[Live Demo] Tableflow, Freight Clusters, Flink AI Features | Register Now
Introducing Confluent Platform 7.2: Enhanced Cloud-Native Security and Geo-Replication
We are pleased to announce the release of Confluent Platform 7.2. With this release, we are further simplifying management tasks for Apache Kafka® operators, providing even more flexible options to build globally available hybrid architectures, and boosting developer productivity.
Building on the innovative feature set delivered in previous releases, Confluent Platform 7.2 makes enhancements to three categories of features:
- Improve speed, security, and reliability while maintaining operational simplicity with increased DevOps automation through Confluent for Kubernetes 2.4
- Ensure globally consistent data while simplifying replication for org-wide data sharing and aggregation with flexible topic naming for Cluster Linking
- Accelerate the development of stream processing pipelines with ksqlDB 0.26 improvements to aggregate functions, RIGHT joins, and JSON support
In this blog post, we’ll explore each of these enhancements in detail, taking a deeper dive into the major feature updates and benefits. As with previous Confluent Platform releases, you can always find more details about the features in the release notes.
Keep reading to get an overview of what’s included in Confluent Platform 7.2, or download Confluent Platform now if you’re ready to get started.
Download Confluent Platform 7.2
Confluent Platform 7.2 at a glance
Confluent Platform 7.2 comes with several enhancements to existing features, bringing more of the cloud-native experience of Confluent Cloud to your self-managed environments, enabling data streaming everywhere, and bolstering the platform with a complete feature set to implement mission-critical use cases end-to-end. Here are some highlights:
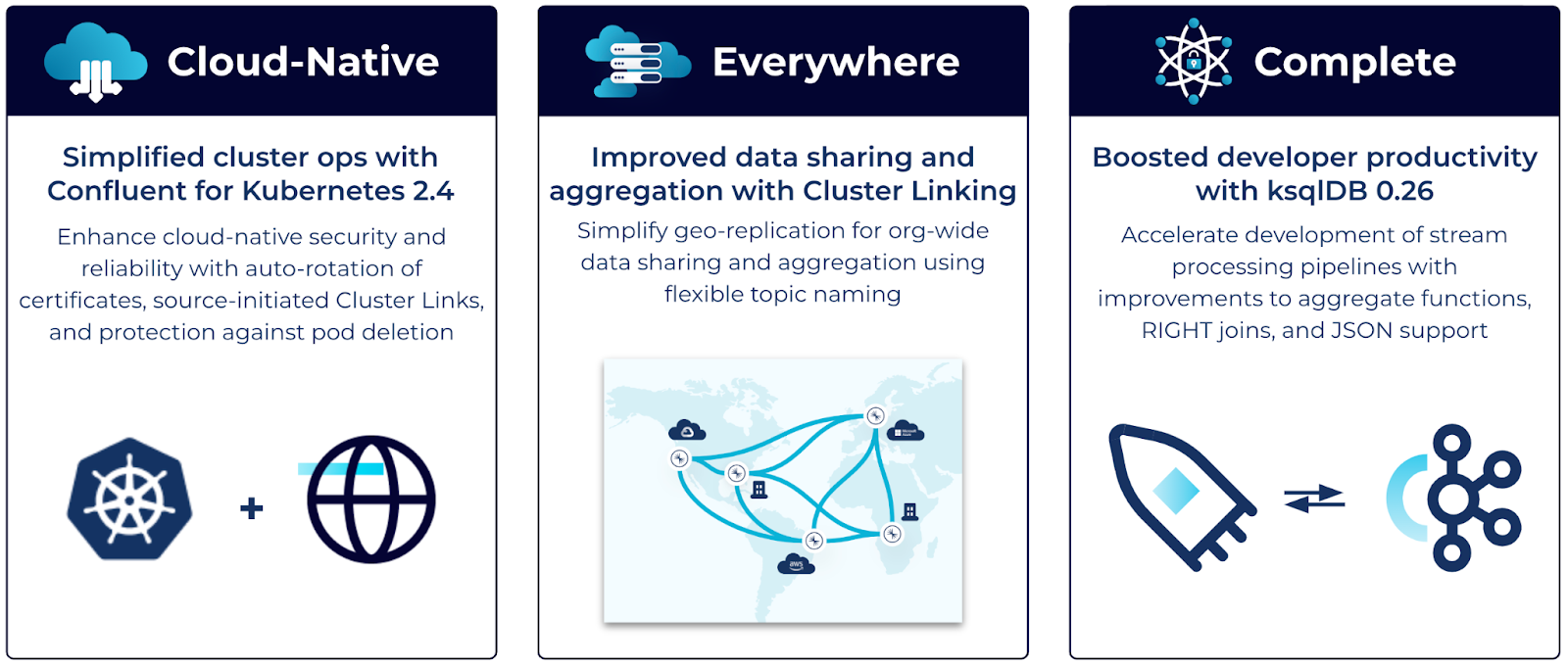
Confluent Platform 7.2 reinforces our key product pillars
Confluent for Kubernetes 2.4 for secure streaming across hybrid environments
In Confluent for Kubernetes 2.2, we introduced cloud-native management of cluster links, which enabled you to declaratively define a real-time bridge between environments in a secure and reliable way. However, migrating data between Confluent Platform and Confluent Cloud still required opening up your private infrastructure firewall to let Confluent Cloud connect directly to Confluent Platform.
