[Webinar] AI-Powered Innovation with Confluent & Microsoft Azure | Register Now
Migrating Data to Azure Synapse with Confluent’s Fully Managed Connector to Unlock Real-Time Advanced Analytics
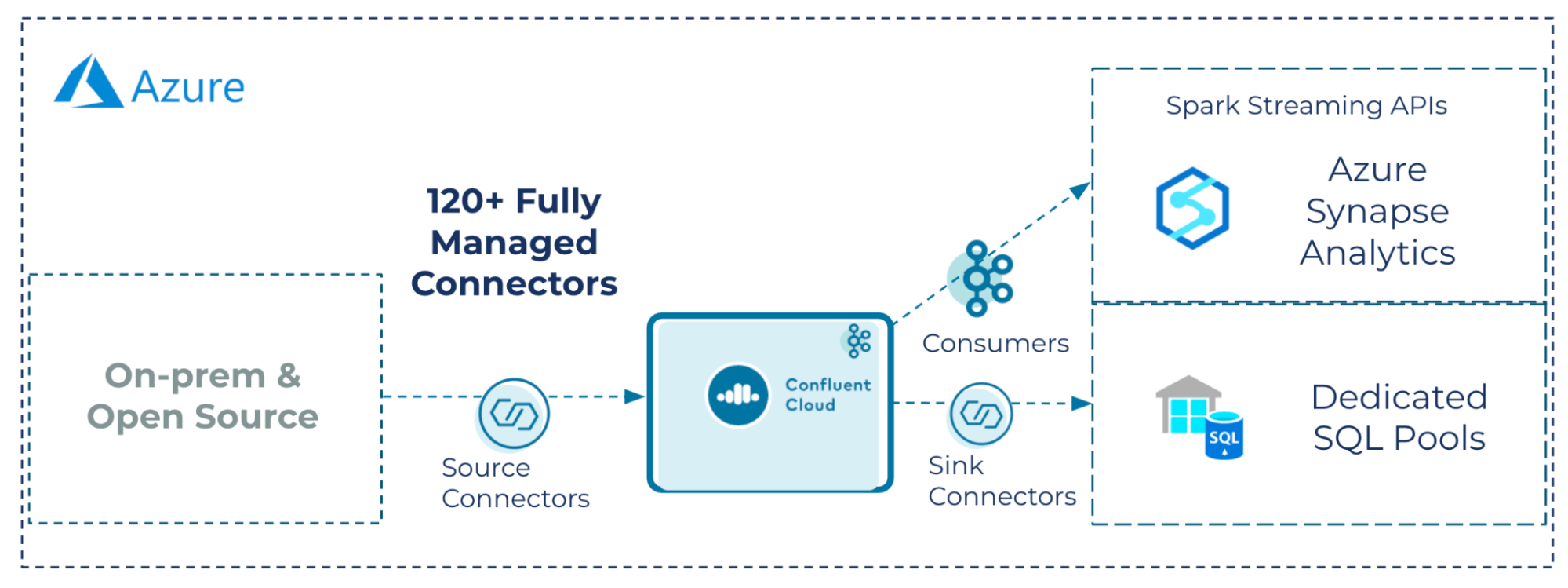
Azure Synapse users are looking to unlock access to on-premises, open source, and hybrid cloud systems to extend advanced analytics capabilities for their organizations. Building connectivity between all your distributed data, apps, and data warehouses is not a trivial task. With Confluent’s rich ecosystem of 120+ connectors that span across clouds and on premises, you can quickly access and migrate the data necessary for their data warehouse use cases. When data flows through Confluent, you can send that data in real time to not only your data warehouse, but also to any application, microservice, or data store that needs it. This blog post reviews how Confluent integrates with Azure Synapse and enables real-time data processing and advanced analytics in Azure.
“Real-time data processing is a key requirement our customers have expressed to us for monitoring, fraud detection, risk analysis, IoT, and many other scenarios. We’re excited to see Confluent addressing this key use case and helping Azure Synapse customers accelerate their digital transformation and achieve faster time to insight.”
