It’s Here! Confluent’s 2026 Data + AI Predictions Report | Download Now
Putting Events in Their Place with Dynamic Routing
Event-driven architecture means just that: It’s all about the events. In a microservices architecture, events drive microservice actions. No event, no shoes, no service.
In the most basic scenario, microservices that need to take action on a common stream of events all listen to that stream. In the Apache Kafka® world, this means that each of those microservice client applications subscribes to a common Kafka topic. When an event lands in that topic, all the microservices receive it in real time and take appropriate action.
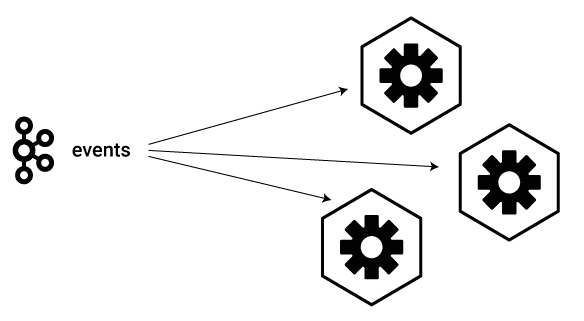
This paradigm of multiple services acting on the same stream of events is very flexible and extends to numerous domains, as demonstrated in practice through the various examples throughout this blog post:
- Finance: a stream of financial transactions in which each financial transaction is an event. Services that may act on this event stream include account services, fraud remediation and customer notifications.
- IoT: a stream of sensor data in which each sensor reading is an event. Services that may act on this event stream include device tracking, predictive maintenance and early part scrapping.
- Retail: a stream of purchases in which each purchase is an event. Services that may act on this event stream include inventory management, email notifications and customer loyalty programs.
This is the simplest way a microservice can subscribe to a stream of events: Within the microservice application, use the Kafka Streams library to build a stream from the data in a Kafka topic, using the method StreamsBuilder#stream().
StreamsBuilder builder = new StreamsBuilder(); KStream<String, Event> events = builder.stream(eventsTopicName); // then take action on the events in the stream
Once this stream is created, the application may take any action on the events using the rich Kafka Streams API. This provides capabilities such as data filtering, transformations and conversions, enrichments with joins, manipulation with scalar functions, analysis with stateful processing, aggregations and windowing operations.
Branching an event stream
Next, let’s modify the requirement. Instead of processing all events in the stream, each microservice should take action only on a subset of relevant events. One way to handle this requirement is to have a microservice that subscribes to the original stream with all the events, examines each record and then takes action only on the events it cares about while discarding the rest. However, depending on the application, this may be undesirable or resource intensive.
A cleaner way is to provide the service with a separate stream that contains only the relevant subset of events that the microservice cares about. To achieve this, a streaming application can branch the original event stream into different substreams using the method KStream#branch(). This results in new Kafka topics, so then the microservice can subscribe to one of the branched streams directly.
For example, in the finance domain, consider a fraud remediation microservice that should process only the subset of events suspected of being fraudulent. As shown below, the original stream of events is branched into two new streams: one for suspicious events and one for validated events. This enables the fraud remediation microservice to process just the stream of suspicious events, without ever seeing the validated events.
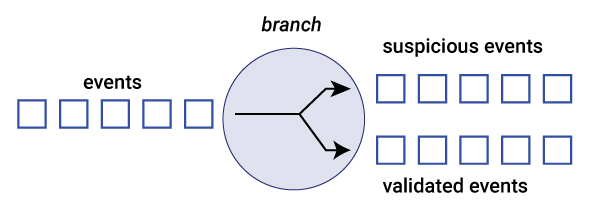
Branching decisions are based on supplied predicates. These predicates (and thus branches) must be fixed in number, and they can evaluate data in the event itself. In the example here, there are two predicates:
- If the event’s transaction value is greater than or equal to a predefined FRAUD_LIMIT, the event is routed to the topic of suspicious events
- If the event’s transaction value is less than a predefined FRAUD_LIMIT, the event is routed to the topic of validated events
final KStream<String, Event>[] branches = events.branch(
(id, event) -> event.getTransactionValue() >= FRAUD_LIMIT,
(id, event) -> event.getTransactionValue() < FRAUD_LIMIT);
branches[0].to(suspiciousTransactionsTopicName);
branches[1].to(validatedTransactionsTopicName);
To use KStream#to(), the output Kafka topics need to be created before running the application. This requirement was a deliberate decision discussed within the user community, and it provides two benefits. First, it ensures that the output topics are created with the required configuration settings. Second, it prevents a buggy or rogue application from creating a bunch of false output topics that would then have to be cleaned up. Consequently, in the above example, the topics defined by the parameters suspiciousTransactionsTopicName and validatedTransactionsTopicName must have already been created ahead of time.
