[Virtual Event] GenAI Streamposium: Learn to Build & Scale Real-Time GenAI Apps | Register Now
Confluent Unlocks the Full Power of Event Streams with Stream Governance
Data governance initiatives aim to manage the availability, integrity, and security of data used across an organization. With the explosion in volume, variety, and velocity of data powering the modern enterprise, it’s no surprise that the management of that data has become paramount to the success of companies across the globe. Data governance is now a mainstream, mandatory, and critical force behind the “data everywhere” movement.
As a result, many organizations have adopted the governance tools needed to manage and deliver their data as a high-quality asset back to the business. Historically, these tools have focused on aspects of data compliance and risk mitigation, which while important and necessary, make it difficult for teams to access and make use of the valuable data they need. The objective has essentially been to lock data down and keep it safe at all costs. Additionally, these tools are built for data at rest—data standing still inside databases—requiring point-to-point integrations with every system, which is a challenging and painful operation that’s constantly chasing an in-sync and on-time state that never fully materializes.
The rise of data in motion
With the sharp rise of real-time data, Apache Kafka®, and event-driven systems, the need for organizational governance over data in motion is growing quickly. While the tools to build and maintain long-term, compatible event streams exist, the ability to safely and effectively share these streams across teams and cloud environments for widespread use has not. This need is most pressing for businesses deploying distributed, event-driven microservices built by small, disparate teams of streaming data experts. As the investment into microservices increases and data sources scale, it becomes more and more challenging for any individual or team to understand or govern the full scope of streams flowing across the business.
To enable a generation of event-centric enterprises, we need a fresh approach to governance, one built for data in motion that allows businesses to scale operations around a central nervous system of real-time data.
Modern governance for data in motion needs to strike a balance in priorities between data guardians and data users. Or said another way, trust and innovation. It allows businesses to find harmony between protecting and democratizing access to data in motion. This concept is bigger than just data governance as it gets to the core of how businesses want to behave and operate in a new reality where every company is becoming software.
Introducing Stream Governance
Confluent enables businesses to set their data in motion and is now embedding tools within its fully managed, cloud-native service that govern and safely guide the expansion of that data across the entire organization. When distributed teams are able to explore, understand, and trust data in motion together they can harness its full value. Companies can accelerate the development of the real-time experiences that drive differentiation and increase customer satisfaction while upholding strict compliance requirements. Modern data governance, built for data in motion, is the key to fostering the collaboration and knowledge sharing necessary to become an event-centric business while remaining compliant within an ever-evolving landscape of data regulations.
Today we are announcing the launch of our Stream Governance suite, now generally available within Confluent Cloud.
Discover, understand, and trust your event streams with the industry’s only fully managed governance suite for data in motion.
Stream Governance is built upon three key strategic pillars:
- Stream quality: Deliver trusted, high-quality event streams to the business and maintain data integrity as services evolve
- Stream catalog: Increase collaboration and productivity with self-service data discovery that allows teams to classify, organize, and find the event streams they need
- Stream lineage: Understand complex data relationships and uncover more insights with interactive, end-to-end maps of event streams
Balance trust and innovation with a life cycle of governance over streaming data
“When responsible for the safety of our customers and their families, confidence in data is of the highest priority. With tools like Schema Registry, we have access to a trusted, scalable supply of real-time data streams across cloud environments to power the services today’s families need. And we’re excited about the launch of Confluent’s stream catalog which can allow us to develop classifications of sensitive data and an easier means of maintaining regulatory compliance.”
-Sean Schade, Distinguished Architect, Care.com
Stream Governance in action
To better understand the governance capabilities we’re releasing today, let’s imagine a real-world scenario of an air traffic control team tracking aircraft locations across the US airspace.
For this scenario, we will create a topic called “aircraft” to store real-time aircraft location data. This is sensitive data that powers mission-critical applications throughout US airports and intelligence agencies. It’s paramount that the data on this topic is secure, accurate, and fit for purpose.
Secure the data
Securing this sensitive data is a key part of governance. Access to the topic should be locked down, monitored for suspicious activity, and encrypted to maintain data confidentiality. Confluent Cloud’s enterprise-grade security features such as Role-Based Access Control (RBAC) or Access Control Lists (ACLs), Audit logs, and data encryption enabled by default provides the appropriate level of security for this data stream.
Define a schema for aircraft location data
Standardize the structure of the data for this topic by creating a JSON schema on Confluent Schema Registry. Schema Registry is a battle-tested schema management system for data in motion with support for Avro, Protocol Buffers, and JSON Schema. Having a well-defined and agreed-upon schema for the topic guarantees producers and consumers of aircraft location data know exactly what to expect. Plus, we put the guardrails in place to successfully evolve the structure of this data over time; i.e., its schema, safely. Schemas and Schema Registry are a key piece of our stream quality pillar and a critical aspect of governing data in motion on Confluent.