—Peri Rocha, Senior Product Manager, Azure Synapse Analytics
Once data is in the Confluent pipeline, you have access to real-time streaming data and can either load data directly from Confluent Cloud into dedicated SQL pools within an Azure Synapse Analytics workspace, or perform real-time queries using the Spark Structured Streaming APIs. The following steps are covered in this blog:
- Ingest data into Azure with Confluent’s fully managed Azure Synapse Connector
- Steps for connector configuration on Confluent Cloud
- Considerations and tips for configuration
- Access real-time data in Apache Kafka® via Spark Structured Streaming APIs from within the Synapse workspace
- Steps for installing prerequisites
- Code example for Spark .readStream and .writeStream in Python
This blog post assumes that you already have the following prerequisites configured:
- Microsoft Azure account
- Confluent Cloud account (or leverage the seamless integration between Microsoft Azure and Confluent Cloud)
- Data already loaded into a Kafka topic in Confluent Cloud.
You can follow along with documentation for one of these examples:
Once on-premises data is in Confluent Cloud, Confluent’s fully managed connectors provide streamlined access to building pipelines to Azure native services. Confluent Cloud has optimized the process for configuring its fully managed connectors, such as dedicated SQL pools (formerly known as Azure SQL Data Warehouse), Azure Cosmos DB, and Azure Data Lake Storage, reducing the effort needed for setup. Confluent Cloud resources can also be configured and associated with cloud platform subscriptions, and provide unified security, billing, and management. Once in Confluent Cloud, live streaming data that feeds into live streaming analytics can also be served to developers, enabling them to build real-time apps or services.
Migrate data into Azure with Confluent’s fully managed Synapse Analytics Sink Connector on Confluent Cloud
Just released this fall, is the fully managed Synapse Connector. Azure Synapse Analytics provides a platform for data analysts and data scientists to analyze and combine data from multiple sources. Within Confluent Cloud, data can be synched to dedicated SQL pools via the fully managed Synapse sink connector and attached to Synapse Analytics workspace. Once added to the Synapse Analytics workspace, analysts have the ability to perform advanced analytics and reporting on data in the Confluent pipeline. The ability to access event-level data enables event-level analytics and data exploration.
Topics in Confluent Cloud can be quickly loaded into dedicated SQL pools, with dynamically created tables and schema by setting auto.create=’true’ and auto.evolve=’true’. To configure the connector within Confluent Cloud, pass in dedicated SQL pool instance details: server.name, user, database.name, and credentials.
