[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
A Guide to the Confluent Verified Integrations Program
When it comes to writing a connector, there are two things you need to know how to do: how to write the code itself, and helping the world know about your new connector. This post specifically outlines the process by which we verify partner integrations, and is a means of letting the world know about our partner’s contributions to our connector ecosystem. It points to best practices for anyone writing Kafka Connect connectors.
Recently, Confluent introduced a revised Verified Integrations Program to support the goal of supplementing connectors provided by Confluent with high-quality and well-vetted integrations from partners. As part of this initiative, we’ve simplified our verification requirements, streamlined our verification process, and updated our partner-facing documentation, making it easier and faster for software vendors and partners to build connectors. Because our partners know how to interface with their products best, we actually prefer it when partners offer connectors to our platform and will always prioritize partner-sourced connectors.
Simplified verification requirements
The verification program still has two tiers: Gold and Standard. Gold verifications indicate the tightest integration with Confluent Platform, whereas Standard verifications are functional and practical.
The Verification Guide for Confluent Platform Integrations describes the requirements that must be met for verification under the earlier vision of the program. In a nutshell, the document states that sources and sinks are verified as Gold if they’re functionally equivalent to Kafka Connect connectors. They’re granted Standard verification as long as the integration can produce or consume Avro in conjunction with Confluent Schema Registry. The idea here was to motivate partners to write their sources and sinks with the Kafka Connect API instead of the consumer/producer APIs, while still making room for developers building consumers and producers to meet the Gold status.
Over the years, we’ve since seen wide adoption of Kafka Connect. We’ve also observed that every partner integration not using Kafka Connect did not meet the criteria for Gold verification, while every partner integration using Kafka Connect did. Partner interest in integrating with other aspects of the Confluent Platform besides sources and sinks has grown as well. Thus, we’ve simplified our verification requirements and added a simple classification model. The classification model is as follows:
- Sources and sinks: integrations that read or write data to Kafka topics
- Stream processors: integrations that process data in Kafka via KSQL, Kafka Streams, or something else
- Platforms: deployment environments, storage infrastructure, hardware appliances, and so on
- Complementary: Systems that might not directly touch the Confluent Platform but interact with it in some way, such as application performance monitoring solutions, visualization engines commonly used with Kafka, and so on
For each classification, there could be integrations that qualify as both Standard and Gold with respect to the Confluent Platform. Currently, our priority is sources and sinks, but partners will integrate with Confluent in other ways in the future.
In line with our commitment to fostering a broad catalog of sources and sinks, we’ve greatly simplified the criteria. Partners who build sources and sinks using the Kafka Connect API qualify for Gold verification, and any other integrations are granted Standard for now. While it’s still possible to obtain Gold verification by following the practices detailed in the Verification Guide for Confluent Integrations, no partners actually do this since it’s so much easier to just go with Kafka Connect. The tight integration with Confluent Platform almost comes by default with Kafka Connect. Connectors provide integration with Confluent Schema Registry, Single Message Transforms, Confluent Control Center, and soon Confluent Cloud.
Building a connector with Kafka Connect
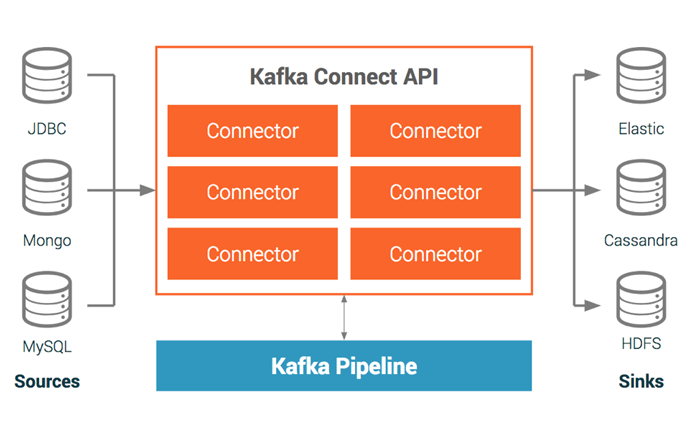
By encouraging partners to standardize on Kafka Connect for sources and sinks, we’re offering our customers the following benefits:
- Reusability: With a robust ecosystem of connectors to choose from, developers don’t need to concern themselves with reimplementing access to third party systems
- Standardization of data in Kafka regardless of source and target: Data that comes in via Kafka Connect can leverage converters and transforms in order to uniformly serialize data and enforce schema
- Easier integration with Confluent Platform
- Established best practices for development and deployment, as articulated in the new verification guide, described below
- A configuration-based turnkey deployment framework for loading data into Apache Kafka
- A single marketplace of supported connectors for the entire ecosystem: Confluent Hub
In addition, many helpful resources on Kafka Connect exist today.
