[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Sharpening your Stream Processing Skills with Kafka Tutorials
Event stream processing solves many business challenges, from big data ingestion and data integration, to real-time data processing and IoT. It gives you the ability to analyze big data streams in-motion as it’s generated, opening new use cases for organizations in every industry.
In the Apache Kafka® ecosystem, ksqlDB and Kafka Streams are two popular tools for building event streaming applications that are tightly integrated with Apache Kafka. While ksqlDB and Kafka Streams both provide solutions for building stream processing workloads, there are some key differences to be aware of.
Kafka Streams is a Java virtual machine (JVM) client library for building event streaming applications on top of Kafka. The library allows developers to build elastic and fault-tolerant stream processing applications with the full power of any JVM-based language.
ksqlDB is an event streaming database built on top of Kafka Streams that provides a high-level SQL syntax, which can build streams and tables, create and serve materialized views, and manage Kafka connectors without having to worry about traditional application management concerns.
My colleague Dani Traphagen published Kafka Streams and ksqlDB Compared – How to Choose, which gives a nice overview of these technologies and some basic guidelines for deciding which to use. The decision often boils down to trade-offs between control and simplicity.
We can visualize these stream processing technologies as a hierarchy of layers.
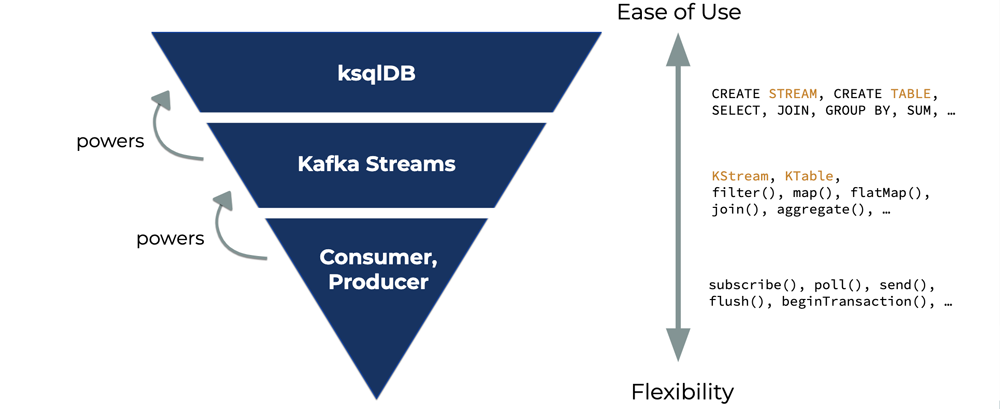
- Standard Kafka clients (the consumer and producer) are at the bottom, providing the most control and low-level access to Kafka
- In the middle sits Kafka Streams, which provides two event streaming APIs (the Streams DSL and Processor API) that trade off between syntax and control
- At the top is ksqlDB, providing the highest level of abstraction, most concise syntax (SQL), and built-in stream processing management
ksqlDB is robust in terms of the stream processing applications and pipelines that it can power, but there may be times when you need an alternative route. This is where you might drop down into the Kafka Streams DSL layer. Some examples of capabilities not yet available in ksqlDB but that are in Kafka Streams include:
In more advanced use cases where the Kafka Streams DSL alone won’t suffice, you might find yourself reaching for the Processor API. You may find a need for custom state management, access to the Kafka record’s metadata, custom functions not yet in the DSL, and explicit control over if/when to forward output records to downstream Kafka topics.
A good strategy for deciding which layer your stream processing application lands on may be to start at the top of the hierarchy with ksqlDB, and work down through the layers driven by the functional requirements. Using the Kafka Tutorials website as a guide, we’ll walk through an example to see how this looks in practice.
Learning stream processing with Kafka Tutorials
Kafka Tutorials is a site where you can learn about various aspects of building applications with Kafka.

They are curated, complete, and functional examples of stream processing patterns. Each tutorial provides the necessary code and configuration to bring up a functioning platform and try out a step-by-step tutorial. Kafka Tutorials is open for anyone to submit content, and you can sign up for notifications as new tutorials are published.
Let’s investigate a stream processing use case and evaluate the technology options for implementing it, using Kafka Tutorials as our guide along the way.
Event streaming use case: Rekeying events
We’re going to look deeper at a particular use case in stream processing: rekeying a stream of records from an existing record value and publishing to a new stream. Let’s initially examine why you would want to rekey records, and then we’ll follow with examples in ksqlDB as well as Kafka Streams.