Example configuration:
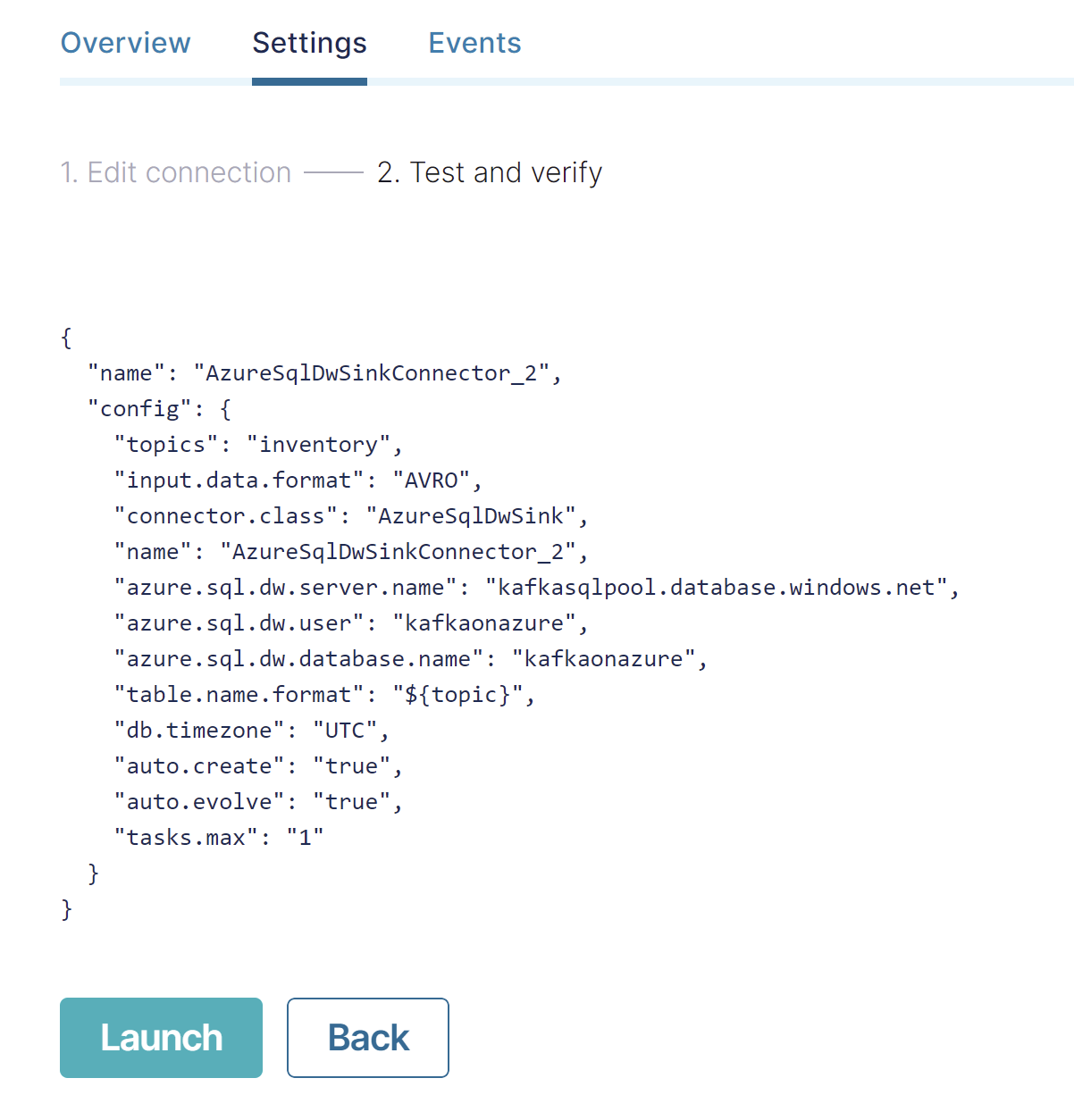
Considerations
Connectivity requires INSERT permissions on the Synapse instance and possibly a firewall rule between your Confluent cluster and your Synapse instance. You can view workspace networking restrictions on Networking -> Firewall rules. There are options to select “Allow Azure services and resources to access this workspace,” or add client IP address/IP ranges to access.
Primary keys are not supported by Azure Synapse, therefore, the connector does not support updates, upserts, or deletes. When auto.evolve is enabled, if a new column with a default value is added, that default value is only used for new records. Existing records will have “null” as the value for the new column.
Access real-time data in Kafka via Spark Structured Streaming APIs
Data sent to Confluent Cloud can be processed with Azure Synapse serverless Apache Spark by using the Structured Streaming APIs. These APIs are available using Python or Scala. To read data from Confluent a few packages need to be installed in the Spark pool that will be used.
Prerequisites
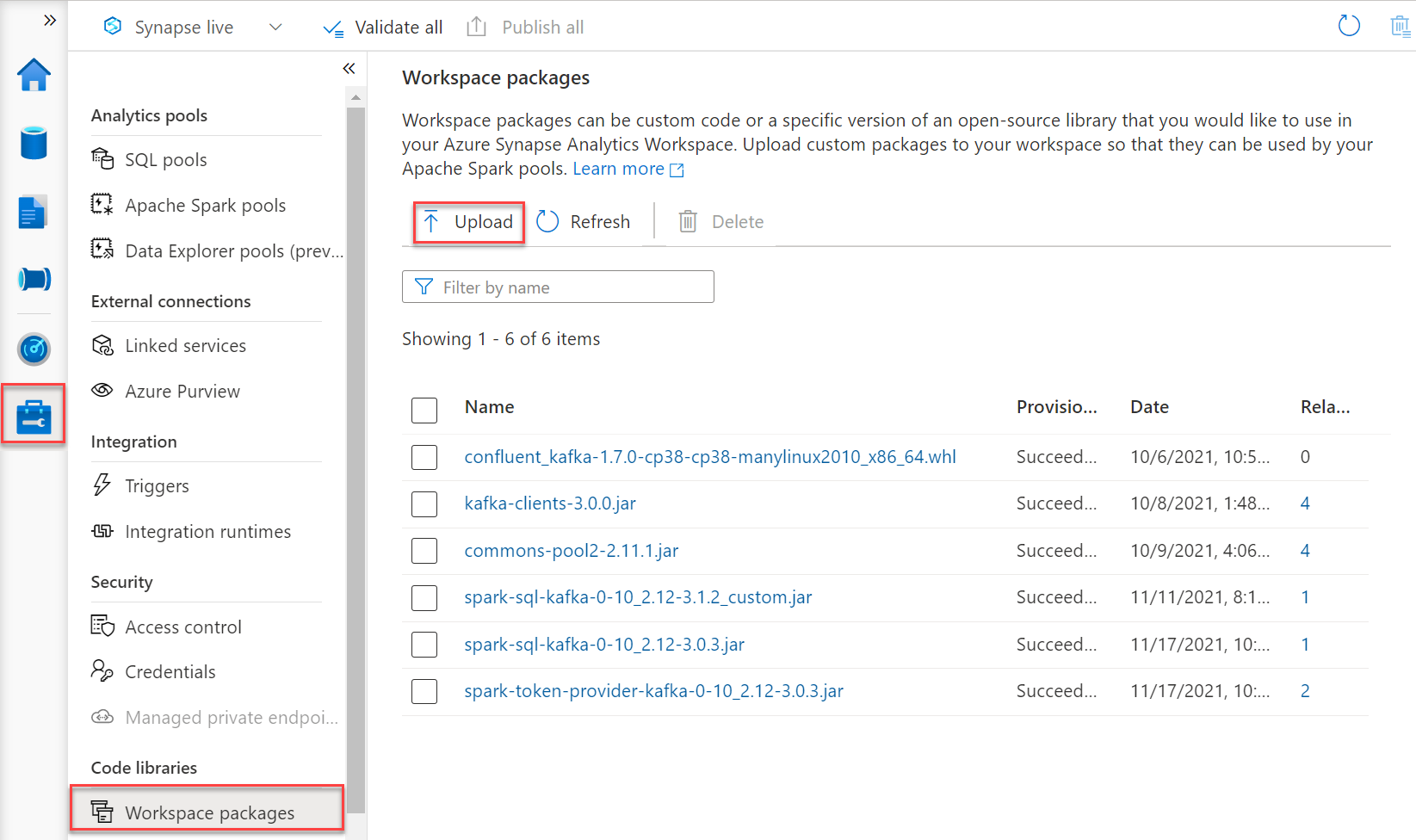
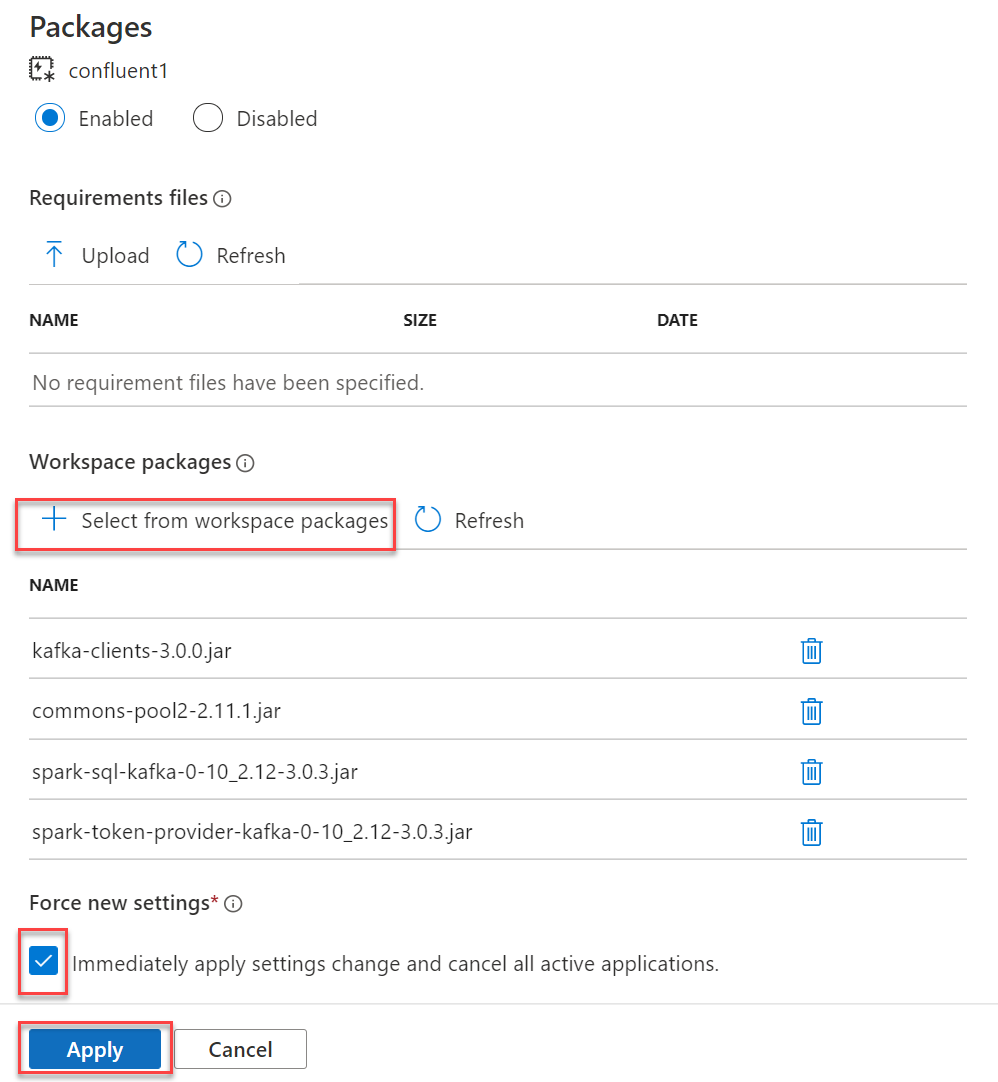
Add the required packages as “Workspace packages” by following the steps below.