This classic blog series provides a great end-to-end example of using Kafka Connect for those who are new to it. Once you’re convinced, you can have a look at the Kafka Connect development guide for an overview on how to get started, as well as see completed open source connectors for Amazon S3, HDFS, or Elasticsearch for examples of completed connectors.
Verification process for integrations
Making the process easy and straightforward for partners while at the same time ensuring that customers receive quality at completion is extremely important. This is why we’ve developed the following process:
- Initiated: A simple discussion with Confluent where we identify the integration and discuss the development process
- Guided: The development effort itself, where Confluent resources are made available to the partner for Q&A, process support, testing/development, and so on
- Submitted: The integration has been submitted to Confluent for review
- Verified: Confluent has concluded verification and produces a verification document which details the results of Confluent’s testing and the degree to which the connector adheres to the best practices detailed in the Verification Guide.
- Published: The integration has been uploaded to the Confluent Hub
Updated development and verification documentation
If you’re building a Kafka Connect connector, you can refer to the verification guide and checklist to get started with the program. The verification guide goes into detail about what’s absolutely required for verification and covers common practices around the development and testing of connectors. This documentation is brand new and represents some of the most informative, developer-centric documentation on writing a connector to date. The checklist shows how to put together a verification package for Confluent and provides a template for how it will be evaluated. Since the program is still young, these guides are subject to revision over time.
Showcase partners
A number of partners have already verified their work through this program and shared end-to-end examples of how to use them.
For example, you can load data from Kafka into Snowflake using their Snowflake Connector for Kafka (sink) and directly access the connector itself. The Snowflake connector is available on the Confluent Hub.
The list goes on:
MongoDB also announced adoption of Kafka Connect via officially supported releases of connectors previously offered by the community. Feel free to read more about it in their blog post, check out the source code, and obtain the connector from the Confluent Hub. Once these source and sink connectors are generally available, we’ll be deprecating the Confluent-supported, Debezium, and community connectors currently hosted there.
Longtime partner Neo4J wrote a blog post about their connector (also on GitHub) and will be working closely with us to make sure their integration evolves in tandem with their solution.
Neo4j and Confluent share a customer base that is determined to push the boundaries of detecting data connections as interactions and events occur. Driven by customer need to realize more value from their streaming data, we have integrated Neo4j and Kafka both as a sink and source in a Confluent setup. As a result, Confluent and Neo4j customers will be able to power their financial fraud investigations, social media analyses, network & IT management use cases, and more with real-time graph analysis.
Philip Rathle, VP of Products, Neo4j
Couchbase developed a source and sink Gold connector to operationalize dataflows with Kafka, available on the Confluent Hub.
A verified Gold connector with Confluent Platform is important to our customers who want a validated and optimized way to enable operational dataflows to and from Couchbase, an enterprise-class NoSQL database, and Kafka. With the Kafka Connect API, we have a deeper level of integration with the Confluent Platform so together, our joint solution is truly enterprise ready for any application modernization or cloud-native application initiatives.
Anthony Farinha, Senior Director, Business Development, Couchbase
Kinetica develops an in-memory database accelerated by GPUs that can simultaneously ingest, analyze, and visualize event streaming data. There is a GitHub repo, and their connector is available on the Confluent Hub.
Customers want to ingest data streams in real time from Apache Kafka into Kinetica for immediate action and analysis. Because the Confluent Platform adds significant value for enterprises, we built out the Kinetica connector using Connect APIs, offering a deeper level of integration with the Confluent Platform.
Irina Farooq, CPO, Kinetica
The DataStax Apache Kafka Connector offers customers high-throughput rates to their database products built on Cassandra.
In collaboration with Confluent, we developed a verified Gold connector that enables our customers to achieve the highest throughput rates possible. It also enables highly secure, resilient, and flexible connections between DataStax database products built on Apache Cassandra™ and Confluent’s event streaming platform. We promised our joint enterprise customers a fully supported microservices-based application stack, and this partnership delivers on that promise.
Kathryn Erickson, Senior Director of Strategic Partnerships, DataStax
Furthermore, we’re looking forward to working more with Humio, which now offers a Kafka Connect interface that can be used to consume events directly into their platform via the HTTP Event Collector Endpoint (HEC). You can also obtain the Humio HEC sink from the Confluent Hub.
For a complete list of partner and Confluent supported connectors, see the Confluent Hub.
Join the Verified Integrations Program
Whether you’re using Kafka Connect or not, we can find a place for your integrations in our program. Once a partner achieves verified status with us, they become a part of an active and robust ecosystem, reassuring customers with full confidence that the joint integration is sound, supported, and backed by both Confluent and the partner. To get started on your connector, we invite you to reach out and ask questions, or join the program.
Learn more
A great place to learn more about the business and technical benefits of building a connector, as well as how to build a connector, is through our online talk.
If you like jumping right in, you can also visit the Confluent Hub and start trying out a variety of connectors for free.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...