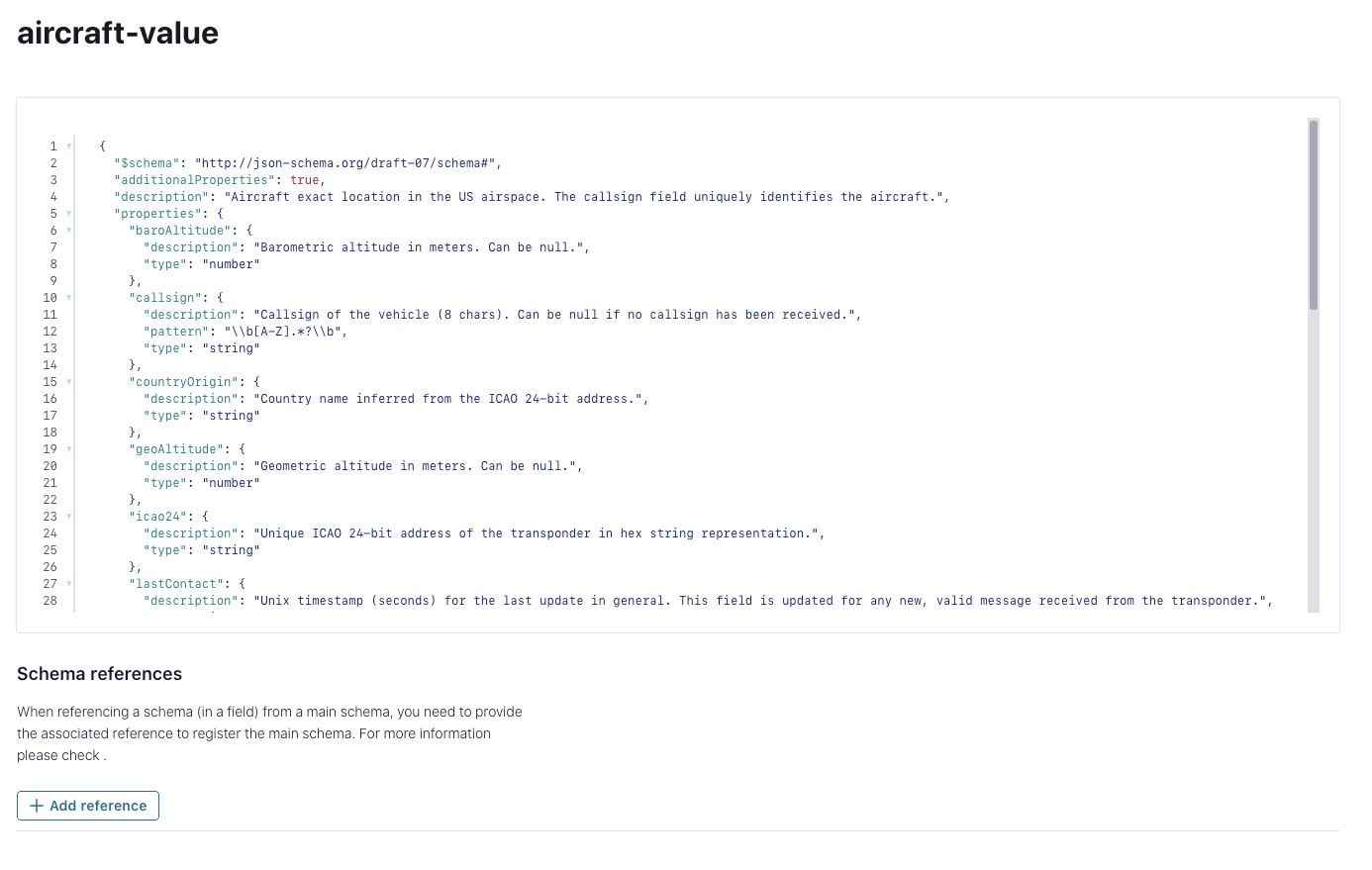
Create JSON schema in Schema Registry
Today we are also releasing our new schema linking product in preview. With schema linking, you can keep schemas in sync across Schema Registry clusters supporting both active-passive and active-active setups. While already available in Confluent Cloud, this new capability will also come to Confluent Platform 7.0 soon.
Additionally, Schema Registry now supports schema references, which simplify and streamline nested schema models and allow you to put multiple event types in the same topic using the default TopicNamingStrategy. By using this subject name strategy you implicitly tie a schema to a topic and, in combination with schema references, specify exactly which event types can appear in a topic, as opposed to using RecordNamingStrategy which allows an unbounded number of event types in a topic.