- Download the following packages from MvnRepository:
- From the Manage hub, choose Workspace packages and upload packages to your workspace.
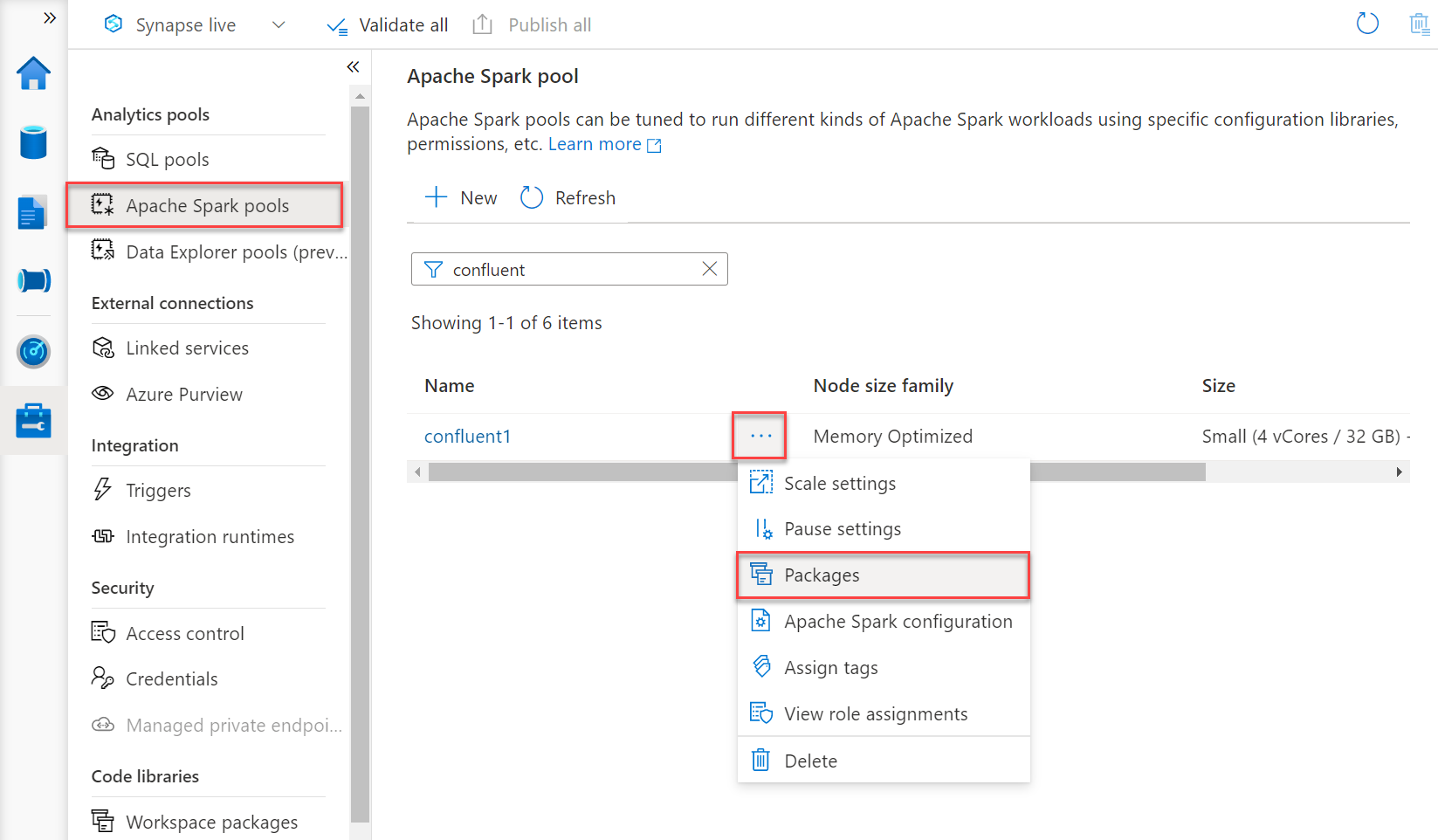
- Attach the packages to your Spark pool, select Force new settings, then select Apply.
