[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Introducing Confluent Hub
Today we’re delighted to announce the launch of Confluent Hub. Confluent Hub is a place for the Apache Kafka and Confluent Platform community to come together and share the components the community needs to build better streaming data pipelines and event-driven applications. Of course, “component” can mean a lot of things, so we should be more specific. Confluent Hub includes three kinds of components, all related to the all-important Kafka Connect:
- Connectors for Kafka Connect
- Transformations for Kafka Connect
- Converters for Kafka Connect
Before Confluent Hub
Connect has been an integral part of Apache Kafka since version 0.9, released late 2015. It has proved to be an effective framework for streaming data in and out of Kafka from nearby systems like relational databases, Amazon S3, HDFS clusters, and even nonstandard legacy systems that typically show themselves in the enterprise. Connect is an API on which the connectors themselves are built, plus a run-time framework that runs them in a scalable, fault-tolerant way. The intent was for the community to provide its own connectors to plug into this framework and do the work of data integration while saving everyone a bunch of unrewarding coding that was near-boilerplate and didn’t add a lot of differentiated value to the business.
So where would those connectors live? Well, GitHub, for starters. At the time of this writing, there were 660 repositories matching the search phrase “Kafka Connect” on the popular hosting service, all in various stages of repair and levels of maintenance. Beyond those, Confluent’s popular Connectors page has proven to be one of the best ways to find connectors, some of which are supported by Confluent, and others of which have robust community support behind them. The Connectors page lists for each entry the type of connector, the developer, a few tags, and how you could obtain the code—but that’s really all it did. You still had to go find the released JARs for the connector, download them, and know how to install them properly. And if there were no released JARs available, you had to clone the repository, figure out how to run the build, and then install the JARs into your own Kafka Connect installation. Maybe not rocket science, but we all know it’s never as simple as it sounds. And besides, this was just connectors—no transformations or converters were available on this page.