Enable schema validation
Next, we enable the “aircraft” topic with broker-side schema ID validation (available for Confluent Cloud dedicated clusters and for Confluent Platform), a broker interceptor that keeps bad data out, only available within Confluent products. With this new stream quality feature, we make sure that no data is allowed in unless it arrives with a schema ID that is both valid within Schema Registry and assigned to the destination topic (when using TopicNamingStrategy). If anyone tries to send data not matching these strict, schema-aware rules, we kindly show them the exit. Schema validation can be enabled without installation or configuration of anything on your clients—it’s a simple configuration switch on your topic.
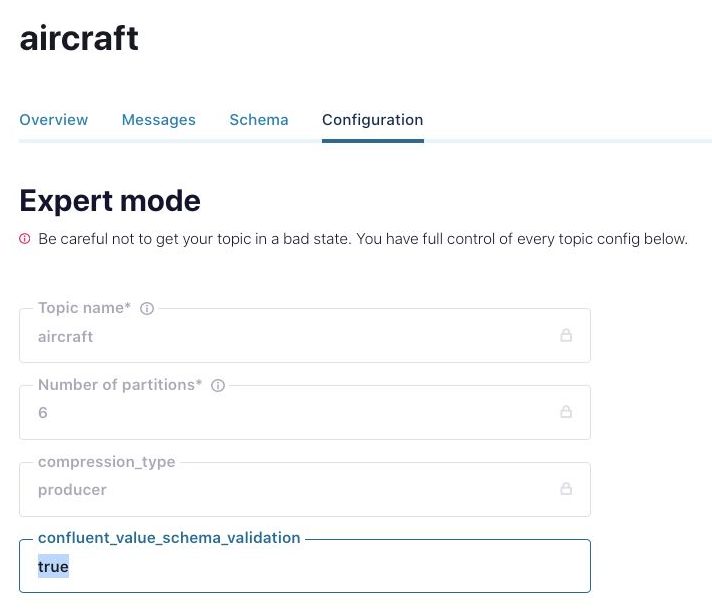
Enable broker-side schema ID validation (topic configuration)
“To provide homes where people feel safe and secure, we need our data in the exact same state. While Confluent ensures that our complex and ever-evolving data streams are always fit for use, keeping the technology framed and easy to use for our teams is one of our priorities. With Stream Governance, we have an additional tool to help developers in our growing engineering organization to keep improving the way we work with data in motion. They’ll have easier ways to not only find the data they need but to truly understand it and gain the confidence required to put it to use right away.”
-Mustapha Benosmane, Digital Product Leader, Adeo
Classify the data
Now that you have the data contract defined for your aircraft data product it’s time to enrich it with business metadata. This will give it more context and make it easier for people to discover the valuable data set. For this task, we’ll use the new stream catalog tagging capabilities to create multiple tags for entity classifications.
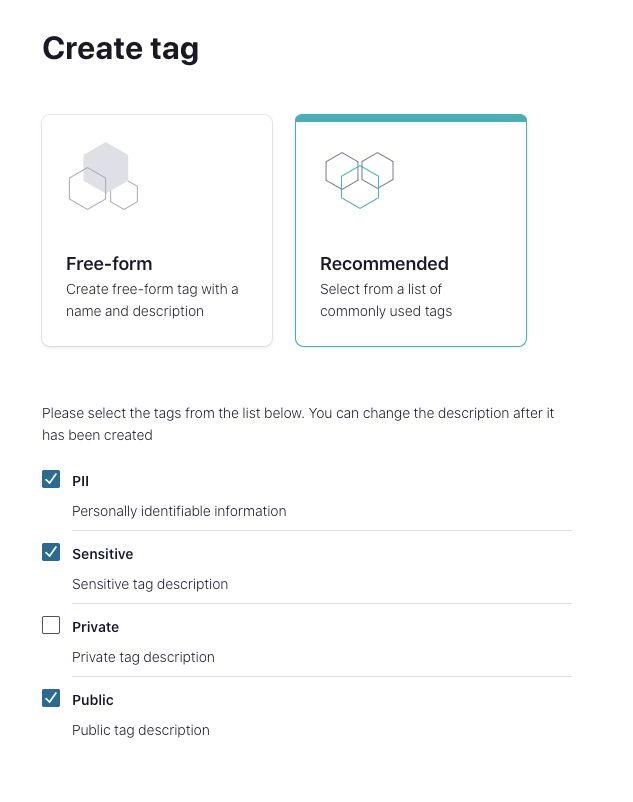
Create tags
Next, we go back to our schema and tag it according to the data classification standards defined by the organization. With the new schema tree view, all users, technical or not, can easily navigate all fields, their descriptions, and tag as necessary—resulting in a collaborative effort to increase the overall value of the stream catalog.