To see this equivalent branching functionality using KSQL, read the latest blog post from Robin Moffatt, KSQL: What’s New in 5.2. It describes how to the new KSQL capability CASE which defines predicates and assigns values to a field, after which separate KSQL queries can branch to different output streams based on that field.
Dynamic routing
Thus far, the application has assumed advance knowledge of the output topic names. You probably can guess where I am going next—changing the requirement such that either there is no advance knowledge of the output topic names or the output topic names may dynamically change.
It used to be the burden on the Kafka Streams application (by which, I really mean a burden on the developer) to respond to topic name changes. This entailed reconfiguring and restarting the Kafka Streams application each time there was a topic name change. This was certainly possible to do but very painful and caused service disruption.
What is more valuable is allowing the microservice to dynamically set the output topic at runtime. This is called dynamic routing. KIP-303 provides the dynamic routing capability with a new interface called TopicNameExtractor, which allows the sink node of a Kafka Streams topology to dynamically determine the name of the Kafka topic to which to send records. To leverage this feature, use Apache Kafka version 2.0 or later.
If the output topic name can be derived from the event itself, then the TopicNameExtractor method can be applied directly on the original stream. For example, in the IoT domain, consider a use case where all sensor data from multiple device types are first sent to a single event stream because it all needs to be cleansed in a consistent way. Cleansing could mean using the Kafka Streams API to drop records with null values, superfluous fields, irrelevant types, etc.
After cleansing data from all devices, the events can be dynamically routed to new Kafka topics, each of which represents a single device type. That device type may be extracted from a field in the original sensor data.
final KStream<String, Event>[] cleansedEvents = events
// …some data cleansing…
cleansedEvents.to((eventId, event, record) -> event.getDeviceType());
The output topics still need to be created ahead of time, so the expected set of device types should be known, and their corresponding output topics must have already been created before running the application. Over time, if a new device type starts sending sensor data, you will need to create the output topic ahead of time, but you will not need to restart the streaming application.
Getting the output topic name from another data source
Let’s now consider a new example in the retail domain in which there is a stream of real-time orders. The goal may be for a microservice to dynamically route orders to output topics that represent the customer loyalty level. In our example, each order event does not contain the loyalty level, so the output topic name cannot be derived directly from the stream like it was in the previous example.
But the order does contain a field with the customer ID, and it just so happens there is a MySQL database that maps the customer ID to all the information about that customer, including name, address and customer loyalty level. So the microservice needs access to the customer information in that database to make the appropriate routing decision on the order.
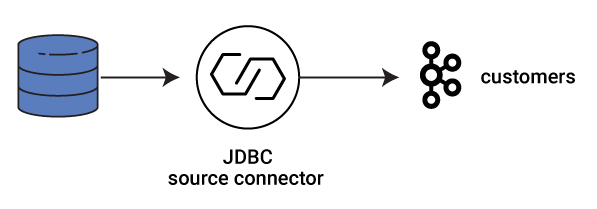
There are various ways to integrate the database with Kafka as discussed in Robin Moffatt’s blog post No More Silos: How to Integrate Your Databases with Apache Kafka and CDC. In essence you can take a log-based or a query-based approach. We will demonstrate the query-based approach in this blog post, using the JDBC source connector, which is shipped with the Confluent Platform or available separately from the Confluent Hub.