We knew there was a better way. We wanted something that was easier to use, would avoid you having to building a connector from source every time you wanted an update (and learning a new build tool every now and then), and would be built on top of a meaningful and functional discovery mechanism. And most importantly, we wanted to avoid the pitfalls of manually moving JARs around and having to debug why Connect didn’t find them.
Introducing Confluent Hub: the App Store for Kafka
Confluent Hub is an online service for finding, reviewing, and downloading extensions for the Apache Kafka and Confluent Platform ecosystems. It highlights features, richer component descriptions, links to external resources for the components, and installation and support information. Starting today, Confluent Hub has Kafka Connect connectors, transformations, and converters, but we also look forward to distributing consumer and producer interceptors, partitioners, security extensions, and more.
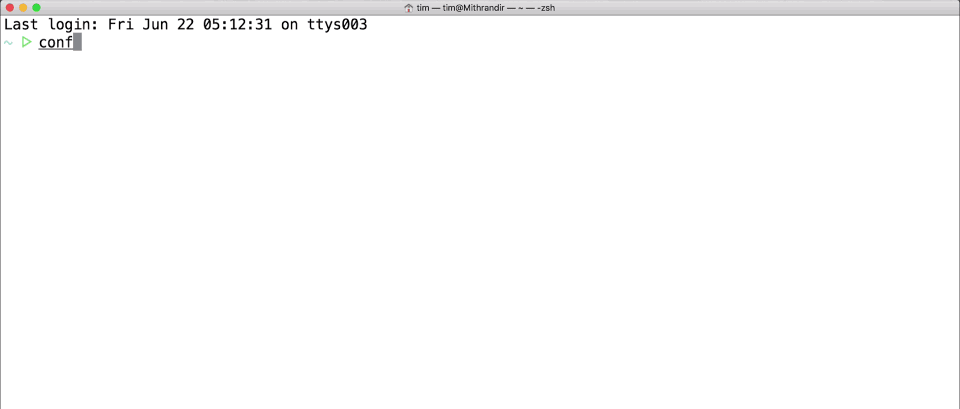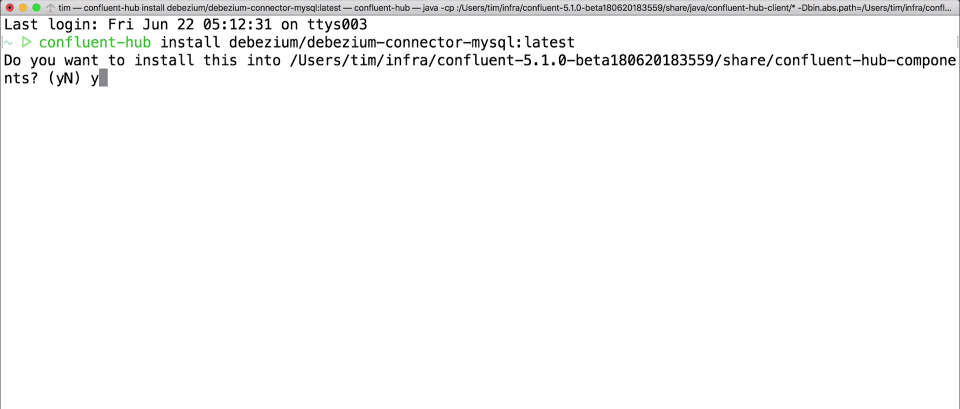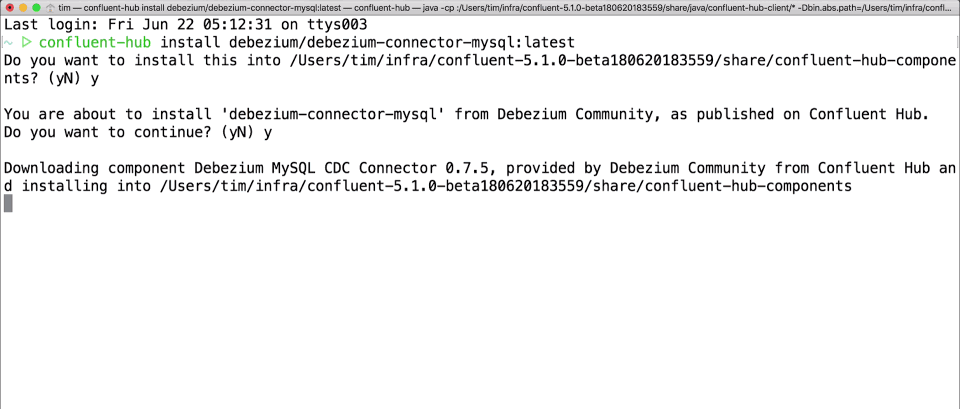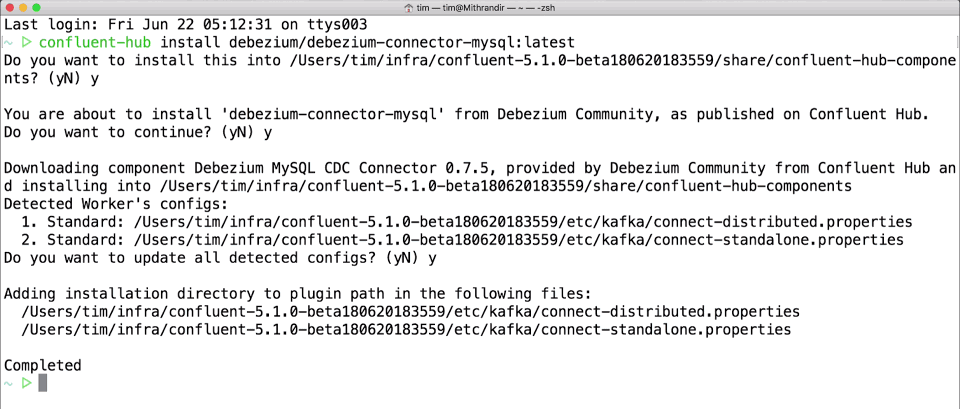
And because installing connectors has always been a bit of a pain, we’re also launching a new Confluent Hub client tool that will make it downright trivial to install any Confluent Hub component into your Confluent Platform deployment. For example, to install the latest Debezium MySQL source connector, run the following command in your Confluent Platform installation:
$ confluent-hub install debezium/debezium-connector-mysql:latest
This may prompt you to verify that you want to install the component and what changes to the installation you might want to make. But it’s pretty simple. You can specify a specific version, add the --dry-run option to just see what it will do, or even use other options to script automated installations.
The Confluent Hub client comes with Confluent Platform starting with the CP 5.0.0-beta2, or you can install it separately, and you’ll soon be able to install components into older Confluent Platform installations.