Post installation, the Spark Structured Streaming APIs can now reference Kafka as a source programmatically via Python code. A new workbook can be created, and within the code a connection to the Kafka server and topic can be instantiated. PySpark libraries, pyspark.sql.functions, pyspark.sql.avro.functions, and pyspark.sql.type can be included in the project. And Spark functions .readstream and .writestream can be instantiated by passing connection details.
Spark code example:
##Define variables
confluentBootstrapServers = "<insert bootstrap server name>" confluentApiKey = "<insert Kafka API Key>" confluentSecret = "<insert Kafka secret >" confluentTopicName = "<insert Kafka topic name>" adls_path = "<insert your Azure Storage destination path>"
##Import PySpark libraries
import pyspark.sql.functions as fn from pyspark.sql.avro.functions import from_avro from pyspark.sql.types import StringType binary_to_string = fn.udf(lambda x: str(int.from_bytes(x, byteorder='big')), StringType())
##Create Spark readstream and writestream
clickstreamTestDf = ( spark .readStream .format("kafka") .option("kafka.bootstrap.servers", confluentBootstrapServers) .option("kafka.security.protocol", "SASL_SSL") .option("kafka.sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(confluentApiKey, confluentSecret)) .option("kafka.ssl.endpoint.identification.algorithm", "https") .option("kafka.sasl.mechanism", "PLAIN") .option("subscribe", confluentTopicName) .option("startingOffsets", "earliest") .option("failOnDataLoss", "false") .load() .withColumn('key', fn.col("key").cast(StringType())) .withColumn('fixedValue', fn.expr("substring(value, 6, length(value)-5)")) .withColumn('valueSchemaId', binary_to_string(fn.expr("substring(value, 2, 4)"))) .select('topic', 'partition', 'offset', 'timestamp', 'timestampType', 'key', 'valueSchemaId','fixedValue') ) query = (clickstreamTestDf.writeStream .option("checkpointLocation", "{}/checkpoints/confluent".format(adls_path)) .format("delta") .outputMode("append") .trigger(once=True) .start("{}/output".format(adls_path))
) query.processAllAvailable() query.stop()
Considerations
When testing this out in your Synapse environment, be sure to stop the session when you leave the notebook so that your Spark pool does not continue to charge. In the monitor hub of Synapse Studio you can view which Apache Spark pools have allocated resources and cancel Spark applications that are running.
Managing dependencies in Synapse Analytics Apache Spark pools requires finding the correct versions of the new libraries which are compatible with the Spark, Scala, and Python versions. If you encounter errors please confirm that the libraries show the same versions in this post and that the Spark pool is using Apache Spark 3.1.
Takeaways
Azure Synapse Analytics is a tool that will increasingly enable Azure users to access and combine real-time data, so that you can gain valuable insights. Confluent’s fully managed Azure Synapse Connector makes it easy for Azure users to bring data stored in Apache Kafka, Confluent Platform, or Confluent Cloud into Azure for analytics. Additionally, Azure Synapse also enables real-time query access against real-time streaming data in Kafka.
Pairing Confluent with Microsoft Azure helps you:
- Reduce the TCO and time to value of hybrid and multicloud data pipelines powering real-time ETL for your data warehouse
- Unlock next-gen event streaming capabilities at cloud scale to power new analytics and real-time apps
- Connect to any app, data warehouse, or data, no matter where it lives, to get more data to and from your data warehouse
Furthermore, Confluent enables businesses to build an integrated data analytics platform with Microsoft Azure with unified security, billing, and management—all accessible via Azure Marketplace. Looking to accelerate your cloud data warehouse migration and modernization with Confluent? Read the technical overview Confluent Data Warehouse Modernization with Microsoft Azure or check out the on-demand webinar with Alicia Moniz and Peri Rocha to learn more.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...