In the latest release, Confluent for Kubernetes supports source-initiated links that can be instantiated and managed through a simple declarative API. Creating cluster links that originate from the source cluster means that you can migrate to cloud or build a bidirectional hybrid cloud data backbone without opening up firewalls to the cloud or storing your on-prem security credentials in the cloud. This eases the information security review process and improves delivery time for hybrid cloud workloads and on-prem to cloud migrations. Source-initiated links can also be used to connect to Confluent Cloud clusters using VPC Peering and Privatelink networking.
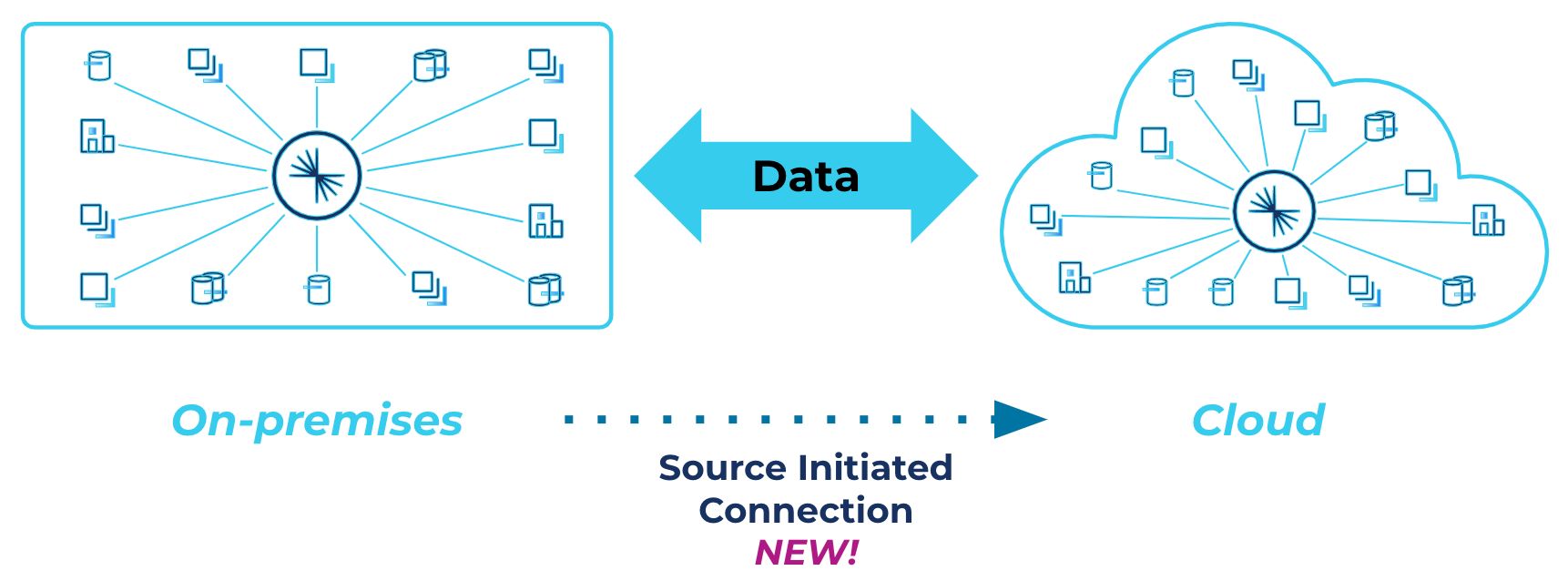
Source-initiated links ensure secure data migration and replication across Kubernetes deployments
In addition to source-initiated cluster links, we’re enhancing Confluent for Kubernetes for complete network encryption with automated certificate management. Certificate-based authentication makes sure only approved users, applications, machines, and endpoints have access to system resources. It relies on a Certificate Authority (CA) to validate identities and issue certificates. As a best practice, certificates should be rotated periodically to ensure optimal security. However, doing this manually can be error prone and operationally burdensome.