Configure and run the connector to connect to the database, read the customer information and produce data into a new Kafka topic customers. As new customers are added to the database, the connector automatically produces that new customer data to the Kafka topic.
As the JDBC source connector pulls the customer information into a Kafka topic, all the customer information becomes available to any streaming application. The application creates a table from it with a unique entry per customer ID. The following code snippet builds a GlobalKTable, versus just a table, to populate with data from all partitions of the customers topic for each Kafka Streams instance, which makes the forthcoming join operation more efficient.
final GlobalKTable<Long, Customer> customers = builder.globalTable(customersTopicName);
At this point, the application has a stream of orders and a table of customers.

And now, to put it all together: Every order from a stream of orders is joined with the table of customers, with the customer ID as the key. Ultimately the service needs to route orders to an output topic derived from the customer loyalty level. Because the customer loyalty level is not part of the order itself—it is in the customer table—you need to enrich the order to add this field. So produce a stream of a new type of order called OrderEnriched, which now includes a field for customer loyalty level.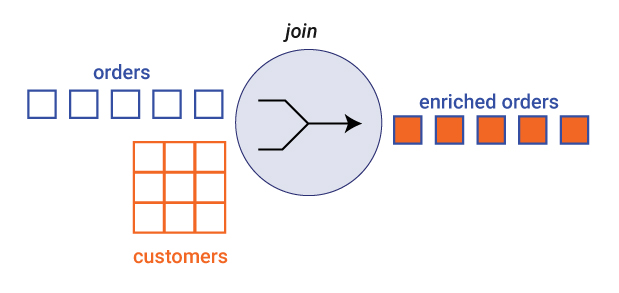
Finally, the stream of enriched orders can be dynamically routed to a Kafka topic derived from the customer loyalty level, which is extracted from the field in the stream of enriched orders.
// Enrich orders to include customer loyalty level
orders.join(customers,
(orderId, order) -> order.getCustomerId(),
(order, customer) -> new OrderEnriched (order.getId(),
order.getCustomerId(),
customer.getLevel()))
// Dynamically route the enriched order to an output topic
// whose name is the customer loyalty level
.to((orderId, orderEnriched, record) ->
orderEnriched.getCustomerLevel());As a result, there will be the original stream of events with all orders, as well as Kafka topics named by the customer loyalty level (e.g., platinum, gold, silver and bronze) containing only the subset of orders coming from customers who match the respective loyalty level.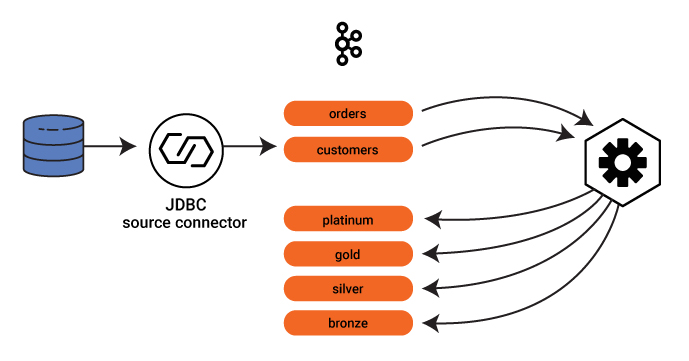
Summary
Kafka Streams is a powerful way to enrich data streaming through your event-driven architectures. You can dynamically route events to topics, even pulling in the output topic information from another end data system.
For a hands-on example of the dynamic routing feature and other cool Kafka Streams features, check out the streaming application development tutorial introduced in the blog post Getting Your Feet Wet with Stream Processing.
If you’d like to know more, you can download the Confluent Platform to get started with the leading distribution of Apache Kafka.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.



Confluent Deepens India Commitment With Major Expansion on Jio Cloud
Confluent Cloud is expanding on Jio Cloud in India. New features include Public and Private Link networking, the new Jio India Central region for multi-region resilience, and streamlined procurement via Azure Marketplace. These features empower Indian businesses with high-performance data streaming.