![]()
Kafka record keys are used in different, albeit related ways. Partitions are the unit of parallelism in Kafka, and producing records to multiple partitions increases potential throughput. By default, when a producer publishes a new record without specifying a partition, the record’s key is used to determine the target partition. Also important to note is that when records are rekeyed, they are also repartitioned. This potentially changes the ordering of records during input as they are written to the output stream.
In addition, keys matter if you want to model the stream of events as a table. There are a wealth of materials for further studying the concept of stream-table duality.
![]()
Related to the stream-table duality are log-compacted topics, which use keys to retain the last observed record for a given key. This enables previous records to be deleted and, thus, compaction can occur.
Typically, you’re looking to use keys in stream processing so that you can perform aggregations on your data across various attributes. Let’s look at how we can accomplish this with ksqlDB and Kafka Streams.
Rekeying events with ksqlDB
Let’s take a closer look at the Kafka Tutorial for this task.
A ksqlDB stream is an unbounded sequence of events, backed by a Kafka topic and associated with a schema. This tutorial leads you through creating a sample stream (ratings) that we can use as input for our rekey use case. ksqlDB allows you to create a stream with its schema and a backing topic in a single command, as shown here:
CREATE STREAM ratings
(id INT, rating DOUBLE)
WITH (kafka_topic='ratings',
partitions=2, value_format='avro');
Message
----------------
Stream created
----------------
In the above example, the schema is defined in the field definition portion of the command (id INT, rating DOUBLE), and the remaining configuration is in the WITH clause.
Inserting data into our new stream is equally trivial with the ksqlDB command line:
INSERT INTO ratings (id, rating) VALUES (294, 8.2); INSERT INTO ratings (id, rating) VALUES (294, 8.5); ...
So far, we’ve created the stream ratings with no key, so the resulting records will have null values in the Kafka record key field as shown below:
ksql> SELECT ROWKEY, ID, RATING >FROM RATINGS >EMIT CHANGES >LIMIT 9; +----------+----------+----------+ |ROWKEY |ID |RATING | +----------+----------+----------+ |null |294 |8.5 | |null |294 |8.2 | ... |null |782 |7.7 | |null |780 |2.1 | Limit Reached Query terminated ksql>
Now let’s implement our rekeying use case by creating a new stream with the id field as the key and leaving the value of the event unchanged:
CREATE STREAM RATINGS_REKEYED
WITH (KAFKA_TOPIC='ratings_keyed_by_id') AS
SELECT *
FROM RATINGS
PARTITION BY ID;
Message
----------------------------------------------
Created query with ID CSAS_RATINGS_REKEYED_0
----------------------------------------------
The new and interesting portions of this command are after the AS operator. SELECT * instructs ksqlDB to infer the schema from our input stream and copy the record values exactly from RATINGS into RATINGS_REKEYED. The PARTITION BY ID clause instructs ksqlDB to rekey our records by the field ID from the RATINGS stream.
Here, we can see our new stream rekeyed with the rating ID field:
ksql> SELECT ROWKEY, ID, RATING >FROM RATINGS_REKEYED >EMIT CHANGES >LIMIT 9; > +----------+----------+-----------+ |ROWKEY |ID |RATING | +----------+----------+-----------+ |294 |294 |8.2 | |354 |354 |9.9 | ... |782 |782 |7.7 | |780 |780 |2.1 | Limit Reached Query terminated
The tutorial concludes with instructions on how to take the solution to production. In just a few steps, we now have a complete solution for a common stream processing use case. We can achieve his same use case using Kafka Streams and Kafka Connect.
Rekeying events with Kafka Streams
In the ksqlDB tutorial above, data is sourced manually by the user who executes INSERT statements to simulate data. This works fine for a simple tutorial, but a more realistic scenario is sourcing data from external systems into Kafka to feed stream processing applications. The Kafka Streams example that we will examine pairs the Kafka Streams DSL with Kafka Connect to showcase sourcing data from a database with stream processing in Java.
Note: ksqlDB supports Kafka Connect management directly using SQL-like syntax to create, configure, and delete Kafka connectors.
With Kafka Streams, we have dropped down the processing hierarchy, and there are more technical concerns to deal with. ksqlDB handled the details of data formatting for us, freeing us from having to think about serializers, classes, and configurations. At the Kafka Streams level, we can use a full programming language at the cost of having to manage these details ourselves.