To address this challenge, Confluent for Kubernetes now automates provisioning, securing, and operating certificates for internal networking communications. This enables a fully encrypted streaming platform without you needing to manage all these certificates. Now we provide automated rotation of these certificates at a period that you define. You can bring your own certificate authority that you want to use, and Confluent for Kubernetes automates the rest to fit your security requirements.
Lastly, we’re introducing support for Admission Controllers to prevent the deletion of critical Kafka resources and maintain Kafka health. One of the benefits of Confluent for Kubernetes is the ability to leverage Kubernetes-native resource management, using the Kubernetes scheduler to automate scaling up or down for efficient resource utilization and pod placement. Nevertheless, there are some critical Kubernetes resources that should not be subject to pod deletion—these should be left to the Confluent for Kubernetes operator.
Using Admission Controllers allows us to intercept configuration and Kubernetes resource change requests and prevent them if they represent a danger to Kafka health. This enhances system reliability and uptime for users who are running production Kafka use cases on Kubernetes.
Flexible Topic Naming for Cluster Linking to boost data sharing and aggregation
In Confluent Platform 7.0, we announced the general availability of Cluster Linking, which enables you to easily link clusters together to form a highly available, consistent, and real-time bridge between on-prem and cloud environments and provide teams with self-service access to data wherever it resides.
Customers with many site clusters often replicate data from two or more source clusters to the same destination cluster using Cluster Linking. However, if the site clusters had topics with the same name(s), a problem would ensue: Kafka doesn’t support topic renaming, and Cluster Linking had required every mirror topic’s name to match its source topic’s name. This created topic name conflicts, which were cumbersome to work around and sometimes became hard blockers.
In Confluent Platform 7.2, flexible topic naming for Cluster Linking further simplifies the setup of common hybrid and multi-cloud use cases, including organizational data sharing, data aggregation, or even a multi-region active-active deployment. Now, a prefix denoting the source cluster can be added to the cluster link, and its mirror topics will be named with that prefix. Topics from different source clusters can be configured with different prefixes so at the destination cluster they have different names (e.g, “us.orders” vs. “apac.orders”) to avoid conflicts and ease identification.