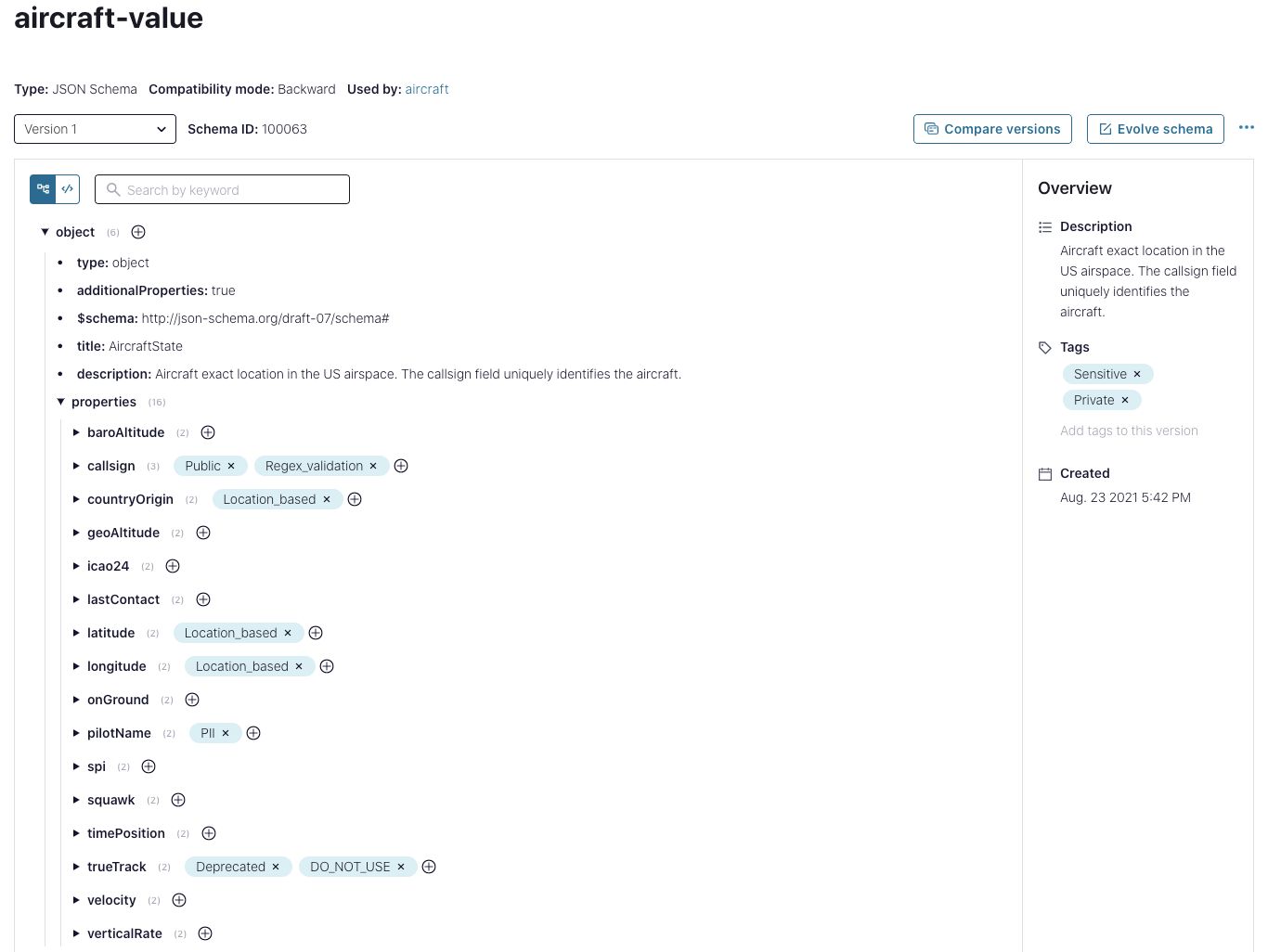
Tag schema and fields
Search for and discover the data you need
Now, let’s switch roles. Let’s say you’re an app developer and your boss asks for you to keep an up-to-date count on the number of aircraft in flight, by country of origin. You don’t know if this data exists, or even where to start looking for it. Until now, that is! With the new stream catalog, you can tap into a business-wide knowledge base of data in motion to search for and discover what’s available across the platform. Maybe you start by searching for “country” within Confluent’s global search bar or filter by the tag “Location_based” on the advanced catalog search page. And boom! There’s a field called “countryOrigin” in one of the schemas. You don’t need to chase people or file tickets to find out what data is available and where it’s located. With a self-service data discovery tool, you’re able to work autonomously with boosted productivity and efficiency.
