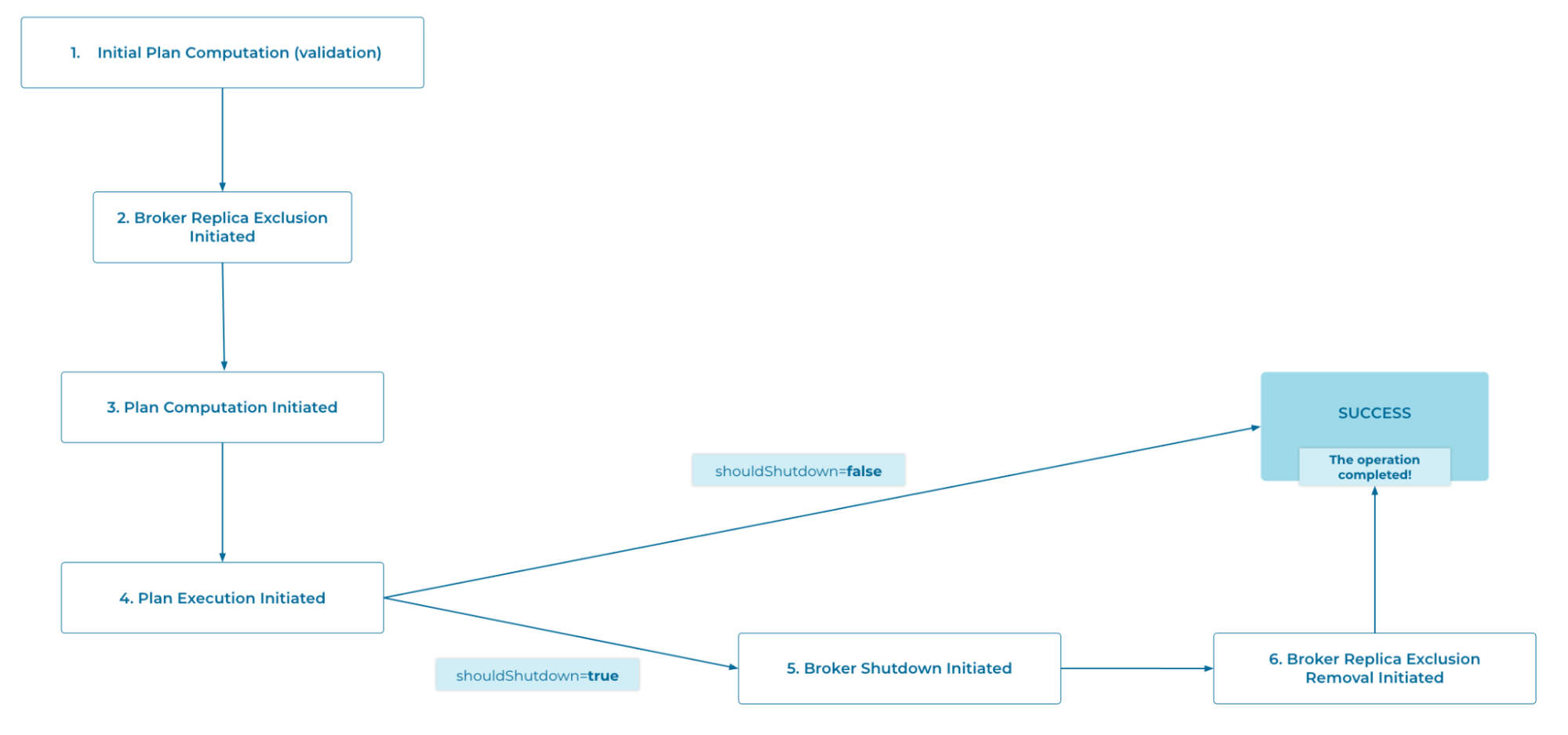
The now-forked version of the broker removal operation state machine
Idempotence
Following best practices of working with a Kubernetes Operator, we made the broker removal operation idempotent. In the case where all the brokers that are part of the removal request are already in the process of being removed, or have been removed from the cluster as part of a previous removal request, the request becomes a no-op and returns a successful status immediately.
The alternative—throwing an exception when a user attempts to remove a broker in the process of being removed, or is already removed—would not aid us in having idempotent subroutines as part of the Operator’s Reconcile loop.
Putting it all together
With that, we have the core building blocks to deliver a well-working multi-broker removal functionality inside Confluent Server.
To recap, the broker removal operation consists of the following steps:
- Compute a reassignment plan as preliminary validation.
- Exclude the brokers marked for removal from having new replicas assigned to them.
- Compute a reassignment plan, this time to actually be used for reassignment.
- Execute the reassignment plan by iteratively issuing the plan’s partition reassignments to the Kafka controller broker.
- Once the plan completes and the brokers are confirmed to be empty, shut down the brokers that had their partitions removed. This step is optional and depends on the toShutdown flag, which defaults to true.
- Clean up the broker replica exclusions on the now shutdown brokers. This step is optional and depends on the toShutdown flag, which defaults to true.
Conclusion
With this six-step process, Confluent offers the full feature of multi-broker removal in Confluent Platform!
This feature also serves as the backbone for cluster shrinking in Confluent Cloud. The result is a cluster that can safely and elastically shrink and expand to meet the varying demands of any real-world use case. Stay tuned to the Confluent Blog in the next few weeks to see more detail on how this was made possible in Confluent Cloud.
In the meantime, consider updating to Confluent Platform 7.1 or opening up the Confluent Cloud UI to try shrinking your cluster today.
If you found any of the intricacies described here interesting — there is much more that goes on behind the scenes! If you’d like to be part of a dynamic team that has no shortage of interesting challenges to solve—we are hiring!
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...