Here are some example use cases of mirror topic prefixes in action:
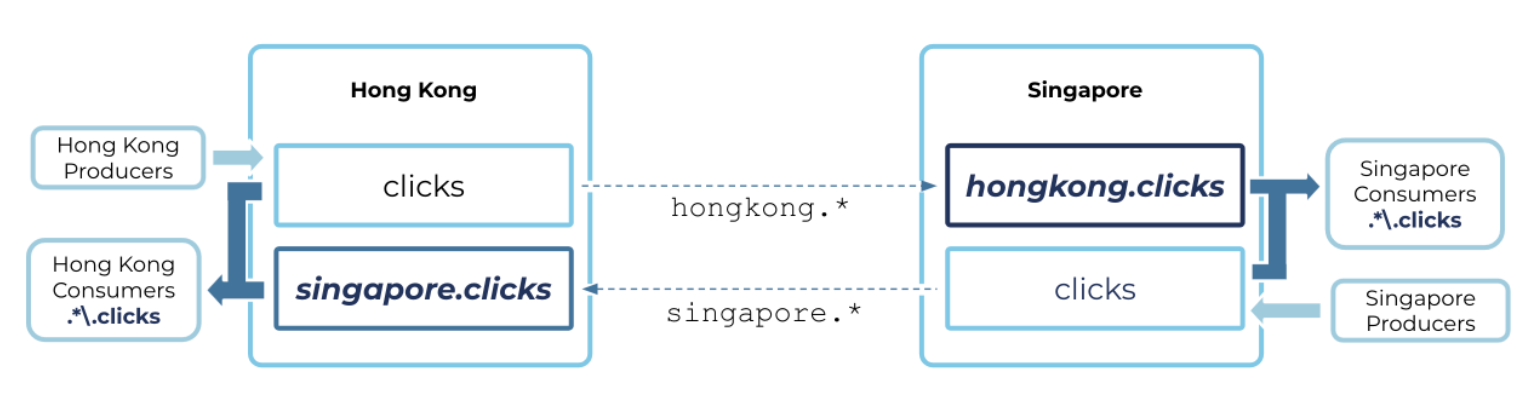
Example of an active-active pattern using mirror topic prefixing
In the active-active pattern, both clusters had a writeable topic called “clicks.” Flexible topic naming enables all producers to use the same topic name string on both clusters and still create a real-time, persistent bridge using Cluster Linking. Likewise, consumers can consume from the same regex pattern on both clusters. This makes it easier to deploy producers and consumers and to fail them over from one cluster to the other.
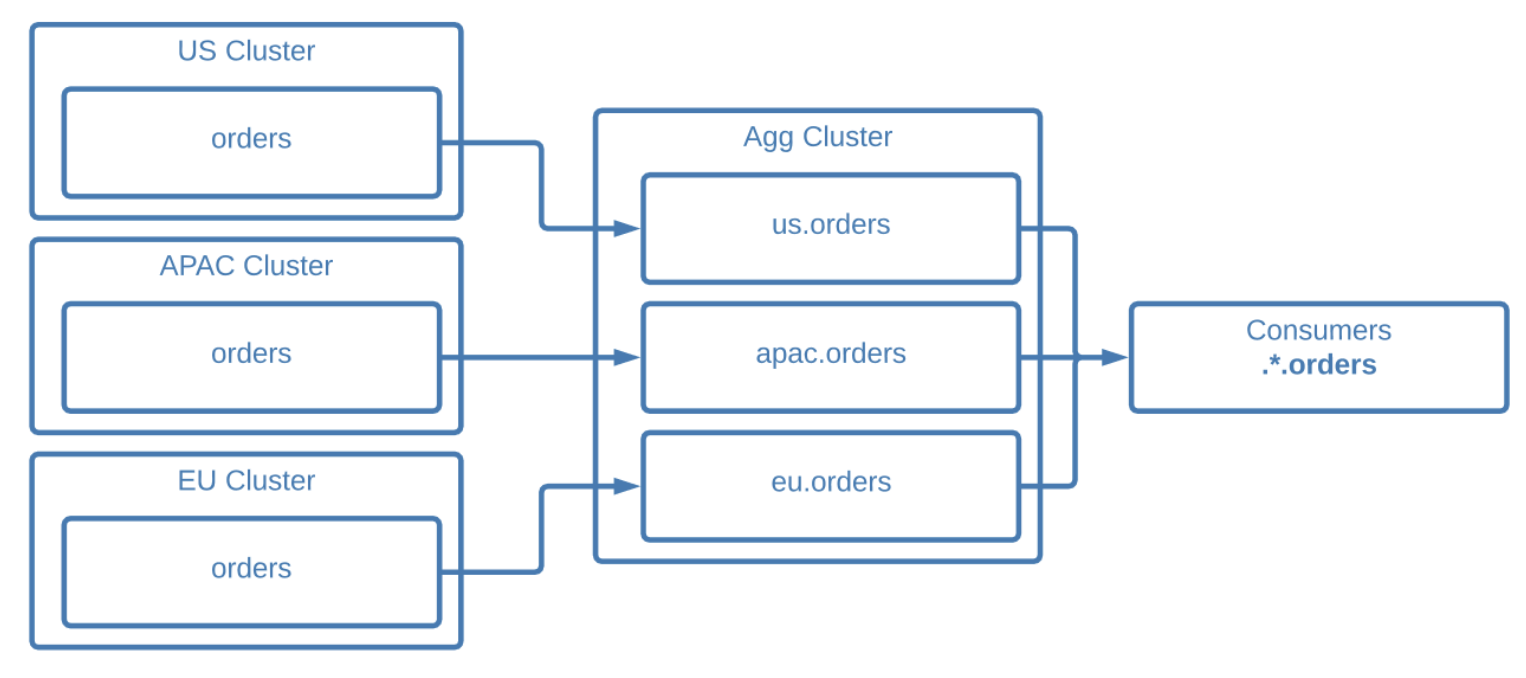
Example of aggregating from identical source clusters using mirror topic prefixing
In the case of data aggregation, edge clusters can all use the same topic names without conflicting on the aggregate cluster. Mirror topics from each edge cluster will be grouped under their source clusters’ names on the aggregate cluster.