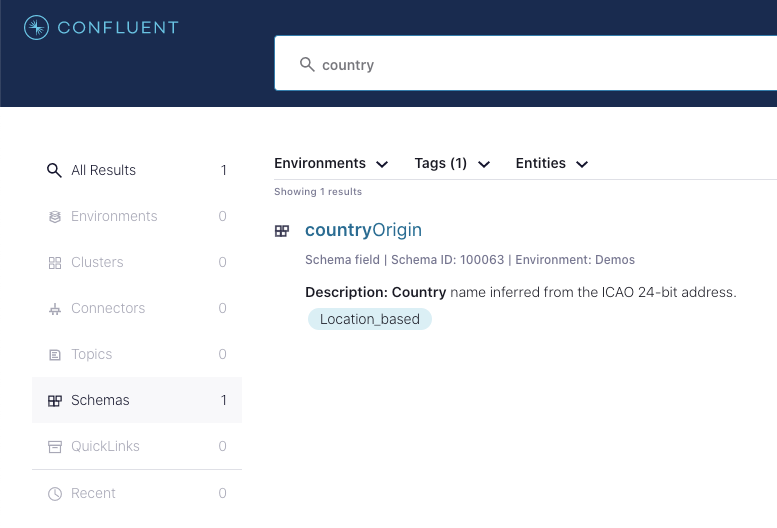
Stream catalog search
Once on the schema page found through the stream catalog, you can now navigate to the corresponding topic (when using TopicNamingStrategy) and browse messages in real-time to learn more about this data.
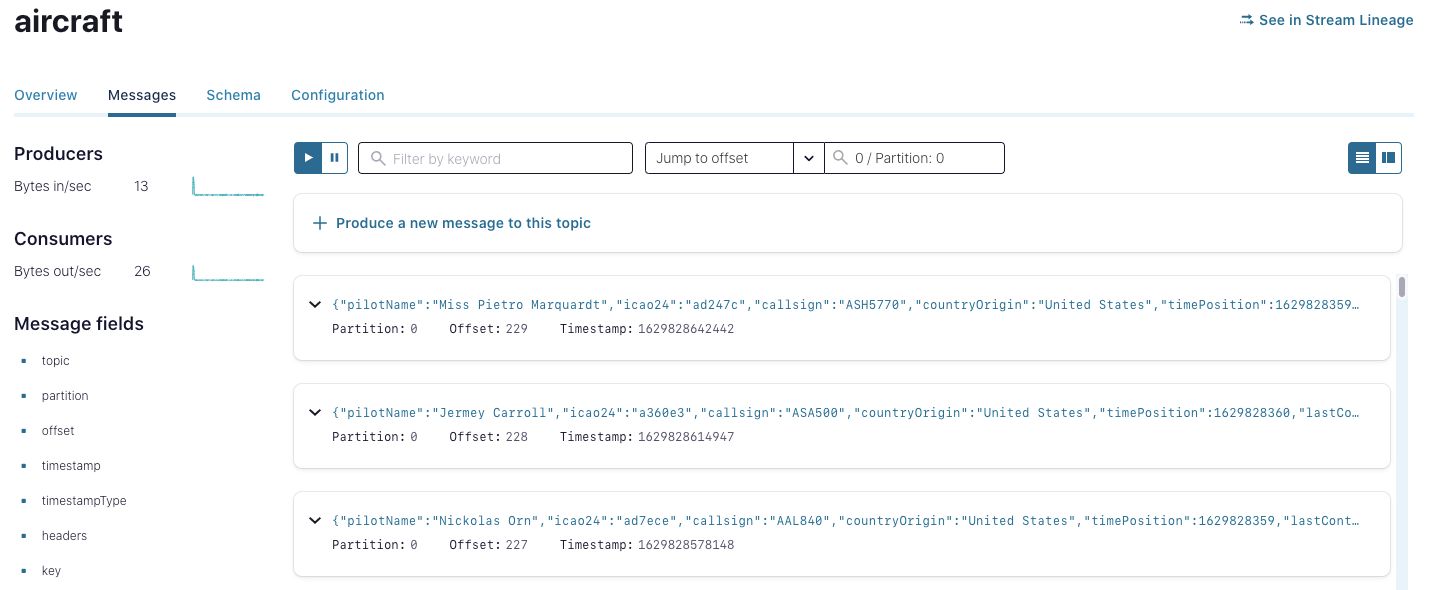
Topic message browser
Finally, you have all you need. Create a ksqlDB query that consumes from the topic “aircraft” and counts the number of aircraft grouped by country of origin.