Confluent Hub is open for all to use and contribute to. See later in this blog for details of how you can get involved.
Let’s take a look at some of the components available in Confluent Hub. At present, these are all focused on Kafka Connect. You can dive a bit more deeply into Kafka Connect here, and see it in action in this series of posts describing The Simplest Useful Kafka Connect Data Pipeline In The World … or Thereabouts in Part 1, Part 2, and Part 3.
Connectors for Kafka Connect
Confluent Platform ships with connectors for S3, HDFS, Elasticsearch, IBM MQ, and connectivity to all databases through JDBC. But perhaps you’re running Apache Kafka already and just want one of these connectors without downloading the whole Confluent Platform. Or maybe you want to take advantage of the dozens of community-written connectors that are out there. Previously you would have had to download the source files, crack out Maven, Gradle, or even SBT, and build the connector yourself. And while everyone we like to hang out with loves a bit of mvn clean package -DskipTests, now you can save some time and build-wrangling by getting the pre-built connector from Confluent Hub directly.
Using Confluent Hub, obtaining connectors is straightforward. Simply locate the connector that you want, and click download! Confluent Hub has an intuitive design and search capability which enables you to easily find the connector that you want for the system from which you want to stream data into Kafka, or into which you want to stream data from Kafka.

Extract the resulting ZIP file into a directory on your Kafka Connect’s plugin.path and off you go. Streaming integration ahoy!
Transformations for Kafka Connect
The Kafka Connect API includes Single Message Transforms (SMT). These are powerful options available to include in the pipeline that you build with Kafka Connect, and enable you to modify messages as they pass through Kafka Connect. This might be as data arrives through Kafka Connect from a source system, doing things such as changing the partition key, dropping fields, changing data types, or adding in lineage information. The important thing is that these are applied by Kafka Connect before the data is send to Kafka. SMT work at the other end of the pipeline too, and are available to modify data as it comes out of Kafka and before it’s sent to the target system. Here, functions such as modifying the target topic based on timestamp or a regular expression are useful.
Apache Kafka and Confluent Platform ship with a dozen transforms already, but there’s always room for more! You can find additional transformations on Confluent Hub:

Extract the resulting ZIP file into a directory on your Kafka Connect’s plugin.path and off you go. Transformers are go!
Converters for Kafka Connect
Kafka Connect is a comprehensive streaming integration solution, and as such it attends to the serialisation and deserialisation of data as it passes between external systems and Kafka. It does this using components called Converters. Within the Confluent Platform the standard formats are usually Avro or JSON. (String and ByteArray are also available.)
For other Converters, including ProtoBuf, check out Confluent Hub:
Extract the resulting ZIP file into a directory on your Kafka Connect’s plugin.path and off you go.
Verified Integrations on Confluent Hub
Confluent’s technology partners provide high-quality integrations between their systems and Apache Kafka. These integrations may use Kafka Connect, or just the Producer/Consumer APIs. Either way, they go through a verification process from Confluent which confirm that Confluent has invested in inspecting and reviewing the quality of code, documentation, functionality, and level of support readiness of that component.
Verified Integration is only available to technology partners of Confluent, as it also includes mandatory support from the partner.
Confluent Hub: Want to Contribute?
Confluent Hub welcomes submissions from all developers of components within the Apache Kafka and Confluent Platform ecosystems. If you created a connector, a transformation, a converter or perhaps something totally different that implements one of the many pluggable APIs, let the community know! Together, we can be more productive.
To get involved, check out the Instructions for Plugin Contribution. If you have questions or suggestions, please do get in touch with us through the #confluent-hub channel on our Community Slack group.
We welcome you to the Confluent Hub.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Confluent Cloud for Government Is Now FedRAMP Ready
Confluent achieves FedRAMP Ready status for its Confluent Cloud for Government offering, marking an essential milestone in providing secure data streaming services to government agencies, and showing a commitment to rigorous security standards. This certification marks a key step towards full...


Bridging the Data Divide: How Confluent and Databricks Are Unlocking Real-Time AI
An expanded partnership between Confluent and Databricks will dramatically simplify the integration between analytical and operational systems, so enterprises spend less time fussing over siloed data and governance and more time creating value for their customers.