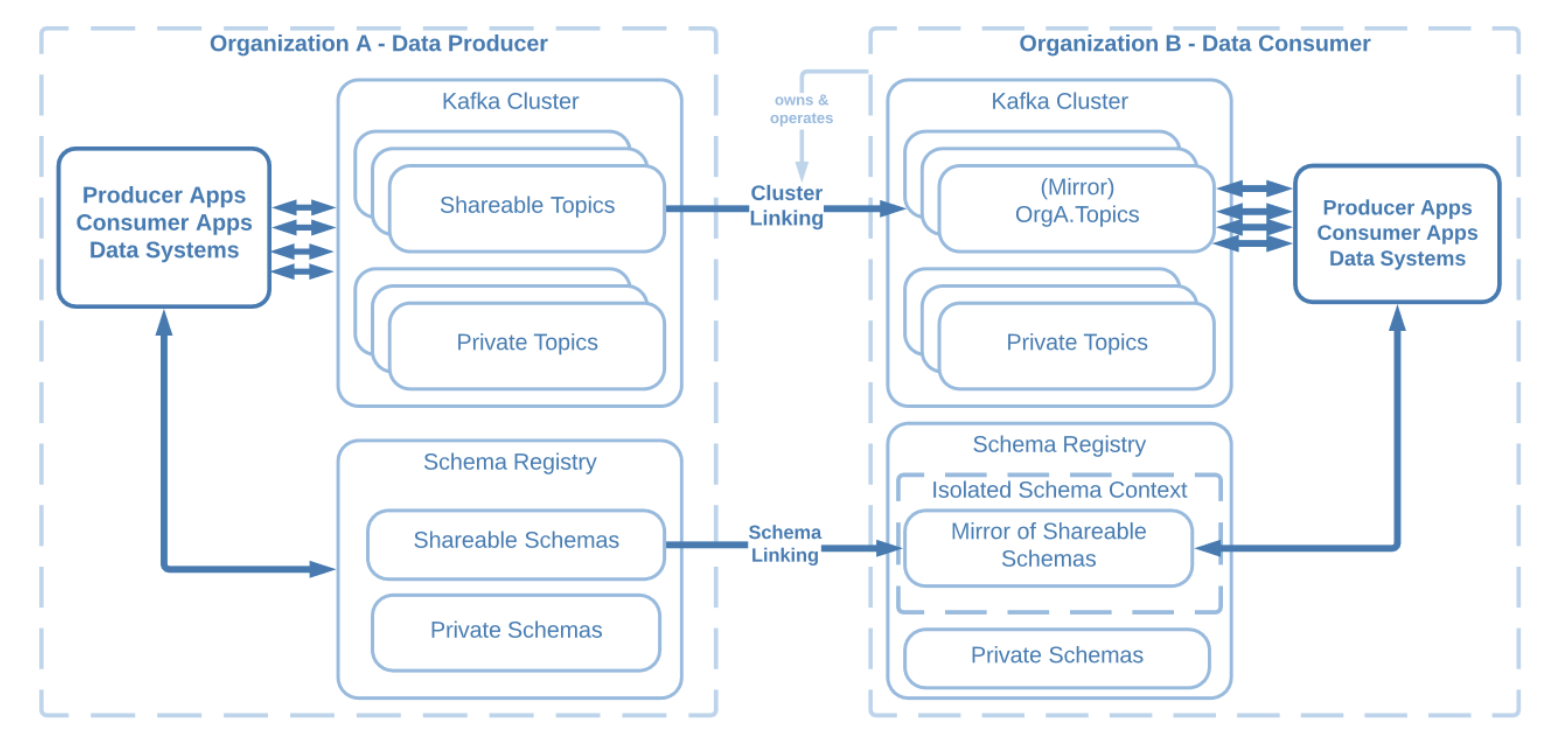
Example of inter-organization data sharing using mirror topic prefixing
When sharing data across orgs, flexible topic naming for Cluster Linking avoids any conflicts in topic names between the two organizations. You can group the mirror topics under a prefix on the destination cluster, making it easier to identify shared topics and assign prefix-scoped roles in Role-Based Access Control to ensure the right access to topics across all of your clusters.