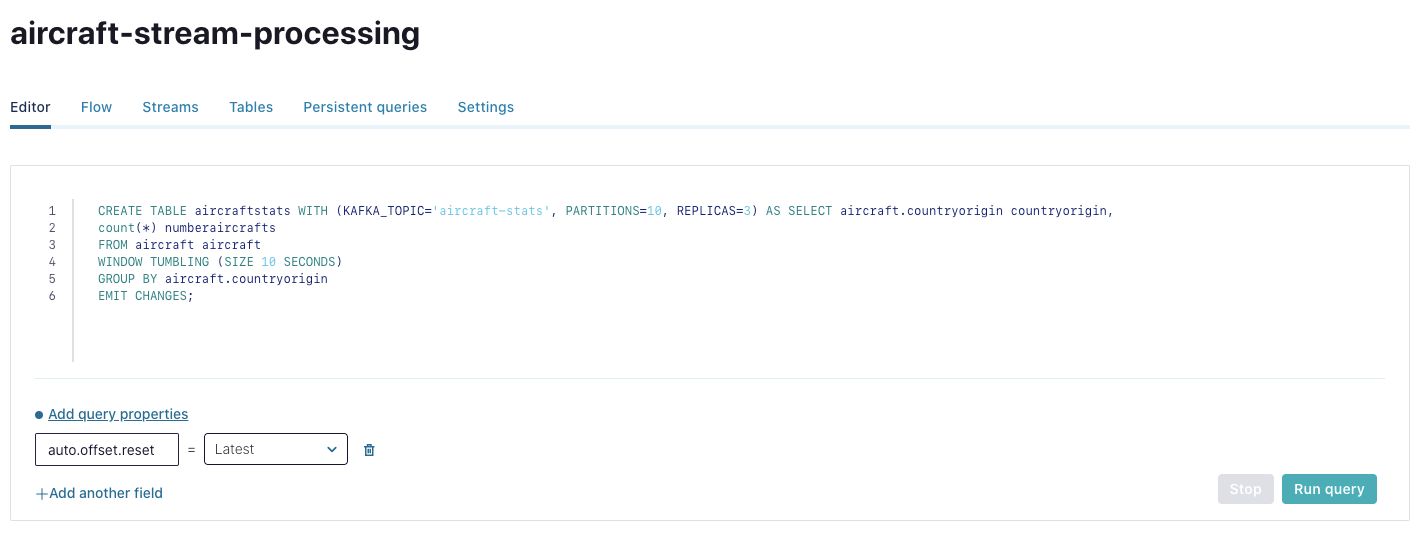
Create ksqlDB table
Trigger dynamic audit reporting on streams lineage
Let’s switch roles again. Suppose you are now a data steward tasked with reporting the flows of aircraft location data for audit purposes. You need to know who produces, transforms, and consumes all this sensitive data. With stream lineage, a detailed graph of event streams from source to destination is just one click away. With this self-service approach, you don’t have to rely upon others to get the data answers you need. Lineage graphs are built automatically based upon activity through your producers and consumers, with no need for client-side setup or any additional instrumentation.
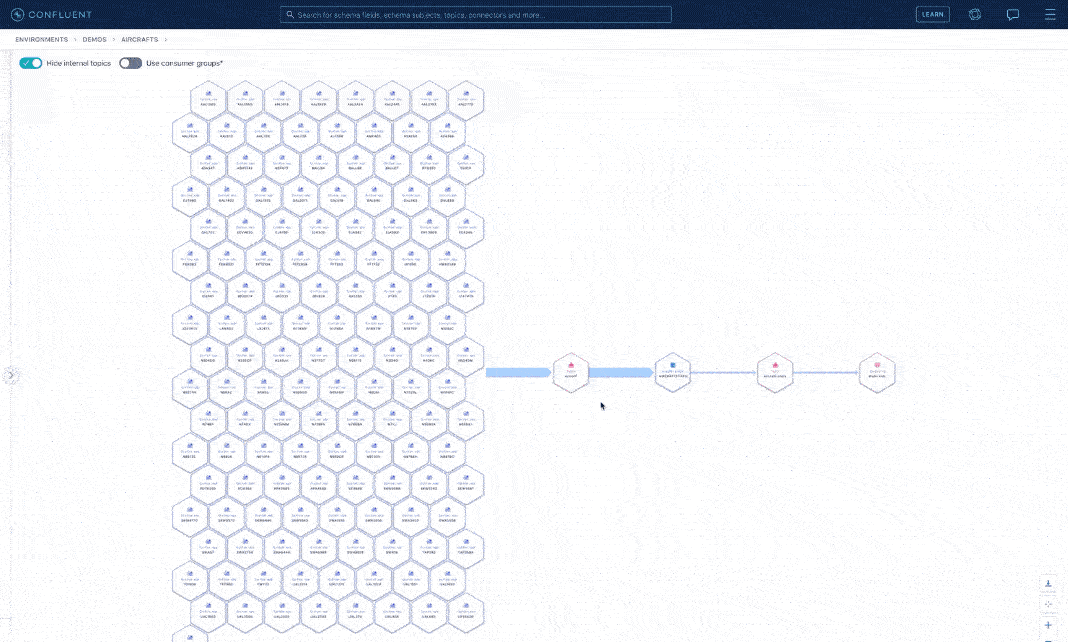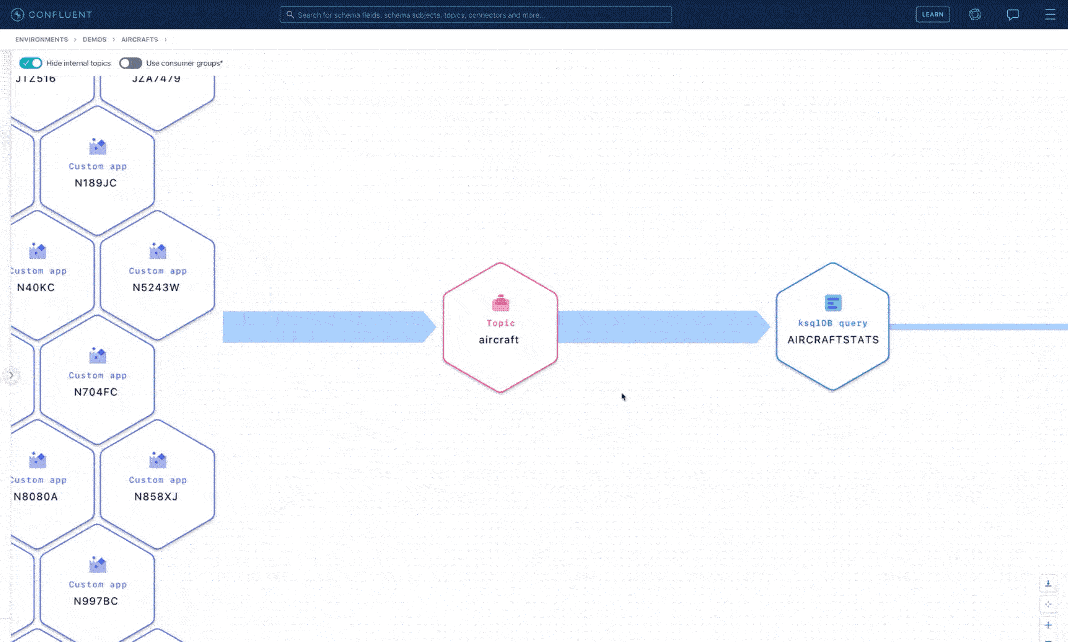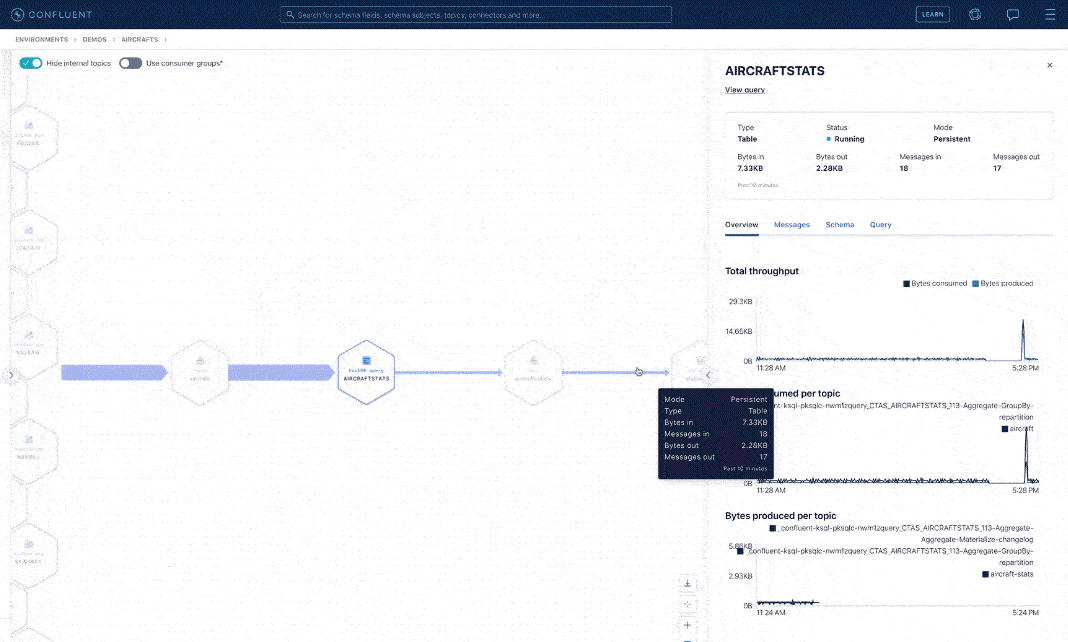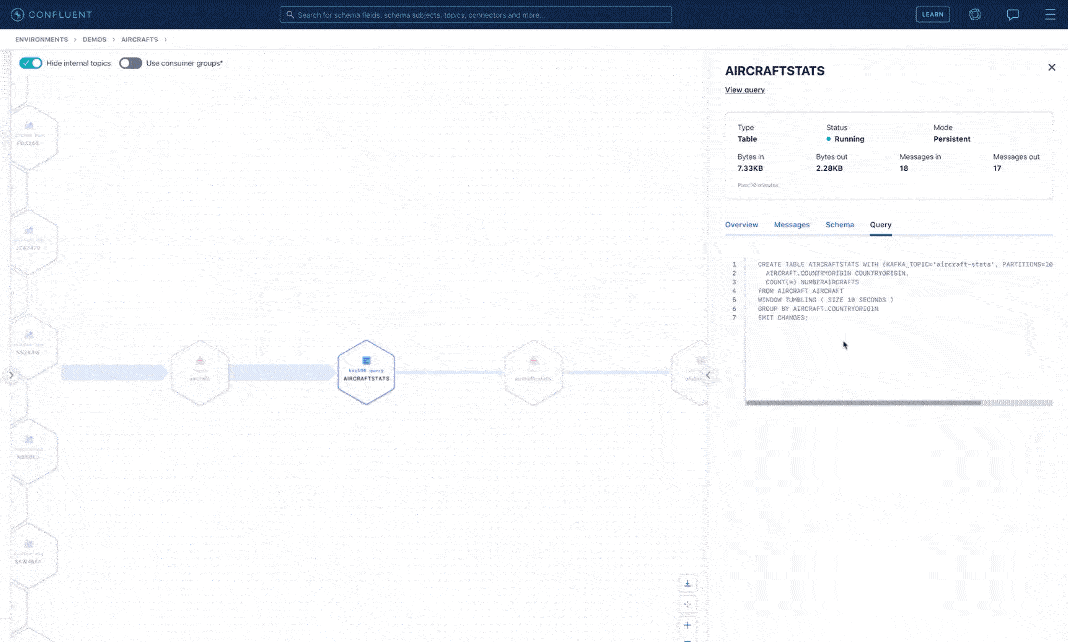
Stream lineage visualization
“As the world’s leading global equipment marketplace, we make buying and selling easy with critical customer services like real-time online bidding powered by data in