First, pull up the Kafka Streams with Kafka Connect tutorial to follow along.
Like the ksqlDB tutorial, the Kafka Streams with Kafka Connect tutorial uses Apache Avro™ for data formatting and the Confluent Schema Registry to manage schema definitions. Because we’re using the full Java language, we need to create objects, set up connections to Schema Registry, and consider serialization techniques.
The Kafka Streams tutorial shows how this is done with an Avro definition file (shown below). Defining a schema in this way is analogous to the field definition portion of the CREATE STREAM ksqlDB command shown previously.
{ "namespace": "io.confluent.developer.avro",
"type": "record", "name": "City",
"fields": [
{ "name": "city_id", "type": "long" },
{ "name": "name", "type": "string" },
{ "name": "state", "type": "string" }
]
}
When using Avro and Java together, you have a choice between three serialization/deserialization (SerDes) formats:
- Generic Avro SerDe
- Specific Avro SerDe
- Reflection-based SerDes (added in Confluent Platform 5.4)
Combining the Avro schema definition with the Avro SerDes allows Java developers to work with Kafka events cleanly and safely using standard Java features. However, there are notable differences between the SerDes. Here, we’re only going to focus on the Generic and Specific versions:
- Generic Avro SerDe: provides non-type-specific data functions (gets/sets with names and implied types). This offers a flexible mechanism for reading values at the cost of validity of types and fields being available.
- Example: String cityName = city.get("name").toString();
- Specific Avro SerDe: provides a direct-to-type SerDes, which allows you to specify the type and have the deserializer instantiate and populate the values of the instance automatically. This frees you from worrying about the validity (in type and name) of each field as they are read.
- Example: String cityName = city.Name;
The Kafka Streams tutorial utilizes the Specific Avro SerDe. In order to make this work properly with the Kafka connector, we have to instruct the connector to publish records with a class name and namespace that is coordinated with our Java code. In the tutorial, this is specified in the Kafka Connect JDBC source connector. The following highlights important configuration values, with specific attention on the transforms.SetValueSchema.schema.name value as it corresponds to the full class path for the City type generated from the Avro schema definition:
"value.converter": "io.confluent.connect.avro.AvroConverter", "transforms": "SetValueSchema", "transforms.SetValueSchema.type": "org.apache.kafka.connect.transforms.SetSchemaMetadata$Value", "transforms.SetValueSchema.schema.name": "io.confluent.developer.avro.City"
Below is the Java code that builds a stream topology that, when executed, consumes records from the inputTopic, rekeys the records using the cityId value, and publishes the new records to the outputTopic:
KStream<String, City> citiesNoKey = builder.stream(inputTopic, Consumed.with(Serdes.String(), citySerde)); final KStream<Long, City> citiesKeyed = citiesNoKey.map((k, v) -> new KeyValue<>(v.getCityId(), v)); citiesKeyed.to(outputTopic, Produced.with(Serdes.Long(), citySerde));
The map function is an example of a stateless transformation in the Kafka Streams DSL, and in this case, we’ve modified the record key but not the record value. This marks the stream for data repartitioning, and the subsequent to function writes the repartitioned stream back to Kafka in the new output-topic topic.
Summary
The Kafka Streams example helps us appreciate the heavy lifting that an event streaming database like ksqlDB can do for us. Additionally, it alleviates us from many ancillary concerns like dependencies and application deployments. In cases where it’s necessary to drop down the hierarchy and utilize the Kafka Streams library, you may still benefit from combining the technologies to accomplish your goals.
For some additional reading on stream processing pipelines and serialization techniques, check out our real-time streaming ETL pipeline blog post and SerDes white paper. The Confluent examples repository also has specific examples on tying stream processing and Kafka Connect together into pipelines.
Be sure to subscribe to updates on Kafka Tutorials and look out for future tutorials covering data integrations, various programming languages, and command-line tools.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Stop Treating Your LLM Like a Database
GenAI thrives on real-time contextual data: In a modern system, LLMs should be designed to engage, synthesize, and contribute, rather than to simply serve as queryable data stores.



Generative AI Meets Data Streaming (Part III) – Scaling AI in Real Time: Data Streaming and Event-Driven Architecture
In this final part of the blog series, we bring it all together by exploring data streaming platforms (DSPs), event-driven architecture (EDA), and real-time data processing to scale AI-powered solutions across your organization.