In summary, flexible topic naming using mirror topic prefixes significantly opens up the architectural patterns you can create with Cluster Linking.
ksqlDB 0.26 to accelerate streaming pipeline development
Confluent Platform 7.2 also comes with ksqlDB 0.26, which includes several new enhancements that improve the developer experience and make it easier to build real-time applications.
The first enhancement is for aggregate functions, which offer powerful ways to transform a grouped column into a new value. Previously, commonly used aggregate functions worked only with primitive data types, constraining their applicability or requiring workarounds like casting the complex types into supported primitive types.
In ksqlDB 0.26, popular aggregate functions, such as COLLECT_LIST and EARLIEST_BY_OFFSET, support complex data types such Structs and Arrays, enabling developers to use these useful functions without the burden of extra casting or other workarounds.

Aggregate functions now also support complex types
Another enhancement in this latest release is the support for RIGHT JOINs for stream-stream and table-table-joins. As the logical inverse to LEFT joins, RIGHT joins select all records from the right-hand stream/table and the matched records from the left-hand stream/table.
Previously, only LEFT joins were supported which meant that users would have to re-order the join clause to get the proper inclusion of matched rows in the combined result. This could disrupt the mental model of the query and limits developer flexibility. RIGHT joins provide additional flexibility while simplifying the syntax to improve the readability of complex queries, which makes working with queries written by other developers easier.
SELECT m.id, m.title, m.release_year, l.actor_name FROM lead_actor l RIGHT JOIN movies m ON l.title = m.title EMIT CHANGES LIMIT 3;
RIGHT joins improve syntax and readability
Finally, ksqlDB 0.26 also includes support for new JSON functions. Many ksqlDB users work with JSON-formatted data. For example, stream processing pipelines often process large JSON blobs from MongoDB or aggregate analytics events produced to Kafka as JSON. This new set of functions makes it easier to integrate ksqlDB with JSON-formatted data sources, resulting in fewer steps for developers to build stream processing pipelines.
Here are a few of the functions available:
- IS_JSON_STRING checks whether the supplied string is valid JSON
- JSON_CONCAT merges two or more JSON structures
- JSON_RECORDS extracts key-value pairs from a string representing a JSON object
- JSON_KEYS extracts an array of keys from a string representing a JSON object
- JSON_ARRAY_LENGTH computes the length of the array encoded as JSON string
- TO_JSON_STRING converts any ksqlDB data type into a JSON string
Support for Apache Kafka 3.2
Following the standard for every Confluent release, Confluent Platform 7.2 is built on the most recent version of Apache Kafka, in this case, version 3.2. This version simplifies the security architecture by introducing a Kraft-based authorizer (KIP-801) that does not depend on Zookeeper in preparation for future Zookeeper removal. In addition, it enhances resiliency with rack awareness for Kafka Streams to improve fault tolerance in case of the failure of an entire rack (KIP-708).
For more details about Apache Kafka 3.2, please read the blog post by Bruno Cadonna or check out the video by Danica Fine below.
Get started today
Download Confluent Platform 7.2 today to get started with the only cloud-native and complete platform for data in motion, built by the original creators of Apache Kafka.
The preceding outlines our general product direction and is not a commitment to deliver any material, code, or functionality. The development, release, timing, and pricing of any features or functionality described may change. Customers should make their purchase decisions based upon services, features, and functions that are currently available.
Confluent and associated marks are trademarks or registered trademarks of Confluent, Inc.
Apache® and Apache Kafka® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks. All other trademarks are the property of their respective owners.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...