motion. Confluent’s Stream Governance suite will play a major role in our expanded use of data in motion and creation of a central nervous system for the enterprise. With the self-service capabilities in stream catalog and stream lineage, we’ll be able to greatly simplify and accelerate the onboarding of new teams working with our most valuable data.”
-Nic Pegg, Platform Lead, Ritchie Bros.
Looking forward and getting started
This is only our first release for Stream Governance. In quarters ahead you’ll see updates including more flexible business metadata coming to stream catalog, time-series lineage coming to stream lineage, private networking and multi-region selection coming to Schema Registry, and data classification-based policies, just to name a few.
We’re building a comprehensive, interoperable, decentralized, and fully integrated Stream Governance solution available across cloud, on-premises, and hybrid environments. We believe that this will unlock a powerful self-service platform that welcomes everyone to be part of the data in motion revolution.
Ready to get going? If you’ve not done so already, make sure to sign up for a free trial of Confluent Cloud and start using our new Stream Governance capabilities today. And with promo code CL60BLOG you’ll get an additional $60 of free Confluent Cloud usage.
Want to continue learning more? Be sure to register for the upcoming Stream Governance demo webinar to dive even deeper and see the governance suite in action.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



New with Confluent Platform 7.9: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and More
This blog announces the general availability of Confluent Platform 7.9 and its latest key features: Oracle XStream CDC Connector, Client-Side Field Level Encryption (EA), Confluent for VS Code, and more.


Meet the Oracle XStream CDC Source Connector
Confluent's new Oracle XStream CDC Premium Connector delivers enterprise-grade performance with 2-3x throughput improvement over traditional approaches, eliminates costly Oracle GoldenGate licensing requirements, and seamlessly integrates with 120+ connectors...